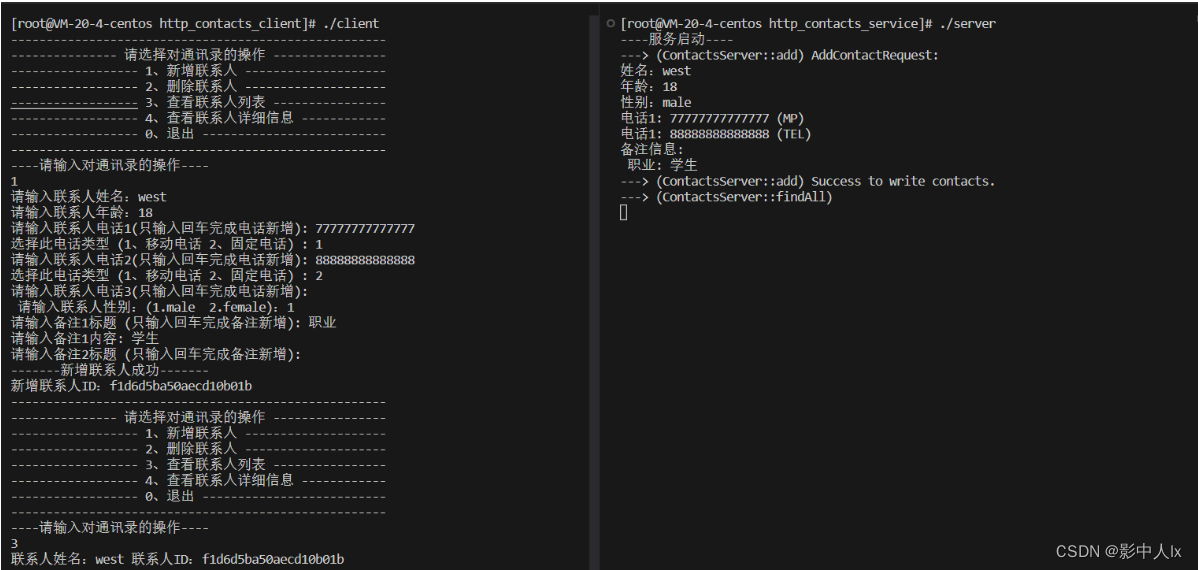
2 月,Meta 发布了其大型语言模型:LLaMA。与 OpenAI 及其 ChatGPT 不同,Meta 不仅仅为世界提供了一个可以玩的聊天窗口。
相反,它将代码发布到开源社区,此后不久模型本身就被泄露了。研究人员和程序员立即开始修改、改进它,让它做一些其他人没有预料到的事情。
他们的结果是立竿见影的、创新的,并预示着这项技术的未来将如何发展。训练速度大大提高,模型本身的大小已经缩小到可以在笔记本电脑上创建和运行的程度。人工智能研究的世界已经发生了巨大的变化。
这一发展并没有像其他公司公告那样引起轰动,但其影响会大得多。它将从大型科技公司手中夺取权力,从而带来更多的创新和更具挑战性的监管环境。
控制这些模型的大公司警告说,这种混战将导致潜在的危险发展,并且已经记录了开放技术的问题使用。但那些致力于开放模型的人反驳说,一个更民主的研究环境比让这种强大的技术由少数公司控制要好。
权力转移来自简化。由 OpenAI 和谷歌构建的 LLM 依赖于以数百亿字节为单位的海量数据集,这些数据集由数万个强大的专用处理器计算得出,这些处理器生成具有数十亿个参数的模型。
人们普遍认为,构建更好的模型需要更大的数据、更大的处理能力和更大的参数集。生产这样的模型需要一家公司的资源,以及谷歌、微软或 Meta 的资金和计算能力。
但是,在 Meta 的 LLaMa 等公共模型的基础上,开源社区进行了创新,其结果几乎与大型模型一样好,但在具有通用数据集的家用机器上运行。
曾经是资源丰富的保护区,现在已成为任何有好奇心、编码技能和一台好笔记本电脑的人的游乐场。越大越好,但开源社区表明,通常越小越好。这为更高效、可访问和资源友好的开源模型打开了大门。
更重要的是,这些更小、更快的 LLM 更容易获得,也更容易进行实验。无需数万台机器和数百万美元来训练新模型,现在可以在几小时内在中等价位的笔记本电脑上定制现有模型,这促进了快速创新。
它还从谷歌和 OpenAI 等大公司手中夺走了控制权。通过提供对底层代码的访问并鼓励协作,开源计划使各种开发人员、研究人员和组织能够塑造技术。
这种控制的多样化有助于防止不当影响,并确保人工智能技术的开发和部署符合更广泛的价值观和优先事项。现代互联网的大部分内容都是基于 LAMP(Linux、Apache、mySQL 和 PHP/PERL/Python)堆栈的开源技术构建的,这是一组经常用于 Web 开发的应用程序。
这使得复杂的网站可以轻松构建,所有这些都使用由爱好者而不是寻求利润的公司构建的开源工具。Facebook 本身最初是使用开源 PHP 构建的。
但开源也意味着没有人为滥用该技术负责。当在对互联网功能至关重要的开源技术的模糊部分中发现漏洞时,通常没有实体负责修复漏洞。开源社区跨越国家和文化,因此很难确保任何国家的法律都会得到社区的尊重。
将技术开源意味着那些希望将其用于意外、非法或邪恶目的的人与其他人一样可以使用该技术。
这反过来又对那些希望监管这项强大的新技术的人产生重大影响。现在开源社区正在重新混合 LLM,不再可能通过规定可以进行哪些研究和开发来规范技术;太多的研究人员在太多不同的国家做着太多不同的事情。
政府现在唯一可用的治理机制是规范使用(并且只针对那些关注法律的人),或者为那些现在是创新驱动力的人(包括初创公司、个人和小公司)提供激励。竞技场。对这些社区的激励可以采取奖励特定技术用途的形式,或举办编程马拉松来开发特别有用的应用程序。
重要的是要记住,开源社区并不总是以利润为动机。这个社区的成员通常被好奇心、实验欲望或简单的构建乐趣所驱使。虽然有些公司从支持开源项目(如 Linux、Python 或 Apache Web 服务器)生产的软件中获利,但这些社区并不是以利润为导向的。
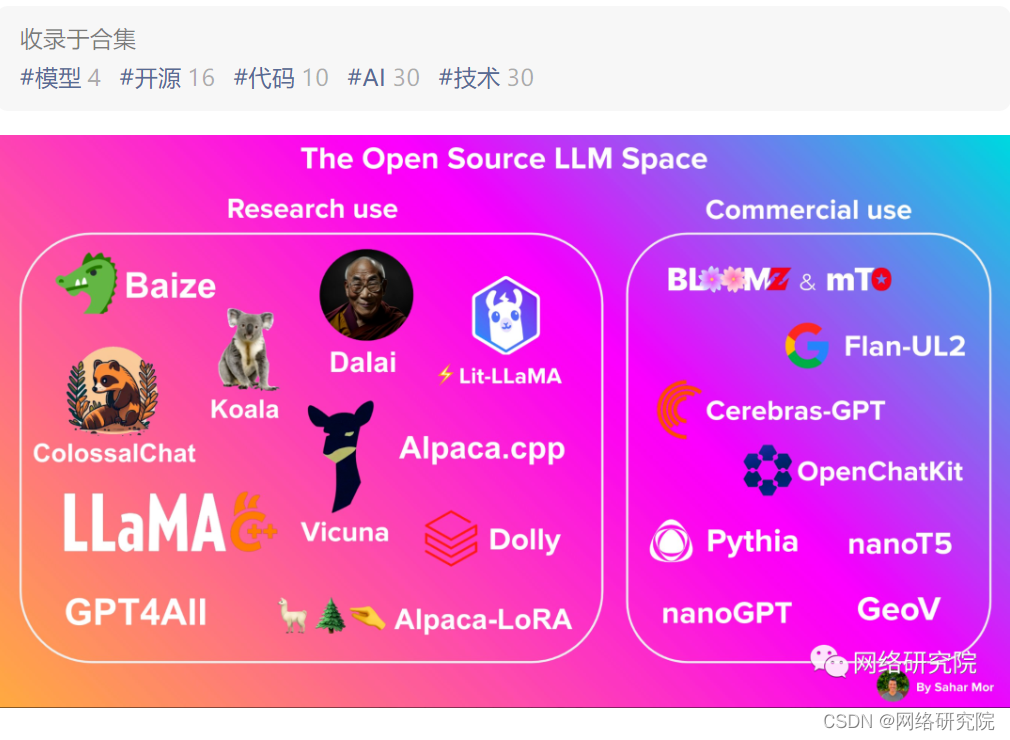
并且有很多开源模型可供选择。Alpaca、Cerebras-GPT、Dolly、HuggingChat 和 StableLM 都在过去几个月发布了。它们中的大多数都建立在 LLaMA 之上,但有些具有其他血统,更多的正在路上。
一直在开发和实施 LLM 的大型技术垄断企业,谷歌、微软和 Meta 还没有为此做好准备。几周前,一名谷歌员工泄露了一份备忘录,其中一名工程师试图向上级解释开源 LLM 对他们自己的专有技术意味着什么。备忘录的结论是,开源社区已经超越了大公司,并以压倒性优势领先于它们。
这不是公司第一次忽视开源社区的力量。Sun 从不了解 Linux。Netscape 从不理解 Apache Web 服务器。
开源在原始创新方面不是很擅长,但一旦发现并采纳了一项创新,社区就会变得势不可挡。大公司可能会通过尝试从开源社区中缩减和撤回他们的模型来做出回应。
但为时已晚。我们已经进入了 LLM 民主化的时代。通过展示更小的模型可以非常有效,使实验变得容易,控制多样化,并提供非利润驱动的激励措施,开源计划正在将我们带入一个更具活力和包容性的人工智能领域。
这并不意味着其中一些模型不会有偏见或错误,或不会被用来产生虚假信息或滥用职权。但这确实意味着控制这项技术将采取与监管大型参与者完全不同的方法。