感谢各位 点赞 收藏 评论 三连支持
本文章收录于专栏【Linux系统编程】
❀希望能对大家有所帮助❀
本文章由 风君子吖 原创


前言
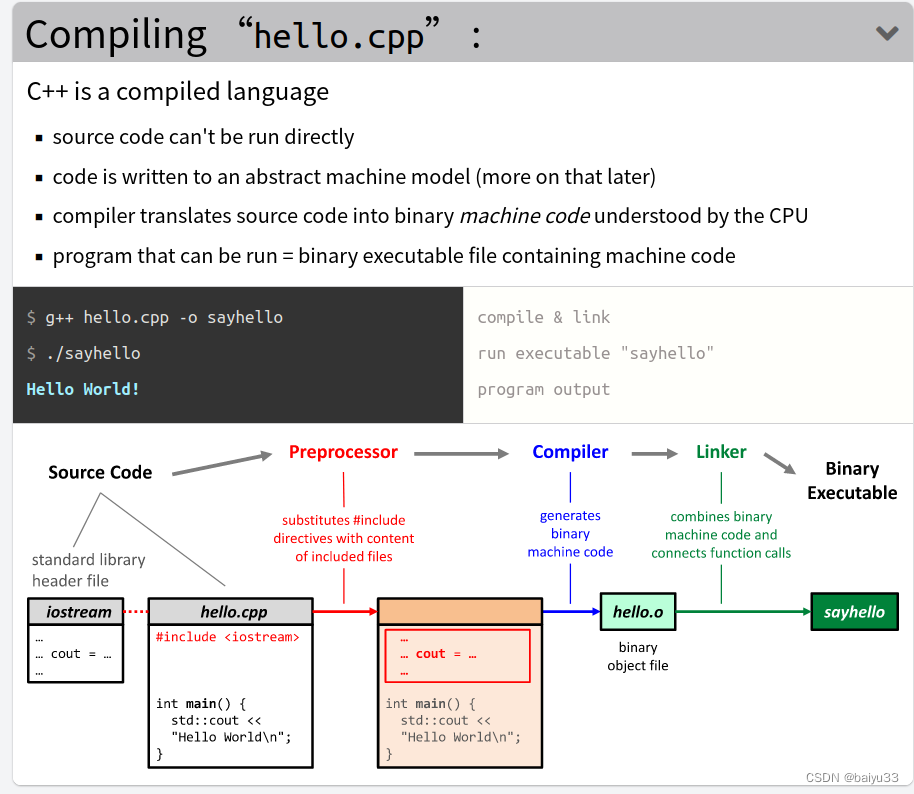
对于文件,之前我们已经铺垫的大量的知识,知道了C语言提供的文件接口底层是如何实现,知道了系统提供的文件接口函数如何使用,了解了内核对于打开的文件的体系结构,明白了重定向的原理,而本章内容主要是为之前的知识做一个更详细的解释和补充。
struct file
上篇文章我们详细讲解了内核是如何对打开的文件进行管理

而struct file 也主要是存储文件的相关属性和其他的一些内容(比如说文件的IO函数),我们这里也是主要详细讲解这个结构体内部存储的一种我们几乎之前没有用到过的东西 -- 函数指针!
首先,要提出这么一个问题,对于每个硬件,每个硬件的IO方式(函数)是否都是一样的?那要是不一样,Linux又如何通过我们上图的这种体系结构来做到 “万物皆文件”?
那么不同的硬件对应着不同的IO函数,我们可以通过怎样的方式来实现,要知道,这可不是C++,在C++中,类有继承和多态,可以做到不同的对象具有不同的形态。但是这些写操作系统的大佬们就想到了如何用C语言这种面向过程的语言做到了面向对象,通过函数指针来实现,在C语言的结构体中包含一个函数。

这就说明,从很久以前,那些C语言的大佬们早就想到了面向对象,于是就有了C++。
缓冲区
对于缓冲区,我们之前也接触过,也使用过fflush(C语言库)。
但是我们始终不知道缓冲区为什么存在,存在的意义是什么,如何存在?
先来说说缓冲区为什么而存在(缓冲区的作用):
在之前的我们写的代码有过许多例子,比如说使用printf函数,如果不在字符串末尾加上\n,就无法及时输出结果,只能等待程序运行完才会输出结果,这就是因为缓冲区没有刷新。
对于缓冲区,我们的第一印象就是,他只是用来临时存储一段数据,等到缓冲区刷新时,再给对应的硬件(文件)进行写操作,那么为什么要这么麻烦呢?我就不能直接给硬件进行写操作吗?这不仅仅在某些场景会显得很奇怪,而且我们直接对硬件进行写不是更方便、更直观吗?
因为你只是在用户层的角度去思考,而对于操作系统,为了提高效率,为了尽量减少与硬件的交互,就可以通过缓冲区来完成。 因为从之前我们学习冯洛伊曼体系来看,硬件的响应速度相对于内存的速度是很缓慢的,有大量的交互就意味着需要大量的时间来等待硬件响应,而缓冲区就是一次性打包一连串的数据给硬件以减少对硬件的交互数量。
而缓冲区也有不同的刷新策略,而最常见的几种刷新策略就是
1.行刷新 :这种刷新策略我们见过的最多的就是printf,对显示器的缓冲区的刷新策略
2.满刷新 :这种刷新策略就是等到缓冲区满了再自动刷新,我们像磁盘文件进行写就是这种刷新策略。
3.用户强制刷新: 这种刷新策略一般是用户调用刷新缓冲区接口来进行刷新,比如fflush。
先来看下面这段代码
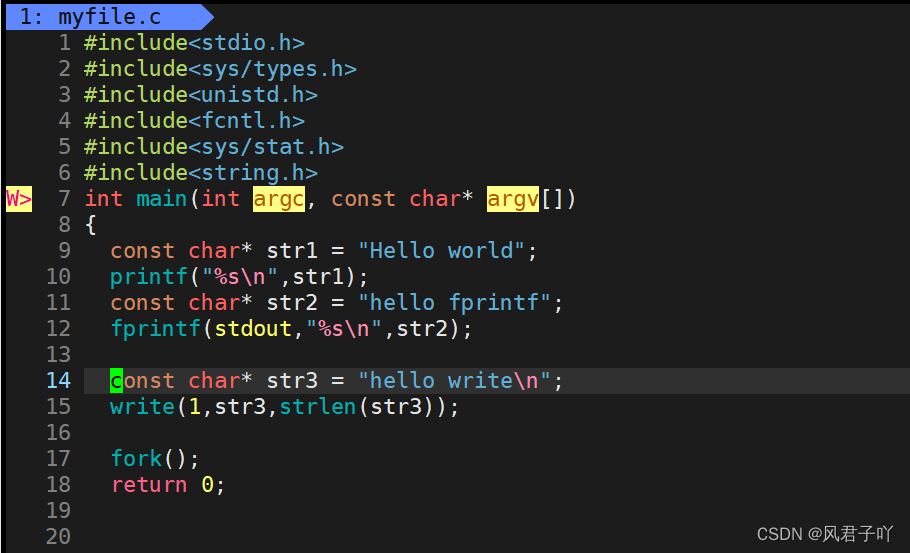
运行结果
[fengjunzi@VM-4-2-centos lesson14_fd]$ ./myfile
Hello world
hello fprintf
hello write
输出重定向结果
[fengjunzi@VM-4-2-centos lesson14_fd]$ ./myfile > log.txt
[fengjunzi@VM-4-2-centos lesson14_fd]$ cat log.txt
hello write
Hello world
hello fprintf
Hello world
hello fprintf
运行结果没什么问题,但是我们的输出重定向结果却是这样的?hello write不仅先打印出来了,而且其他的两个竟然打印了两次?
这就是因为缓冲区的缘故,先来看看导致的问题可能是哪些?
1.在代码结束时使用fork创建子进程
2.write是系统接口,printf和fprintf是C语言库提供的接口
首先,对正常运行的过程进行逐步分析:
1.调用printf并且有\n,根据显示器的刷新策略,行刷新遇到\n,直接刷新缓冲区并打印到屏幕上。
2.fprintf与printf同理。
3.调用write系统接口函数给fd为1的文件(显示器)写入数据。
4.调用fork 创建子进程,但是由于以上的函数都已经完成且缓冲区都刷新完毕,所以子进程没有干事。
再对输出重定向的过程进行逐步分析:
1. 输出重定向要先调用dup2 函数,对fd = 1 的文件(显示器)进行被拷贝覆盖为log.txt文件的内容。
2.此时的缓冲区刷新策略不再是行刷新,而是全刷新。
3. 调用printf,但因为是全刷新策略,printf的内容被保存在缓冲区中,没有被刷新,也就没有被写到log.txt文件中。
4.调用fprintf与printf同理。
5.调用write系统接口函数给fd为1的文件(log.txt)写入数据。
6.调用fork 创建子进程,这个时候由于缓冲区有内容,且在子父进程main函数结束时,刷新缓冲区,而在刷新缓存区的时候就会发生 写时拷贝,就会出现子父进程给log.txt分别打印一次数据的现象。
通过这种分析,大家是否明了了呢?并且我们可以从以上结果推断
1. 因为发生的是写时拷贝,所以这个缓冲区必然是C语言库的,而且还是存储在FILE中。
2. write因为是系统接口,没有像printf和fprintf一样要经过FILE的缓冲区,所以会被先写入到log.txt中。需要注意的是,内核也有自己的缓冲区,但是这里不作分析。
总结
本章内容 对之前的内容进行了一个详细的细节补充和缓冲区的概念补充,下篇文章我会针对我们所有所学知识来完成一个自己的FILE和加入到我们自己实现的easy_shell中