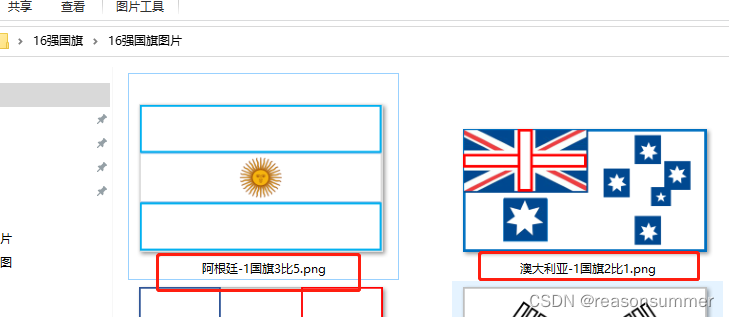
展示效果:
(1个国家2张,16国旗,共32张)

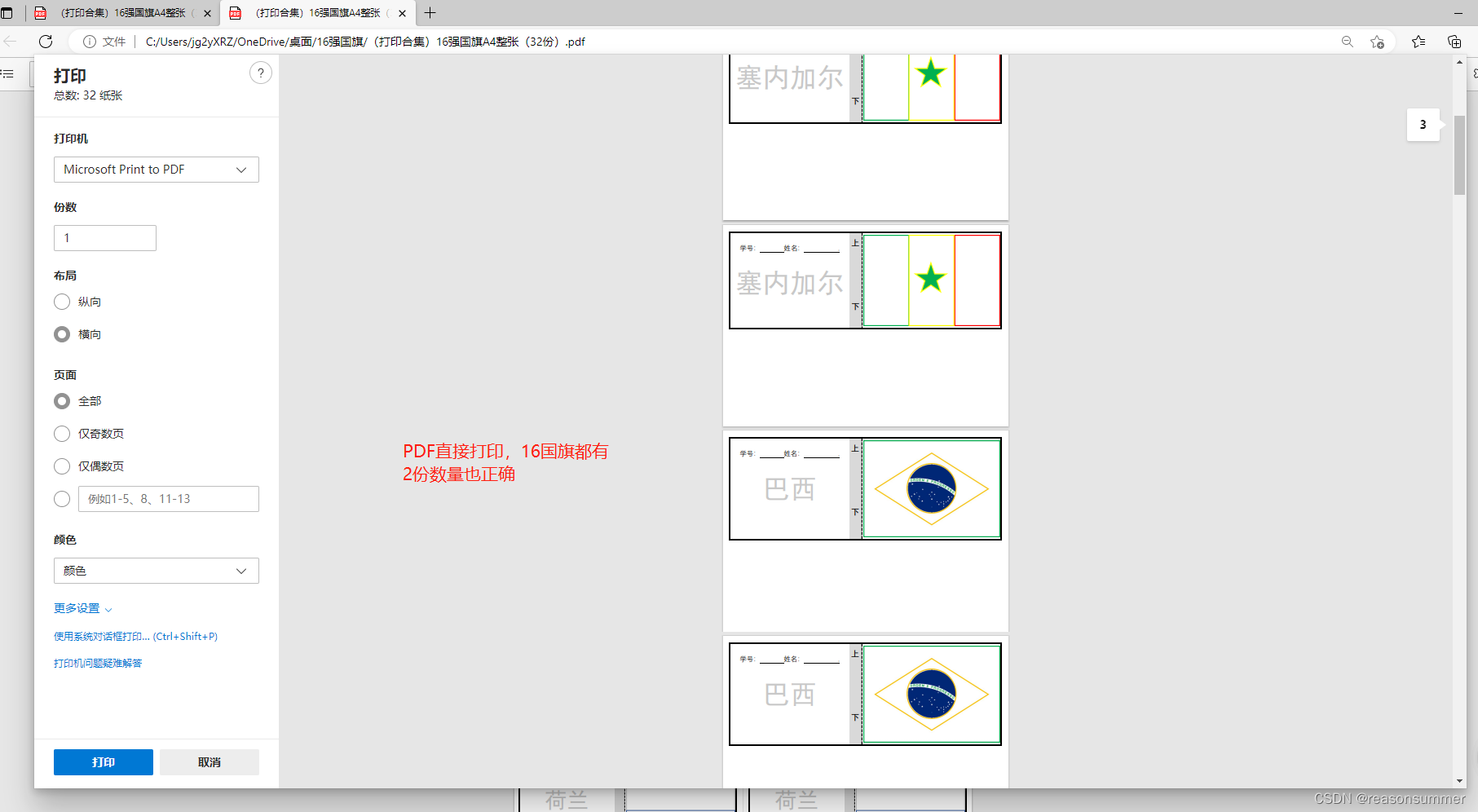
打印效果:

背景需求:
上一份代码打印后发现:
1.打印时发现随机抽取的图案不稳定,30张”澳大利亚”“波兰”的图片特别多。因为前期修图花了不少时间,我想把所有的16张图片都用上,只能单张单国打印2份。

2、而且打印后发现,只有13个国旗图片,少了3个国家。

random.choice(lists,N)因为是随机抽1张,所以会有图案重复,某些图片抽多了,部分图片就不会被选中,因而遗漏。
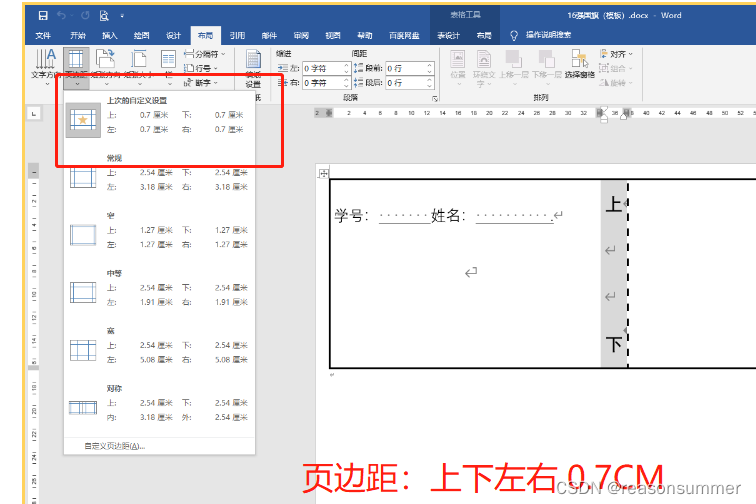
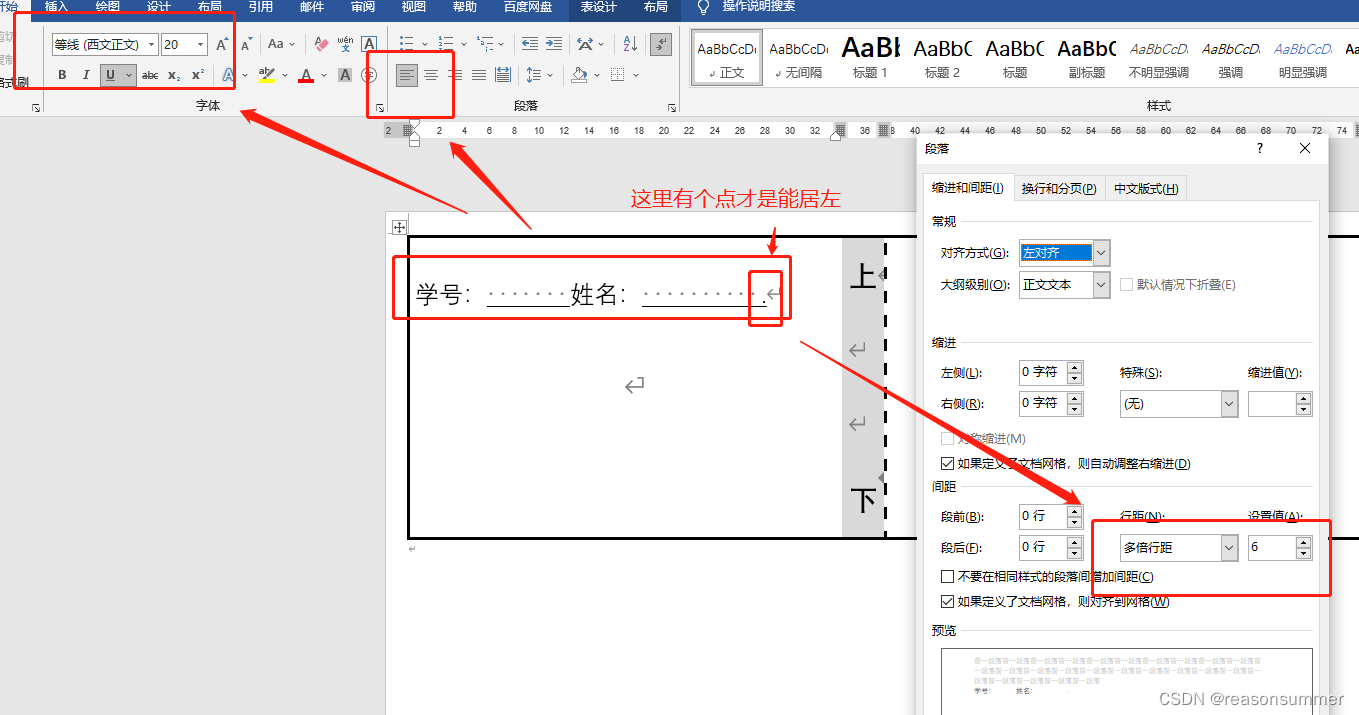
Word模板设置
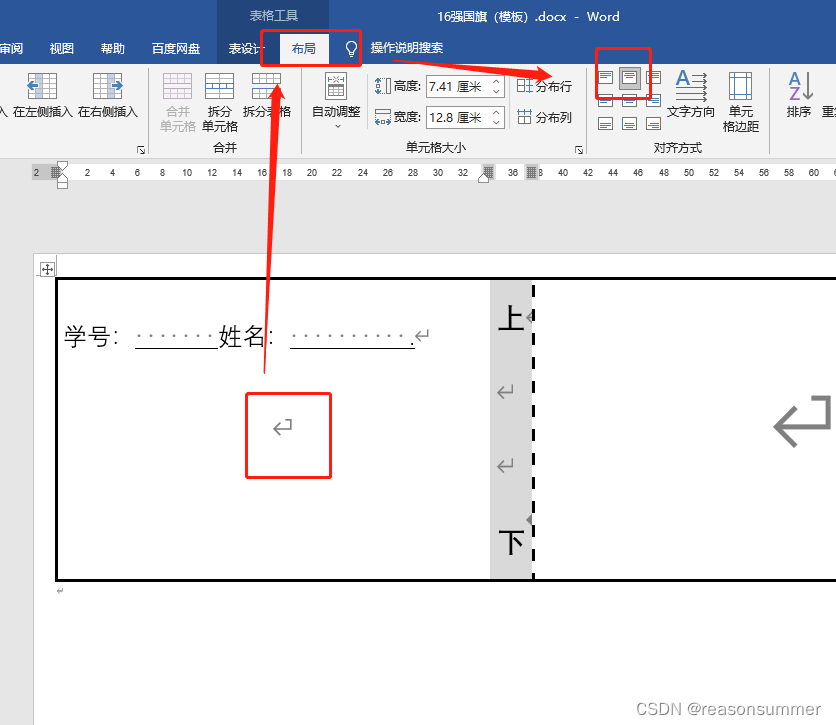
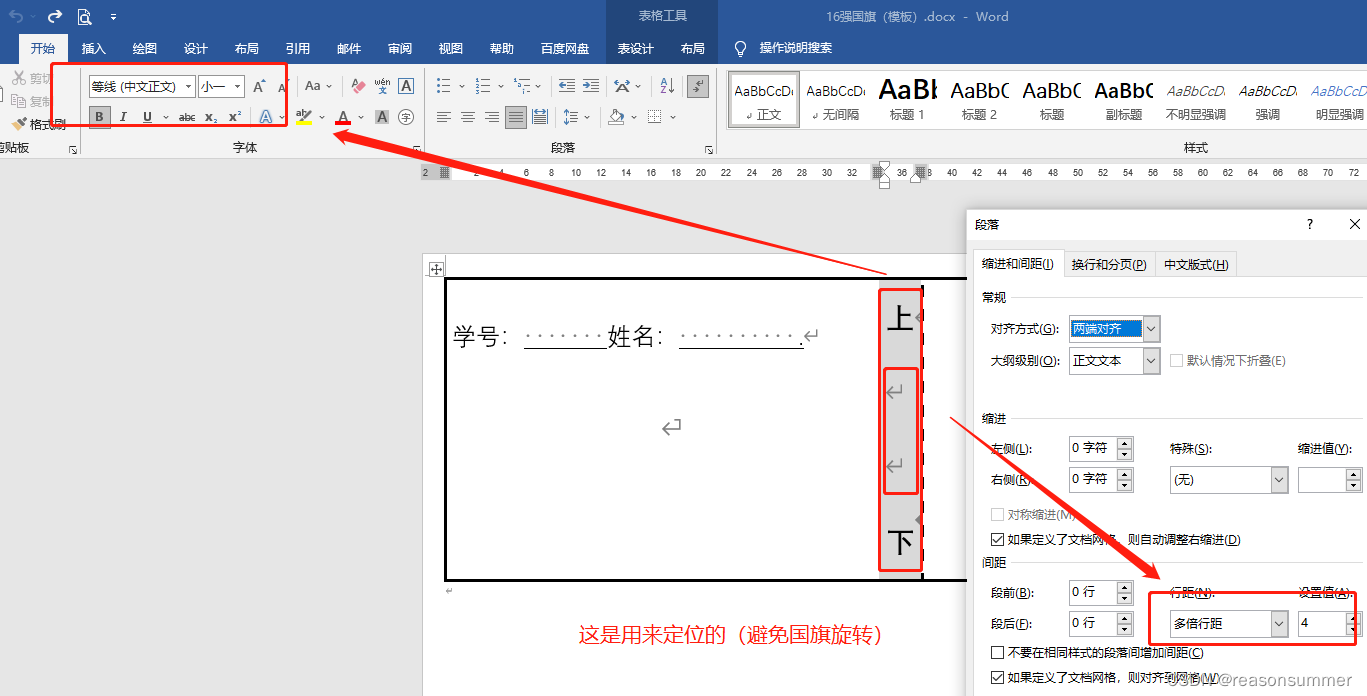
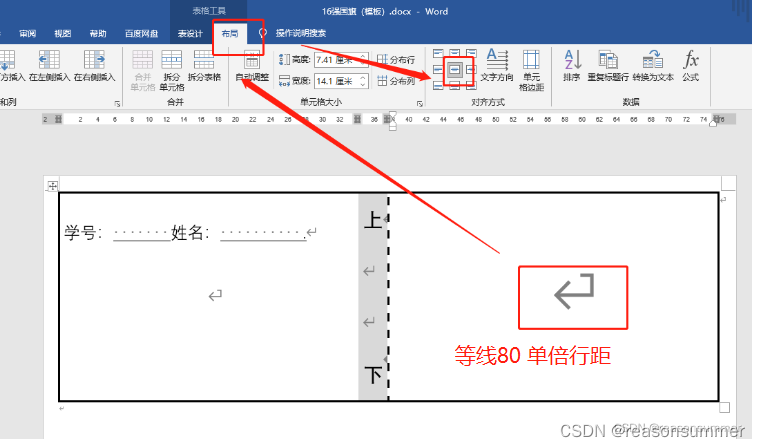
插入1行3列表格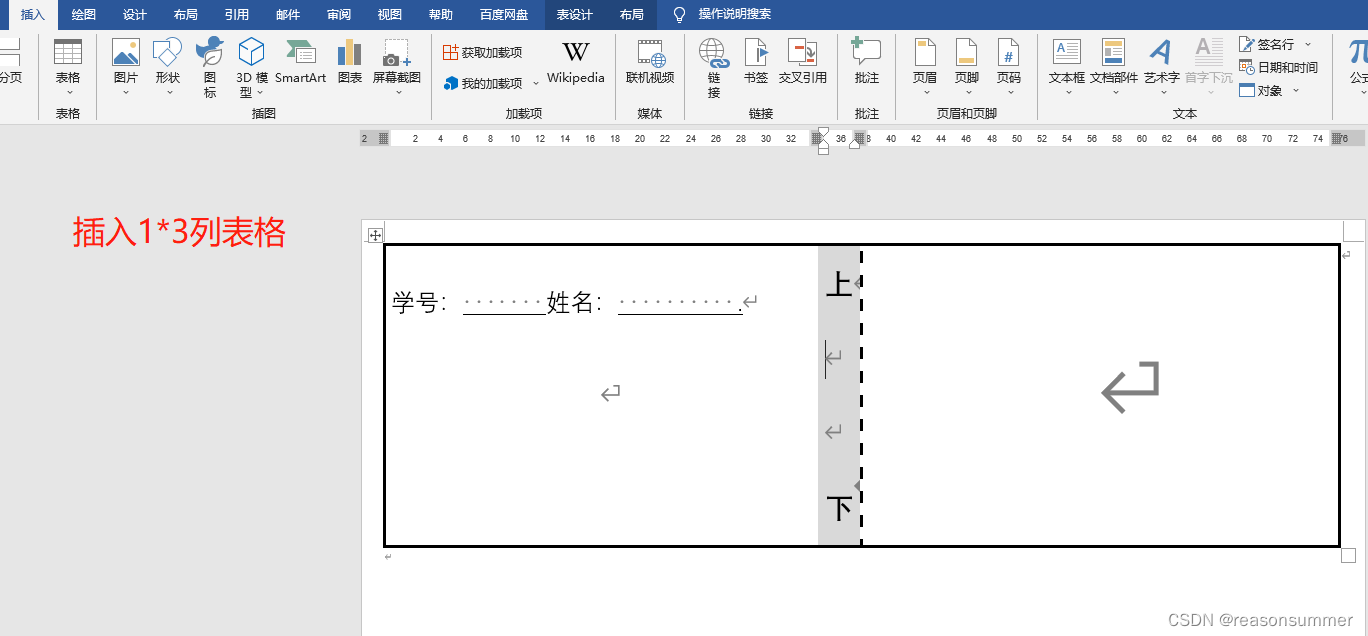
第1个单元格的高宽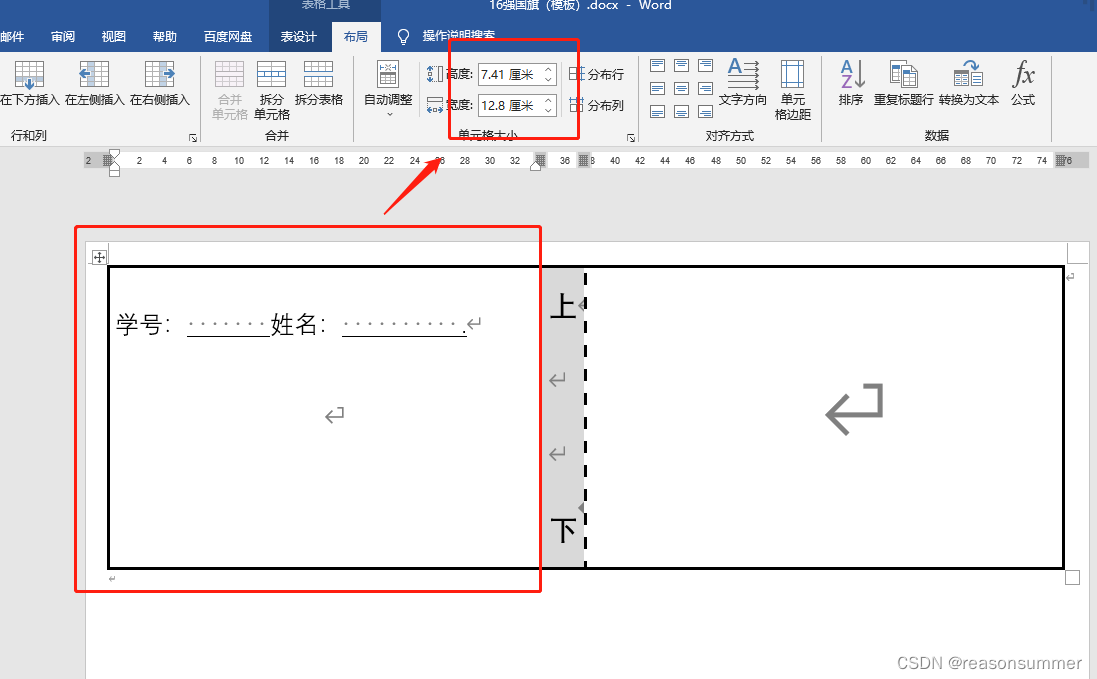
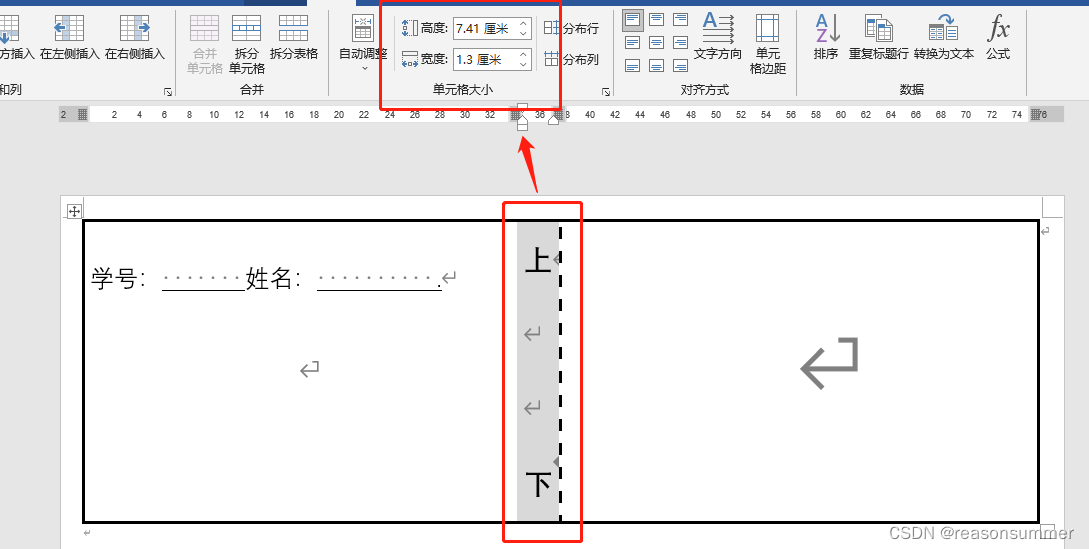
第2个单元格的高宽
第3个单元格的高宽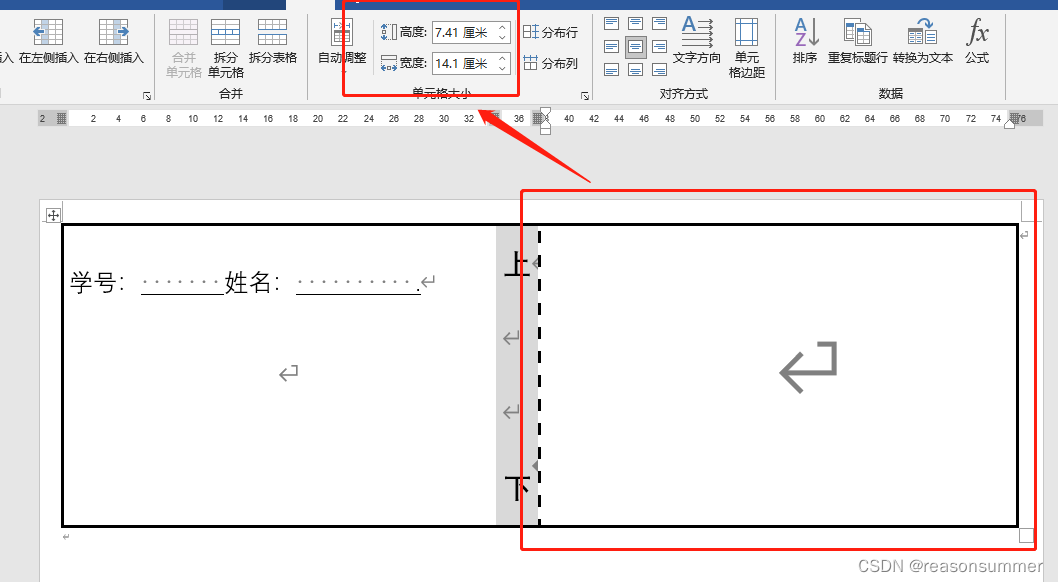
边框设置:内外边框都是黑体3磅,
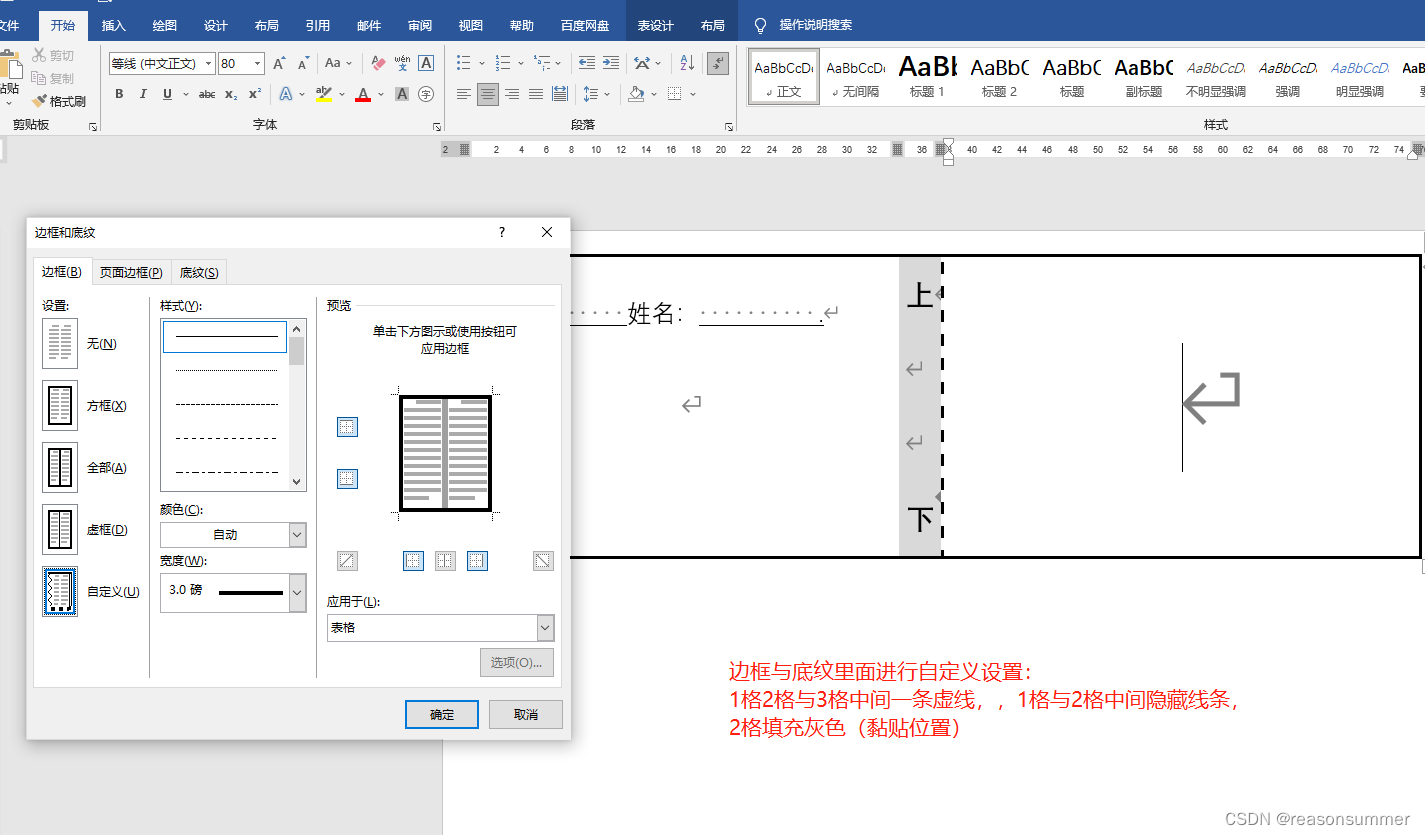
文字
国旗的设计:
网上百度百科里下载16强国家的国旗图片,PNG图片+标注国旗长宽比
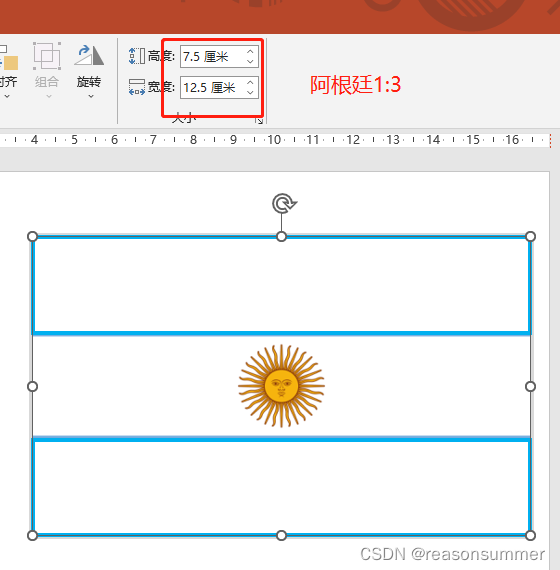
由于每个国旗的长宽比不同,因此不能把国旗统一成一样的长款。
所以需要在ppt 里把图片调整适应Word单元格大小(宽度最多14.1CM)
16强国旗主要有几种款式:(1:3、1:2、7:10、10:18、5:8、1:1、3:5、2:3最多)
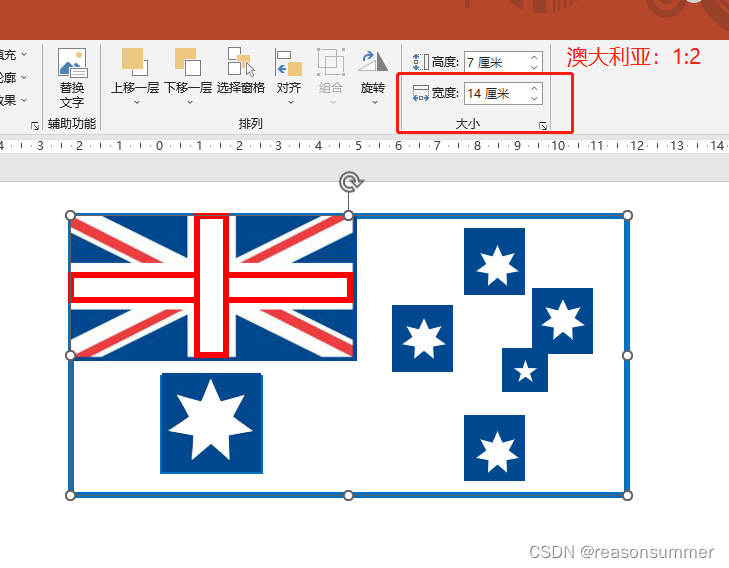
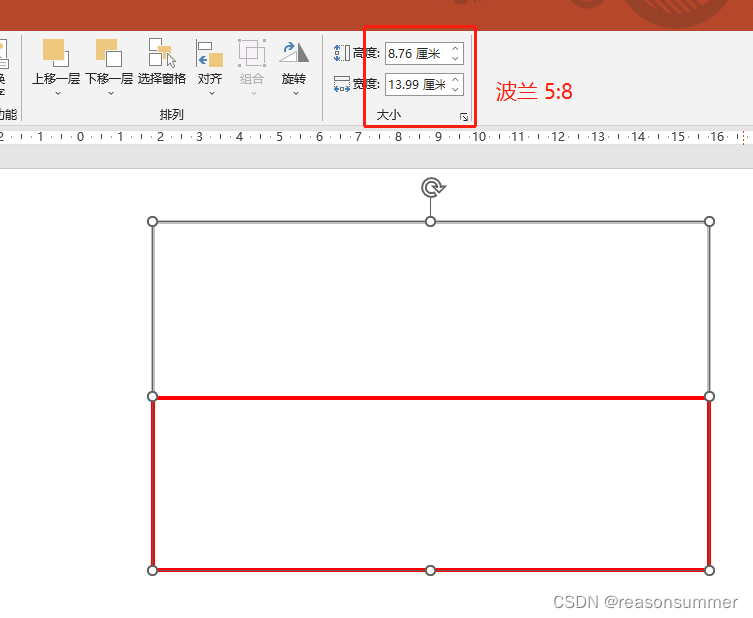
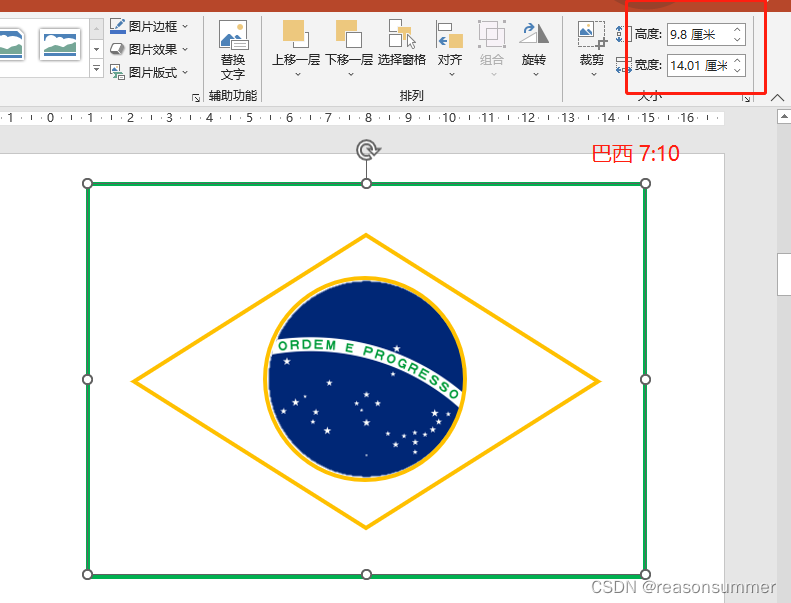
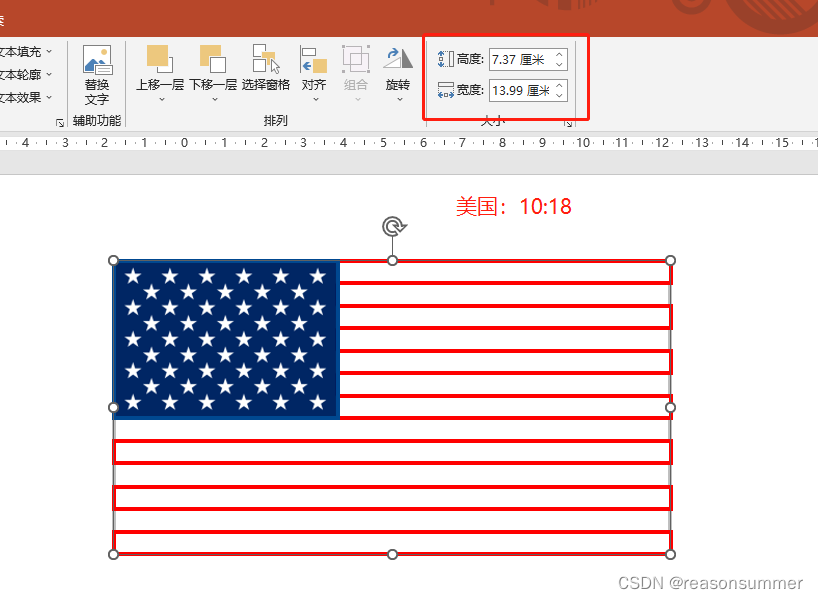
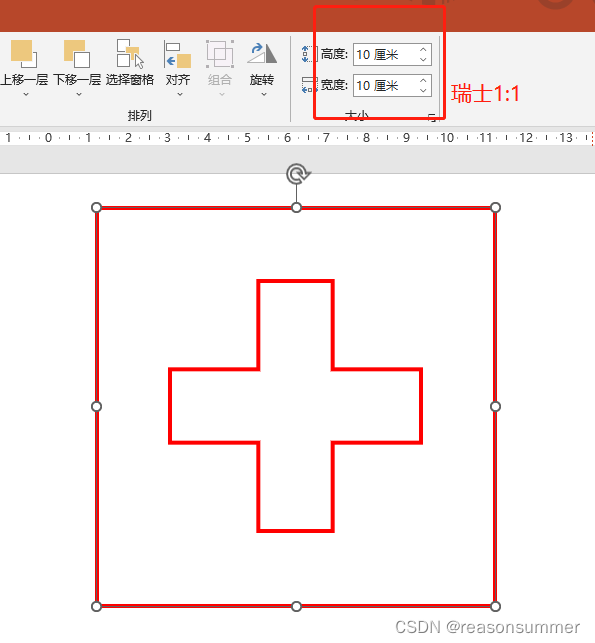
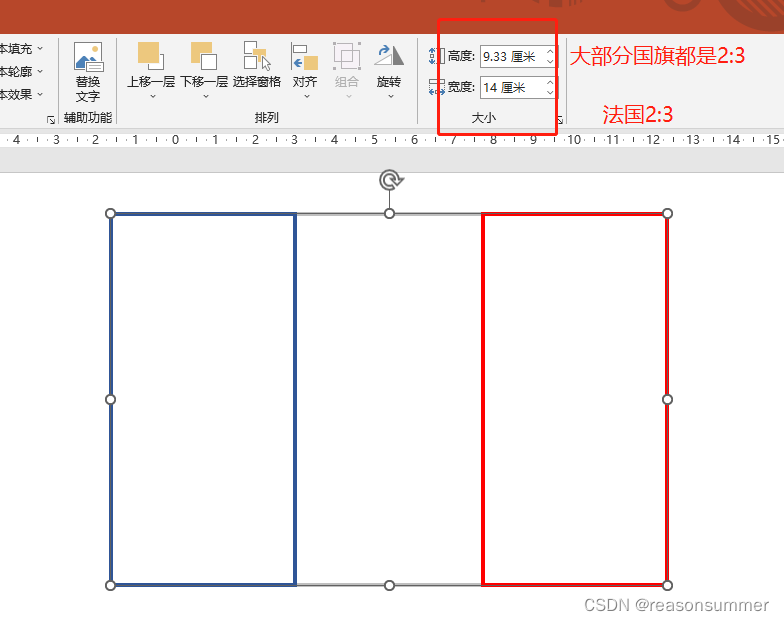
如果单纯用纸条制作旗杆,时间过快,所以用PPT把16强国旗上主要色块做色卡,让幼儿进行简单的涂色。
(国徽标志、星星由于太过细小,蜡笔根本涂不到这些细节,所以都保留彩色图案,只需要幼儿涂大色块)

为了便于抽取国家名称,所有的图片名字格式“国家-1国旗X比X.png"
里面的“-”很重要,是抽取文字的一个节点,必须在国家名称后面加一个“-”,否则无法提取国旗对应的名字。

代码设计:
'''
作者:阿夏
时间:2022年12月04日世界杯16强国旗(定量32张,每个国家2份)
'''
import os,random
num=int(input('生成多少份32份\n'))
# Number=int(input('抽取几个16强国旗图片(1个)\n'))
print('----------第1步:提取所有的16强国旗图片的路径------------')
path = r'C:\Users\jg2yXRZ\OneDrive\桌面\16强国旗\16强国旗图片' #文件夹目录
files= os.listdir(path) #得到文件夹下的所有文件名称 ['塞内加尔国旗2比3.png','澳大利亚国旗2比1.png']
print(files)
lists=[] # 所有图片路径的集合
for f in files:
a='{}\{}'.format(path,f) # 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\16强国旗\\16强国旗图片\\塞内加尔国旗2比3.png'
lists.append(a)
lists.append(a)
print(lists)
# ['C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\16强国旗\\16强国旗图片\\塞内加尔国旗2比3.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\16强国旗\\16强国旗图片\\巴西国旗7比10.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\16强国旗\\16强国旗图片\\法国国旗2比3.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\16强国旗\\16强国旗图片\\波兰国旗5比8.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\16强国旗\\16强
# 国旗图片\\澳大利亚国旗2比1.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\16强国旗\\16强国旗图片\\美国国旗10比19.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\16强国旗\\16强国旗图片\\英格兰国旗3比
# 5.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\16强国旗\\16强国旗图片\\荷兰国旗2比3.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\16强国旗\\16强国旗图片\\葡萄牙国旗2比3.png', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\16强国旗\\16强国旗图片\\阿根廷国旗3比5.png']
print('----------第2步:新建一个临时文件夹------------')
# 新建一个”装N份word和PDF“的文件夹
os.mkdir(r'C:\Users\jg2yXRZ\OneDrive\桌面\16强国旗\零时Word')
print('----------第3步:随机抽取16个国旗1个 ------------')
from win32com.client import constants,gencache
from win32com.client.gencache import EnsureDispatch
from win32com.client import constants # 导入枚举常数模块
import os,time
import docx
from docx import Document
from docx.shared import Inches,Cm,Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor
for nn in range(0,len(lists)):
# word = gencache.EnsureDispatch('Word.Application')
doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\16强国旗\16强国旗(模板).docx')# 打开带docx模板(这个模板有页脚的页码,阿夏认为页码是必须的)
table = doc.tables[0] # 一共有1个表格
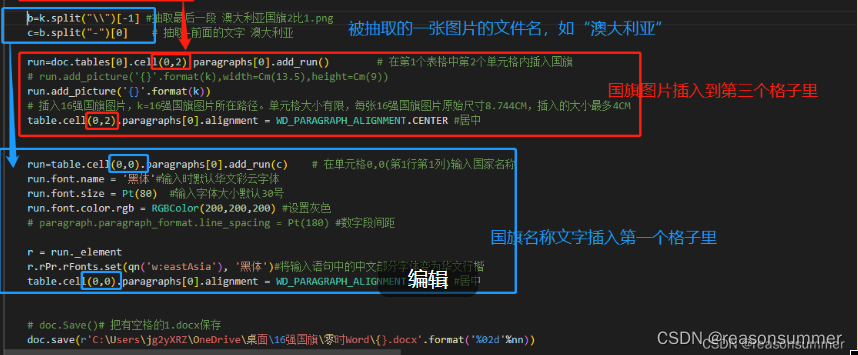
k = lists[nn] # 随机抽取8个不重复空心图案 # C:\Users\jg2yXRZ\OneDrive\桌面\16强国旗\16强国旗图片\澳大利亚国旗2比1.png
b=k.split("\\")[-1] #抽取最后一段 澳大利亚国旗2比1.png
c=b.split("-")[0] # 抽取-前面的文字 澳大利亚
run=doc.tables[0].cell(0,2).paragraphs[0].add_run() # 在第1个表格中第2个单元格内插入国旗
# run.add_picture('{}'.format(k),width=Cm(13.5),height=Cm(9))
run.add_picture('{}'.format(k))
# 插入16强国旗图片,k=16强国旗图片所在路径。单元格大小有限,每张16强国旗图片原始尺寸8.744CM,插入的大小最多4CM
table.cell(0,2).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
run=table.cell(0,0).paragraphs[0].add_run(c) # 在单元格0,0(第1行第1列)输入国家名称
run.font.name = '黑体'#输入时默认华文彩云字体
run.font.size = Pt(80) #输入字体大小默认30号
run.font.color.rgb = RGBColor(200,200,200) #设置灰色
# paragraph.paragraph_format.line_spacing = Pt(180) #数字段间距
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷
table.cell(0,0).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
# doc.Save()# 把有空格的1.docx保存
doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\16强国旗\零时Word\{}.docx'.format('%02d'%nn))
from docx2pdf import convert
# docx 文件另存为PDF文件
inputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/16强国旗/零时Word/{}.docx".format('%02d'%nn) # 要转换的文件:已存在
outputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/16强国旗/零时Word/{}.pdf".format('%02d'%nn) # 要生成的文件:不存在
# 先创建 不存在的 文件
f1 = open(outputFile, 'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfFileMerger
target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/16强国旗/零时Word'
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfFileMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/16强国旗/(打印合集)16强国旗A4整张({}份).pdf".format(num))
file_merger.close()
# doc.Close()
# print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/16强国旗/零时Word') #递归删除文件夹,即:删除非空文件夹
重点说明:
输入数据
只要填写份数(16*2=32张)
运行过程
国旗图片的路径

合成PDF
随后删除过渡信息
一、提取所有图片的路径

二、抽图片,及图片上的文字,填入相应的格子里

效果展示:

实现目标:
1、用这一份代码生成的PDF,让我找到了缺失的三个国家国旗,补打印。
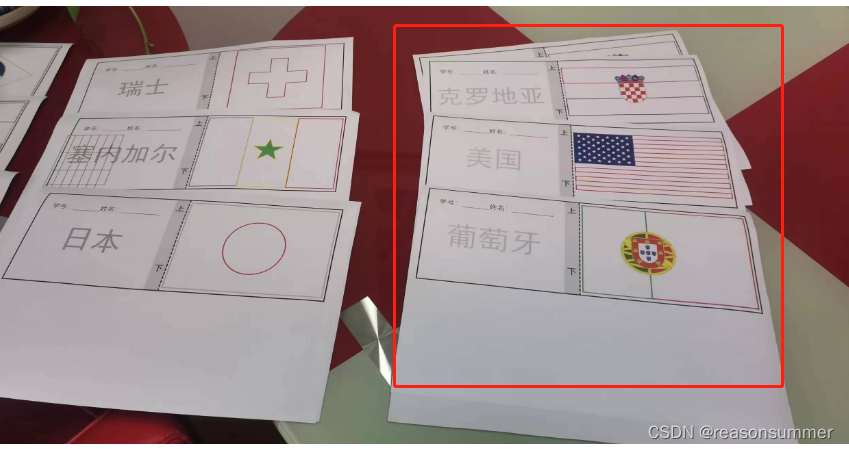 2、这份代码PDF可以直接打印,确保16国旗都有,并且每份2张。发的时候。同桌的孩子可以选一样的2张,互相讨论画法。
2、这份代码PDF可以直接打印,确保16国旗都有,并且每份2张。发的时候。同桌的孩子可以选一样的2张,互相讨论画法。
感悟:
还是老老实实按照列表索引一个个抽取写入图案吧。
![[附源码]Python计算机毕业设计Django松林小区疫情防控信息管理系统](https://img-blog.csdnimg.cn/9752c7186f504ccda539b9fdd8bb603d.png)








![[ 红队知识库 ] 常见防火墙(WAF)拦截页面](https://img-blog.csdnimg.cn/9a895acff51c4beaa1d36d414afe7470.png)