文章目录
- 一、简介
- 1. XML定义
- 2. 测试
- 3. HTML和XML的区别
- 二、XML基本语法
- 1. 语法规则
- 2. 元素的属性
- 3. CDATA
- 4. DTD文件
- 5. XSD文件
- 三、Java解析XML
- 1. 简介
- 2. 解析XML文件
- 四、Xpath
- 1. 简介
- 2. Xpath的使用
一、简介
1. XML定义
XML(可扩展标记语言)是一种用于编码文档的标准。它是由万维网联盟(W3C)在1998年制定的,目的是让信息能够易于共享、处理和传输。XML 是标记语言,这意味着它用标记(或元素)来描述数据或内容。这些标记是用户定义的,所以 XML 可以用来描述任何类型的数据。比如,你可以创建一个包含“书”和“作者”标记的 XML 文档来描述一个图书库。XML 的重要特性包括:
- 可扩展性:XML 让用户定义自己的标记。这意味着它可以扩展和适应各种应用和信息模型。
- 自我描述性:因为标记是用户定义的,所以 XML 文档通常能描述其包含的信息。
- 机器可读和人类可读:XML 的另一个优点是它同时易于机器处理和人类阅读。
- 开放标准:XML 是由 W3C 制定的开放标准,这意味着它在全球范围内被广泛接受和使用。
XML 在很多地方都有应用,包括网页开发、科学数据交换、音频视频处理、电子商务等。由于它的可扩展性和自我描述性,XML 是一种非常强大的工具,能够适应各种数据描述和交换的需要。它最重要的功能就是数据传输、配置文件和存储数据(数据不多时,充当小型数据库)
2. 测试
下面写一个简单的XML文件
<user>jack</user>
<msg>超级大帅哥</msg>
然后用浏览器打开这个文件查看是否有错误

发现出现了错误,因为所有的xml都必须有一个根节点
<root>
<user>jack</user>
<msg>超级大帅哥</msg>
</root>

3. HTML和XML的区别
- HTML标签不能自定义,XML标签必须自定义
- HTML语法要求不严格,XML标签要求极其严格,必须是成对标签
- XML用来传输或存储数据,HTML用来展示数据
二、XML基本语法
1. 语法规则
(1)xml必须有根节点(根节点就是其他所有节点的父节点)

(2)XMl头声明:不强制要求可有可无(建议写)
<?xml version="1.0" encoding="utf-8" ?>
- version:xml版本
- encoding:编码类型
(3)所有xml元素都必须是成对标签
(4)标签名区分大小写
(5)XML中注释和HTML注释是一样的
(6)特殊字符使用实体转义(如< 为$lt;)
xml中需要转义的字符
| $lt; | < | less than |
|---|---|---|
| > | > | greater than |
| & | & | ampersand |
| ' | ' | apostrophe |
| " | " | quotation mark |
2. 元素的属性
属性就是描述标签额外信息的

一个标签可以有多个属性,属性的值必须使用引号引起来,属性的命名规则:数字字母下划线(数字不能开头)
3. CDATA
如下面代码,存在很多需要转义的字符,如果手动转义,则工作量特别大,这时候CDATA就派上的用场:
<?xml version="1.0" encoding="utf-8" ?>
<root>
<man>
<name>张杰</name>
<msg>世界上最好的大学是什么:如果2<4 ,但是4>5,7<3</msg>
</man>
<man>
<name age="38">太白</name>
</man>
</root>

<?xml version="1.0" encoding="utf-8" ?>
<root>
<man>
<name>张杰</name>
<msg><![CDATA[世界上最好的大学是什么:如果2<4 ,但是4>5,7<3]]></msg>
</man>
<man>
<name age="38">太白</name>
</man>
</root>

CDATA的中括号中的内容不会被解析(CDATA必须大写)
4. DTD文件
前面说到XML的文件的标签都是自定义的,但这会带来一些问题,比如会导致XML内容非常乱等问题,所以我们需要在使用XML时提前定义好XML标签的规范(例如Mybatis的配置文件),而我们配置的规范文件就是DTD文件
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration><!-- 配置 -->
<properties /><!-- 属性 -->
<settings /><!-- 设置 -->
<typeAliases /><!-- 类型命名 -->
<typeHandlers /><!-- 类型处理器 -->
<objectFactory /><!-- 对象工厂 -->
<plugins /><!-- 插件 -->
<environments><!-- 配置环境 -->
<environment><!-- 环境变量 -->
<transactionManager /><!-- 事务管理器 -->
<dataSource /><!-- 数据源 -->
</environment>
</environments>
<databaseIdProvider /><!-- 数据库厂商标识 -->
<mappers /><!-- 映射器 -->
</configuration>
下面实现简单的DTD文件
<!ELEMENT students (student*)>
<!ELEMENT student (name,age)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT name (#PCDATA)>
上面表示,studetns标签下只能有student标签,student标签下有name和age标签,然后age和name的数据类型都是String,然后演示一下使用我们自己的dtd文件
<?xml version="1.0" encoding="utf-8" ?>
<!--引入dtd文件-->
<!DOCTYPE students SYSTEM "test1.dtd">
<students>
<student>
<name></name>
<age></age>
</student>
</students>
5. XSD文件
XSD,即xml结构定义,XSD时DTD的替代品,所以XSD的作用和DTD的作用是一样的,只是XSD的用法更加的高端。XML Schema Definition (XSD) 用于描述和验证 XML 文档的结构。它提供了一种规定 XML 文档必须如何看起来(哪些元素可以存在、它们的顺序、一个元素可以有多少个子元素等等)的方式。具体而言,你可以用 XSD 来定义:
- 元素和属性可以出现的位置和次数
- 元素和属性的数据类型
- 元素和属性的默认值和固定值
以下是 XSD 的一些基本语法:
声明元素: xsd:element 用于声明一个元素。
<xsd:element name="elementName" type="dataType"/>
声明属性: xsd:attribute 用于声明一个属性。
<xsd:attribute name="attributeName" type="dataType"/>
声明复杂元素: xsd:complexType 可用于声明复杂元素,这些元素包含其他元素和/或属性。
<xsd:complexType name="complexTypeName">
<!-- definitions of elements and/or attributes -->
</xsd:complexType>
声明简单元素: xsd:simpleType 可用于声明简单元素,这些元素只包含文本。
<xsd:simpleType name="simpleTypeName">
<!-- definition of text type -->
</xsd:simpleType>
现在让我们看一个完整的示例,假设我们有以下 XML 文档:
<?xml version="1.0" encoding="utf-8" ?>
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note>
一个对应的 XSD 可能如下:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:element name="note">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="to" type="xsd:string"/>
<xsd:element name="from" type="xsd:string"/>
<xsd:element name="heading" type="xsd:string"/>
<xsd:element name="body" type="xsd:string"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>
在此 XSD 中,我们定义了一个名为 “note” 的复杂元素,它包含四个子元素:to、from、heading 和 body。所有这些元素都是字符串类型,并且它们必须按照在 xsd:sequence 中指定的顺序出现。要在 XML 文档中引用或链接到相应的 XSD 文件,你需要在 XML 文档的顶部使用 xmlns (XML 命名空间) 属性以及 xsi:schemaLocation 或 xsi:noNamespaceSchemaLocation 属性。如果 XSD 文件与 XML 文档在同一个命名空间,你可以使用 xsi:noNamespaceSchemaLocation 属性:
<?xml version="1.0" encoding="UTF-8"?>
<note xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="note.xsd">
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note>
在上面的例子中,XSD 文件名为 “note.xsd”,并且它位于与 XML 文档相同的目录下。如果 XSD 文件和 XML 文档在不同的命名空间,你需要使用 xsi:schemaLocation 属性,并定义你的命名空间:
<?xml version="1.0" encoding="UTF-8"?>
<note xmlns="http://www.example.com"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.example.com note.xsd">
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note>
在上述例子中,我们定义了一个命名空间 “http://www.example.com” 并将它与 XSD 文件 “note.xsd” 关联起来。注意,命名空间的 URL 不需要是真实的 URL,它只是一个命名空间标识符。
三、Java解析XML
1. 简介
解析XML文件共有四种方式:
- DOM解析:解析XML时,把文档中的所有元素按照其出现的层次关系,在内存中构造出树形结构。其优点是可以遍历和修改节点的内容,但内存压力较大,解析较慢。(性能不好)
- SAX解析:是一种XML解析的替代方法,相对比DOM方式速度更快,更有效。其特点是不能修改节点内容(性能第二)。SAX 是一种基于事件的解析器,按照 XML 文档从头到尾的顺序解析。它在读取文档时触发一系列事件(如开始文档,开始元素,结束元素,结束文档等),并调用预定义的方法来处理这些事件。由于它不需要加载整个文档到内存,所以内存占用较少,适合大型文档的解析。
- JDOM解析:它仅使用具体的类,而不用接口(不灵活且性能不好)。JDOM 是 Java 特有的 XML 解析器,它结合了 SAX 和 DOM 的优点。JDOM 使用具体类而非接口,简化了 DOM 的复杂性,并且提供了更直观的方法来操作 XML。JDOM 能将 XML 文档加载到内存中,提供了一种基于树形结构的方式来访问和修改数据,但是同样的,对于大型文档,可能会导致内存占用过多。
- DOM4J解析:是JDOM的一种的智能分支,合并了许多超出基本XML文档的功能,例如Hibernate就使用DOM4J解析(性能最高)DOM4J 是一个开源的 Java XML 解析器,类似于 JDOM,它结合了 DOM 和 SAX 的优点。DOM4J 提供了灵活的 API 和良好的性能,适合在 Java 应用程序中处理复杂的 XML 文档。它可以在任何时候切换到事件驱动的处理方式,这意味着它可以处理非常大的文档,而不会消耗大量内存。
前两种方法是基础方法,为官方提供的(与平台无关)。后两种属于扩展方法,是在基础方法上扩展出来的,只适用于Java平台
2. 解析XML文件
定义XML文件
<?xml version="1.0" encoding="UTF-8" ?>
<students>
<student>
<id>1</id>
<name>kobe</name>
<age>23</age>
</student>
<student>
<id>2</id>
<name>james</name>
<age>24</age>
</student>
</students>
使用DOM4J解析XML(使用前需要到mvn仓库中下载相关的jar包)
public static void main(String[] args) throws DocumentException {
//1. 加载XML文件到jvm中,形成数据流
InputStream resourceAsStream = TestXML_1.class.getClassLoader().getResourceAsStream("xml/4.xml");
//2. 创建解析对象
SAXReader saxParser= new SAXReader();
//3. 获得整个文档对象(整个xml文件)[将数据流转换为一个文档对象]
Document read = saxParser.read(resourceAsStream);
//4. 首先读取根节点
Element rootElement = read.getRootElement();
//5. 获得根元素下的所有子元素
List<Element> elements = rootElement.elements();
elements.forEach(s-> System.out.println(s));
for (Element element : elements) {
List<Element> elements1 = element.elements();
for (Element element1 : elements1) {
System.out.println(element1.getName()+":"+element1.getData());
}
}
}

解析属性
<students>
<student type="usa" color="black">
<id>1</id>
<name>kobe</name>
<age>23</age>
</student>
<student type="china" color="yellow">
<id>2</id>
<name>guoailun</name>
<age>24</age>
</student>
</students>
public class TestXML_1 {
public static void main(String[] args) throws DocumentException {
//1. 加载XML文件到jvm中,形成数据流
InputStream resourceAsStream = TestXML_1.class.getClassLoader().getResourceAsStream("xml/4.xml");
//2. 创建解析对象
SAXReader saxParser= new SAXReader();
//3. 获得整个文档对象(整个xml文件)[将数据流转换为一个文档对象]
Document read = saxParser.read(resourceAsStream);
//4. 首先读取根节点
Element rootElement = read.getRootElement();
//5. 获得根元素下的所有子元素
List<Element> elements = rootElement.elements();
for (Element element : elements) {
System.out.println(element);
Attribute type = element.attribute("type");
System.out.println("type:"+type.getValue());
}
}
}

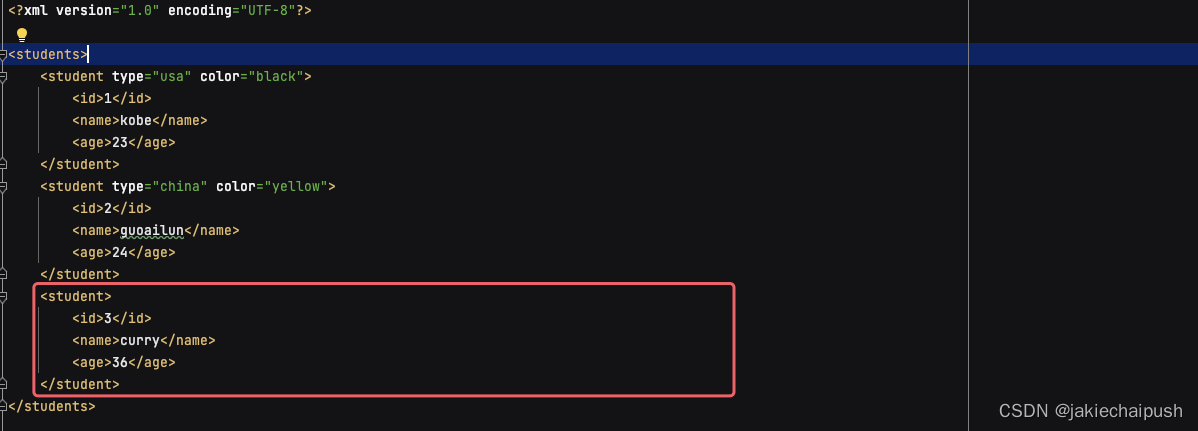
使用java程序添加XML元素
public static void main(String[] args) throws DocumentException, IOException {
//1. 加载XML文件到jvm中,形成数据流
InputStream resourceAsStream = TestXML_1.class.getClassLoader().getResourceAsStream("xml/4.xml");
//2. 创建解析对象
SAXReader saxParser= new SAXReader();
//3. 获得整个文档对象(整个xml文件)[将数据流转换为一个文档对象]
Document read = saxParser.read(resourceAsStream);
//4. 首先读取根节点
Element rootElement = read.getRootElement();
//5. 创建元素节点
Element student = rootElement.addElement("student");
Element id = student.addElement("id");
Element name = student.addElement("name");
Element age = student.addElement("age");
id.setText("3");
name.setText("curry");
age.setText("36");
//6. 写入到xml文件
FileOutputStream out=new FileOutputStream(new File("/Users/jackchai/Desktop/自学笔记/java项目/leetcode/leetcodetest/src/xml/4.xml"));
OutputFormat format=new OutputFormat("\t",true,"UTF-8");
XMLWriter writer=new XMLWriter(out,format);
writer.write(read);
writer.close();
}
四、Xpath
1. 简介
xpath是一门在xml文档中快速查找信息的方式。单纯使用Dom4j时只能一层层的获取并处理元素,有了xpath之后,访问层级的节点就很简单了
2. Xpath的使用
导入依赖包
解析方法
public class TestXML_1 {
public static void main(String[] args) throws DocumentException, IOException {
//1. 加载XML文件到jvm中,形成数据流
InputStream resourceAsStream = TestXML_1.class.getClassLoader().getResourceAsStream("xml/4.xml");
//2. 创建解析对象
SAXReader saxParser= new SAXReader();
//3. 获得整个文档对象(整个xml文件)[将数据流转换为一个文档对象]
Document read = saxParser.read(resourceAsStream);
//4. 首先读取根节点
Element rootElement = read.getRootElement();
//5. 获取所有学生信息
List<Node> student = rootElement.selectNodes("student");
student.forEach(s-> System.out.println(s));
//6. 获得所有学生的名字
List<Node> nodes = rootElement.selectNodes("student/name");//也可以使用"//name":忽略层级和位置只获取name标签
nodes.forEach(s-> System.out.println(((Element)s).getData()));
//7. 获得第一个学生信息
List<Node> node = rootElement.selectNodes("student[1]");
System.out.println(node);
//8. 获得所有带有type属性的学生的名字
List<Node> node3 = rootElement.selectNodes("student[@type]/name");
//9. 获得指定属性值的学生
List<Node> node4 = rootElement.selectNodes("student[@type=\"usa\"]/name");
//10. 获得年龄超过30的学生
List<Node> node8 = rootElement.selectNodes("student[age>22]/name");
System.out.println("123"+node8);
}
}