👨💻 作者简介:程序员半夏 , 一名全栈程序员,擅长使用各种编程语言和框架,如JavaScript、React、Node.js、Java、Python、Django、MySQL等.专注于大前端与后端的硬核干货分享,同时是一个随缘更新的UP主. 你可以在各个平台找到我!
🏆 本文收录于专栏: 零基础学机器学习
🔥 专栏介绍: 本专栏将帮助您了解机器学习、其工作原理以及如何使用它。本教程包含以下内容:监督和无监督学习、线性回归、随机森林算法、朴素贝叶斯分类器、K-means聚类算法等等等基础学习基础知识,以及各种实战案例。

文章目录
- 回顾监督学习?
- 什么是分类?
- 什么是分类算法?
- 分类问题中的学习方法
- 懒惰学习方法(消极学习方法)
- 急切学习方法(积极学习方法)
- 机器学习中的四种分类任务
- 分类预测建模
- 二元分类 - Binary Classification
- 多类分类 - Multi-Class Classification
- 多标签分类 - Multi-Label Classification
- 不平衡分类 - Imbalanced Classification
- 常见分类算法
- 1. 逻辑回归
- 2. 朴素贝叶斯算法
- 3. K-最近邻算法
- 4. 决策树算法
- 5. 随机森林算法
- 6. 支持向量机算法
- 常用分类器
- 朴素贝叶斯
- 决策树
- K最近邻算法
- 评估分类模型
- 1. 混淆矩阵
- 2. Log Loss 或交叉熵损失函数
- 3. AUC-ROC 曲线
- 分类算法的应用场景
- 分类器评估
- 交叉验证
- 留出法
- ROC曲线
- 偏差
- 方差
- 精度和召回率
- 选择合适的算法
- 常见问题
- 知识普及-算法和模型
想象一下打开你的橱柜,发现所有东西都混乱不堪。你会发现取需要的东西非常困难和耗时。如果一切都被分组,那就会变得非常简单。这就是机器学习分类算法的作用。
回顾监督学习?
在我们深入分类之前,让我们先复习一下监督学习是什么。假设你正在学习数学中的一个新概念,解决一个问题后,你可能会参考答案来确定自己是否正确。一旦你对解决特定类型的问题有信心,你就会停止参考答案,自己独立解决问题。
这也是机器学习模型中监督学习的工作方式。在监督学习中,模型通过示例进行学习。除了输入变量之外,我们还会给模型相应的正确标签。在训练过程中,模型可以查看哪个标签与我们的数据相对应,因此可以找到我们的数据与这些标签之间的模式。
一些监督学习的例子包括:
- 通过教授模型什么是垃圾邮件和非垃圾邮件来进行分类。
- 语音识别,通过教机器识别你的声音。
- 物体识别,向机器展示物体的外观并让它从其他物体中选择该物体。
我们可以进一步将监督学习分为分类和回归:
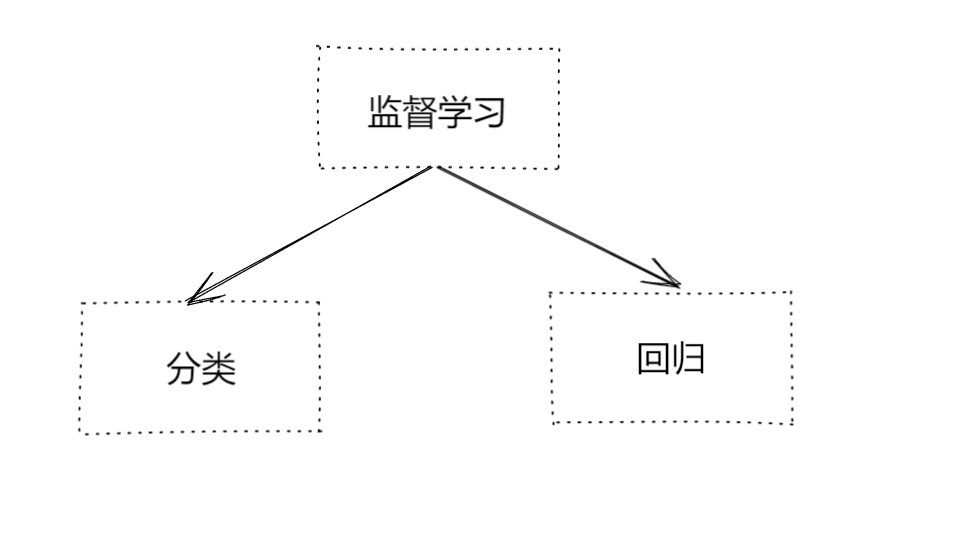
什么是分类?
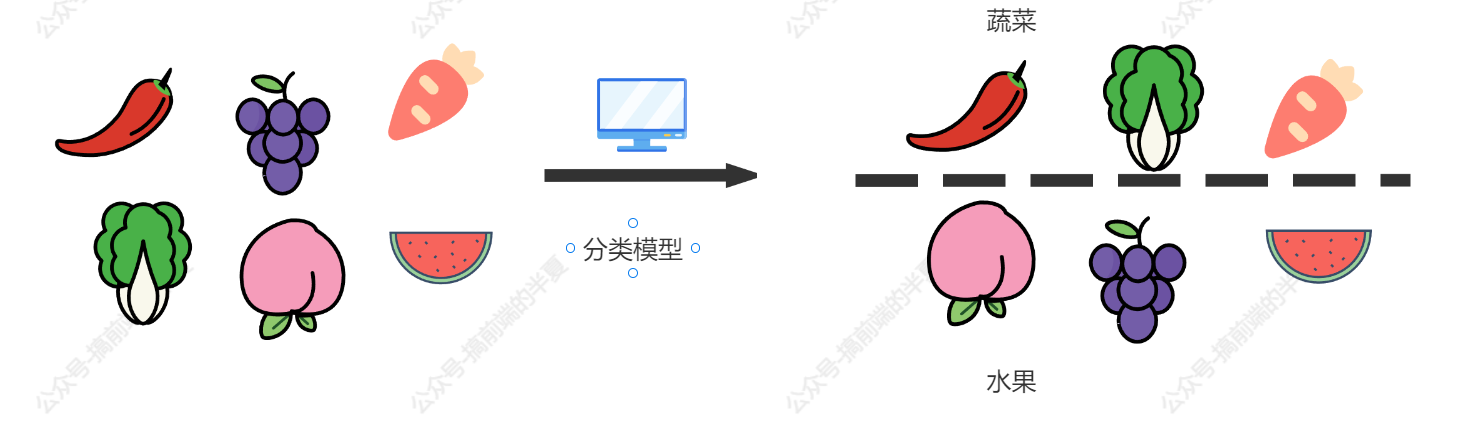
分类被定义为将对象和思想识别、理解和分组到预设类别(也称为“子群体”)的过程。借助这些预分类的训练数据集,机器学习程序中的分类利用各种算法将未来的数据集分类到相应和相关的类别中。
机器学习中使用的分类算法利用输入的训练数据来预测随后的数据可能属于预定类别中的一个的可能性或概率。分类的最常见应用之一是将电子邮件过滤为“垃圾邮件”或“非垃圾邮件”,这是今天顶尖电子邮件服务提供商使用的方法。
简而言之,分类是一种“模式识别”。在这里,应用于训练数据的分类算法在未来的数据集中找到相同的模式(类似的数字序列、单词或情感等)。
我们将详细探讨分类算法,并发现文本分析软件如何执行诸如情感分析之类的操作-用于按意见极性(积极、消极、中性等)对非结构化文本进行分类。
什么是分类算法?
分类算法是一种有监督学习技术,基于训练数据,用于对新数据进行分类。在分类中,程序使用提供的数据集或观测来学习如何将新观测分类为不同的类别或组。例如,0或1、红色或蓝色、是或否、垃圾邮件或非垃圾邮件等。目标、标签或类别都可以用来描述类别。分类算法使用带标签的输入数据,因为它是一种有监督学习技术,包括输入和输出信息。在分类过程中,离散输出函数(y)被转换为输入变量(x)。
简单来说,分类是一种模式识别类型,其中分类算法在训练数据上执行,以发现新数据集中相同的模式。
分类问题中的学习方法
有两种类型的学习者。
懒惰学习方法(消极学习方法)
它首先存储训练数据集,然后等待测试数据集到达。使用懒惰学习方法时,分类是使用训练数据集的最合适数据进行的。花费在训练上的时间较少,但在预测上花费的时间较多。一些例子是基于案例的推理和KNN算法。
急切学习方法(积极学习方法)
在获得测试数据集之前,急切学习方法使用训练数据集构建分类模型。他们花费更多的时间学习,而花费更少的时间预测。一些例子是ANN、朴素贝叶斯和决策树。
机器学习中的四种分类任务
在深入探讨机器学习中的四种分类任务之前,让我们先讨论分类预测建模。
分类预测建模
机器学习中的分类问题是指针对特定输入数据示例预测类标签的问题。
分类问题包括以下内容:
- 给出一个示例并指示它是否为垃圾邮件。
- 将手写字符识别为已识别的字符之一。
- 确定是否将当前用户行为标记为流失。
- 建模方面需要具有大量输入和输出示例的训练数据集。
模型将使用训练数据集确定将输入数据样本映射到某些类标签的最佳方式。因此,训练数据集必须包含每个类标签的大量样本,并且适当代表问题。
在向建模算法提供类标签时,必须首先将字符串值(如“垃圾邮件”或“非垃圾邮件”)转换为数值。常用的标签编码为每个类标签分配一个不同的整数,例如“垃圾邮件”= 0,“非垃圾邮件”= 1。
分类建模问题有许多算法类型,包括预测建模和分类。
根据它们的输出,评估分类预测建模算法。基于预测类标签的分类准确率是评估模型性能的常见统计数据。虽然不是完美的,但分类准确率对于许多分类任务来说是一个合理的起点。
一些任务可能需要为每个示例预测类成员概率,而不是类标签。这增加了预测的不确定性。ROC曲线是评估预期概率的常用诊断方法。
以下是机器学习中的四种不同类型的分类任务:
- 二元分类
- 多类别分类
- 多标签分类
- 不平衡分类
现在,让我们详细看一下它们。
二元分类 - Binary Classification
只有两个类别标签的分类任务被称为二元分类。
例如:
- 转化预测(购买或不购买)。
- 流失预测(流失或不流失)。
- 垃圾邮件检测(垃圾邮件或非垃圾邮件)。
二元分类问题通常需要两个类别,一个代表正常状态,另一个代表异常状态。
例如,正常状态是“非垃圾邮件”,而异常状态是“垃圾邮件”。另一个例子是当涉及到医学测试的任务具有“未检测到癌症”的正常状态和“检测到癌症”的异常状态时。
类别标签0赋予正常状态的类别,而类别标签1赋予异常状态的类别。
通常使用预测每个样本的伯努利概率分布的模型来对二分类任务进行建模。
称为伯努利分布的离散概率分布处理事件有二进制结果0或1的情况。在分类方面,这意味着模型预测示例将属于类别1或异常状态的可能性。
以下是众所周知的二元分类算法:
- 逻辑回归。
- 支持向量机。
- 简单贝叶斯。
- 决策树。
有些算法,如支持向量机和逻辑回归,是专门为二元分类而创建的,不支持多于两个类。
多类分类 - Multi-Class Classification
多类分类是指具有两个以上类别标签的分类任务
例如:
- 人脸分类。
- 分类植物物种。
- 使用光学进行字符识别。
与二元分类相比,多类分类没有正常和异常结果的概念。相反,实例被分组到几个类别之一中。
在某些情况下,类别标签的数量可能相当高。例如,在面部识别系统中,模型可能会预测拍摄属于成千上万张面孔之一。
涉及预测单词序列的问题,例如文本翻译模型,也可以视为一种特殊类型的多类别分类。要预测的单词序列中的每个单词都涉及一个多类别分类,其中词汇的大小定义了可以预测的类别数量,其大小可能是成千上万个单词。
多类分类任务经常使用预测每个示例的多项式概率分布的模型进行建模。
多项式分布涉及具有分类结果的分类事件,例如1,2,3,…,K中的K。在分类方面,这意味着模型预测给定示例将属于某个类别标签的可能性。
对于多类分类,许多二元分类技术是适用的。
以下是可用于多类分类的知名算法:
- 渐进式提升。
- 决策树。
- 最近的K个邻居。
- 粗糙森林。
- 简单贝叶斯。
可以使用为二元分类创建的算法来解决多类分类问题。
为此,使用称为“一对多”或“每对类别一个模型”的方法,其中包括拟合多个二元分类模型,其中每个类别与所有其他类别(称为一对多)相对应。
一对一:为每对类别拟合单个二元分类模型。
以下二元分类算法可以应用这些多类分类技术:
一对多:为每个类别与所有其他类别拟合单个二元分类模型。
以下二元分类算法可以应用这些多类分类技术:
- 支持向量机。
- 逻辑回归。
多标签分类 - Multi-Label Classification
多标签分类是指具有两个或以上分类标签的分类任务,其中每个样本可以预测为一个或多个类别。
以照片分类为例。在这里,模型可以预测照片中存在许多已知的物体,例如“人”,“苹果”,“自行车”等。特定的照片可能在场景中有多个物体。
这与多类分类和二元分类形成了鲜明的对比,后者预测每个出现的单个类标签。
多标签分类问题通常使用预测多个结果的模型进行建模,每个结果都被预测为伯努利概率分布。实质上,这种方法为每个示例预测了几个二元分类。
不可能直接应用于多类或二元分类中使用的多标签分类方法。所谓的算法的多标签版本是传统分类算法的专门版本,包括:
- 多标签梯度提升
- 多标签随机森林
- 多标签决策树
另一种策略是使用不同的分类算法预测类标签。
不平衡分类 - Imbalanced Classification
不平衡分类是指其中每个类别中的示例数不均匀分布的分类任务。大多数训练数据集的实例属于正常类别,而少数属于异常类别,使得不平衡分类任务通常是二元分类任务。
例如:
- 临床诊断程序。
- 异常值检测。
- 欺诈调查。
虽然可能需要独特的方法,但这些问题被建模为二元分类任务。
可以使用专门的策略来改变训练数据集中样本组成,例如过采样少数类或欠采样多数类。
例如:
- SMOTE过采样。
- 随机欠采样。
可以使用专门的建模技术,例如成本敏感的机器学习算法,在拟合训练数据集的模型时更多地考虑少数类。
例如:
- 成本敏感支持向量机。
- 成本敏感决策树。
- 成本敏感逻辑回归。
由于报告分类准确度可能会具有误导性,因此可能需要使用替代性能指标。
例如:
- F-Measure。
- 召回率。
- 精度。
常见分类算法
根据你所处理的数据集,你可以应用许多不同的分类方法。这是因为统计学中的分类研究非常广泛。以下是前五种机器学习算法:
1. 逻辑回归
它是一种监督学习分类算法,可以预测目标变量的可能性。只会有两个类别之间的选择。数据可以编码为1或yes,表示成功,或者0或no,表示失败。使用逻辑回归可以最有效地预测因变量。当预测是分类的,比如真或假,是或否,或0或1时,你可以使用它。逻辑回归可以用来确定一封电子邮件是否是垃圾邮件。
2. 朴素贝叶斯算法
朴素贝叶斯算法可以确定一个数据点是否属于特定类别。它可以用于对文本分析中的短语或单词进行分类,判断它们是否属于预定的分类。
| Text | Tag |
|---|---|
| “一场伟大的游戏” | 体育 |
| “选举结束了” | 不是体育 |
| “多么高分数” | 体育 |
| “一场难忘的游戏” | 体育 |
3. K-最近邻算法
K-最近邻算法是根据数据点最接近的那些点所属的群组来计算数据点加入哪个群组的可能性。在使用K-最近邻算法进行分类时,可以根据最近的邻居来确定数据的分类。
4. 决策树算法
决策树算法可以解决回归和分类问题,但在分类问题方面表现出色。类似于流程图,它将数据点一次分为两个相似的组,从“树干”开始,穿过“分支”和“叶子”,直到类别之间更密切相关。
5. 随机森林算法
随机森林算法是决策树算法的扩展,首先使用训练数据创建多个决策树,然后将新数据适配到其中一个“树”作为“随机森林”。它根据数据的规模将数据平均连接到最近的树数据上。这些模型非常适合解决决策树强制将数据点不必要地归为一类的问题。
6. 支持向量机算法
支持向量机是一种流行的监督机器学习算法,适用于分类和回归问题。它通过使用算法根据极性对数据进行分类和训练,超越了X/Y预测。
常用分类器
分类器是一种机器学习算法,用于将数据分为不同的类别或标签。它通过学习输入数据的特征来预测新数据的类别。分类器可以应用于各种领域,如图像识别、自然语言处理、金融风险评估等。常见的分类器包括朴素贝叶斯分类器、支持向量机、决策树、神经网络等。
朴素贝叶斯
朴素贝叶斯假设数据集中的预测变量是独立的。这意味着它假设特征之间没有关联。例如,如果给定一个香蕉,分类器将会看到这个水果是黄色的、长而且尖,所有这些特征将独立地对它是不是香蕉的概率做出贡献,并且它们不依赖于彼此。朴素贝叶斯基于贝叶斯定理,该定理如下:

其中:
- P(A | B) = 在B发生的情况下A发生的频率
- P(A) = A发生的可能性
- P(B) = B发生的可能性
- P(B | A) = 在A发生的情况下B发生的频率
决策树
决策树是一种用于可视化决策的算法。通过提出一个是/否问题并将答案分裂为其他决策,可以构建决策树。问题在节点上,结果的决策在叶子下方。下面的树用于决定我们是否可以打网球。
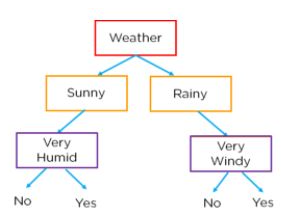
在上图中,根据天气条件、湿度和风速,我们可以系统地决定是否应该打网球。在决策树中,所有错误的语句位于树的左侧,而正确的语句则分支到右侧。知道这一点,我们可以制作一个树,将特征放在节点上,将结果分类放在叶子上。
K最近邻算法
K近邻算法是一种分类和预测算法,它基于数据点之间的距离将数据分成类别。K近邻算法假设彼此相近的数据点必须是相似的,因此,要分类的数据点将与最接近的聚类组合在一起。

评估分类模型
在我们的模型完成后,我们必须评估其性能以确定它是回归模型还是分类模型。因此,我们有以下选项来评估分类模型:
1. 混淆矩阵
混淆矩阵(Confusion Matrix),也称误差矩阵(Error Matrix),是用于评估分类模型性能的一种矩阵。它是一个二维矩阵,其中行代表实际类别,列代表预测类别。在混淆矩阵中,每个元素表示在实际类别和预测类别之间的匹配情况,即分类器预测正确和错误的情况。
混淆矩阵的四个元素分别为:
真正例(True Positive,TP):实际类别为正例,预测类别也为正例。
假负例(False Negative,FN):实际类别为正例,预测类别为负例。
假正例(False Positive,FP):实际类别为负例,预测类别为正例。
真负例(True Negative,TN):实际类别为负例,预测类别也为负例。
混淆矩阵可以用于计算分类模型的准确率、召回率、F1值等指标,从而对分类模型的性能进行评估和优化。
2. Log Loss 或交叉熵损失函数
Log Loss 或交叉熵损失函数用于评估分类器的性能,输出结果是介于 1 和 0 之间的概率值。
具体来说,对于一个二分类问题,Log Loss 可以定义为:
− 1 N ∑ i = 1 N ( y i log ( p i ) + ( 1 − y i ) log ( 1 − p i ) ) -\frac{1}{N}\sum_{i=1}^{N}(y_i\log(p_i)+(1-y_i)\log(1-p_i)) −N1i=1∑N(yilog(pi)+(1−yi)log(1−pi))
其中, N N N 是样本数量, y i y_i yi 是第 i i i 个样本的真实标签(0 或 1), p i p_i pi 是模型预测该样本为正类的概率。
Log Loss 的值越小,表示模型的性能越好。当模型的预测结果与真实标签完全一致时,Log Loss 的值为 0。当模型的预测结果与真实标签完全相反时,Log Loss 的值为无穷大。
Log Loss 在深度学习中经常被用作分类问题的损失函数,特别是在二分类问题中。它的优点是能够对预测概率进行连续性建模,从而更好地反映模型的性能。
3. AUC-ROC 曲线
AUC-ROC曲线是评估分类模型性能的一种常用方法,它是指在二分类问题中,绘制出真阳性率(TPR)与假阳性率(FPR)之间的关系曲线。其中,TPR是指真正例被正确分类的比例,即TPR=TP/(TP+FN),其中TP表示真正例的个数,FN表示假反例的个数;而FPR是指假正例被错误分类的比例,即FPR=FP/(FP+TN),其中FP表示假正例的个数,TN表示真反例的个数。
AUC-ROC曲线的面积(AUC)越接近1,说明模型的性能越好;而AUC越接近0.5,说明模型的性能越差,相当于随机猜测。因此,AUC-ROC曲线是评估分类模型性能的重要指标之一,可以用于比较不同模型的性能,选择最优模型。
分类算法的应用场景
分类算法有许多应用场景,以下是其中的一些:
- 语音识别
- 垃圾邮件检测
- 药物分类
- 癌症肿瘤细胞识别
- 生物识别等
分类器评估
在分类器完成后,验证分类器的准确性和有效性是最关键的一步。我们可以用多种方式来评估分类器。让我们从交叉验证开始,看看下面列出的这些技术。
交叉验证
交叉验证是一种常用的分类器评估方法,它将数据集分成许多个子集,每次使用其中一个子集作为测试集,其他子集作为训练集。这样可以避免对某一特定的数据集过拟合,提高了分类器的泛化能力。
常见的交叉验证方法包括k折交叉验证和留一交叉验证。k折交叉验证将数据集分成k个子集,每次使用其中一个子集作为测试集,其他子集作为训练集。留一交叉验证是k折交叉验证的特殊情况,即将数据集分成n个子集,每次使用其中一个样本作为测试集,其他样本作为训练集。
交叉验证可以用来评估分类器的性能,比如准确率、精确率、召回率和F1值等指标。通过多次交叉验证,可以得到分类器的平均性能指标,从而更加准确地评估分类器的性能。
留出法
留出法是一种常用的分类器评估方法,它将数据集划分为训练集和测试集两部分,其中训练集用于训练分类器,测试集用于评估分类器的性能。每个集合分别包含总数据的20%和80%。
具体步骤如下:
-
将原始数据集随机划分为训练集和测试集,通常采用70%的数据作为训练集,30%的数据作为测试集。
-
在训练集上训练分类器,得到分类模型。
-
在测试集上测试分类器的性能,通常采用准确率、精确率、召回率、F1值等指标来评估分类器的性能。
-
重复上述步骤多次,取平均值作为最终的评估结果。
留出法的优点是简单易行,适用于数据量较小的情况,但也存在一些缺点,如划分不合理可能导致评估结果不准确,同时训练集和测试集的划分可能会影响评估结果的稳定性。
ROC曲线
ROC曲线是一种用于评估分类器性能的图形化工具。ROC曲线的横轴是假正率(False Positive Rate),纵轴是真正率(True Positive Rate),其中:
- 假正率是指实际为负样本但被分类器错误地判定为正样本的样本数占所有实际为负样本的样本数的比例;
- 真正率是指实际为正样本且被分类器正确地判定为正样本的样本数占所有实际为正样本的样本数的比例。
ROC曲线的绘制过程是:对于不同的分类阈值,计算出对应的假正率和真正率,然后将这些点连接起来形成曲线。ROC曲线越靠近左上角,代表分类器的性能越好,因为此时假正率较低而真正率较高。
ROC曲线的面积(Area Under Curve,简称AUC)可以用来衡量分类器的整体性能。AUC越大,代表分类器的性能越好。当AUC等于0.5时,代表分类器的性能等同于随机猜测,没有任何预测能力。
偏差
是指评估方法本身的缺陷或限制,导致评估结果与实际情况存在一定的偏差。常见的偏差包括:
偏差是实际值和预测值之间的差异。偏差是模型对数据进行预测的简单假设。它直接对应于我们数据中发现的模式。当偏差高时,模型所做的假设过于基础,无法捕捉我们数据的重要特征,这称为欠拟合。
方差
我们可以将方差定义为模型对数据波动的敏感度。我们的模型可能会从噪声中学习,这会导致模型将无关紧要的特征视为重要。当方差很高时,我们的模型将捕捉到所给定数据的所有特征,会自我调整到数据上,并能够很好地进行预测,但是新数据可能没有完全相同的特征,模型就无法很好地进行预测。我们称之为过度拟合。
精度和召回率
精度(precision)指分类器正确预测为正样本的样本数占所有预测为正样本的样本数的比例。即:
精度 = 正确预测为正样本的样本数 / 所有预测为正样本的样本数
召回率(recall)指分类器正确预测为正样本的样本数占所有实际为正样本的样本数的比例。即:
召回率 = 正确预测为正样本的样本数 / 所有实际为正样本的样本数
在分类任务中,精度和召回率往往是相互矛盾的。如果一个分类器将所有样本都预测为正样本,则召回率为100%,但精度很低;如果一个分类器只预测一小部分样本为正样本,则精度很高,但召回率很低。因此,需要综合考虑精度和召回率,通常使用F1值作为评价指标。F1值是精度和召回率的调和平均数,即:
F1 = 2 * 精度 * 召回率 / (精度 + 召回率)
F1值越高,分类器的性能越好。
选择合适的算法
除了上述策略之外,我们还可以应用以下程序来选择模型的最优算法。
- 根据我们的自变量和因变量特征,创建自变量和因变量数据集。
- 为数据创建训练集和测试集。
- 利用多种算法来训练模型,包括SVM,决策树,KNN等。
- 考虑分类器。
- 决定最准确的分类器。
- 准确性是使模型高效的最佳路径,即使选择模型的最优算法可能需要更长的时间。
常见问题
- 什么是分类算法?能否举个例子?
分类算法是指预测特定输入数据示例的类别标签。例如,它可以识别某个代码是否为垃圾邮件,可以对手写字母进行分类。 - 哪种分类算法最好?
与逻辑回归、支持向量机和决策回归等其他分类算法相比,朴素贝叶斯分类器算法能够产生更好的结果。 - 最简单的分类算法是什么?
最简单的分类技术之一是kNN。 - 什么是分类和分类的类型?
分类是将对象分组或分类到系统中的类别或分区。你可以遇到以下四种分类任务类别:二元分类、多类分类、多标签分类和不平衡分类。 - 分类和聚类之间有什么区别?
聚类的目标是通过考虑最令人满意的标准来将相似类型的项目分组,该标准规定同一组中的任何两个项目都不应该可比较。这与分类不同,分类的目标是预测目标类。
知识普及-算法和模型
算法和模型是机器学习中两个重要的概念,它们有以下区别:
- 定义:算法是一组指令或步骤,用于解决特定问题的计算方法。而模型是用于描述和预测数据的数学表达式或函数。
- 目的:算法的目的是通过数据处理和分析来解决问题,而模型的目的是预测或描述数据的行为。
- 实现:算法通常是一个程序或函数,可以直接应用于数据,而模型通常需要在训练数据上进行训练和优化,然后才能应用于新数据。
- 范围:算法可以是通用的,也可以是特定领域的,而模型通常是针对特定问题或领域设计的。
举例说明:
举例来说,决策树算法是一种用于分类和预测的算法,它使用一系列的规则和条件来判断输入数据的类别。而决策树模型则是一个基于决策树算法创建的预测函数,它可以将新的输入数据映射到正确的类别中。
另一个例子是线性回归算法,它用于预测连续的数值输出。线性回归模型则是一个基于线性回归算法创建的数学函数,它可以预测输入数据的输出值。