文章目录
- 0x0. 前言
- 0x1. Megatron-LM GPT2
- 使用原始的 Megatron-LM 训练 GPT2
- 设置训练数据
- 运行未修改的Megatron-LM GPT2模型
- 开启DeepSpeed
- 参数解析
- 初始化和训练
- 初始化
- 使用训练API
- 前向传播
- 反向传播
- 更新模型参数
- 损失缩放
- 检查点保存和加载
- DeepSpeed Activation Checkpoints(可选)
- 训练脚本
- DeepSpeed 使用 GPT-2 进行评估
- 0x2. Zero Redundancy Optimizer (零冗余优化器)
- Zero概述
- 训练环境
- 开启Zero优化
- 训练一个1.5B参数的GPT2模型
- 训练一个10b的GPT-2模型
- 使用ZeRO-Infinity训练万亿级别的模型
- 使用ZeRO-Infinity将计算转移到CPU和NVMe
- 分配大规模Megatron-LM模型
- 以内存为中心的分块优化
- 提取权重
- 0x3. Zero-Offload
- ZeRO-Offload概述
- 训练环境
- 在单个 V100 GPU 上训练10B的GPT2模型
- Megatron-LM GPT-2 的启动脚本更改:
- DeepSpeed 配置更改
- 0x4. 总结
0x0. 前言
这篇文章主要翻译DeepSpeed的Megatron-LM GPT2 ,Zero零冗余优化器技术,ZeRO-Offload技术。关于DeepSpeed 的Zero和ZeRO-Offload的技术原理大家也可以查看图解大模型训练之:数据并行下篇(ZeRO,零冗余优化) 这篇文章,文章里面对内存的计算和通信量的分析都很棒。
0x1. Megatron-LM GPT2
如果你还没有阅读过入门指南,我们建议你在开始本教程之前先阅读该指南(https://www.deepspeed.ai/getting-started/ 这个指南的翻译在 【DeepSpeed 教程翻译】开始,安装细节和CIFAR-10 Tutorial)。
在本教程中,我们将向 Megatron-LM GPT2 模型添加 DeepSpeed,Megatron-LM GPT2 是一个大而强的 transformer。Megatron-LM 支持模型并行和多节点训练。有关更多详细信息,请参阅相应的论文:Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism(https://arxiv.org/abs/1909.08053)。
首先,我们讨论数据和环境设置,以及如何使用原始的Megatron-LM训练GPT-2模型。接下来,我们逐步介绍如何使用DeepSpeed使该模型运行。最后,我们演示使用DeepSpeed所获得的性能提升和内存占用减少。
使用原始的 Megatron-LM 训练 GPT2
我们将原始的Megatron-LM(https://github.com/NVIDIA/Megatron-LM)模型代码复制到DeepSpeed Megatron-LM(https://github.com/microsoft/Megatron-DeepSpeed)中,并将其作为子模块提供。要下载,请执行以下操作:
git submodule update --init --recursive
设置训练数据
按照Megatron的说明(https://github.com/NVIDIA/Megatron-LM#collecting-gpt-webtext-data)下载webtext数据,并在DeepSpeedExamples/Megatron-LM/data( 在最新版本的DeepSpeedExamples中可以放置在 /home/zhangxiaoyu/DeepSpeedExamples/training/megatron )下放置一个符号链接。
运行未修改的Megatron-LM GPT2模型
对于单块GPU:
- 修改
scripts/pretrain_gpt2.sh,将其--train-data参数设置为 “webtext”。 - 运行
bash scripts/pretrain_gpt2.sh
对于多个节点和多个GPU:
- 修改
scripts/pretrain_gpt2_model_parallel.sh- 将其
--train-data参数设置为 “webtext”。 GPUS_PER_NODE指示了测试中每个节点使用的GPU数量。NNODES指示了测试中涉及的节点数量。
- 将其
- 执行
bash scripts/pretrain_gpt2_model_parallel.sh
开启DeepSpeed
为了用上DeepSpeed需要更新三个文件:
arguments.py: 参数配置文件pretrain_gpt2.py: 训练的主入口点utils.py: 模型保存和加载工具
参数解析
第一步是在 arguments.py 中使用 deepspeed.add_config_arguments() 将 DeepSpeed 参数添加到 Megatron-LM GPT2 模型中。
初始化和训练
我们将修改 pretrain.py 以启用使用 DeepSpeed 进行训练。
初始化
我们使用 deepspeed.initialize 创建 model_engine、optimizer 和 LR scheduler。下面是其定义:
def initialize(args,
model,
optimizer=None,
model_parameters=None,
training_data=None,
lr_scheduler=None,
mpu=None,
dist_init_required=True,
collate_fn=None):
对于 Megatron-LM GPT2 模型,我们在其 setup_model_and_optimizer() 函数中进行 DeepSpeed 初始化,函数传的参数包含原始model、optimizer、args、lr_scheduler 和 mpu。
请注意,当启用FP16时,Megatron-LM GPT2会在Adam优化器上添加一个包装器。DeepSpeed有自己的FP16优化器,因此我们需要直接将Adam优化器传递给DeepSpeed,而不需要任何包装器。当启用DeepSpeed时,我们从 get_optimizer() 返回未包装的Adam优化器。
使用训练API
由 deepspeed.initialize 返回的模型是 DeepSpeed 模型引擎,我们将基于该引擎使用 forward、backward 和 step API 训练模型。
前向传播
前向传播API与PyTorch兼容,不需要进行任何更改。
反向传播
通过在模型引擎上直接调用 backward(loss) 来进行反向传播。
def backward_step(optimizer, model, lm_loss, args, timers):
"""Backward step."""
# Total loss.
loss = lm_loss
# Backward pass.
if args.deepspeed:
model.backward(loss)
else:
optimizer.zero_grad()
if args.fp16:
optimizer.backward(loss, update_master_grads=False)
else:
loss.backward()
DeepSpeed会在使用小批量更新权重后自动处理梯度清零。此外,DeepSpeed在内部解决了分布式数据并行和FP16,简化了多个地方的代码。
(A) DeepSpeed 还在梯度累积边界处自动执行梯度平均,因此我们跳过allreduce通信。
if args.deepspeed:
# DeepSpeed反向传播已经处理了allreduce通信。重置计时器以避免破坏下面的计时器日志。
timers('allreduce').reset()
else:
torch.distributed.all_reduce(reduced_losses.data)
reduced_losses.data = reduced_losses.data / args.world_size
if not USE_TORCH_DDP:
timers('allreduce').start()
model.allreduce_params(reduce_after=False,
fp32_allreduce=args.fp32_allreduce)
timers('allreduce').stop()
(B) 我们也跳过更新主节点梯度,因为DeepSpeed在内部解决了这个问题。
# Update master gradients.
if not args.deepspeed:
if args.fp16:
optimizer.update_master_grads()
# Clipping gradients helps prevent the exploding gradient.
if args.clip_grad > 0:
if not args.fp16:
mpu.clip_grad_norm(model.parameters(), args.clip_grad)
else:
optimizer.clip_master_grads(args.clip_grad)
return lm_loss_reduced
更新模型参数
DeepSpeed引擎中的 step() 函数更新模型参数以及学习率。
if args.deepspeed:
model.step()
else:
optimizer.step()
# Update learning rate.
if not (args.fp16 and optimizer.overflow):
lr_scheduler.step()
else:
skipped_iter = 1
损失缩放
GPT2训练脚本在训练过程中记录了损失缩放值。在DeepSpeed优化器内部,该值存储为 cur_scale,而不是Megatron的优化器中的 loss_scale。因此,我们在日志字符串中适当地进行了替换。
if args.fp16:
log_string += ' loss scale {:.1f} |'.format(
optimizer.cur_scale if args.deepspeed else optimizer.loss_scale)
检查点保存和加载
DeepSpeed引擎具有灵活的API,用于保存和加载检查点,以处理来自客户端模型和其自身内部的状态。
def save_checkpoint(self, save_dir, tag, client_state={})
def load_checkpoint(self, load_dir, tag)
要使用DeepSpeed,我们需要更新utils.py,它是Megatron-LM GPT2保存和加载检查点的脚本。
创建一个新的函数 save_ds_checkpoint(),如下所示。新函数收集客户端模型状态,并通过调用DeepSpeed的 save_checkpoint() 将其传递给DeepSpeed引擎。
def save_ds_checkpoint(iteration, model, args):
"""Save a model checkpoint."""
sd = {}
sd['iteration'] = iteration
# rng states.
if not args.no_save_rng:
sd['random_rng_state'] = random.getstate()
sd['np_rng_state'] = np.random.get_state()
sd['torch_rng_state'] = torch.get_rng_state()
sd['cuda_rng_state'] = get_accelerator().get_rng_state()
sd['rng_tracker_states'] = mpu.get_cuda_rng_tracker().get_states()
model.save_checkpoint(args.save, iteration, client_state = sd)
在 Megatron-LM GPT2 的 save_checkpoint() 函数中,添加以下行以调用上述 DeepSpeed 函数。
def save_checkpoint(iteration, model, optimizer,
lr_scheduler, args):
"""Save a model checkpoint."""
if args.deepspeed:
save_ds_checkpoint(iteration, model, args)
else:
......
在 load_checkpoint() 函数中,使用以下 DeepSpeed 检查点加载API,并返回客户端模型的状态。
def load_checkpoint(model, optimizer, lr_scheduler, args):
"""Load a model checkpoint."""
iteration, release = get_checkpoint_iteration(args)
if args.deepspeed:
checkpoint_name, sd = model.load_checkpoint(args.load, iteration)
if checkpoint_name is None:
if mpu.get_data_parallel_rank() == 0:
print("Unable to load checkpoint.")
return iteration
else:
......
DeepSpeed Activation Checkpoints(可选)
DeepSpeed可以通过在模型并行GPU之间划分激活检查点或者将其转移到CPU来减少模型并行训练过程中激活的内存消耗。这些优化措施是可选的,除非激活内存成为瓶颈,否则可以跳过。要启用Activation checkpoint,我们使用deepspeed.checkpointing API来替换Megatron的Activation checkpoint和随机状态跟踪器API。这个替换应该发生在首次调用这些API之前。
a) 替换 pretrain_gpt.py 中的:
# Optional DeepSpeed Activation Checkpointing Features
#
if args.deepspeed and args.deepspeed_activation_checkpointing:
set_deepspeed_activation_checkpointing(args)
def set_deepspeed_activation_checkpointing(args):
deepspeed.checkpointing.configure(mpu,
deepspeed_config=args.deepspeed_config,
partition_activation=True)
mpu.checkpoint = deepspeed.checkpointing.checkpoint
mpu.get_cuda_rng_tracker = deepspeed.checkpointing.get_cuda_rng_tracker
mpu.model_parallel_cuda_manual_seed =
deepspeed.checkpointing.model_parallel_cuda_manual_seed
替换 mpu/transformer.py 中的:
if deepspeed.checkpointing.is_configured():
global get_cuda_rng_tracker, checkpoint
get_cuda_rng_tracker = deepspeed.checkpoint.get_cuda_rng_tracker
checkpoint = deepspeed.checkpointing.checkpoint
通过这些替换,可以使用 deepspeed.checkpointing.configure 或 deepspeed_config 文件指定各种 DeepSpeed Activation checkpoint优化,例如activation partitioning, contiguous checkpointing 和 CPU checkpointing。
关于DeepSpeed Activation CheckPoint的更多信息我们可以参考 https://deepspeed.readthedocs.io/en/latest/activation-checkpointing.html#configuring-activation-checkpointing ,我翻译一下主要的 configure 和 is_configured接口。
deepspeed.checkpointing.configure(mpu_, deepspeed_config=None, partition_activations=None, contiguous_checkpointing=None, num_checkpoints=None, checkpoint_in_cpu=None, synchronize=None, profile=None)
配置 DeepSpeed Activation Checkpointing.
参数:
mpu – 可选:一个实现以下方法的对象:get_model_parallel_rank/group/world_size 和 get_data_parallel_rank/group/world_size。
deepspeed_config – 可选:当提供DeepSpeed配置JSON文件时,将用于配置DeepSpeed激活检查点。
partition_activations – 可选:启用后在模型并行GPU之间Partitions activation checkpoint。默认为False。如果提供,将覆盖deepspeed_config。
contiguous_checkpointing – 可选:将activation checkpoint复制到一个连续的内存缓冲区中。仅在启用Partitions activation checkpoint时与同构检查点一起使用。必须提供num_checkpoints。默认为False。如果提供,将覆盖deepspeed_config。
num_checkpoints – 可选:在模型的前向传播期间存储的activation checkpoint数。用于计算连续checkpoint缓冲区的大小。如果提供,将覆盖deepspeed_config。
checkpoint_in_cpu – 可选:将activation checkpoint移动到CPU。仅在Partitions activation checkpoint时工作。默认值为false。如果提供,将覆盖deepspeed_config。
synchronize – 可选:在每次调用deepspeed.checkpointing.checkpoint的前向和反向传递的开始和结束处执行get_accelerator().synchronize()。默认为false。如果提供,将覆盖deepspeed_config。
profile – 可选:记录每个deepspeed.checkpointing.checkpoint调用的前向和反向传播时间。如果提供,将覆盖deepspeed_config。
deepspeed.checkpointing.is_configured()
如果已配置deepspeed activation checkpoint,则为True
否则返回false,需要通过调用deepspeed.checkpointing.configure来进行配置。
训练脚本
我们假设在先前的步骤中准备好了 webtext 数据。要开始使用 DeepSpeed 训练 Megatron-LM GPT2 模型,请执行以下命令开始训练。
- 单GPU运行:
bash scripts/ds_pretrain_gpt2.sh - 多GPU/节点运行:
bash scripts/ds_zero2_pretrain_gpt2_model_parallel.sh
DeepSpeed 使用 GPT-2 进行评估
DeepSpeed 通过先进的 ZeRO 优化器有效地训练非常大的模型。在2020年2月,我们在 DeepSpeed 中发布了 ZeRO 的一部分优化,该优化执行优化器状态切分。我们将其称为 ZeRO-1。在2020年5月,我们在 DeepSpeed 中扩展了 ZeRO-1,包括来自 ZeRO 的其它优化,包括梯度和激活切分,以及连续内存优化。我们将此版本称为 ZeRO-2。
ZeRO-2显着降低了训练大型模型的内存占用,这意味着可以使用更少的模型并行度和更大的批量大小来训练大型模型。较小的模型并行度通过增加计算的粒度(例如矩阵乘法)来提高训练效率,其中性能与矩阵的大小直接相关。此外,较小的模型并行度还导致模型并行GPU之间的通信更少,进一步提高了性能。较大的批量大小具有类似的效果,增加了计算粒度,并减少了通信,也获得了更好的性能。因此,通过DeepSpeed和ZeRO-2集成到Megatron中,与仅使用Megatron相比,我们将模型规模和速度提升到了一个全新的水平。
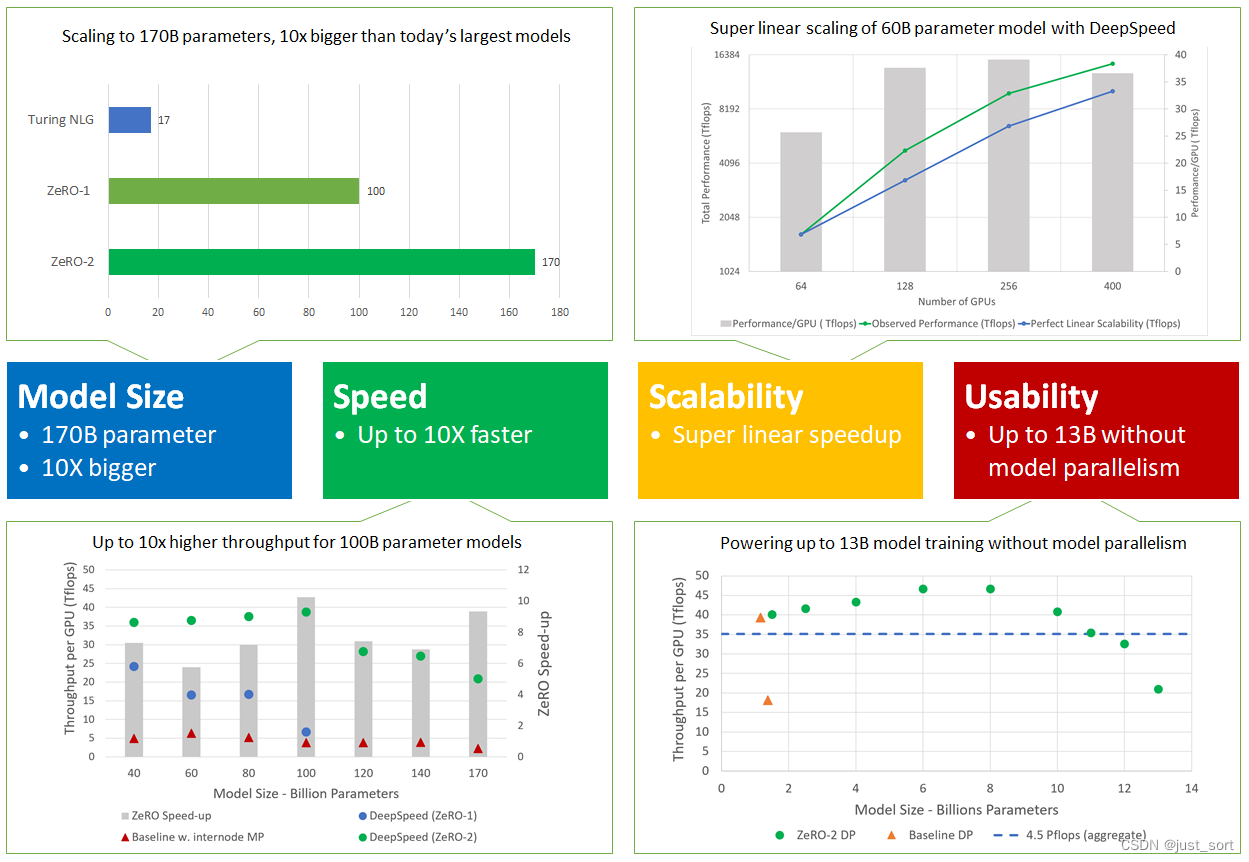 更具体地说,DeepSpeed和ZeRO-2在以下四个方面表现出色(如图2所示),支持比现有模型大一个数量级的模型,速度快了多达10倍,具有超线性的可扩展性,并提高了可用性以实现大型模型训练的平民化。以下详细介绍了这四个方面。
更具体地说,DeepSpeed和ZeRO-2在以下四个方面表现出色(如图2所示),支持比现有模型大一个数量级的模型,速度快了多达10倍,具有超线性的可扩展性,并提高了可用性以实现大型模型训练的平民化。以下详细介绍了这四个方面。
模型大小:目前最先进的大型模型,例如OpenAI GPT-2、NVIDIA Megatron-LM、Google T5和Microsoft Turing-NLG,分别具有1.5B、8.3B、11B和17B个参数。ZeRO-2提供了系统支持,可以高效地运行1700亿个参数的模型,比这些最大的模型大一个数量级(图2,左上角)。
速度: 改进的内存效率提高了吞吐量和训练速度。图2(左下角)显示了ZeRO-2和ZeRO-1(两者都将由ZeRO驱动的数据并行与NVIDIA Megatron-LM模型并行结合在一起)的系统吞吐量,以及仅使用最先进的模型并行方法Megatron-LM(图2,左下方的基准线)。ZeRO-2可以在一个由400个NVIDIA V100 GPU组成的集群上运行1000亿参数的模型,每个GPU的性能超过38 teraflops,聚合性能超过15 petaflops。对于相同大小的模型,与仅使用Megatron-LM相比,ZeRO-2的训练速度快10倍,与ZeRO-1相比快5倍。
扩展性: 我们观察到超线性加速(图2,右上角),即当GPU数量翻倍时,性能增长超过两倍。ZeRO-2降低了模型状态的内存占用,使我们可以在每个GPU上容纳更大的批量大小,从而提高了性能。随着数据并行度的增加,ZeRO-2减少了模型状态的内存占用,这也导致了超线性加速的效果。
平民化大模型训练: ZeRO-2使模型科学家能够高效地训练高达130亿个参数的模型,而无需进行通常需要模型重构的模型并行(图2,右下角)。130亿个参数比大多数最先进的模型(如具有110亿个参数的Google T5)都要大。因此,模型科学家可以自由地尝试大型模型,而不必担心模型并行。相比之下,经典数据并行方法的实现(如PyTorch分布式数据并行)在1.4亿个参数的模型上会耗尽内存,而ZeRO-1则支持最多6亿个参数。
此外,在没有模型并行的情况下,这些模型可以在带宽较低的集群上进行训练,同时仍然比使用模型并行获得显着更高的吞吐量。例如,使用40 Gbps Infiniband互连连接的四个节点集群(每个节点具有四个连接到PCI-E的NVIDIA 16GB V100 GPU),使用ZeRO提供的数据并行比使用模型并行快近4倍,可将GPT-2模型训练得更快。因此,通过这种性能提升,大型模型训练不再仅限于具有超快速互连的GPU集群,而且也可以在带宽有限的中等集群上进行。
目前,Megatron的仓库也集成了DeepSpeed提供的大量Feature,所以Megatron-DeepSpeed这个仓库用的人很少,一般还是独立使用Megatron或者DeepSpeed来炼丹。不过这里的教程为我们指出了要将DeepSpeed用在Megatron仓库需要做的修改,我们也可以看到DeepSpeed的扩展性是还不错的。如果你对DeepSpeed和Megatron的联合使用感兴趣,可以参考下面DeepSpeedExamples中的例子:https://github.com/microsoft/DeepSpeedExamples/tree/bdf8e59aede8c8e0577e8d4d557298ca8515268f/Megatron-LM
0x2. Zero Redundancy Optimizer (零冗余优化器)
在阅读这个 Tutorial 之前可以先浏览一下0x1节,在本教程中,我们将把ZeRO优化器应用于Megatron-LM GPT-2模型。ZeRO是一组强大的内存优化技术,可以有效地训练具有数万亿参数的大型模型,如GPT-2和Turing-NLG 17B。与其它用于训练大型模型的模型并行方法相比,ZeRO的一个关键优势是不需要对模型代码进行修改。正如本教程将演示的那样,在DeepSpeed模型中使用ZeRO非常快捷和简单,因为你只需要在DeepSpeed配置JSON中更改一些配置即可。不需要进行代码更改。
Zero概述
ZeRO利用数据并行的计算和内存资源来降低模型训练所需的每个设备(GPU)的内存和计算要求。ZeRO通过在分布式训练硬件中的可用设备(GPU和CPU)之间分区各种模型训练状态(权重、梯度和优化器状态)来降低每个GPU的内存消耗。具体而言,ZeRO被实现为逐步优化的阶段,其中早期阶段的优化在后期阶段可用。如果您想深入了解ZeRO,请参见Zero的论文(https://arxiv.org/abs/1910.02054v3)。
- Stage 1 。优化器状态(例如Adam优化器的32位权重和第一、第二阶矩估计)在进程间被切分,以便每个进程仅更新它持有的部分。
- Stage 2。用于更新模型权重的32位梯度也被切分,以便每个进程仅保留与其优化器状态部分对应的梯度。
- Stage 3。16位模型参数被在进程间被切分。ZeRO-3将在前向和后向传递期间自动收集和切分它们。
此外,ZeRO-3还包括无限卸载引擎以形成ZeRO-Infinity(https://arxiv.org/abs/2104.07857),可以卸载到CPU和NVMe内存以实现巨大的内存节省。
训练环境
我们使用DeepSpeed Megatron-LM GPT-2代码作为例子。你可以按照Megatron-LM教程逐步操作,熟悉代码。我们将在配备32GB RAM的NVIDIA Tesla V100-SXM3 Tensor Core GPU(https://www.nvidia.com/en-us/data-center/v100/)上训练本教程中的模型。
开启Zero优化
要为DeepSpeed模型启用ZeRO优化,我们只需要将zero_optimization键添加到DeepSpeed JSON配置中。有关zero_optimization键的配置的完整描述,请参见此处(https://www.deepspeed.ai/docs/config-json/#zero-optimizations-for-fp16-training)。
训练一个1.5B参数的GPT2模型
我们通过展示ZeROStage 1的优点来演示它使得在八个V100 GPU上进行1.5亿参数的GPT-2模型的数据并行训练成为可能。我们将训练配置为每个设备使用1个批次,以确保内存消耗主要由模型参数和优化器状态引起。我们通过对deepspeed启动脚本应用以下修改来创建这个训练场景:
--model-parallel-size 1 \
--num-layers 48 \
--hidden-size 1600 \
--num-attention-heads 16 \
--batch-size 1 \
--deepspeed_config ds_zero_stage_1.config \
在没有ZeRO的情况下训练这个模型会失败,并显示出内存不足(OOM)错误,如下所示:

这个模型不能适应GPU内存的一个重要原因是Adam优化器状态消耗了18GB的内存,这是32GB RAM的一个相当大的部分。通过使用ZeRO Stage1将优化器状态在八个数据并行 rank 之间进行切分,每个设备的内存消耗可以降低到2.25GB,从而使得模型可训练。为了启用ZeRO Stage1,我们只需要更新DeepSpeed JSON配置文件如下:
{
"zero_optimization": {
"stage": 1,
"reduce_bucket_size": 5e8
}
}
如上所示,我们在zero_optimization键中设置了两个字段。具体来说,我们将stage字段设置为1,并将可选的reduce_bucket_size设置为500M。启用ZeRO Stage1后,模型现在可以在8个GPU上平稳地训练,而不会耗尽内存。以下是模型训练的一些屏幕截图:

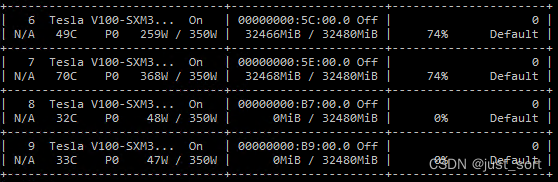
从上面的nvidia-smi截图中,我们可以看到只有第6-7个GPU被用于训练模型。通过使用ZeRO Stage1,我们可以进一步减少每个设备的内存消耗,通过增加数据并行度来实现这些内存节省,这些内存节省可以用于增加模型大小和/或 batch 大小。相比之下,仅使用数据并行无法实现这样的好处。
训练一个10b的GPT-2模型
ZeRO Stage2 优化进一步增加了可以使用数据并行训练的模型大小。我们通过使用32个V100 GPU训练一个具有10B参数的模型来展示这一点。
首先,我们需要配置一个启用了Activation Checkpoint的10B参数模型。这可以通过对DeepSpeed启动脚本应用以下GPT-2模型配置更改来完成。
--model-parallel-size 1 \
--num-layers 50 \
--hidden-size 4096 \
--num-attention-heads 32 \
--batch-size 1 \
--deepspeed_config ds_zero_stage_2.config \
--checkpoint-activations
接下来,我们需要更新DeepSpeed JSON配置,如下所示,以启用ZeRO Stage2优化:
{
"zero_optimization": {
"stage": 2,
"contiguous_gradients": true,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"allgather_bucket_size": 5e8
}
}
在上面的更改中,我们将stage字段设置为2,并配置了在ZeRO Stage2 中可用的其他优化选项。例如,我们启用了contiguous_gradients,以减少反向传播期间的内存碎片。这些优化设置的完整描述可在(https://www.deepspeed.ai/docs/config-json/#zero-optimizations-for-fp16-training)找到。有了这些更改,我们现在可以启动训练。
以下是训练日志的截图:

以下是训练期间nvidia-smi显示的GPU活动的截图:

使用ZeRO-Infinity训练万亿级别的模型
ZeRO-3是ZeRO的第三个阶段,它可以将完整的模型状态(即权重、梯度和优化器状态)进行切分,以线性地扩展内存节省量和数据并行度。可以在JSON配置中启用ZeRO-3。这里(https://www.deepspeed.ai/docs/config-json/#zero-optimizations-for-fp16-training)提供了这些配置的完整描述。
使用ZeRO-Infinity将计算转移到CPU和NVMe
ZeRO-Infinity使用DeepSpeed的无限卸载引擎将完整的模型状态转移到CPU或NVMe内存中,从而使更大的模型尺寸成为可能。卸载可以在DeepSpeed配置中启用:
{
"zero_optimization": {
"stage": 3,
"contiguous_gradients": true,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_prefetch_bucket_size": 1e7,
"stage3_param_persistence_threshold": 1e5,
"reduce_bucket_size": 1e7,
"sub_group_size": 1e9,
"offload_optimizer": {
"device": "cpu"
},
"offload_param": {
"device": "cpu"
}
}
}
ZeRO-Infinity与ZeRO-Offload的区别:DeepSpeed最初通过ZeRO-Offload实现了Offload功能,这是一种将优化器和梯度状态转移到ZeRO-2中的CPU内存的系统。ZeRO-Infinity是下一代基于ZeRO-3的Offload功能。ZeRO-Infinity能够比ZeRO-Offload更多地卸载数据,并具有更有效的带宽利用和计算与通信的重叠。
分配大规模Megatron-LM模型
我们进行了两项进一步的模型初始化更改,以支持超出本地系统内存但未超出总系统内存的模型。
- 以可扩展内存的方式分配模型。模型参数将被分配并立即切分到数据并行group中。如果
remote_device是“cpu”或“nvme”,模型也将被分配到CPU / NVMe内存中而不是GPU内存中。有关更多详细信息,请参阅完整的ZeRO-3初始化文档(https://deepspeed.readthedocs.io/en/latest/zero3.html#deepspeed.zero.Init)。
with deepspeed.zero.Init(data_parallel_group=mpu.get_data_parallel_group(),
remote_device=get_args().remote_device,
enabled=get_args().zero_stage==3):
model = GPT2Model(num_tokentypes=0, parallel_output=True)
- 收集额外的嵌入权重以进行初始化。DeepSpeed 在 module 的构造函数和前向/反向传递期间会自动收集 module 的参数。但是,如果需要额外的访问,则必须与DeepSpeed进行协调以确保参数数据被收集并随后被切分。如果修改了张量,则还应使用
modifier_rank参数,以确保所有进程对数据有一致的视角。有关更多详细信息,请参阅完整的GatheredParameters文档(https://deepspeed.readthedocs.io/en/latest/zero3.html#deepspeed.zero.GatheredParameters)。
self.position_embeddings = torch.nn.Embedding(...)
with deepspeed.zero.GatheredParameters(self.position_embeddings.weight,
modifier_rank=0):
# Initialize the position embeddings.
self.init_method(self.position_embeddings.weight)
...
self.tokentype_embeddings = torch.nn.Embedding(...)
with deepspeed.zero.GatheredParameters(self.tokentype_embeddings.weight,
modifier_rank=0):
# Initialize the token-type embeddings.
self.init_method(self.tokentype_embeddings.weight)
阅读了一下文档,这里的优化就类似于编译器中的公共子表达式消除,由于embeding层在模型中只在init中声明,然后每一层的Transformer块都要访问embedding对象的weight,所以可以采用这种声明为公共变量的特殊优化来减少显存占用。
以内存为中心的分块优化
ZeRO-Infinity包括一个用于进一步降低内存使用的Linear层替代方案。我们可以选择性地对每个Transformer层中的模型并行线性层进行分块。请注意,可以通过在构建层时指定相应的基类来将模型并行性和分块相结合。deepspeed.zero.TiledLinear模块利用ZeRO-3的数据获取和释放模式,将一个大的运算符分解成较小的块,可以顺序执行,从而降低工作内存需求。
我们在代码中包含了一个来自Megatron-LM的ParallelMLP(https://github.com/microsoft/DeepSpeedExamples/blob/bdf8e59aede8c8e0577e8d4d557298ca8515268f/Megatron-LM-v1.1.5-ZeRO3/megatron/model/transformer.py#L82)的示例更改。transformer.py中的另外三个模型并行层的处理方式类似。
Megatron-LM的模型并行层具有特殊的形式,其中层的加性bias被延迟,并在forward()中返回,以便与后续运算符融合。DeepSpeed的deepspeed.zero.TiledLinearReturnBias是TiledLinear的子类,它只是将返回的偏置参数转发而不进行累加。
-self.dense_h_to_4h = mpu.ColumnParallelLinear(
+self.dense_h_to_4h = deepspeed.zero.TiledLinearReturnBias(
args.hidden_size,
4 * args.hidden_size,
+ in_splits=args.tile_factor,
+ out_splits=4*args.tile_factor,
+ linear_cls=mpu.ColumnParallelLinear,
gather_output=False,
init_method=init_method,
skip_bias_add=True)
注意,我们按比例缩放in_splits和out_splits与input_size和output_size。这会导致固定大小的小块[hidden/tile_factor,hidden/tile_factor]。
提取权重
如果您需要从Deepspeed中获取预训练权重,则可以按以下步骤获取fp16权重:
- 在ZeRO-2下,
state_dict包含fp16模型权重,可以使用torch.save正常保存这些权重。 - 在ZeRO-3下,
state_dict仅包含占位符,因为模型权重被切分到多个GPU上。如果你想要获取这些权重,请启用:
"zero_optimization": {
"stage3_gather_16bit_weights_on_model_save": true
},
然后使用如下的代码保存模型:
if self.deepspeed:
self.deepspeed.save_16bit_model(output_dir, output_file)
因为它需要在一个GPU上合并权重,所以这可能会很慢并且需要大量内存,因此只在需要时使用此功能。
请注意,如果stage3_gather_16bit_weights_on_model_save为False,则不会保存任何权重(因为state_dict中没有这些权重)。你也可以使用此方法保存ZeRO-2权重。
如果你想获取fp32权重,我们提供了一种特殊的脚本,可以进行离线合并。它不需要配置文件或GPU。以下是其使用示例:
$ cd /path/to/checkpoint_dir
$ ./zero_to_fp32.py . pytorch_model.bin
Processing zero checkpoint at global_step1
Detected checkpoint of type zero stage 3, world_size: 2
Saving fp32 state dict to pytorch_model.bin (total_numel=60506624)
当你保存checkpoint时,zero_to_fp32.py脚本会自动生成。注意:目前该脚本使用的内存(通用RAM)是最终checkpoint大小的两倍。
或者,如果你有足够的CPU内存,并且想要将模型更新为其fp32权重,您可以在训练结束时执行以下操作:
from deepspeed.utils.zero_to_fp32 import load_state_dict_from_zero_checkpoint
fp32_model = load_state_dict_from_zero_checkpoint(deepspeed.module, checkpoint_dir)
请注意,该模型适合保存,但不再适合继续训练,并且需要重新执行deepspeed.initialize()。如果你只想要state_dict,可以执行以下操作:
from deepspeed.utils.zero_to_fp32 import get_fp32_state_dict_from_zero_checkpoint
state_dict = get_fp32_state_dict_from_zero_checkpoint(checkpoint_dir)
0x3. Zero-Offload
Zero-Offload有一篇介绍的博客(https://www.microsoft.com/en-us/research/blog/zero-infinity-and-deepspeed-unlocking-unprecedented-model-scale-for-deep-learning-training/),本来想翻译下发现智源的一篇博客基本算是翻译版本了,所以大家可以看这篇中文版的Zero-Offload博客 https://hub.baai.ac.cn/view/7905。这里做一下Zero-Offload的教程翻译。
ZeRO-Offload 是一种 ZeRO 优化,它将优化器内存和计算从GPU转移到主机CPU。 ZeRO-Offload 可以在单个GPU上高效地训练具有多达130亿个参数的大模型。在本教程中,我们将使用 ZeRO-Offload 在 DeepSpeed 中训练一个具有100亿个参数的 GPT-2 模型。此外,在 DeepSpeed 模型中使用 ZeRO-Offload 很快很容易,因为你只需要在 DeepSpeed 配置json中更改一些配置即可,无需进行代码更改。
ZeRO-Offload概述
对于大型模型训练,如Adam等优化器可能会消耗大量GPU计算和内存资源。ZeRO-Offload通过利用主机CPU的计算和内存资源执行优化器来减少此类模型的GPU计算和内存要求。此外,为了防止优化器成为瓶颈,ZeRO-Offload使用DeepSpeed高度优化的CPU Adam实现,称为DeepSpeedCPUAdam(https://github.com/microsoft/DeepSpeed/tree/master/deepspeed/ops/adam)。 DeepSpeedCPUAdam比标准的PyTorch实现快5倍到7倍。要深入了解ZeRO-Offload的设计和性能,请参阅我们的博客文章(就是上面提到的)。截图:

训练环境
在本教程中,我们将使用 DeepSpeed Megatron-LM GPT-2 代码配置一个具有 100 亿参数的 GPT-2 模型。如果你之前没有使用过 Megatron-LM,请建议你先完成 Megatron-LM 教程(也就是本文中的0x1节)。我们将使用一张 NVIDIA Tesla V100-SXM3 Tensor Core GPU,其具有 32GB 的内存。
在单个 V100 GPU 上训练10B的GPT2模型
我们需要对 Megatron-LM 的启动脚本和 DeepSpeed 配置 json 进行更改。
Megatron-LM GPT-2 的启动脚本更改:
我们需要对 DeepSpeed Megatron-LM GPT-2 模型的启动脚本进行两个更改。第一个更改是配置一个启用activation checkpointing的 10B 参数 GPT-2 模型,可以通过以下一组更改来实现:
--model-parallel-size 1 \
--num-layers 50 \
--hidden-size 4096 \
--num-attention-heads 32 \
--batch-size 10 \
--deepspeed_config ds_zero_offload.config \
--checkpoint-activations
如果你已经完成了 Megatron-LM 教程,上述更改中的大多数标志应该是熟悉的。
其次,我们需要应用以下更改,以确保只使用一个GPU进行训练。
deepspeed --num_nodes 1 --num_gpus 1 ...
DeepSpeed 配置更改
ZeRO-Offload 利用了一些 ZeRO Stage 1和 Stage 2 机制,因此启用 ZeRO-Offload 需要的配置更改是启用 ZeRO Stage 1和 Stage 2 所需的扩展。下面是启用 ZeRO-Offload 的 zero_optimization 配置:
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
}
"contiguous_gradients": true,
"overlap_comm": true
}
}
如上所述,除了将stage字段设置为2(启用ZeRO Stage 2,但Stage 1也可以),我们还需要将offload_optimizer设备设置为cpu以启用ZeRO-Offload优化。此外,我们可以设置其他ZeRO Stage 2优化标志,例如overlap_comm来调整ZeRO-Offload性能。通过这些更改,我们现在可以运行模型。我们在下面分享了一些训练的截图。
 以下是
以下是 nvidia-smi 的截图,显示仅在训练期间激活了 GPU 0
最后,以下是 htop 的截图,显示了在优化器计算期间主机CPU和内存的活动情况:
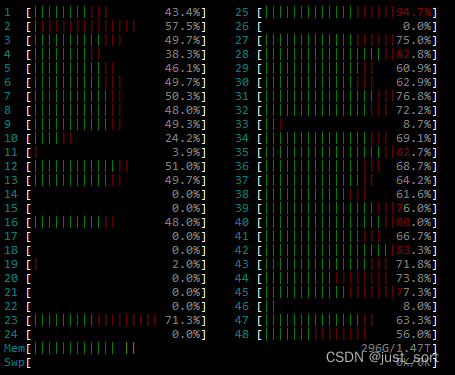
0x4. 总结
本篇文章主要翻译了DeepSpeed里面和Zero相关的技术教程,对DeepSpeed感兴趣的读者可以对照官方文档学习一下。




![[openeuler]Yocto embedded 联合sig例会 (2022-12-15)](https://img-blog.csdnimg.cn/dd82d40707304348ba330eb54d437330.png)


![[操作系统]4.文件管理](https://img-blog.csdnimg.cn/a220aa23e9f641cea287b6db1396a465.png)