因为复习时间来不及了
还是老规矩,知识点覆盖不完全,具体内容请参考黑书,知识脉络来自王道操作系统
关于文件操作系统
1.文件系统基础
(1)文件的定义
文件时操作系统中的重要概念,是以计算机硬盘为基础载体存储在假期上的信息的集合
(2)文件的属性
文件的属性可以理解为文件的基本信息
包括名称,标识符,类型,位置,大小,保护,时间
(3)文件的基本操作
文件的基本操作是操作系统为用户提供的一些功能
比如创建文件,写文件,删除文件,文件重定位,截断文件.读文件
所有文件的复杂操作都可以被拆分为这六个步骤
2.文件的逻辑结构(*)
文件的逻辑结构指的是以用户的视角看待文件
(1)无结构文件也叫做流式文件
流式文件打个比方,很类似那种txt文件,在早期进行java流学习的时候,就是使用这些文件来存储一些信息.这种数据是按顺序,但是没有任何结构存放,只能使用穷举法获取某个数据
(2)有结构文件
有结构文件,其实可以类比为excel,或者数据库表这种形式的内容
并且能正常的区分出结构的数据,这种记录分为数据定长度和数据不定长度两种类型,按照组织记录的形式可以分为两种
1.顺序文件:顺序文件的特点是文件记录一个接一个按照顺序排列,如果文件和关键字有关(比如关键字为1的文件就是第一个文件)称之为顺序结构,而和关键字无关的,称之为串结构
2.索引文件:索引文件可以类比为有序列表or数组or切片,根据信息可以直接一次计算出所需文件的位置,索引文件的分为定长和不定长两种,定长文件可以通过算数得到我们需要的地址,而不定长文件实际上还是要通过遍历叠加,计算出我们所需的地址的`位置
3.顺序索引文件,顺序索引文件是前两种的集合,将顺序排列的文件划分为多个小组,每个组中的第一个被视为索引文件块,这些索引文件块会单独建立一个索引表管理
查询某个文件快,可以先找到所在组的第一个文件块,然后再通过遍历在组中寻找
4.直接文件或者散列文件
散列的性质已经很简单了,散列避免了顺序的特性,但是会造成冲突
(3)文件目录:
文件目录在就要用来管理一些东西,并且执行一些搜索,创建文件,删除文件,显示文件这类工作,进行操作的时候,可以考虑以下几种目录结构
1.单级目录结构:整个文件系统中只有一张表,所有的目录项都不能重名
2.二级目录结构;二级目录结构的第一节目录就算用户,每个用户拥有一个自己的目录表
3.多级目录结构:将两级目录结构进行推广,完成了一个树形的目录结构,当层次较多的时候,从根目录进行查询会导致目录查询耗费时间过长,所以会引入"相对目录"概念
4.无环图目录结构:无环图目录结构便于实现文件的共享,通过一个"共享节点"的数据结构来管理某个文件的共享状态.使用计数器来计算有多少用户在共享整个文件
当一个用户试图删除整个节点,count-1,当count=0的时候,即可真正删除整个绩点
(4)关于文件的共享
这里的文件共享指的是静态共享,并行和并发处理的则是动态共享
1.基于索引节点的共享方式
通过创建一个索引节点,然后进行计数,如果count为0,则可以删除整个索引节点
2.使用符号链来实现文件共享
只有文件的拥有者又有索引节点的指针
其他用户拥有的只是一个路径
(5)文件保护
文件保护可以使用以下几种方式来进行实现
1.访问类型:限制操作的类型
2.访问控制:对于访问者的身份进行验证
3.口令和密码:口令和密码的区别就是是否明文保存
2.文件系统的实现
(1)文件系统的层次结构
文件系统的层次结构是有多层次实现的
(1)用户调用接口:文件系统对于用户提供的与文件和目录相关的系统调用,比如新建删除文件这些操作
(2)文件目录系统:文件目录系统的主要功能是管理文件目录
(3)存取控制和验证模块
(4)逻辑文件系统与文件信息缓冲区
(5)物理文件系统
(6)辅助分配模块/设备管理程序模块
(2)文件的分配方式
1.连续分配方法
连续分配方法要求每个文件在内存中占据一个连续的区间
同时存在一个排序表,记录了文件的名字,起始地点和长度
比如 [ddaa, 0 ,2]
名为ddaa的文件,起点是0,长度为2,可以理解为占据0,1这个两个块
连续分配杠十的优势就算支持顺序访问和世界访问,实现简单,但是缺点在于文件长度不易动态增加,因为一个文件结尾的下一个块可能也被分给了其他的文件,此外会产生大量的外部碎片,难以使用
2.连接分配
在链接分配中,文件可以分为多个盘块离散地存储内存中
每个盘块会单独开辟出一小块内存,来存储一个指向下一个盘块的指针,这些指针对于用户是透明的
缺点是盘块指针会消耗一定的存储空间,而且稳定性不好,容易造成文件丢失
但是可以使用别的方式来进行节约这个空间,比如单独成立一个FAT表数据结构
这种表会在系统启动的时候存入内存,所以可以直接在内存中寻找盘块,减少了IO次数
3.索引分配
在索引分配中,每个文件都存在一个索引块,这个索引块中存在了这个文件所有相关的盘块索引
例如,某个索引块(代表file1文件)的内容为[1,23,44,-1,-1]
代表这个文件是盘块1,盘块23,盘块44组成的文件
-1代表长度还没有这么长
但是如果盘块的数目太多,导致索引块长度不够无法完全记录文件的盘块有以下三种处理方案
1.连接方案:将多个索引块视为一体,另一种性质的连续分配
2.多层索引:类似属性表的处理方式
3.混合索引:总和以上两种方案
(3)文件的存储空间管理
空闲表法:空闲表法其实属于另一种形式的连续分配方式,不过这次是管理空闲的列表
会按照一定顺序记录每一个空闲的区间,空闲块起始盘号,以及空闲盘块数目
空闲链表法:
位视图法:纵列为磁盘序号,横行为磁盘块号,1代表着块被使用了
成组链接法:不知道是干啥的
3.关于磁盘的组织和管理
(1)磁盘的结构
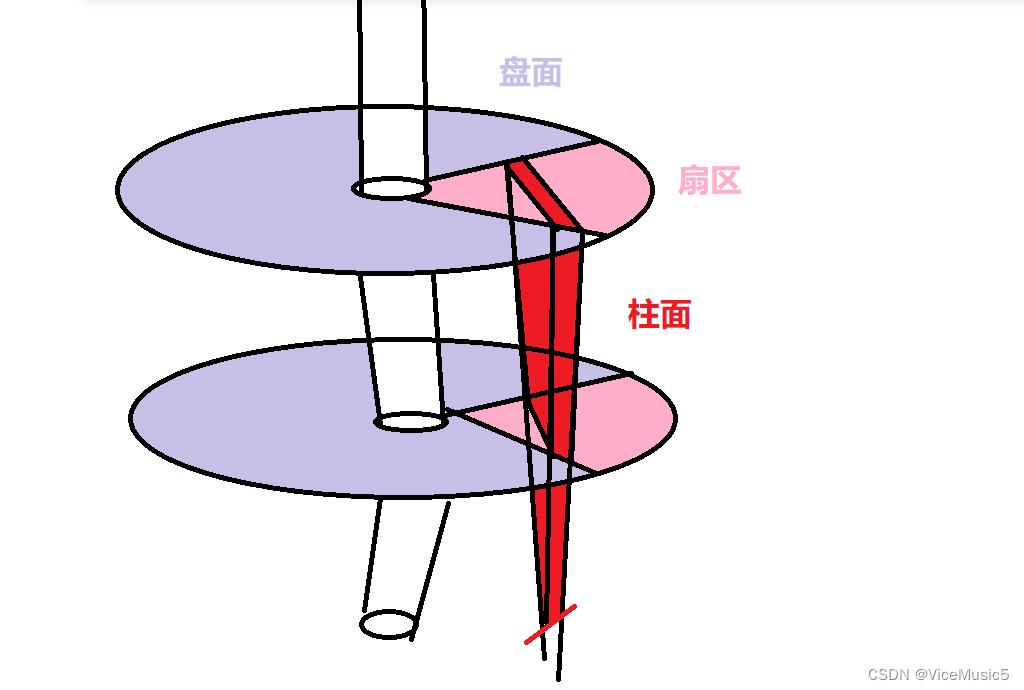
简单的画了个示意图供给参考,可以分为盘面,扇面柱面三个维度,就可以定位到某个位置上
(2)关于磁盘调度的几个算法
或者说,是查询硬盘文件的方法
1.先来先服务:
先来先服务算法其实就是按照请求,寻址的顺序来获取磁盘盘块
其实就是按请求的需求不断跳转
2.最短时间寻找优先算法:
SSFT算法的处理是每次寻找距离当前磁头嘴贱的刺刀,以便每次寻找到时间最短
顾名思义,每次都去寻找距离自己最近的一个
3.扫描算法
扫描算法和最短时间寻找算法一样,但是这个的区别在于不是每次都寻找距离自己最近的,而是在开始时刻,选择距离自己最近的目标的方向,然后一直运行到磁盘的尽头.
到达尽头以后,会反方向继续遍历
4.循环扫描算法
循环扫描算法在扫描算法上做出的改动是
每次运行到磁盘的尽头,不是反方向继续扫描,而是快速回到起点,开始下一次的扫描
快速回到起点的过程不会服务任何进程,形象点理解就是......黄金矿工?
5.还有一种lock算法,是在上面两种扫描算法上做出的改动
不会直接遍历到边界了,如果探查到该方向没有其他任务,就会停下