IO流
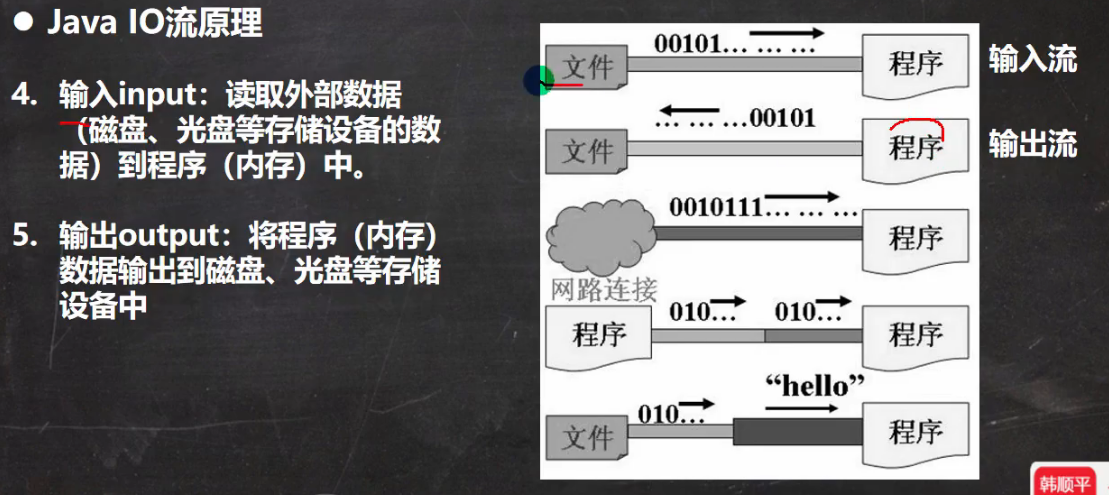
原理
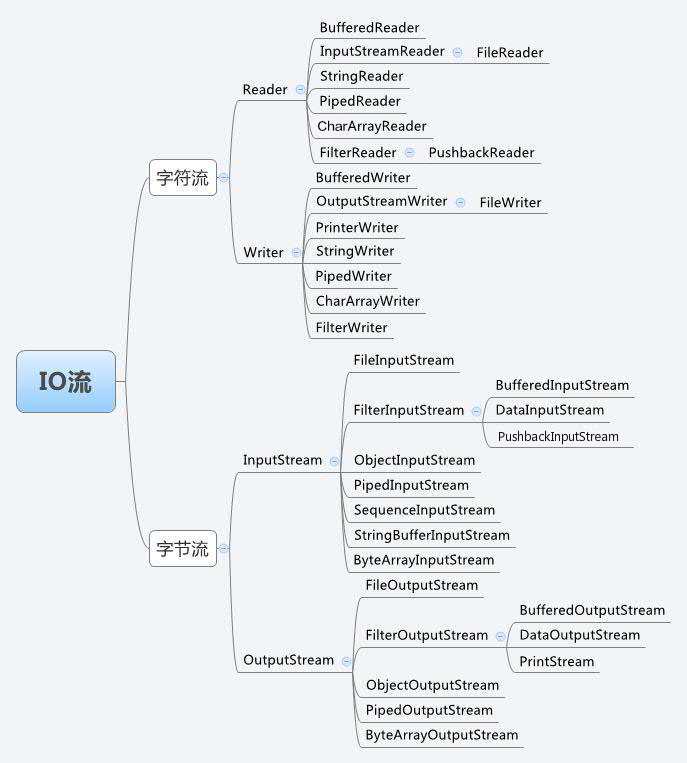
分类
字节流与字符流

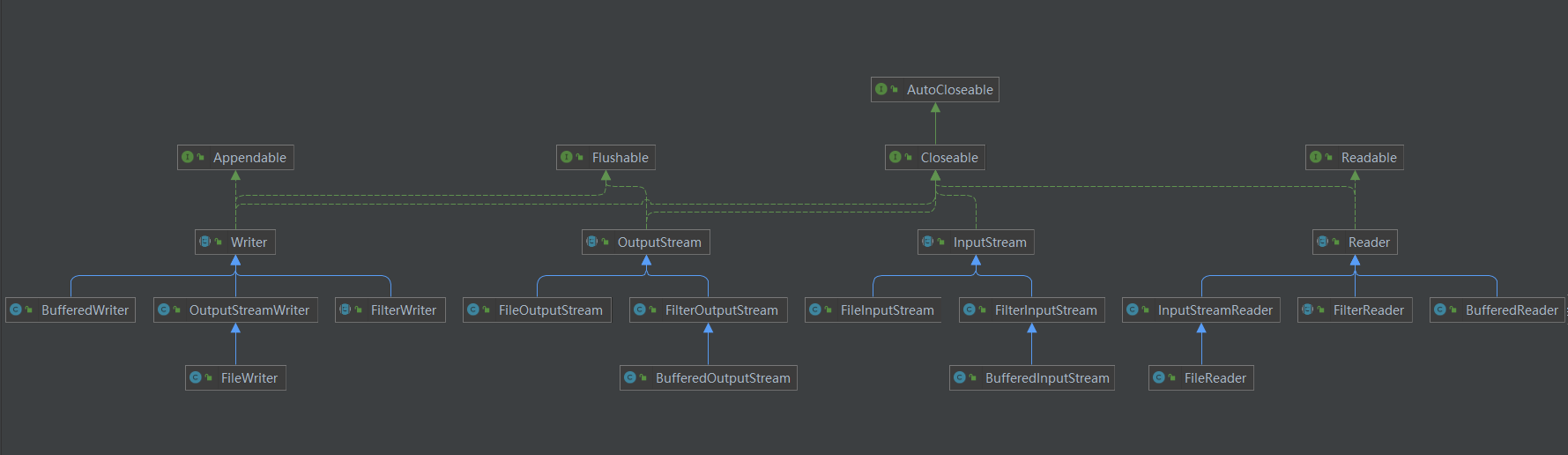
节点流与包装流
- Java IO详解(五)------包装流 - YSOcean - 博客园 (cnblogs.com)
- JAVA I/O流 字符流和字节流、节点流和处理流(包装流、过滤流)、缓冲流_过滤流和缓冲流,字节流的关系_X-Dragon烟雨任平生的博客-CSDN博客
字符流
import org.junit.jupiter.api.Test;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class CopyBytes {
public static void main(String[] args) throws IOException {
}
//单个字节的读取
@Test
public void test1() throws IOException{
FileInputStream in = null;
FileOutputStream out = null;
String path="src\\single\\in.txt";
String dpath="src\\single\\out.txt";
try {
in = new FileInputStream(path);
//String,boolean true追加;false覆盖,默认
out = new FileOutputStream(dpath,true);
int datacode;
//read()一次读取一个字节,返回读取字节的ASCII码,返回-1,表示读取完毕
while ((datacode = in.read()) != -1) {
System.out.println(datacode);//输出ASCII码 例如 a 是97 ;一个汉字是3个字节
System.out.println((char)datacode);
out.write(datacode);
}
} finally {
if (in != null) {
in.close();
}
if (out != null) {
out.close();
}
}
}
@Test
public void test2() throws IOException{
FileInputStream in = null;
FileOutputStream out = null;
String path="src\\single\\in.txt";
String dpath="src\\single\\out.txt";
try {
in = new FileInputStream(path);
out = new FileOutputStream(dpath);
//一次读取多个字节,返回读取字节的长度
byte[] buf=new byte[3];
int datalen=0;//实际读取的长度,读取完毕返回-1
while((datalen=in.read(buf))!=-1){
System.out.println(datalen);
System.out.println(new String(buf,0,datalen));
//System.out.println(new String(buf));//这样会导致读取异常,因为当最后一次读取不够时,上一次的读取并没有清空
out.write(buf,0,datalen);
}
} finally {
if (in != null) {
in.close();
}
if (out != null) {
out.close();
}
}
}
}
字节流
package file;
import org.junit.jupiter.api.Test;
import java.io.*;
public class FileReader_ {
public static void main(String[] args) {
}
//单个字符
@Test
public void readFile01() {
String filePath = "src\\file\\in.txt";
String dPath="src\\file\\out.txt";
FileReader fileReader = null;
FileWriter fileWriter=null;
int datacode = 0;
//1. 创建 FileReader 对象
try {
fileReader = new FileReader(filePath);
fileWriter=new FileWriter(dPath);
//循环读取 使用 read, 单个字符读取
while ((datacode = fileReader.read()) != -1) {
System.out.print(datacode);
System.out.println((char) datacode);
fileWriter.write(datacode);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fileReader != null) {
fileReader.close();
}
if(fileWriter!=null){
//这里一定要关闭,才会写入 或者flush
//close 等价于 flush + close
//底层还是字节流
fileWriter.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
@Test
public void readFile02() {
String filePath = "src\\file\\in.txt";
String dPath="src\\file\\out.txt";
FileReader fileReader = null;
FileWriter fileWriter=null;
int readLen = 0;
char[] buf = new char[8];
//1. 创建 FileReader 对象
try {
fileReader = new FileReader(filePath);
fileWriter=new FileWriter(dPath,true);
//循环读取 使用 read(buf), 返回的是实际读取到的字符数
//如果返回-1, 说明到文件结束
while ((readLen = fileReader.read(buf)) != -1) {
System.out.print(new String(buf, 0, readLen));
fileWriter.write(buf,0,readLen);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fileReader != null) {
fileReader.close();
}
if(fileWriter!=null){
fileWriter.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
缓冲流

package file;
import java.io.*;
/**
* @author 韩顺平
* @version 1.0
* 演示 bufferedReader 使用
*/
public class BufferedReader_ {
public static void main(String[] args) {
String filePath = "src\\file\\in.txt";
String dPath="src\\file\\out.txt";
//创建 bufferedReader
BufferedReader bufferedReader =null;
BufferedWriter bufferedWriter=null;
try {
bufferedReader=new BufferedReader(new FileReader(filePath));//也可以传入其他的Reader
bufferedWriter=new BufferedWriter(new FileWriter(dPath));
//读取
String line; //按行读取, 效率高
//说明
//1. bufferedReader.readLine() 是按行读取文件
//2. 当返回 null 时,表示文件读取完毕
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
bufferedWriter.write(line);
bufferedWriter.newLine();
}
} catch (Exception e) {
e.printStackTrace();
}finally {
//关闭流, 这里注意,只需要关闭 BufferedReader ,因为底层会自动的去关闭 节点流
try {
if(bufferedReader!=null) {
bufferedReader.close();
}
if(bufferedWriter!=null){
bufferedWriter.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
好处
- 使用更方便,屏蔽底层细节
- 使用缓冲读取,效率更高
- 功能更强大
大文件
- 前端上传文件之前,首先查询数据,比较md5值;如果存在,就提示秒传
- 如果不存在,前端分片上传,上传之前首先检查分片是否存在,如果存在,则不用上传实现断点续传
- 后端存储分片
- 文件上传完毕,合并分片成一个完整的文件,并保存文件记录到数据库
分布式文件系统
一个计算机无法存储海量的文件,通过网络将若干计算机组织起来共同去存储海量的文件,去接收海量用户的请求,这些组织起来的计算机通过网络进行通信
好处:
1、一台计算机的文件系统处理能力扩充到多台计算机同时处理。
2、一台计算机挂了还有另外副本计算机提供数据。
3、每台计算机可以放在不同的地域,这样用户就可以就近访问,提高访问速度。
- 常用的分布式文件系统 - 知乎 (zhihu.com)
minio
官网:https://min.io
中文:https://www.minio.org.cn/,http://docs.minio.org.cn/docs/
- 轻量,简单,功能强大
- 适合于存储大容量非结构化的数据,例如图片、视频、日志文件、备份数据和容器/虚拟机镜像等。支持大小从几k到5T
- 读写性能好
- MinIO集群采用去中心化共享架构,每个结点是对等关系,通过Nginx可对MinIO进行负载均衡访问。
- 冗余存储,安全性高
- 去中心化有什么好处?
在大数据领域,通常的设计理念都是无中心和分布式。Minio分布式模式可以帮助你搭建一个高可用的对象存储服务,你可以使用这些存储设备,而不用考虑其真实物理位置。
它将分布在不同服务器上的多块硬盘组成一个对象存储服务。由于硬盘分布在不同的节点上,分布式Minio避免了单点故障。如下图:
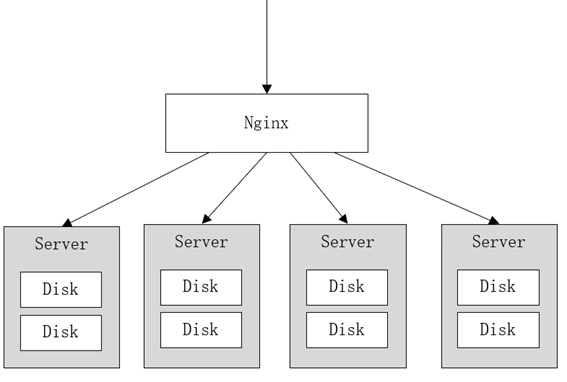
Minio使用纠删码技术来保护数据,它是一种恢复丢失和损坏数据的数学算法,它将数据分块冗余的分散存储在各各节点的磁盘上,所有的可用磁盘组成一个集合,上图由8块硬盘组成一个集合,当上传一个文件时会通过纠删码算法计算对文件进行分块存储,除了将文件本身分成4个数据块,还会生成4个校验块,数据块和校验块会分散的存储在这8块硬盘上。
使用纠删码的好处是即便丢失一半数量(N/2)的硬盘,仍然可以恢复数据。 比如上边集合中有4个以内的硬盘损害仍可保证数据恢复,不影响上传和下载,如果多于一半的硬盘坏了则无法恢复。