本文主要讲解哈希思想的实际应用,位图和布隆过滤器。
位图
讲解位图之前我们先来解答这样一道腾讯的面试题
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。【腾讯】
很多人立马就想到了用哈希表或者红黑树,因为足够快,特别是哈希表,它的查询速度到达了O(1),想法是非常好的,但是我们可以仔细思考一下,这样真的可行吗?
答案是不现实,因为这是四十亿个整数,如果要全部写入到内存中,需要16GB大小的空间,并不是所有的计算机都能装下这些数据,换而言之,就算能完全装下,用这么大的空间去解决这个问题,也是不太好的,面试官也不会满意。
所以这个时候就引入了位图,我们可以想一想,这个问题只是让我们求解一个整数在或者不在,这两种状态,我们只需要用一个bit位就可以标记,例如1代表在,0代表不在。再配合哈希的映射思想,就产生了位图这个数据结构。如果不了解哈希,可以看看我之前的文章,我进行了很详细的讲解,我把链接贴在这里:哈希。
可以先看一下位图的结构和代码是怎么实现的
template<size_t N>
class bitset {
private:
vector<char> bits;
public:
bitset()
{
bits.resize(N / 8,0);
}
//设置对应bit位
void set(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
bits[i] |= (1 << j);
}
//重置对应数值bit位
void reset(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
bits[i] &= ~(1 << j);
}
//是否存在
bool test(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
return bits[i] & (1 << j);
}
};
其实再C++库中是有位图结构的:bitset
布隆过滤器
上面的位图结构能很便捷的记录整数在或者不在,那么布隆过滤器是什么呢?
布隆过滤器(Bloom Filter)是一种空间效率非常高的随机数据结构,用于判断一个元素是否可能存在于一个集合中。布隆过滤器可以在时间和空间上做到很高效,但是会有一定的误判率。
布隆过滤器的核心是一个位数组和一组哈希函数。假设位数组的长度是 m,有 k 个哈希函数,则每个元素经过 k 次哈希函数得到 k 个哈希值,将这 k 个值对 m 取模,得到 k 个位置,将这 k 个位置的值都设置为 1。当要查询一个元素时,同样地,将该元素经过 k 次哈希函数得到 k 个哈希值,查询这 k 个位置的值是否都为 1,如果都为 1,则说明该元素可能存在于集合中,如果有任何一个位置的值为 0,则说明该元素一定不存在于集合中。
布隆过滤器的优点在于,它可以很高效地判断一个元素是否存在于一个集合中,而且空间效率非常高,因为它只需要使用一个位数组和一组哈希函数即可。但它的缺点在于,存在一定的误判率,也就是说,有可能某个元素不在集合中,但是经过判断后,布隆过滤器认为它存在于集合中。
简单来说就是一个元素通过K个哈希函数映射K个bit位,布隆过滤器如果说某个元素不存在时,该元素一定不存在,如果该元素存在时,该元素可能存在,因为有些哈希函数存在一定的误判。
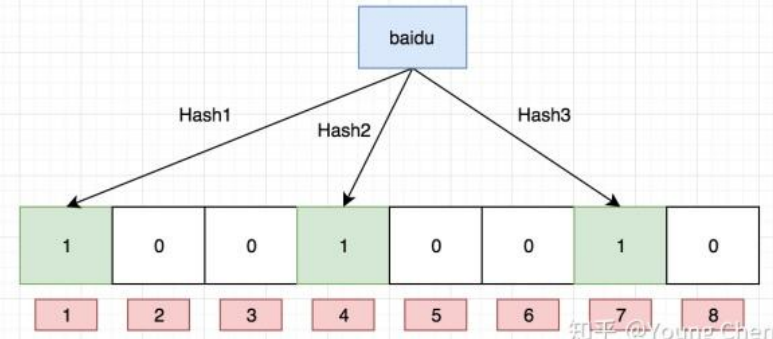
布隆过滤器实现代码:
struct BKDRHash
{
size_t operator()(const string& s)
{
size_t hash = 0;
for (auto ch : s)
{
hash += ch;
hash *= 31;
}
return hash;
}
};
struct APHash
{
size_t operator()(const string& s)
{
size_t hash = 0;
for (long i = 0; i < s.size(); i++)
{
size_t ch = s[i];
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ ch ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));
}
}
return hash;
}
};
struct DJBHash
{
size_t operator()(const string& s)
{
size_t hash = 5381;
for (auto ch : s)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
template<size_t N,
class K = string,
class Hash1 = BKDRHash,
class Hash2 = APHash,
class Hash3 = DJBHash>
class BloomFilter {
private:
static const size_t _X = 6;
bitmap<N* _X> bts;
size_t len = N * _X;
public:
void set(const K& key)
{
size_t hash1 = BKDRHash()(key) % len;
bts.set(hash1);
size_t hash2 = APHash()(key) % len;
bts.set(hash2);
size_t hash3 = DJBHash()(key) % len;
bts.set(hash3);
}
bool test(const K& key)
{
if (!bts.test(BKDRHash()(key) % len))
{
return false;
}
if (!bts.test(APHash()(key) % len))
{
return false;
}
if (!bts.test(DJBHash()(key) % len))
{
return false;
}
return true;
}
};
布隆过滤器使用的哈希函数越多误判率越低,但是占用的空间也就越大。用三个哈希函数是比较合适的。
这就是位图和布隆过滤器的原理和实现,如果对您有所帮助,点个赞和关注吧!