目录
一、搭建主从集群
1、介绍
2、搭建
二、数据同步原理
1、全量同步
2、主节点如何判断是不是第一次连接
3、增量同步
4、优化主从数据同步
一、搭建主从集群
1、介绍
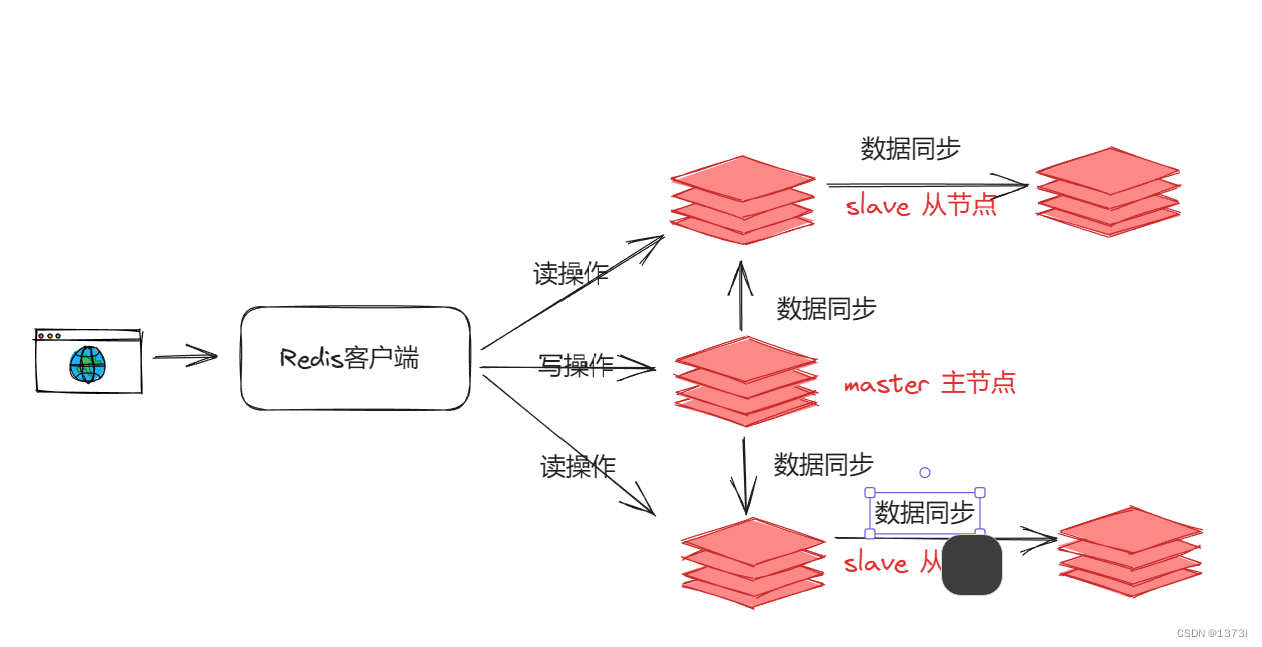
单节点的Redis并发能力存在上限,要提高并发能力就需要搭建主从集群,实现读写的分离,下面是Redis主从集群读写分离的整体架构。客户端所有的读操作都会去从节点,而所有的写操作都会去主节点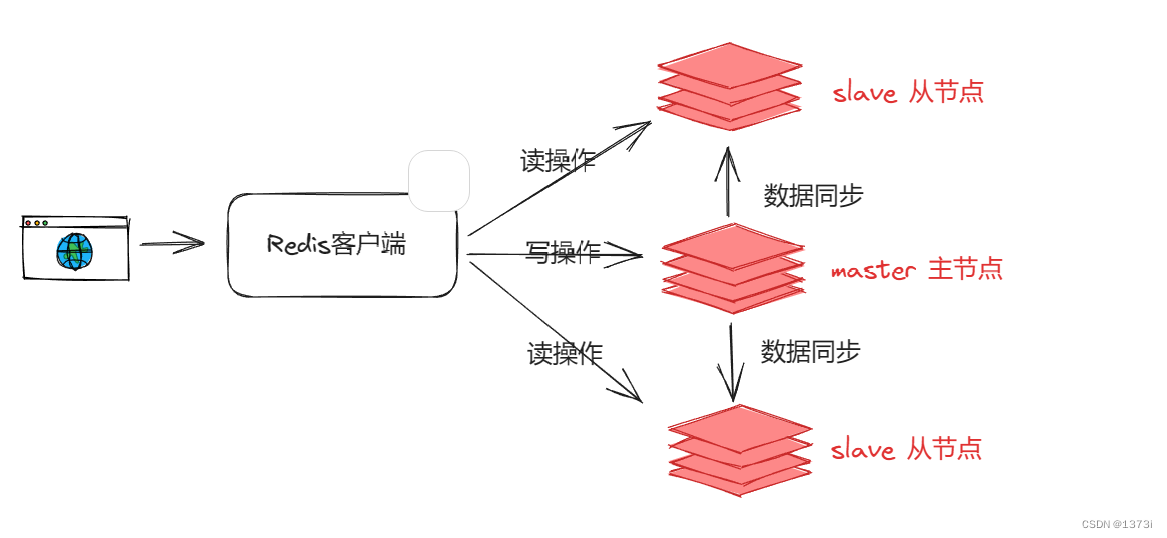
2、搭建
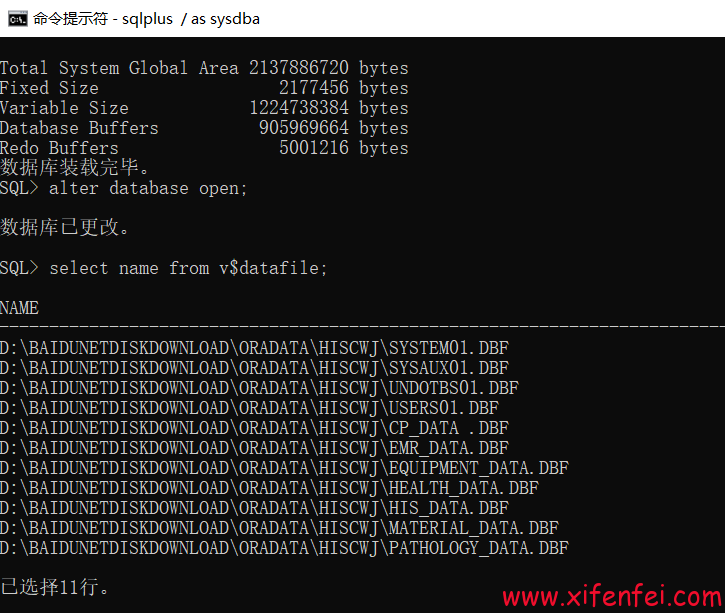
我们在本地部署三个Redis来模拟实现,手写我们需要准备三个不同的文件夹,在创建好文件夹后,我们需要分别将Redis的配置文件拷贝到这三个文件夹里并进行修改,首先我们需要开启RDB,然后修改端口以及RDB文件的保存路径,此时先打开主节点,然后再启动从节点在每个从节点执行一下命令就完成主从集群的搭建了
slaveof 主节点的IP 端口Port
二、数据同步原理
那么主从节点之间是如何进行数据同步的呢,当从节点第一次连接到主节点时会通过全量同步来同步数据
1、全量同步
当从节点执行slaveof 命令时会向主节点请求同步数据,此时主节点会判断他是否是第一次连接,判断是第一次连接后,主节点会返回一个自己的数据版本信息从节点收到后则会进行保存。此时主节点会执行一次bgsave将此时的数据进行快照,然后将结果也就是rdb文件发送给从节点,从节点收到后则清空本地数据加载rdb文件,在这个过程中主节点依旧会处理新的写操作的数据,那么这些新的数据如何同步呢,在rdb这个过程中主节点新的写操作会生成一个repl_baklog,主节点会继续将repl_baklog发送给从节点进行数据同步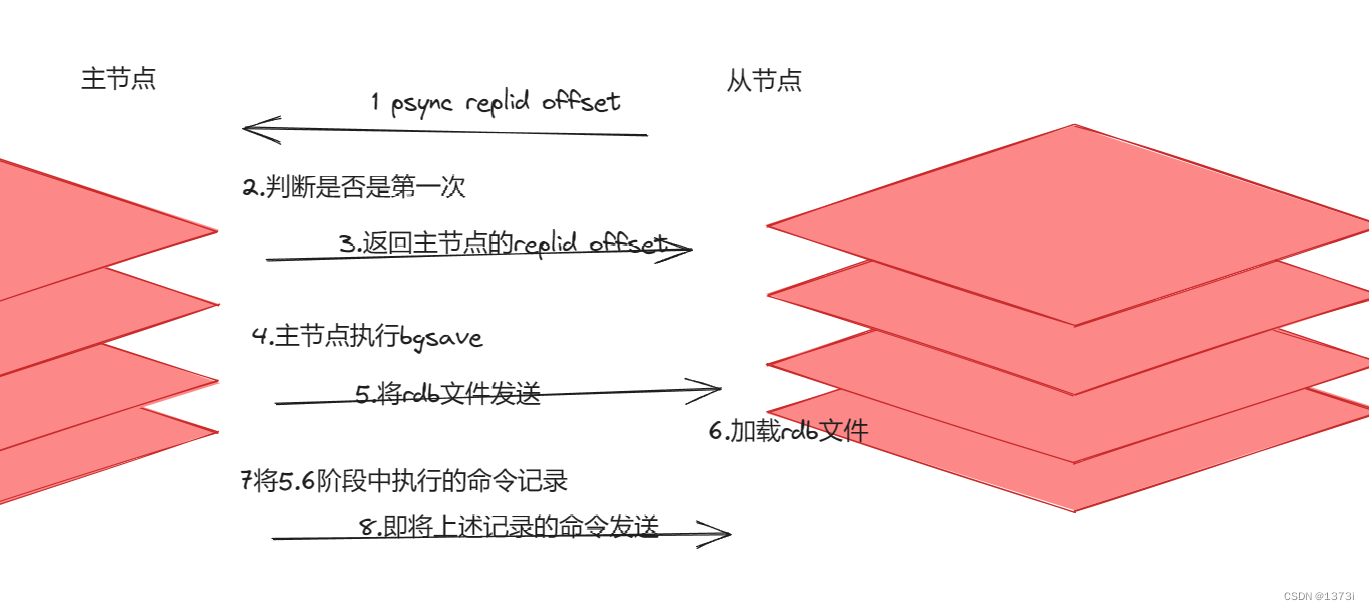
2、主节点如何判断是不是第一次连接
首先需要了解两个概念
replid:全称Replication id 是数据集的标识,id一致则说明是同一数据集。每一个主节点都有唯一的replid,slave节点会继承主节点的replid
offset:偏移量,随着记录的在repl_baklog中的数据增多而逐渐增大,slave完成同步时也会记录当前的offset。如果从节点的offset小于主节点的说明从节点数据落后,需要更新
所以从节点做数据同步时必须告诉主节点自己的replid与offset,主节点会根据replid是否一样来判断是否是第一次连接
3、增量同步
当从节点重启后会执行增量同步,从节点重启后会给主节点发送同步请求携带replid与offset,主节点判断它不是第一次连接后根据offset来判断是否进行增量同步,如果进行增量同步则将偏移量差的repl_baklog发送从节点
repl_baklog的大小是有上限的,它类似循环队列当写满后会覆盖最早的数据,如果从节点断开太长导致没有同步的数据被覆盖,则无法进行增量同步,进行全量同步
4、优化主从数据同步
1.在主节点的配置中开启无磁盘复制直接使用网络,避免全量同步时的磁盘io
repl-diskless-sync yes
2.redis单节点的内存占用不要太多,以此来减少RDB导致过多的磁盘io
3.适当提高repl_baklog的大小,当从节点宕机时尽快恢复,尽量避免全量同步
4.限制一个主节点上从节点的数量,如果实在有太多则可以采用主从从的链式结构,减少主节点的压力