目录
关系抽取两大类方法
CasRel(HBT)——ACL2020
1. 基本思想
2. 模型细节
2.1 头实体识别层
2.2 关系、尾实体联合识别层
2.3 原理解释
3. 实验
NLP 关系抽取 — 概念、入门、论文、总结 - 知乎 (zhihu.com)
关系抽取两大类方法
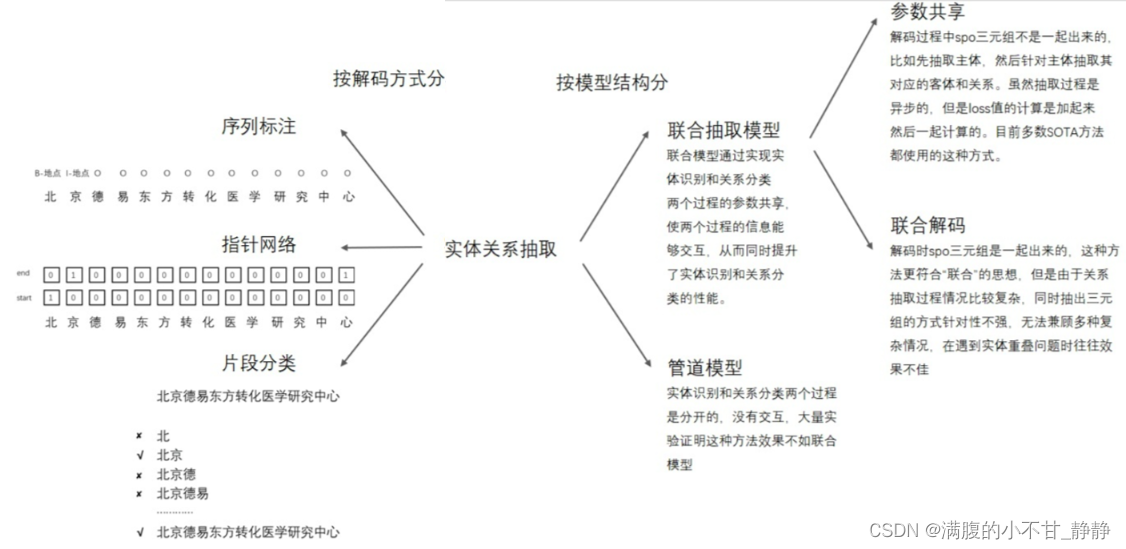
按模型结构分类,关系抽取主要分为 Pipeline 和 Joint 方法。 对于 联合抽取(Joint extraction),又可以分为 "参数共享的联合模型" 和 "联合解码的联合模型":
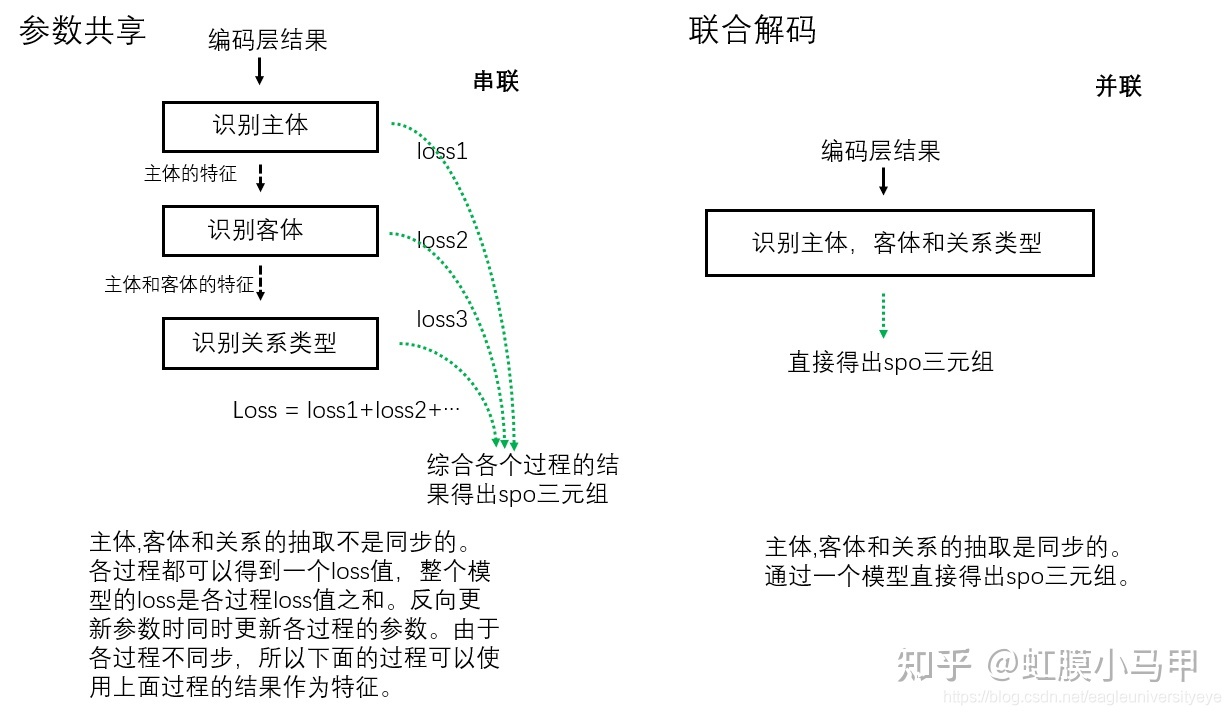
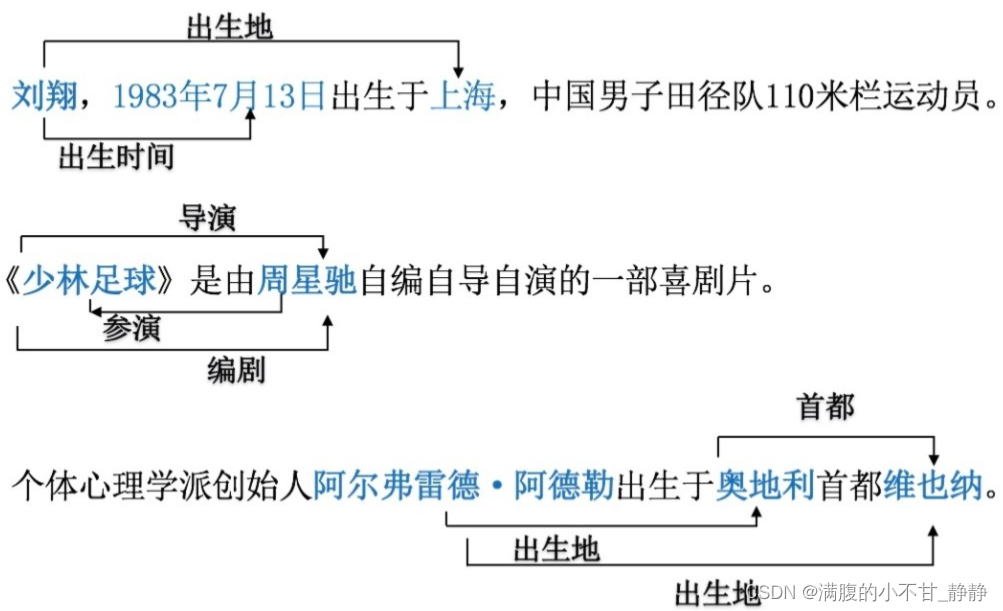
关系抽取要考虑的问题,如下图所示:
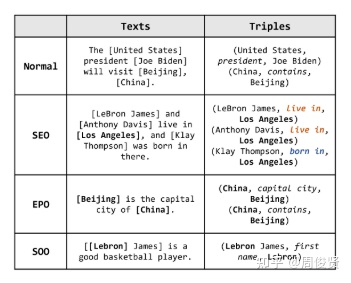
- SEO:SingleEntityOverlap,如上图中的Los Angeles与多个实体有关系
- EPO:EntityPairOverlap,如上图的China与Beijing有capital city和contains两个关系
- SOO:Subject Object Overlap,也有称为HOO(HeadTailOverlap)的,Subject和Object有nest嵌套的情况。
前沿的方法基本都能解决Overlap问题。而应用时,要看实际场景会不会遇到这些问题,假如没有的话,其实大部分方法都可以进行简化的。
CasRel(HBT)——ACL2020
论文名称:《A Novel Cascade Binary Tagging Framework for Relational Triple Extraction》
论文链接:https://aclanthology.org/2020.acl-main.136.pdf
代码地址:https://github.com/weizhepei/CasRel
pytorch 版本:https://github.com/powerycy/Lic2020-
文章:
一文详解关系抽取模型 CasRel - 知乎 (zhihu.com)
【关于 关系抽取 之 HBT】 那些的你不知道的事-技术圈 (proginn.com)
1. 基本思想
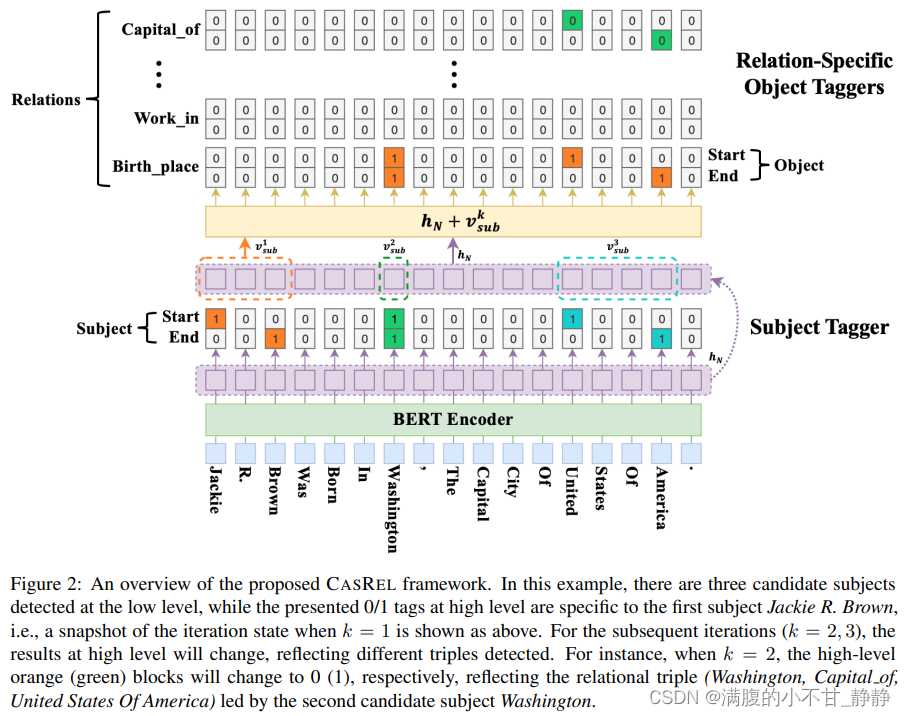
CasRel提出的动机最主要就是解决OverLap问题,至于CasRel里面提到的先抽主语,再把Predict和Object同时抽出来,并非CasRel的首创,最开始提到的应该是叫ETL的方法。
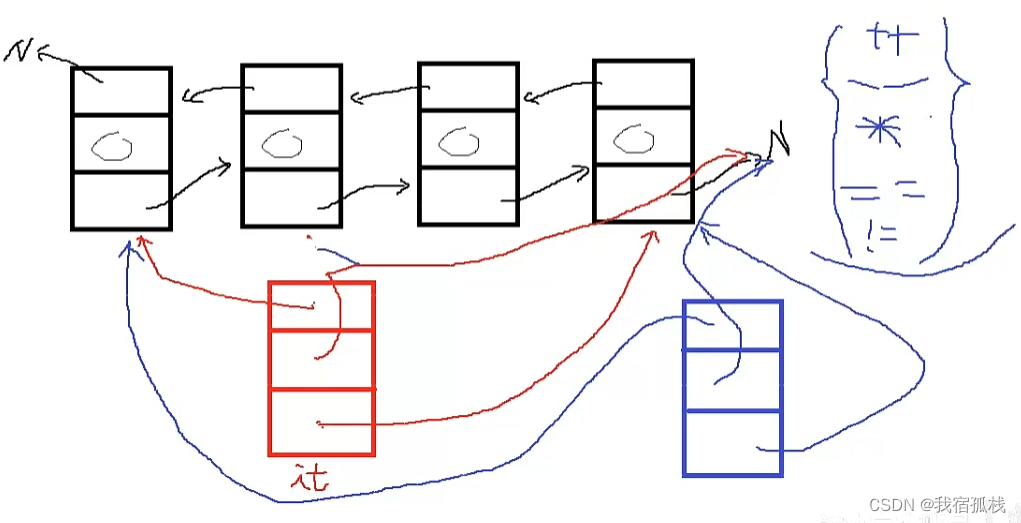
CasRel 本质上也是基于参数共享的联合实体关系抽取方法,它通常被大家称作层叠指针网络。实际上,CasRel 的核心思想或者说作者改进现有模型的重点在于子层的设计。
- 因为CasRel 对于关系抽取这个任务的拆分不同,所以子任务及子任务求解顺序也不同。具体地:(1)首先CasRel 会识别所有可能的主语(头实体);(2)然后在给定类别关系R下,再去识别与主语相关的宾语(尾实体)。
- 更形式化的表达,如果说以前关系抽取/关系分类是这样一个映射函数
,现在在CasRel中关系抽取对应的映射函数则是
。与之相似的思想很早之前就有出现在知识图谱表示学习方法当中,比如在下图的TransE模型中就有h+r≈t(这里h为头实体,t为尾实体)。
2. 模型细节
现在我们再来看CasRel的模型细节。CasRel是一个基于联合解码的实体关系抽取模型,其思想和模型都很简单,主要包括三层:
- 编码端:基于BERT的编码层用于获取上下文语义信息对字/词进行表征;
- 解码端:解码端主要包括了头实体识别层、关系与尾实体联合识别层。
在这里,基于BERT的编码层就不做过多的介绍了,感兴趣的读者可以下载论文《Pre-trained Models for Natural Language Processing》进行阅读学习。接下来,将着重介绍CasRel的解码端。
2.1 头实体识别层
CasRel的头实体识别层直接对编码层的结果进行解码,去识别所有可能的头实体。这里CasRel是识别头实体span,也就是start和end位置,所以它采用的是二分类。这点和实体识别BERT-MRC论文阅读笔记、实体识别LEAR论文阅读笔记 中类似。
因此,模型本身很简单:
- 首先,利用一个(线性层 + 一个sigmoid激活函数)判断每个token是不是头实体的开始token或结束token;
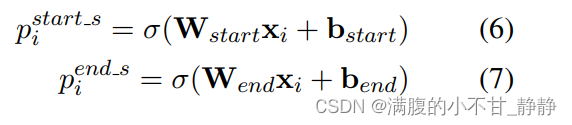
- 然后,利用最近匹配原则将识别到的start和end配对获得候选头实体集合。
2.2 关系、尾实体联合识别层
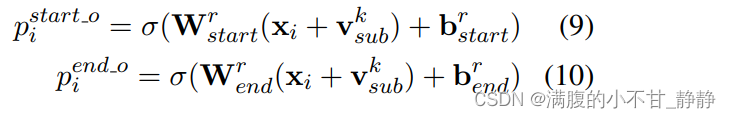
识别头实体后就要进行关系和尾实体的联合识别了。这里,CasRel是通过一组关系相关的尾实体识别层来实现的。每一层尾实体识别层的结构其实与头实体识别层是一样的,不同主要在于输入:
- 头实体识别层的输入直接就是编码层的输出;
- 而尾实体识别层的输入还考虑了头实体的特征:
这里是第k个候选头实体所包含的所有token的向量的平均。
2.3 原理解释
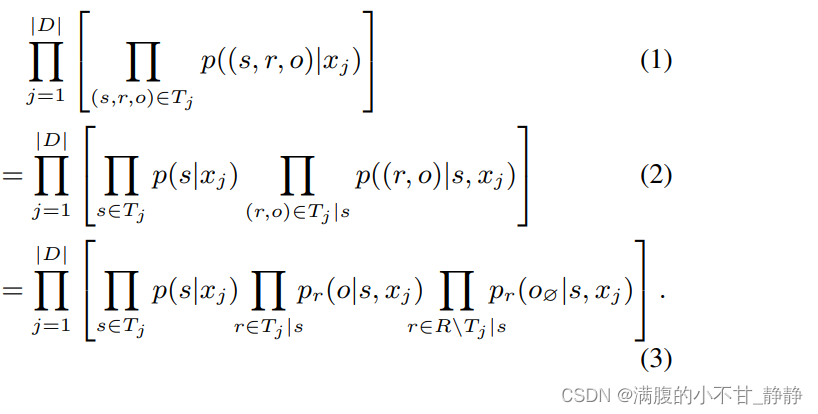
(1)优化目标
假设D为训练集,xj是第j个输入样本,是文本xj中含有的所有三元组,CasRel的训练目标自然是如下似然函数值最大:
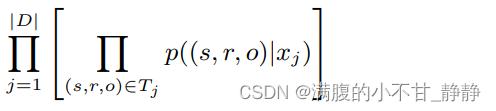
(2)概率公式变换
根据联合概率=边缘概率*条件概率,我们有:
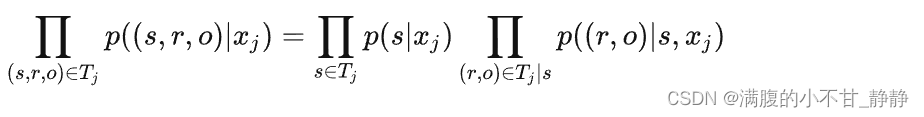
这里s∈Tj表示出现在Tj中的一个头实体,(r,o)∈Tj|s表示出现在Tj中且其头实体为s的一组关系-尾实体对。P(s|xj)为先验概率,P((r,o)|s,xj)为条件概率。
(3)关系作为先验知识
然后,把关系作为先验知识,我们可以进一步把上式右端第二项拆成两部分,即出现在Tj中且头实体为s的关系、其他关系:
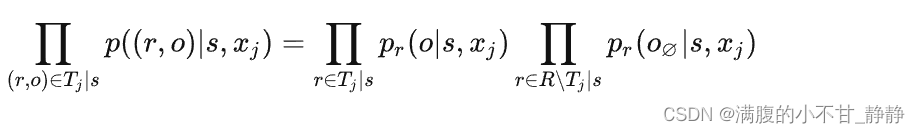
这里,R是所有关系的集合,r∈Tj|s表示出现在Tj中且头实体为s的一组关系,r∈R∖Tj|s是R与r∈Tj|s的差集,也就是没有出现在Tj中的其他关系。
表示对于文本xj与头实体s以及没有出现在Tj中的关系r来说,尾实体识别结果应当为空。所以最终我们有:
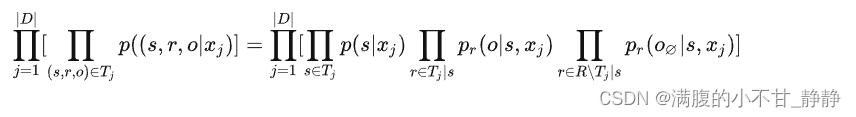
(4)结论
可以发现,最终这个式子与CasRel抽取实体关系三元组的子任务顺序一致:
- 首先识别文本中所有可能的头实体;
- 然后在每个关系类别下,去抽取与识别到的头实体存在该关系的所有可能的尾实体。
另一方面,这个任务拆解方式也很自然解决了重叠实体关系三元组的提取问题。
3. 实验
实验主要在两个公开的数据集 NYT 和 WebNLG 上进行。此外,需要注意的是CasRel模型本身还有两个变体:
- CasRelrandom:表示编码端的BERT参数是随机初始化的;
- CasRelLSTM:表示编码端使用的是LSTM而不是BERT。
当然CasRel则表示采用预训练好的BERT作为编码端。
(1)整体实验效果比对
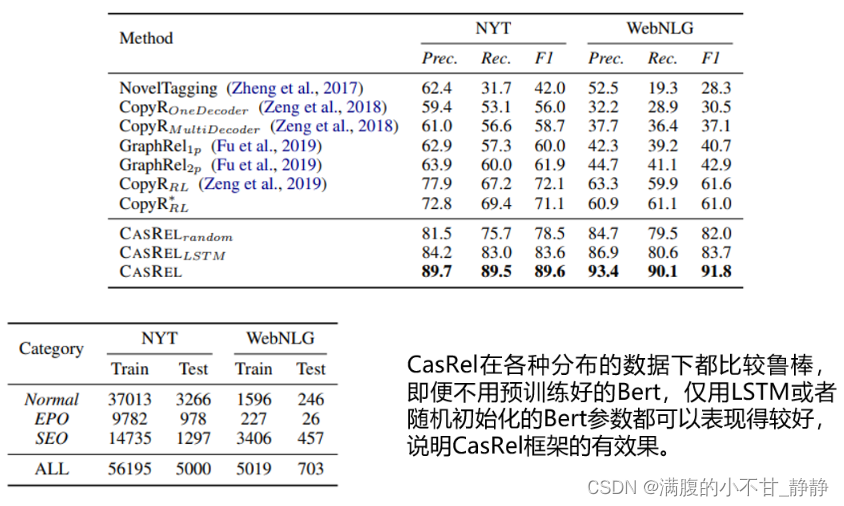
上图中展示了CasRel及其变体模型、、
与其他基准方法在两个数据集上的效果。可以看到CasRel 及其变体的效果都高于其他方法;尤其在WebNLG数据上,相对提升得更多。仔细看 NYT、WebNLG两个数据分布差异还是蛮大的:
- NYT、WebNLG两个数据中都有Normal类型的三元组、SEO类型的三元组、EPO类型的三元组,且三者在两个数据集中占比不同;
- Normal、SEO、EPO分别代表常规实体关系三元组、单个实体重叠的实体关系三元组、实体对重叠的实体关系三元组;
- NYT 中的实体关系三元组类型多为Normal类型,即数据中常规实体关系三元组居多。
- WebNLG 中的实体关系三元组多为SEO类型,即单个实体重叠的实体关系三元组居多。
CasRel 在两个数据集上相对稳定的表现说明了在实体关系重叠这种复杂场景下,其框架的有效性。
(2)不同三元组重叠类型实验对比
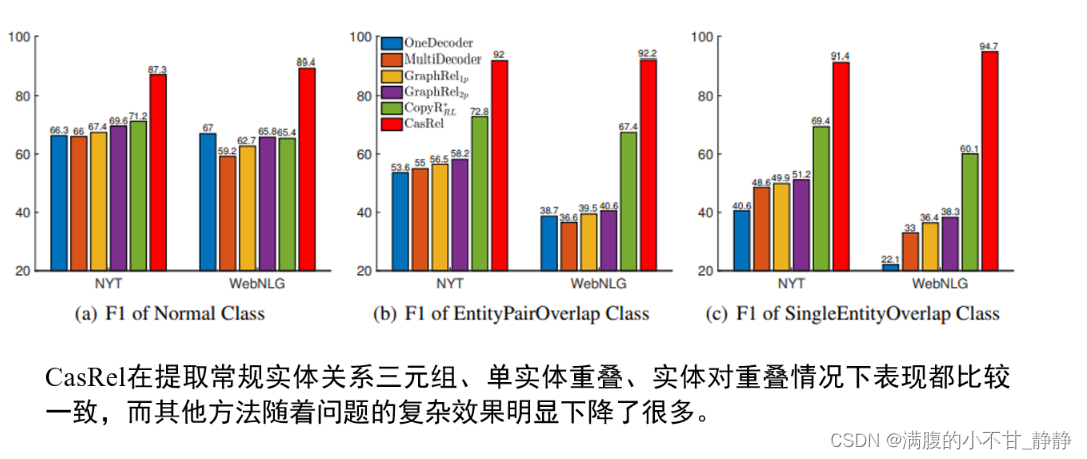
上图展示了在不同三元组重叠类型的样本上各个基准方法与CasRel的实验结果。可以发现随着场景逐渐复杂(Normal->EPO、SEO),基准方法的效果都逐渐下降,但CasRel则取得了相对稳定且优异的表现。这个对比实验进一步说明了CasRel在重叠三元组场景下的有效性。
(3)不同三元组个数实验对比
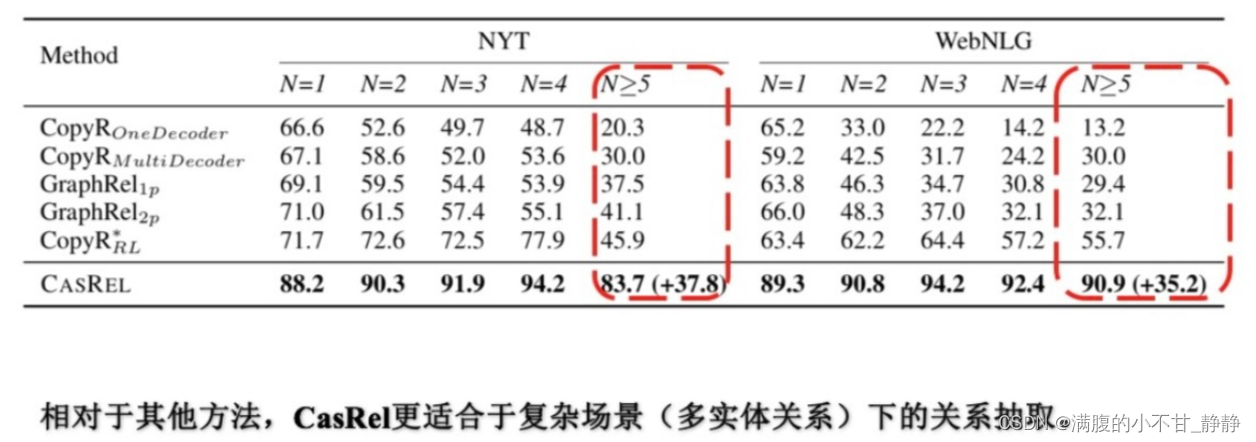
随着样本中三元组个数的增多,每个方法的效果都或多多少地受到了影响,尤其在N>5即多于五个三元组的样本上,基准方法效果基本都大幅度下降,而CasRel相对要好一些。同时,在N>5的样本上CasRel的效果相对于基准方法提升的最多。
这个对比实验反映了CasRel相比其他基准方法在处理多实体关系三元组下的能力更强。
参考:
NLP 关系抽取 — 概念、入门、论文、总结
一文详解关系抽取模型 CasRel - 知乎 (zhihu.com)









![[附源码]Python计算机毕业设计SSM健身房管理系统(程序+LW)](https://img-blog.csdnimg.cn/82e218dccbe846febad7fb4c0906e364.png)