友情提示:由于本专栏的文章偏向于爬虫,所以对于python的介绍不可能面面俱到,在这里只讲重点。 如果大家觉得有没讲到的地方,欢迎补充~
往期推荐:
【Python爬虫开发基础①】Python基础(变量及其命名规范)
【Python爬虫开发基础②】Python基础(正则表达式)
上一篇文章已经讲了Python的正则表达式,Python在爬虫开发时不免要涉及到数据的读写,今天来看一下一系列的文件操作!
文章目录
- 1 文件的编码
- 2 文件的打开、关闭以及读写和追加
- 2.1 操作汇总
- 3 文件操作常用模块—os模块
- 4 文件操作常用模块—json模块
- 5 文件操作及数据处理常用模块—pandas模块
- 5.1 pandas提供的数据类型
- 5.2 pandas提供的强大数据处理功能
- 6 处理CSV文件专用模块—csv模块
1 文件的编码
什么是文件编码?
文件编码是指将文本或二进制数据存储在计算机文件中的方式,以便在读取和写入文件时能够正确地识别数据类型、字符集和格式。
对于文本文件来说,文件编码决定了如何将字符编码成字节序列。常见的文本文件编码包括ASCII、UTF-8、GB2312、GBK、BIG-5 等等。
对于二进制文件来说,文件编码定义了用于表示特定格式数据的规则和约定。例如,PNG图像文件使用基于「非压缩的位图」编码规范保存像素数据,而PDF文件则采用 Adobe 公司开发的 PDF 语言进行编码。
为什么要使用文件编码?
- 文件编码可以确保数据的正确性:不同的字符集和格式可能采用不同的编码方式,如果不进行编码,则可能会导致文本内容或二进制数据的损坏和格式化错误。
- 文件编码可以提高可移植性:不同的操作系统和软件对字符集和编码的支持存在差异,在存储、读取和处理相同文件时,正确的文件编码可以确保数据在不同平台和应用程序之间的兼容性和互通性。
- 文件编码可以节省存储空间:一些编码方案具有压缩特性,可以将数据在硬盘及网络传输过程中占用的空间降至最小,从而提高工作效率并节约存储成本。
2 文件的打开、关闭以及读写和追加
在Python中,要进行文件操作,需要使用内置的
open()函数来打开文件,并返回一个文件对象。同时,为了避免资源浪费和数据损坏,还需要使用close()方法显式地关闭文件。读取和写入文件内容,则可以使用相关的读写操作符。
打开文件:
使用open()函数打开文件,它接受两个参数:文件路径和打开模式("r"表示读,"w"表示写,"a"表示追加),例如:
f = open("file.txt", "r") # 以只读模式打开指定文件
关闭文件:
使用close()方法关闭已经打开的文件,例如:
f.close() # 关闭文件
读取文件:
使用read()、readline()或readlines()方法读取文件内容,例如:
text = f.read() # 一次性读取整个文件内容到字符串中
line = f.readline() # 逐行读取文件内容(每次读取一行)
lines = f.readlines() # 返回所有行的列表
readlines()方法多用于for或者while循环中
写入文件:
使用write()方法向文件写入内容,例如:
f.write("hello world")
完成文件读写操作后,需要及时释放已占用的资源并将内存对象保存到磁盘。因此,建议对文件操作都使用with语句结构,在代码执行完毕后自动关闭文件,例如:
# 自动关闭文件并将文件内容写入到磁盘中
with open("file.txt", "w") as f:
f.write("hello world")
追加操作:
通过a模式打开即可,例如:
f = open('python.txt', 'a')
- 文件不存在会创建文件
- 件存在会在最后,追加写入文件
2.1 操作汇总
| 操作 | 功能 |
|---|---|
| 文件对象 = open(file, mode, encoding) | 打开文件获得文件对象('r’代表读,'w’代表写,'a’代表追加) |
| 文件对象.read(num) | 读取指定长度字节(不指定num读取文件全部) |
| 文件对象.readline() | 读取一行 |
| 文件对象.readlines() | 读取全部行,得到列表 |
| for line in 文件对象 | for循环文件行,一次循环得到一行数据 |
| 文件对象.close() | 关闭文件对象 |
| with open() as f | 通过with open语法打开文件,可以自动关闭 |
3 文件操作常用模块—os模块
Python内置的
os模块提供了一些与操作系统交互和操作相关文件和目录的函数
常用的包括以下几个:
os.chdir(path):
将当前工作目录改变为指定目录,例如:
import os
# 改变当前工作目录到 /user/newdir
os.chdir("/user/newdir")
os.getcwd():
返回当前工作目录的字符串名称,例如:
import os
# 输出当前工作目录
print(os.getcwd())
os.listdir([path]):
返回指定路径下所有文件夹和文件名的列表,例如:
import os
# 返回当前工作目录下的所有文件夹和文件
print(os.listdir())
os.mkdir(path):
创建单层目录。如果已经存在,则抛出异常,例如:
import os
# 创建/创建目录
os.mkdir("newdir")
os.makedirs(path):
递归地创建目录树。如果已经存在,则抛出异常,例如:
import os
# 递归创建新目录if it doesn't already exist
os.makedirs("newdir/subdir")
os.remove(path):
删除文件,例如:
import os
# 删除一个文件
os.remove("file.txt")
os.rmdir(path):
删除单层目录。如果目录非空,则无法删除,例如:
import os
# 删除目录"dirname"(注:目录必须是空的,否则无法删除)
os.rmdir("dirname")
os.rename(src, dst):
重命名/移动文件或目录,例如:
import os
# 将文件重命名(可用于移动文件)
os.rename("oldname.txt", "newname.txt")
4 文件操作常用模块—json模块
什么是json及其在python网络爬虫中的应用
json模块是Python中的一个内置模块,提供了一种简单的方式来处理JSON数据。JSON(JavaScript Object Notation)是一种轻量级的数据格式,常用于将数据从服务器发送到网页中,或者将数据从一个程序传递到另一个程序。
JSON在网络爬虫中应用广泛。网络爬虫可以从网站上爬取数据,将这些数据转换为JSON格式,然后进行分析和处理。JSON格式简单明了、易于解析、处理和传输,因此非常适合在网络爬虫中使用。
- json.dumps():
该函数用于将Python对象转换为JSON格式的字符串。obj参数可以是字典、列表、元组、整数、浮点数、布尔值和None等Python对象。skipkeys、ensure_ascii、check_circular、allow_nan、cls、default、indent、separators和sort_keys等参数可以用于设置转换时的各种选项和参数。
json.dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False)
该函数的定义如上述所示,下面用一个例子来演示一下这个函数的用法:
import requests
import json
url = 'https://jsonplaceholder.typicode.com/todos/1'
r = requests.get(url)
data = r.json()
# 将字典转化为JSON字符串并输出
data_json = json.dumps(data)
print(data_json)
# 将JSON字符串写入文件
with open('data.json', 'w') as f:
json.dump(data, f)
输出:
{"userId": 1, "id": 1, "title": "delectus aut autem", "completed": false}
上面的例子,我们请求了一个todolist API 的数据,并将其转化为 JSON格式的字符串,并输出到了终端。然后我们使用json.dump()将字典数据写入data.json文件中,以实现数据的持久化。
- json.loads():
该函数用于将JSON格式的字符串转换为Python对象。s参数是需要解析的JSON格式的字符串,encoding参数用于设置字符串的编码方式,cls、object_hook、parse_float、parse_int、parse_constant和object_pairs_hook等参数可以用于设置解析时的各种选项和参数。
json.loads(s, encoding=None, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None)
该函数的定义如上述所示,下面用一个例子来演示一下这个函数的用法:
# 定义如下 JSON 格式字符串
json_str = '{"name": "Alice", "age": 25, "isStudent": true}'
# 把这个字符串转成 Python 字典类型
data = json.loads(json_str)
print(type(data))
print(data)
输出:
<class 'dict'>
{'name': 'Alice', 'age': 25, 'isStudent': True}
在这个例子中,json_str 是一个 JSON 格式字符串,我们使用 json.loads() 将其解析成了 Python 字典类型 data。这样,就可以方便地对 JSON 数据进行处理和操作了。
需要注意的是,如果 JSON 数据格式不正确或无法解析,则 json.loads() 方法会抛出异常,需要进行异常处理。同时,在使用json.loads()方法时,也需要确保JSON数据是合法的,否则会导致数据解析失败、程序崩溃等问题发生。
5 文件操作及数据处理常用模块—pandas模块
Pandas库是一个开源的,易于使用的数据处理工具,它是Python编程语言的扩展库,为Python编程语言提供了快速,灵活和富有表现力的数据结构,简单而强大,是数据科学和数据分析中常用的库之一。
5.1 pandas提供的数据类型
- Series
Series是一个一维数组对象,类似于带有索引的numpy数组。它可以包含任何数据类型,例如整数、浮点数、字符串、Python对象等。Series是面向标签的,可以使用标签进行检索。
代码示例1:
import pandas as pd
#Series创建方式1:
#由列表或numpy数组创建
s1 = pd.Series(data = np.random.randint(0,10,size=5), index = list('abcde'), name = 'str1')
print(s1)
输出:
a 4
b 2
c 6
d 8
e 7
Name: str1, dtype: int32
代码示例2:
#方式2:
#由字典创建
s2 = pd.Series({'A':80,'B':30})
print(s2)
#key:行索引,value:数值
输出:
A 80
B 30
dtype: int64
- DataFrame
DataFrame是一个二维表格型数据结构,具有轴标签(行和列)。DataFrame可以看作是由多个Series组成的字典,它们共享相同的索引,融合了类似SQL表格上的操作。
代码示例:
import pandas as pd
# 创建DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'gender': ['female', 'male', 'male']
}
df = pd.DataFrame(data)
# 显示前几行数据
print(df.head())
# 筛选特定列
print(df['name'])
# 根据条件筛选行
print(df[df['age'] > 30])
# 添加新列
df['income'] = [5000, 6000, 7000]
print(df)
输出:
name age gender
0 Alice 25 female
1 Bob 30 male
2 Charlie 35 male
0 Alice
1 Bob
2 Charlie
Name: name, dtype: object
name age gender
2 Charlie 35 male
name age gender income
0 Alice 25 female 5000
1 Bob 30 male 6000
2 Charlie 35 male 7000
5.2 pandas提供的强大数据处理功能
Pandas也提供了强大的数据预处理、分析和建模功能
- 多种数据输入输出格式支持,如CSV、Excel、SQL数据库等:
首先演示一下如何读取并操作CSV文件:
'''
假定我们有一个名为“data.csv”的CSV文件,
其中包含有关城市、日期、天气和温度的数据。
'''
import pandas as pd
# 从CSV文件中读取数据
df = pd.read_csv('data.csv')
# 查看数据前5行
print(df.head())
# 查看数据信息
print(df.info())
# 对数据进行聚合
mean_temp = df.groupby('city')['temperature'].mean()
print(mean_temp)
pd.read_csv()是用于读取CSV文件的函数head()函数用于查看CSV文件的前5行info()函数用于显示数据类型和缺失值等详细信息groupby()函数根据指定的列对数据进行分组mean()函数计算每一组数据的平均值
这里展示如何使用Pandas读取并操作Exccel文件:
'''
以读取一个名为“data.xlsx”的Excel文件为例,
里面包含“Sheet1”工作表,
其中记录了城市、日期、天气和温度的信息。
'''
import pandas as pd
# 从Excel文件中读取工作表数据
df = pd.read_excel('data.xlsx', sheet_name='Sheet1')
# 查看数据前5行
print(df.head())
# 查看数据信息
print(df.info())
# 对数据进行聚合
mean_temp = df.groupby('city')['temperature'].mean()
print(mean_temp)
pd.read_excel()是用于读取Excel文件的函数,并且必须指定工作表名称或索引。- 其他部分与CSV文件操作相同。
以下是处理SQL数据库的实例代码:
'''
假设我们有一个MySQL数据库,
其中包含一个名为“weather”的表,
该表记录了城市、日期、天气和温度等信息。
'''
import pandas as pd
import mysql.connector
# 连接到 MySQL 数据库
con = mysql.connector.connect(user='root', password='password123',
host='localhost',
database='mydatabase')
# 从 MySQL 中选择对应表中的数据
query = "SELECT city, date, weather, temperature FROM weather"
df = pd.read_sql(query, con)
# 查看数据前5行
print(df.head())
# 查看数据信息
print(df.info())
# 对数据进行聚合
mean_temp = df.groupby('city')['temperature'].mean()
print(mean_temp)
# 关闭连接
con.close()
mysql.connector.connect()是用于连接MySQL数据库的函数,需要提供数据库的用户名、密码、主机地址和数据库名称等参数。pd.read_sql()方法接受一个SQL查询并返回一个DataFrame。- 其他部分与CSV文件操作相同。
- 数据清洗,包括处理缺失值、异常值等:
使用Pandas库可以方便地对数据进行清洗。下面将介绍如何使用Pandas库处理数据缺失值和异常值的常用方法。
在现实生活中,数据中经常会存在缺失值。这些缺失值有可能是由于人为操作出错,或者因为某些原因无法获得相应的数据等。
代码示例:
'''
假设我们有一个DataFrame包含以下三列:
日期、城市和温度,其中部分数据是缺失的:
'''
import numpy as np
import pandas as pd
# 创建 DataFrame,模拟数据中存在缺失值
dates = pd.date_range('2023-01-01', '2023-01-10')
df = pd.DataFrame({'date': dates,
'city': ['Beijing']*5 + ['Shanghai']*5,
'temperature': [np.nan, 20, 21, np.nan, 22, np.nan, np.nan, 19, 23, 24]})
print(df)
输出:
date city temperature
0 2023-01-01 Beijing NaN
1 2023-01-02 Beijing 20.0
2 2023-01-03 Beijing 21.0
3 2023-01-04 Beijing NaN
4 2023-01-05 Beijing 22.0
5 2023-01-06 Shanghai NaN
6 2023-01-07 Shanghai NaN
7 2023-01-08 Shanghai 19.0
8 2023-01-09 Shanghai 23.0
9 2023-01-10 Shanghai 24.0
可见,数据中涉及到多个缺失值。下面是使用Pandas库来处理数据缺失值的方法:
- 首先检查缺失值
# 检查数据是否存在缺失值
print(df.isnull().sum())
输出结果:
date 0
city 0
temperature 4
dtype: int64
其中.isnull()函数用于检查DataFrame中的缺失值,若该位置的值为空,则返回True;否则返回False。而.sum()函数用于统计每列中缺失值个数。
- 其次,删除缺失值
# 删除 DataFrame 中含有缺失值的行
df_dropna = df.dropna()
print(df_dropna)
输出:
date city temperature
1 2023-01-02 Beijing 20.0
2 2023-01-03 Beijing 21.0
4 2023-01-05 Beijing 22.0
8 2023-01-09 Shanghai 23.0
9 2023-01-10 Shanghai 24.0
此处使用了.dropna()函数来删除DataFrame中含有缺失值的行。.dropna()函数默认只要有缺失值就删除对应行,同时也可以通过参数来设定删除的方式,例如按列删除、保留至少有N个非空值等。
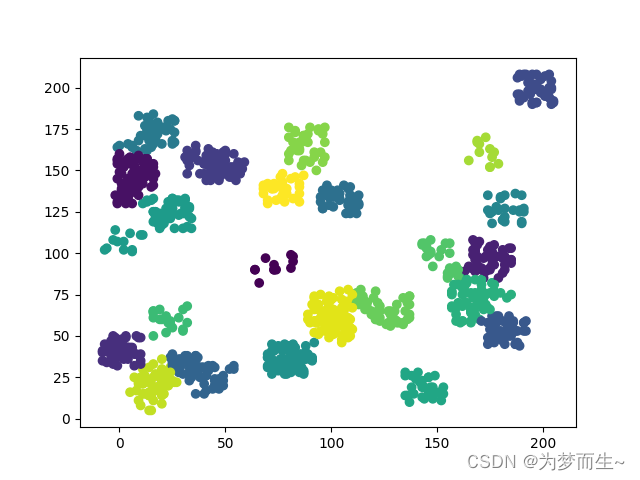
- 除此之外,pandas库还有强大的数据变换功能,包括重采样、聚合、合并、分组、填充等;时间序列分析与处理功能;数据可视化,支持通过Matplotlib库绘图。
例如:使用pandas库结合matplotlib以及sklearn,得到的K-Means聚类算法的结果图
6 处理CSV文件专用模块—csv模块
在Python中处理CSV文件是一种常见的任务。CSV文件是以逗号分隔值(Comma-Separated Values)的格式存储数据。除了上面介绍的pandas模块,csv模块也是一个比较合适的模块,下面来介绍一下csv模块的简单用法
- 读取CSV文件:
要读取CSV文件,可以使用Python内置的csv模块。首先需要将CSV文件打开并将其作为文件对象传递给csv.reader()函数。
代码示例:
import csv
with open('filename.csv', newline='') as csvfile:
reader = csv.reader(csvfile, delimiter=',', quotechar='"')
for row in reader:
print(', '.join(row))
上述代码中,我们用Python内置的with open()来打开CSV文件,指定参数newline=''解决防止出现多余的空行。然后,我们使用csv.reader()方法并传递CSV文件对象。此执行将会返回一个可迭代的活动列表(list)。您可以通过循环语句来访问每一行,或者逐行读取文本(最后一行是空的),并使用delimited和quote characters等选项控制行的分隔符和引号字符。
- 写入CSV文件:
要写入CSV文件,可以使用Python内置的csv模块中的csv.writer类。该类提供了writerow()方法,它允许您一次写入一行。
代码示例1:
import csv
with open('filename.csv', mode='w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['John Smith', 'Accounting', 'November'])
上述代码中,我们用Python内置的with open()打开文件,并指定了参数'Mode',并将其传递给csv.writer()函数。接下来,我们将需要写入CSV文件的数据传递为一个列表,并使用writerow()方法向CSV文件写入该行数据。
代码示例2(以字典写入):
import csv
data = [
{'Name': 'John', 'Age': 29, 'Country': 'USA'},
{'Name': 'Mary', 'Age': 22, 'Country': 'Canada'},
{'Name': 'Tom', 'Age': 31, 'Country': 'UK'}
]
with open('people.csv', mode='w', newline='') as file:
fieldnames = ['Name', 'Age', 'Country']
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
for person in data:
writer.writerow(person)
在这个例子中,我们创建了一个包含3个人员详细信息的字典列表。然后我们打开并创建一个名为"people.csv"的CSV文件,并使用DictWriter()函数和fieldnames参数指定要写入CSV文件的字段。最后,我们通过writerow()函数将每个字典写入CSV文件。函数writeheader()会自动写入表头。
注:除此之外,我们也可以利用一开始介绍的文件读写操作,选择’a’进行追加写入。