引言:
北京时间:2023/6/9/9:13,今天8:15起床,可能是最近课非常少,导致写博客没什么压力,什么时间都能写,导致7点起不来,哈哈哈,习惯睡懒觉了,但是问题不大,还在可控范围内,并且就在前天下午,我们进行了学校MySQL的期末考试,大一就学MySQL,我甚是想吐糟,实操题对于我来说问题不大,谁让我不仅是一个CSDN博主,逛CSDN我也是专业的,所以对于MySQL的骚操作我还是会的挺多的,导致一不小心在第一个实操题,就把后面想考的知识点都给用上了,哈哈哈!但是,有一个不好的消息,那就是实训课从线上改成了线下,呜呜呜,想哭,而且是那种一整天都是实训课,哇,真烦,主要是我们的电脑续航能力不怎么样,哎!废话不多说,事在人为,古有名言:谋事在人成事在天,我命由我不由天,哈哈哈,该篇博客我们将上篇博客有关右值引用的知识收个尾,并且学习有关拓展知识,最终通过模板可变参数相关知识,正式进入lambda表达式的学习!Let’s go go go!

右值引用剩余相关知识
上篇博客由于时间安排问题,导致最后还有一个很重要的知识点没有讲解,也就是下述我们即将要学习的有关移动赋值的知识,虽然移动赋值和移动构造本质没有什么太大的区别,掌握了什么是移动构造之后,学习移动赋值就如顺水推舟,但是,作为在右值引用相关知识中具有一定崇高地位的移动赋值,这里我们还是很有必要对它进行一定的解析,如下:
什么是移动赋值
同理,根据上述所说,移动赋值的本质原理和移动构造没有什么太大区别,所以按照我的老思路,学习一个东西就是通过对比或者图示来学习,这里简简单单,我们就通过移动构造来对比移动赋值,从而搞定什么是移动赋值,此时我们就来复习一下有关移动构造相关的知识吧!首先明白,发生移动构造的前提是该值是一个右值,由于自定义类型的右值是一个将亡值,一个不被程序需要的值,即将析构的值,此时编译器为了提高代码的执行效率和优化资源管理方式,它就可以通过右值引用的方式来间接识别到右值,从而执行相关移动构造代码,而非是原来左值相关的拷贝构造代码,但注意:上述移动构造,首先我们是针对自定义类型,其次我们针对的需要进行深拷贝的自定义类型,所以如果对应的对象是内置类型,或者是浅拷贝的自定义类型,那么本质移动构造和拷贝构造没有区别
正式学习移动赋值
明白了上述知识之后,此时我们就再来讲讲有关构造函数和赋值运算符之间的关系,这两者在我看来,本质都是用于初始化对象,只是被初始化对象存在一定的不同,所以它们之间最大的区别就是,被赋值对象和被构造对象是否定义,如果被初始化对象已经存在,那么此时就是赋值,反之构造,明白了这点之后,通过移动构造搞定移动赋值就等于是如鱼得水,同理,移动赋值在原理使用上和移动构造没有任何区别,也是在使用一个右值(将亡值)的前提下,直接将对应将亡值的资源通过赋值的形式,转移给被赋值对象,这种赋值方式,也就是闻名不如见面的移动赋值,如下图所示:
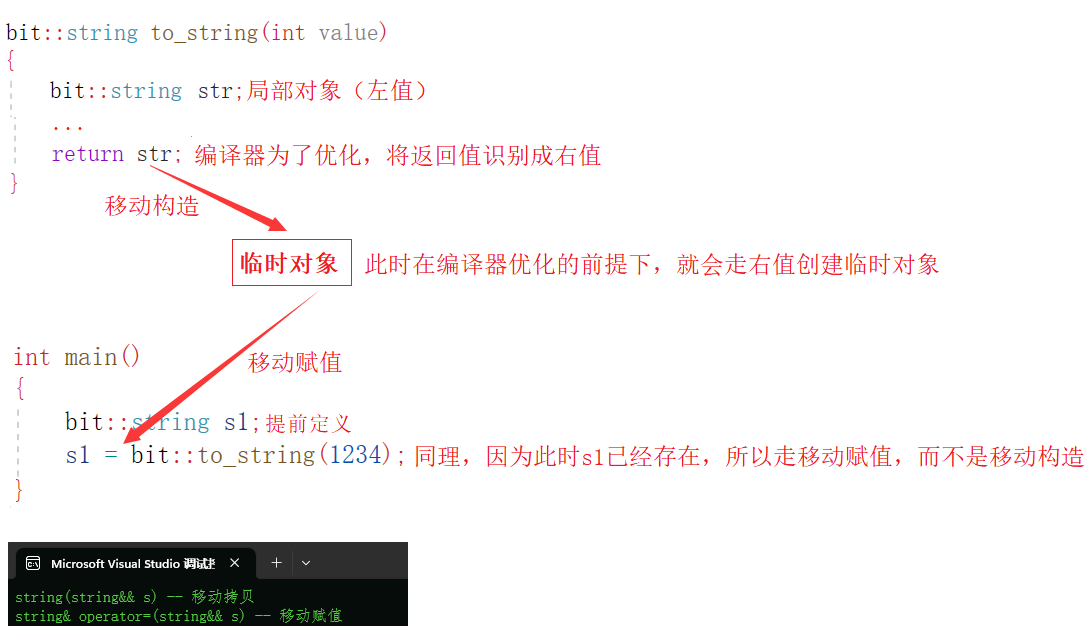
注意: 此时使用移动赋值的方式去接收函数返回值,不仅要使用移动构造,还要使用移动赋值的原因是:移动赋值和移动构造属于两种不同的初始化方式,编译器不会像移动构造一样,将两次移动构造给优化成一次移动构造,编译器可以进行优化的前提是,连续的构造,或者是连续的赋值,如下图所示:
同理,通过这个生活中的小场景,我们就知道,如果C想把钱要回来,就一定需要找B,最终间接通过B,将钱从A要回,而不能直接找到A,因为A根本就不认识C,无凭无据,这样肯定是不能完成目标,所以编译器也是同理,只有在连续构造或者是连续赋值的情况下,它才能完成优化,也就是在C认识A的情况下,通过一定的操作,最终完成要钱这个目标
移动构造和移动赋值的区别
搞定了上述知识,有关移动赋值具体的使用原理我们就搞清楚了,但是我相信很多同学都还存在一定的疑问,所以身为一个极具责任心的CSDN博主,此时我们必须将移动赋值和移动构造进行进一步的对比,首先上述我们虽然了解了构造和赋值最大的区别,也就是被初始化对象是否定义,但本质上构造和赋值还有一定的区别,如:构造是对将要被定义的对象申请资源后再去初始化它,而赋值是将自己对应的值直接赋值给被初始化对象,所以根据这一点的不同,移动构造和移动赋值,在本质上就有了区分,移动构造是直接将右值对应的资源转移给将要被定义的对象,而移动赋值却不同,因为在移动赋值前,被赋值对象已经存在,所以我们在进行资源转移的时候,就不仅会将右值对应的资源转移给被赋值对象,而且被赋值对象对应的资源也会转移给右值,而右值此时又即将被析构,所以右值此时对应的资源,也就是被赋值对象对应的资源,就会被间接析构,从而再一次提高了代码的执行效率和优化资源管理方式,具体如下图所示:

所以本质上,虽然调用移动赋值,需要多执行一次移动构造,但是由于移动赋值,可以间接释放资源,所以在效率方面二者并没有区别,如下就是移动构造和移动赋值两者在写法上最本质的区别,同理,移动赋值,被初始化对象是一个已经被定义的对象,而移动构造却是构造一个正在被定义的对象

最后明白: 无论是移动构造,还是移动赋值,本质都称为移动语义,目的:通过延长对应右值生命周期的方式,达到优化资源管理方式和提高代码执行效率,准确来说,是在延长对应资源的生命周期
const引用详解
搞定了上述有关移动赋值的知识,此时我们再来看看有关右值引用剩下的一些零碎知识,由于这些知识非常容易忽略,所以此时我们需要进行一定的总结,将这些旧饭给吃透,不然以后在具体场景分析的时候,容易搞混,导致分析不清或者分析不全,最终导致头大,所以接下来我们就一起看看有关const引用的知识,如何蹂躏我们
使用const引用具体场景分析
无论是之前在C++入门学习引用的时候,还是在学习右值引用的时候,我们都知道引用可以和const结合使用,并且使用场景还比较频繁,那么具体为什么要让const和引用结合在一起使用呢?首先就拿我们上篇博客学习左值引用什么时候能够引用右值来看,左值引用想要引用右值,那么就必须要加上const,本质是因为右值具有常性,那么在之前学习相关引用知识时,如:将引用作为函数参数,将引用作为函数返回值时,为什么也需要加上const呢?其实本质就是为了延长对应资源的生命周期,防止对应右值资源在传参使用之前发生析构,导致编译错误,如下图所示:

如上图,本质就是因为右值如果不使用const&接收,那么它就会被提前析构,本质和为什么左值引用使用const之后,就可以引用右值是一个道理,本质就是解决如何接收右值的问题,从而让右值的资源不会被提前析构,进而可以完成对应拷贝构造或者赋值构造任务,只有在完成任务之后,它才能合理释放,但是要注意的是,不是所有位置都可以使用const引用,例如:当使用一个const引用作为返回值时,此时就可能导致问题,如下图所示:

所以const和引用在一起使用时,一定要慎重,并且上述这种使用const引用返回局部对象的写法,一定要扼制,如果你想使用const引用作为返回值,那么就一定要保证该对象不是局部对象,不会随着栈帧的销毁而销毁,也就是该对象一定要是静态变量(static)或者是堆区变量(new),当然,最后的避免方法就是不用,如果你不使用const引用作为返回值,那么对应的局部变量返回值,在返回的时候,就会去构建一个临时变量,从而达到在析构之前保留对应数据,给调用位置使用,一切都是那么的合理,哈哈哈!小知识点: 此时的这个临时变量对于函数栈帧来说,如果较小,那么就放在寄存器中,如果较大,那么就放在相对于该函数的上一层函数栈帧上(通常是main函数)
C++11类的新功能
谈到类的功能,第一时间想起的,就应该是之前学习类和对象时学习的有关6个默认成员函数的知识,也就是我们经常都在用,都在说的什么构造呀,什么析构呀,什么拷贝构造呀,什么拷贝赋值呀,什么取地址呀,什么const取地址呀 ,但,这6个默认成员函数只是C++98中的内容,自从C++11之后,类在默认成员函数方面,就又增加了两个,也就是刚学不久的 移动构造和移动赋值 , 但,对于这两个函数,如果想让编译器自动生成,需要具备一定的条件,如下:
同理,本质就是在区别深拷贝和浅拷贝,如果识别是深拷贝,那么编译器就不会自动生成,只有当是浅拷贝的情况下,它才会自动生成,其实本质理解,就是同理深拷贝和浅拷贝,如果一个类是自定义类型,并且是浅拷贝,那么此时它的构造函数编译器就可以自动生成,程序也不会出现任何问题,但是如果该类是一个深拷贝的类,那么它的构造函数就不允许编译器去自动生成,而是一定要自己控制,不然就会导致程序崩溃(一个空间被析构两次),总而言之,移动构造和移动赋值就如同此时的深拷贝,本质就是因为编译器控制不住,会导致程序崩溃,所以需要我们自己手动来控制,具体编译器允许默认生成移动构造和移动赋值条件如下:
1.如果你没有自己实现移动构造函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个,那么编译器会自动生成一个默认移动构造(本质就是在防范深拷贝的类),大白话理解,就是这个类不是深拷贝,而是浅拷贝,那么编译器就生成默认移动构造函数,默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝(值拷贝),自定义类型成员,则需要看这个成员是否实现移动构造,如果实现了就调用移动构造,没有实现就调用拷贝构造(因为对于浅拷贝来说,移动构造等于拷贝构造)
2.如果你没有自己实现移动赋值重载函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个,那么编译器会自动生成一个默认移动赋值(同理),默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝(同理),自定义类型成员,则需要看这个成员是否实现移动赋值,如果实现了就调用移动赋值,没有实现就调用拷贝赋值(同理)
总:移动构造和移动赋值对于深拷贝的类来说需要自己手动实现,对于浅拷贝来说编译器会自动生成,但本质还是调用了拷贝构造和拷贝赋值
什么是可变参数模板
想要学习这个知识点,首先,我们还是得先通过一个自己较为熟悉的知识出发,所以此时我们就通过C语言中最为常用的 printf 接口出发,如下图所示:

从上图中我们可以看到,在C++使用说明中,printf 接口的第一个参数为const char* format,但是第二个参数却是...三个点,这两个参数表示的是什么意思呢?回顾我们之前在C语言中使用printf接口打印数据,如下:

通过使用说明和使用场景,此时我们就可以推断出,const char* format表示的是一个字符串常量,也就是上述引号中的内容,用于指定输出格式和对应变量的类型,而后序的三个点(...)表示的就是我们需要输出的变量,并且由于我们可能需要同时输出多个变量,具体几个编译器也不知道,所以就把第二个参数设计成了...的形式,表示的就是可变参数,这样就可以让printf接收任意个变量,打印任意个变量对应的数据,同理,此时我们将要学习的可变参数模板也是这个道理,如下图所示:

如上图,我们可以看出,当我们使用可变参数模板定义了一个函数接口之后,这个函数就允许我们传任意类型,任意数据的参数,并且经过我们使用模板递归的方式,此时就可以将这个参数包,也就是我们传给该接口的所有参数打印出来,原理也就是使用模板推导类型,递归解析参数包,将参数包中的内容一个一个的解析出来
注意: 使用可变参数模板的本质特征在于那三个点(...)和命名没有任何关系,这三个点才是关键,并且要明白,在使用对应参数包时,三个点的位置一定要符合语法规则,不然就可能出现错误
总:使用可变参数模板不仅可以解决某些函数接口在参数数量和参数类型上不固定的问题,而且还可以让函数接口适配多种类型和数量的参数,从而避免重复编写大量类似代码
emplace系列
了解了上述有关可变参数模板的知识之后,知道可变参数模板在许多方面的用处还是非常大的,例如:在STL中许多容器就是使用可变参数模板进行的封装,最为经典的就是emplace系列,如下:


可以发现,像list和vector等这些经典的容器,都增加了emplace系列,并且注意:emplace接口的功能和insert是相同的,emplace_back的功能和push_back是相同的,都是尾插数据,此时也就是表示,STL中的容器都支持使用可变参数模板来插入数据,也就是因为emplace系列使用的是可变参数模板实现,所以只要是push_back和insert支持的功能,emplace系列都可以支持,但是两者在某些方面的插入效率上存在一定的差异,如下对比所示:
emplace_back和push_back对比
由于这两个接口在使用上非常的相似,并且C++语法模板都是一样的,所以两个接口在实际使用上区别非常小,所以想要区分这两个接口在插入效率上的差异,我们就需要进行比较全面的对比,下述我们分为两个方面进行对比,浅拷贝的类和深拷贝的类,如下:
1.深拷贝的类
当我们谈到的是一个深拷贝的类时,此时最重要就是就是区分拷贝构造和移动构造,所以在插入数据时也不例外,同样需要区分的就是看该接口在对应左值和右值不同的情况下,调用的是拷贝构造还是移动构造,如下图所示:
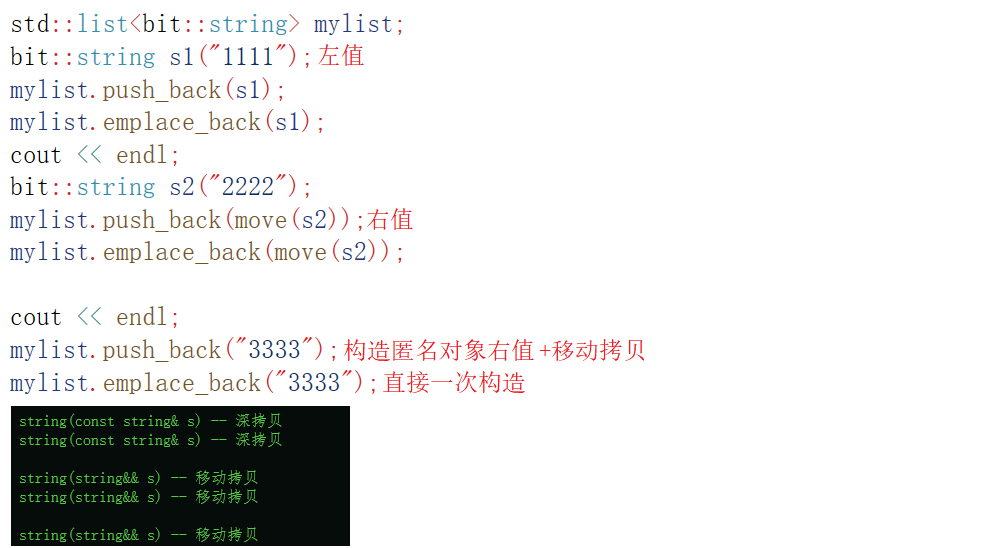
此时我们可以发现,当一个类是深拷贝的类时,无论是左值还是右值,push_back和emplace_back在本质上调用的构造接口都是相同的,唯一的一点不同是,当在直接插入右值时,由于push_back需要先进行一次隐式类型转换,也就是构造一个匿名string对象,然后再去调用移动拷贝,而,emplace_back由于是使用可变参数模板,此时如果给它一个字符串类型,那么它就可以直接通过参数包的形式,用这个参数包直接去构造结点,最后插入,所以在深拷贝的类中,push_back和emplace_back的本质区别就在于面对一个字符串常量类型时,push_back需要隐式类型转换成右值再移动拷贝,而emplace_back则可以直接使用模板参数包构造,但注意:这两者在效率上没有任何的区别
总:对于深拷贝而言,push_back和emplace_back在插入效率方面上,没有太大区别
注意: emplace_back可以通过参数包直接在容器内部构造对象,避免了额外内存分配和拷贝,所以虽然二者在效率方面没什么区别,但使用时应根据实际应用场景和要求使用对应的接口
2.浅拷贝的类
同理,对于浅拷贝的类来说,重点也是区分push_back和emplace_back在插入左值和右值时调用的是拷贝构造还是移动构造,如下图所示:

同理,可以看出,这两者在上述插入情况下没有什么区别,此时同理深拷贝,我们去看看push_back和emplace_back在常量数据面前是否有什么区别吧!如下图所示:

此时可以看出,同理,在直接面对插入数据时,push_back需要先构造出临时对象再拷贝构造,而emplace_back却只需要一次构造,所以此时当浅拷贝对象中需要拷贝的数据非常多时,那么此时push_back和emplace_back就存在了一定的效率差距,因为push_back需要多执行一次拷贝构造,但注意:和深拷贝刚刚的差距这里有所不同,虽然在深拷贝中,push_bakc也比emplace_back多了一次移动拷贝,但是注意,深拷贝的移动拷贝本质是在进行资源转换,和浅拷贝的拷贝构造是完全不同的,所以可以说深拷贝两者插入效率无差异,浅拷贝两者插入效率存在差异
总:对于浅拷贝而言,当需要拷贝的数据量非常大时,push_back和emplace_back在插入效率方面上有一定的区别
lambda表达式
搞定了上述知识,此时正式进入该篇博客的重点,lambda表达式相关知识,之所以lambda表达式相关知识能作为该篇博客的重点,而不是可变参数模板,其实本质还是因为可变参数模板对于我们平时编码,并没有很大的用处,我们只要认识它,知道它的基本使用方法就行,不需要深刻掌握,但是lambda表达式在许多编码方面对我们提供的好处很多,所以需要掌握,并且在编码中使用lambda表达式,不仅可以让我们的代码更加简洁,重点是还可以让我们的代码变得更加灵活,具体需要从代码场景中分析,总之,lambda表达式可以很好的提高代码的可读性和代码的灵活性,具体如下图演示:
引出问题:

从上图我们可以看出,当我们想要对一个自定义的类进行排序时,此时不仅需要该类对象中的迭代器数据,而且还需要有一个具体的比较规则,但是由于这个类是一个自定义类型的类,所以sort接口并不知道具体应该按照什么原则进行排序,所以我们需要自己实现一个仿函数,用于规定该类的比较规则,并且允许sort接口使用该仿函数对象去调用该仿函数接口,从而达到按照自己的预期进行排序,但是我们可以发现,对应的仿函数实现和sort接口调用仿函数对象,两者之间的关系并不密切,我们不能通过sort接口中调用的仿函数对象,一眼看出具体的比较规则,而是一定要去寻找到对应的仿函数,才能知道对应排序是按照什么规则进行,代码可读性非常的差,所以为了解决这个问题,此时就出现了我们即将要学习的lambda表达式,它的出现,就可以很好的解决这一类现象出现的问题,如下:
正式进入lambda表达式的学习
基础语法:分为四个部分
1.捕捉列表(用
[]表示)
2.参数列表(用()表示)
3.返回值类型(用->表示)
4.函数体(用{}表示)
具体使用样例如下图所示:

注意: 此时[](int x, int y)->int {return x + y; };表示的是一个lambda对象,所以上述代码具体表示的意思就是将lambda对象赋值给add对象,目的:可以直接使用add对象去调用lambda对象,从而实现lambda表达式,具体lambda表达式如下:

同理,此时我们就可以直接使用[](int x, int y)->int {return x + y; };对象去调用lambda表达式,或者是使用add对象去调用lambda表达式
明白了上述lambda表达式的具体使用方法之后,此时就可以正式解决上述那个有关排序代码可读性差的问题了,当然也就是lambda最常用的一个场景,如下图所示:

总: lambda表达式在提高代码可读性和代码灵活性方面非常有优势
搞定了上述知识,此时我们就深入探讨一下lambda表达式的使用,当然这块知识重点想要讲的就是lambda表达式的一些使用特点,其中捕捉列表,能够捕捉上下文所有的变量供给lambda函数体使用,参数列表,指定调用lambda函数时,需要传递的参数,
返回值类型,指明参数返回值对应的类型,函数体,用于具体代码编写,其中 注意: 参数列表和返回值允许省略,但捕捉列表和函数体不允许省略,如下就是捕捉列表的详细捕捉场景: