背景:分布式锁在后端开发者会用到,它有哪些特点呢?
在分布式系统中,一个应用部署在多台机器当中,在某些场景下,
为了保证数据一致性,要求在同一时刻,同一任务只在一个节点上运行,即保证某个行为在同一时刻只能被一个线程执行;
在单机单进程多线程环境,通过锁很容易做到,
比如mutex、spinlock、信号量等;而在多机多进程环境中,此时就需要分布式锁来解决了;
所谓的分布式场景就是:多机器,多网段,通过socket通信。
需要注意的问题
互斥性
同时只允许一个持锁对象进入临界资源;其他待持锁对象要
么等待,要么轮询检测是否能获取锁;
有唯一的标识。
锁超时
允许持锁对象持锁最长时间;如果持锁对象宕机,需要外力
解除锁定,方便其他持锁对象获取锁;
高可用
锁存储位置若宕机,可能引发整个系统不可用;应有备份存储位置和切换备份存储的机制,从而确保服务可用;
在合理的时间内得到合理的回复,备份点可以理解为不同的服务器,总节点数应为奇数。
容错性
若锁存储位置宕机,恰好锁丢失的话,是否能正确处理;
当一个“上锁/解锁”的请求应答过半时,就可以认为请求成功。
etcd , redis ,mysql 这三种数据库做分布锁对比
- 完备性 etcd > redis > mysql
- 性能 redis > etcd > mysql
- 选择:如果系统上三者都有,选etcd; 如果只有mysql,不会为了实现分布式锁而加入redis 或者 etcd
上面的内容太抽象了,怎么实现呢?
需要抓住 “多机器,多网段,通过socket通信” 这个分布式的要义,然后分布锁是通过数据库的表去实现的,
表里面的primary-key对应 分布式锁的唯一性
以mysql为例尝试性解释
相关的代码:
创建表:
DROP TABLE IF EXISTS `dislock`;
CREATE TABLE `dislock` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT
COMMENT '主键',
`lock_type` varchar(64) NOT NULL COMMENT '锁类
型',
`owner_id` varchar(255) NOT NULL COMMENT '持锁对
象',
`update_time` timestamp NOT NULL DEFAULT
CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_lock_type` (`lock_type`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT
CHARSET=utf8 COMMENT='分布式锁表';
加锁
INSERT INTO dislock (`lock_type`, `owner_id`)
VALUES ('act_lock', 'ad2daf3');
解锁
DELETE FROM dislock WHERE `lock_type` = 'act_lock'
AND `owner_id` = 'ad2daf3';
互斥性的理解
加锁,某个节点往服务器表里面插入lock_type,它是唯一的,跟锁的特性一致,一旦数据库有了’act_lock’, ‘ad2daf3’,其它节点再想往里面插入,就会失败,相当于被锁住了。
方便理解可以参考下图
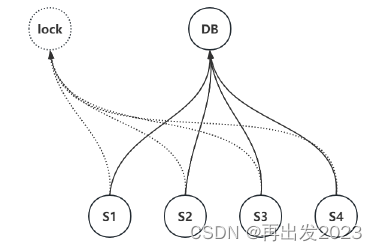
lock理解为数据库中的分布锁对应的表
节点S1通过socket发送加锁指令到lock,S2,S3,S4再发送加锁指令到lock,因为lock_type的唯一性,加锁失败;
只有等到S1通过socket发送解锁指令到lock,或者S1 lock超时,S2,S3,S4才有再次加锁的可能。
锁超时的理解
加锁、解锁的对象只能为同一个(超时除外),S1加的锁,只能由S1去解。
在S1宕机,或者通信故障的时候,由“锁超时”功能去处理,把超的锁解锁,或者删掉。
锁超时功能:在节点(服务器)开启超线程:对锁进行超时检测,超时就对其进行解锁
高可用性的理解
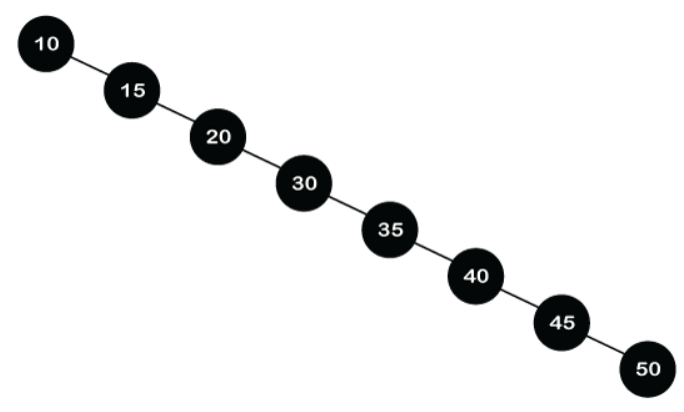
创建表,可以在多台机器上都创建,也就是备份,如下图:
开起多个备份点,R1~R5是含有lock的服务节点,它们之间的数据是相互备份的。
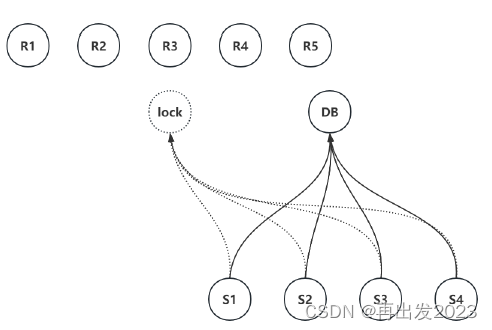
容错性的理解
假如R1宕机,
还可以从R2~R4获取数据。
另一方面,加锁、解锁等操作都可以同时向R1~R5发起,半数以上通过即可认为有效。
这里涉及到的算法有:raft一致性算法等
有些复杂了,暂更新到这。。。
文章参考与<零声教育>的C/C++linux服务期高级架构系统教程学习:链接