一、安装mysql
二、数据库操作
1、进入本地数据库
win + r 运行cmd.exe 输入命令 mysql -uroot -p 敲回车;随后输入密码;
-u用户名 -p密码;

1.1 连接远程数据库:mysql -h ip地址 -u 用户名 -p
mysql -h 10.10.25.159 -u root -p root
-h主机名 -u用户名 -p密码;
2、创建数据库
mysql> create database hh_test DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
Query OK, 1 row affected, 2 warnings (0.01 sec)create database hh_test 代表的是创建数据库 hh_test
DEFAULT CHARTERSET utf8 代表的是将该库的默认编码格式设置为utf8格式。
COLLATE utf8_general_ci :代表的是数据库校对规则:utf8_bin 将字符串中的每一个字符用二进制数据存储,区分大小写。utf8_genera_ci不区分大小写,ci为case insensitive的缩写,即大小写不敏感。utf8_general_cs区分大小写,cs为case sensitive的缩写,即大小写敏感。
3、查询数据库
show databases;

显示出当前PC中有哪些数据库,上图就是我PC中的数据库,因为我之前创建过数据库;
4、删除数据库
drop database **(数据库名);
5、选择数据库
use **(数据库名);

6、在当前数据库中创建一张表
create table movie(
id varchar(10),
title varchar(20),
subjects text,
ank int,
gender enum('man','woman'),
dtime timestamp
);
desc + 表名 显示表结构
6.1 数据类型
数值类型-整数型

在计算机中,可以区分正负的类型,称为有符号类型。无正负的类型,称为无符号类型。即:有符号值可以表示负数,0以及正数;无符号值只能为0或正数。
M表示整数类型的最大显示宽度。M表示整数类型的最大显示宽度。对于浮点和定点类型, M是可以存储的总位数(精度)。对于字符串类型, M是最大长度。允许的最大值M取决于数据类型。
数值类型-浮点型

D适用于浮点和定点类型,并指示小数点后面的位数。最大可能值为30,但不应大于 M-2。
数据类型-定点型
DECIMAL[(M[,D])] 常用于存储精确的小数,M是总位数,D是小数点后的位数。小数点和(负数) -符号不计入 M。如果 D为0,则值没有小数点或小数部分。最大位数(M)为 65. 最大支持小数(D)为30.如果D省略,则默认值为0.如果M省略,则默认值为10。M的范围是1到65。D范围为0到30,且不得大于M。
6.2 字符串类型

TEXT系列的存储范围比VARCHAR要大,当VARCHAR不满足时可以用TEXT系列中的类型。需要注意的是TEXT系列类型的字段不能有默认值,在检索的时候不存在大小写转换,没有CHAR和VARCHAR的效率高;
在ENUM中我们只能从允许值列表中给字段插入一个值,而在SET类型中可以给字段插入多个值。
6.3 日期时间类型

TIME我们可以看到TIME的存储范围是’-838:59:59’到 ‘838:59:59’,因为TIME类型不仅可以用于表示一天中的时间(,还可以用于表示两个事件之间的经过时间或时间间隔
TIME的完整的显示为 D HH:MM:SS
D:表示天数,当指定该值时,存储时小时会先乘以该值
HH:表示小时
MM:表示分钟
SS:表示秒
7、删除该数据库中的某一张表
drop table **(表名);
drop table **,**,**...;
第一条是删除一个表格,第二条是删除多个表格;
8、表的基本操作
8.1向表中增加数据
insert into **(表名) (字段1,字段2,字段3......) values (值1,值2,值3.......);
例如向 movie 中插入:
insert into movie(id,title,subjects,ank,gender,dtime) values('1','章鱼团长','长长的触手很长很长','10','man','2022-01-01 00:00:01.000000');
8.2查询数据
select * from **(表名);
select * from movie 这条命令是查询 movie 表格中的所有信息,*就代表所有。
查询该表内某字段的所有数据
select 字段1,字段2,字段3......(或用*代替所有字段) from **(表名);
例如:查询movie 表中的 title 字段:select title from movie;

查询某条件的所有数据
select * from **(表名)where 字段1 = 值1 and 字段2 = 值2 and ......;
select * from movie where ank="10"; 查询movie 表格中所有 ank 字段都为 10 的项;

模糊查询某条件数据
| 通配符 | 说明 |
|---|---|
| % | 与包含0个或多个字符串匹配 |
| _ | 与任意单个字符匹配 |
| [ ] | 与特定范围(例如[a-d]或特定集例如[abcdef])中的任意字符串匹配 |
| [^] | 与特定范围(例如,[^a-f])或特定集(例如,[^abcdef])之外的任意单字符匹配。 |
select * from 表名 where 字段 like '%值%';select * from movie where title like '_团长'; 查询movie 表格中所有title字以团长结尾的项(_下划线个数表示匹配字符个数)
 select * from movie where title like '%团长%'; 查询movie 表格中所有title字段包含团长的项
select * from movie where title like '%团长%'; 查询movie 表格中所有title字段包含团长的项
select * from movie where title like '团长%'; 查询movie 表格中所有title字段以团长开头的项
select * from movie where title like '%团长'; 查询movie 表格中所有title字段以团长结尾的项

升(降)排序
select * from **(表名) order by 字段x asc;(默认就是升序)
select * from **(表名) order by 字段x desc;(降序)
例如:movie 表格中按 ank 字段升序

按某条件排序
select * from **(表名) where 字段x = 值x oreder by 字段x asc(desc);
例如:movie 表格中 字段 gender 的值为 woman 按照升序排序
select * from movie where gender="woman" order by ank asc;

分组查询(group by)
1、分组查询是对数据按照某个或多个字段进行分组,在MYSQL中使用GROUP BY关键字对数据进行分组
2、GROUP BY关键字可以将查询结果按照某个字段或多个字段进行分组。字段中值相等的为一组
⑴分组的核心是:在查询SQL中指定分组的列名,然后根据该列的值进行分组,值相等的为一组
3、分组查询的基本的语法格式如下:
GROUP BY 字段名 [HAVING 条件表达式]
参数:
1、字段名:是指按照该字段的值进行分组(分组是所依据的列名称)
2、HAVING条件表达式:用来限制分组后的显示,符合条件表达式的结果将被显示1、对数据进行分组,一般有两种使用场景:
⑴单独使用GROUP BY关键字,
例如 movie 表格中按照性别分组 select * from movie group by gender;

如果直接查询某个列时:只会返回该分组内第一个值
⑵将GROUP BY关键字与聚合函数一起使用(常用)
例如 查询movie 表格中所有的数据,按照 gender 字段值进行分组,然后计算每组的记录条数 select gender, count(*) from movie group by gender;

2、GROUP BY关键字可以和GROUP_CONCAT()函数一起使用。GROUP_CONCAT()函数会把每个分组的字段值都显示出来。
select gender,count(*),group_concat(gender) as sex from movie group by gender;

使用GROUP_CONCAT()函数,就会返回该分组内所有的值
3、若用于分组的列中包含有NULL值,则NULL将作为一个单独的分组返回;若该列中存在多个NULL值,则将这些NULL值所在的行分为一组
多字段分组
1、使用GROUP BY可以对多个字段进行分组,GROUP BY关键字后面跟需要分组的字段

HAVING过滤分组
1、GROUP BY可以和HAVING一起限定显示记录所需满足的条件:只有满足条件的分组才会被显示
2、HAVING关键字是对分组结果进行过滤。WHERE关键字是对表数据进行过滤
⑴两者同时存在时:肯定是先计算WHERE,WHERE排除的记录肯定是不会出现在分组内的

上面例子:先按照 ank 进行分组,统计的列数;接着筛选 ank 小于 60;最后过滤 gender > 1
分组排序
某些情况下需要对分组进行排序
⑴一般情况下ORDER BY是用来对查询结果进行排序的。当其与GROUP BY一起使用时,可以对分组结果进行排序
select gender,ank,count(*) from movie group by ank order by ank desc;

连表查询(join)
数据查询时很多时候需要连表,查询出来的内容则包含2个表中的列内容,这个时候就需要用到连表,连表又分为左连接、右连接、内连接;
左查询是以左表为准(对应图中的article表),逐行在右表中进行筛选,如果有匹配到的值则正常显示,如果没有则用null填充;同理,右查询也是同样的道理;
内连
inner join会提取出2张表的共同交集
select * from 表名1 inner join 表名2 on 条件;
现有如下两张表 movie 与 copy_movie 如下所示
例如查询两张表 title 字段相等的 address 与 subjects ank 字段的值
select subjects,address,ank from copy_movie inner join movie on copy_movie.title = movie.title;
左外连
左外连接是以左表为基准,左表的所有数据都会显示,对于右表匹配到的就显示匹配的数据,没有匹配的就显示null.也可以把outer省略
select 字段 from 左表名 left outer join 右表名 on 条件;
例如:以copy_movie 为左表
select subjects,address,ank from movie left outer join copy_movie on copy_movie.title = movie.title; 
右外连接
select 字段 from 左表名 right outer join 右表名 on 条件;
右外连接是以右表为基准,右表的所有数据都会显示,对于左表匹配到的就显示匹配的数据,没有匹配的就显示null.
数据合并(union)
取前n条数据
select * from **(表名) limit n;
例如取 movie 表格中的前3条数据 select * from movie limit 3;

从第n条开始(起始位置是0)取m条
select * from **(表名) limit n,m;
例如: movie 表格中从第二条开始取两条数据 select * from movie limit 2,2;
查询某排序下的前n条数据
select * from **(表名) order by 字段x asc(desc) limit n;
例如:查询 movie 表格中 ank 字段升序排列的前两条数据 select * from movie order by ank asc limit 2;

8.3 删除数据
delete from **(表名) where 字段x = 值x;
先增加一条数据:
insert into movie(id,title,subjects,ank,gender,dtime) values('5','章鱼团长爸爸','长长的触手又粗又长孔武有力','60','man','2022-01-01 00:00:05.000000');

再将该数据删除
delete from movie where ank = "60";

8.4 修改数据
update **(表名) set 字段1 = 值1,字段2 = 值2 where 条件;
update **(表名) set 字段1 = 值1; (修改某一字段下的所有值)
例如:将 movie 表中 字段 gender 的值为 woman 的 字段 ank 与 title 分别修改为 40 与 小乌龟
update movie set title = "小乌龟",ank = 40 where gender="woman";

8.5 常用数据处理函数
sum(); 求和 select sum(字段x) from **(表名);
avg(); 求平均值 select avg(字段x) from **(表名);
max(); 求最大值 select max(字段x) from **(表名);
min(); 求最小值 select min(字段x) from **(表名);
count(字段x) ------统计该字段x的行数,如果该列的值是null,不统计在内
count(*) 统计所有的列,相当于统计行数,不会忽略null
在某字段条件下使用函数 select 函数名() from **(表名) where 字段x = 值x;
例如 :
id 字段求和

id 字段求平均值
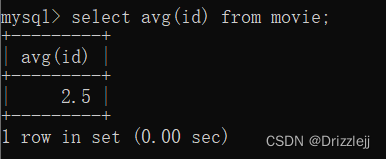
保留小数位数(round)
空置判断(ifnull)
条件判断(if)
分类查询(case when)
字符截取(substring、left、right)
9、操作表
9.1新增字段
alter table 表名 add 字段名 字段数据类型(长度) [character set 字段编码 collate 字段排序编码] [NOT NULL] [DEFAULT 0] [COMMENT ‘备注’] [(FIRST)|(AFTER 表中已存在字段)]CHARACTER SET 字段编码 COLLATE 字段排序编码:用于设置特殊字段的编码值。例如:表字段中如果要存储包含表情的字符串,但是数据库的编码是utf-8,那么表情会乱码。这时候就需要将字段的编码修改成utf8mb4。(alter table 表名 add 字段名 字段数据类型(长度) character set utf8mb4 collate utf8mb4_general_ci)
NOT NULL:代表该字段不允许为空。
EFAULT 值:设置默认值。可为数字也可为字符串。
COMMENT ‘备注’:该字段的备注信息。
(FIRST)|(AFTER 表中字段):在第一列创建该字段或者在表中字段之后创建该字段。
在字段 title 后新增字段 nickname
alter table movie add column nickname varchar(10) default null comment '昵称' after title;
新增表非空字段
alter table movie add phone varchar(11) not null;
新增表默认值字段
alter table movie add phone varchar(11) not null default '13228257753';
9.2删除字段
alter table 表名 drop column 字段名;例如删除 copy_movie 表中的 phone 字段 alter table copy_movie drop column phone;


9.3修改字段
修改字段名称
change常用于修改字段名称,但与modify一样。同样可以修改字段类型和长度。且修改后的字段,alter table语句中没有设置默认值等限制,原字段的限制将会被重置。如下例name1字段不会继承name字段的备注、默认值等信息。
alter table [表名] change [字段名] [字段新名称] [字段的类型]修改字段类型与长度
modify常用于修改表中字段的类型和长度。
alter table [表名] modify column [字段名] [新数据类型(修改后的长度)]例如修改 movie 表中 titile 字段长度为 20
alter table movie modify column title varchar(20);
9.4 复制表
复制表结构及数据到新表
CREATE TABLE 新表SELECT * FROM 旧表 会将oldtable中所有的内容都拷贝过来
例如复制 movie 表: create table copy_movie select * from movie;

只复制表结构到新表
CREATE TABLE 新表LIKE 旧表
例如: create table copy_movie like movie;

复制旧表的数据到新表(假设两个表结构一样)
INSERT INTO 新表 SELECT * FROM 旧表
复制旧表的数据到新表(假设两个表结构不一样)
INSERT INTO 新表(字段1,字段2,.......) SELECT 字段1,字段2,...... FROM 旧表
可以将表1结构复制到表2
SELECT * INTO 表2 FROM 表1 WHERE 1=2
可以将表1内容全部复制到表2
SELECT * INTO 表2 FROM 表1