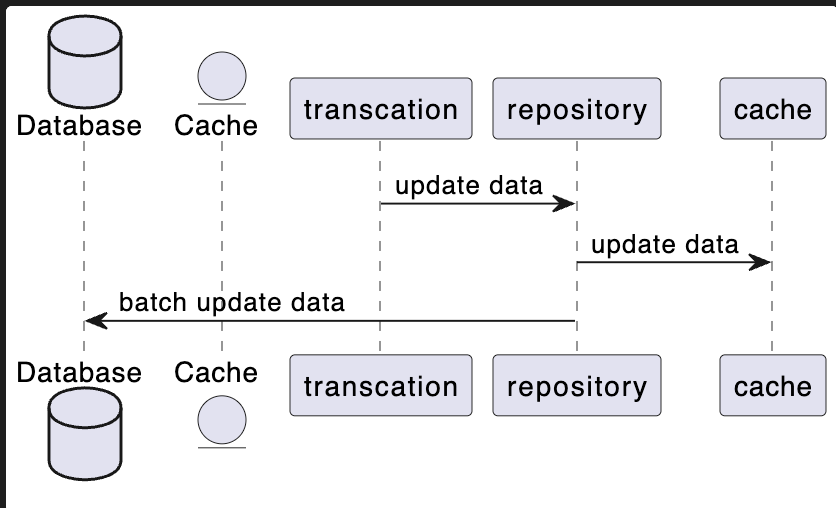
Linux知识点 – 进程控制(一)
文章目录
- Linux知识点 -- 进程控制(一)
- 一、进程创建
- 1.fork函数
- 2.写时拷贝
- 2.fork常规用法
- 3.fork调用失败的原因
- 二、进程终止
- 1.进程终止时操作系统的行动
- 2.进程终止的常见方式
- 3.用代码终止一个进程
- 三、进程等待
- 1.进程等待的必要性
- 2.进程等待的方法
- 3.wait、waitpid函数的意义
- 4.父进程非阻塞等待
- 5.非阻塞等待时父进程执行其他函数
一、进程创建
1.fork函数
(1)进程调用fork函数后,当控制转移到内核中的fork代码后,内核进行以下操作:
- 分配新的内存块和内存数据结构给子进程;
- 将父进程部分数据结构内容拷贝至子进程;
- 添加子进程到系统进程列表中;
- fork返回,开始调度器调度;
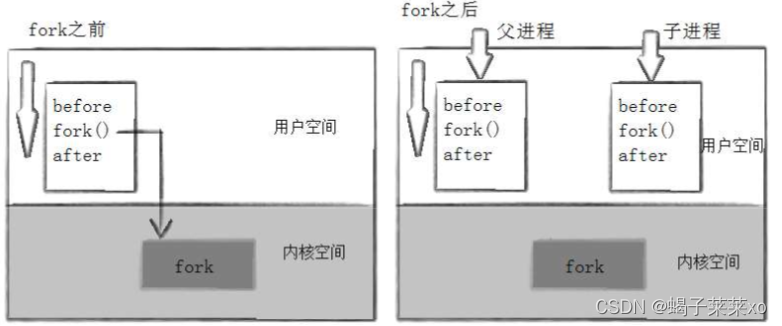
(2)进程 = 内核数据结构 + 进程代码和数据
创建子进程,给子进程分配对应的内核结构,必须要求是子进程自己独有的,因为进程具有独立性;理论上,子进程也要有自己的代码和数据,可是一般而言,我们没有对于子进程的加载过程,也就是说,子进程没有自己的代码和数据,所以子进程只能“使用”父进程的代码和数据;
代码:都是不可写的,只能读取,所以父子共享,没问题;
数据:可能被修改,所以必须分离;
(3)fork之后,父子进程代码共享
- 父子进程共享的是所有的代码,而不是只有fork之后的;
- 我们的代码在汇编之后,会有很多行代码,并且每行代码加载到内存之后,都有相应的地址;
- 因为进程随时可能被中断(可能并没有执行完),下次回来,还必须从当前位置继续运行,就要求CPU必须随时记录下来当前进程执行的位置,所以,CPU内有对应的寄存器数据(EIP,指向当前正在执行的代码的下一行代码地址),用来记录当前进程执行的位置;寄存器内的数据在CPU内是可以有多份的,这就是进程的上下文数据;
- 子进程在创建时,EIP会拷贝父进程的数据,虽然父子进程各自调度,各自会修改EIP,但是子进程已经认为自己的EIP起始值就是fork之后的代码;
2.写时拷贝
对于子进程数据的创建,有两种方式:
- 进程创建的时候,就直接拷贝分离;
这种方式的就是在子进程创建时就直接将父进程的数据再拷贝一份作为子进程的数据;但是,有可能子进程并不会用到其中的某些数据,即使用到了,可能也只是读取,这样会造成空间浪费;
因此创建子进程的时候,不需要将不会被访问的和只会读取的数据进行拷贝,但是操作系统不知道未来哪些数据会被子进程写入,而且就算知道了需要拷贝的数据,这些数据提前拷贝了,也可能不会立马使用,所以,OS选择了写时拷贝技术,来将父子进程的数据进行分离; - 写时拷贝:只有在子进程对数据进行写入操作的时候,OS才会在内存上拷贝父进程的该数据供子进程使用,同时修改子进程关于该数据的页表;
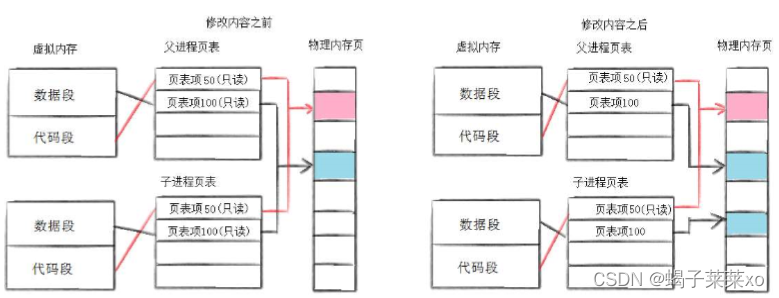
为什么要使用写时拷贝:
- 因为有写时拷贝技术的存在,父子进程得以完全分离,完成了进程独立性的技术保证;
- 写时拷贝是一种延时申请技术,可以提高整机内存的使用率;
2.fork常规用法
- 一个父进程希望复制自己,使父子进程同时执行不同的代码段;例如,父进程等待客户端请求,生成子进程来处理请求;
- 一个进程要执行一个不同的程序;例如子进程从fork返回后,调用exec函数;
3.fork调用失败的原因
- 系统中有太多的进程;
- 实际用户的进程数超过了限制;
二、进程终止
1.进程终止时操作系统的行动
进程终止时,操作系统释放了进程申请的相关内核数据结构和对应的数据和代码,本质就是释放系统资源;
2.进程终止的常见方式
- 代码跑完,结果正确;
- 代码跑完,结果不正确;
- 代码没有跑完,程序崩溃了;
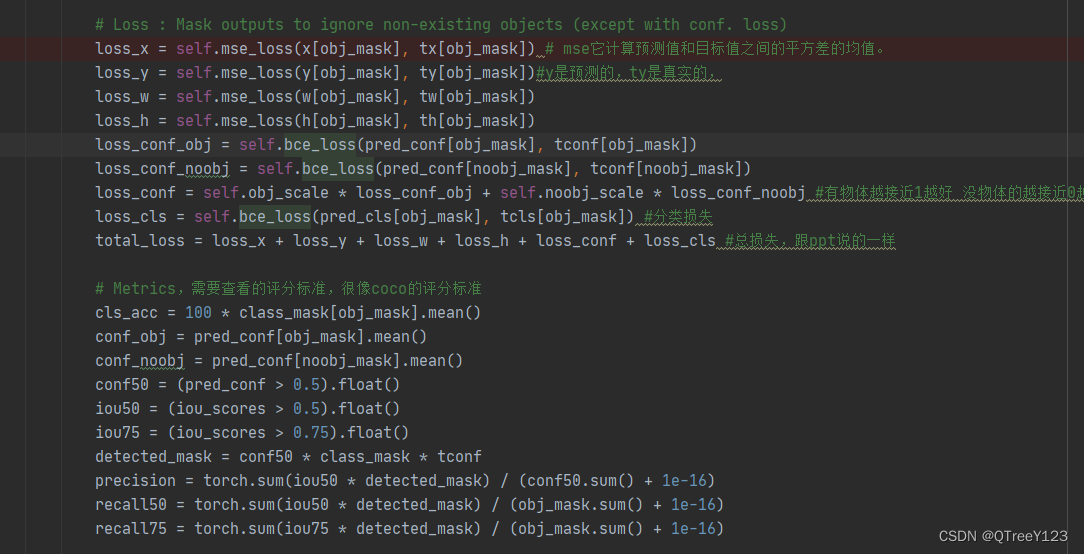
代码跑完之后,如何知道结果是否正确?
-
main函数的返回值其实是进程的退出码,0表示运行结果正确,非0表示结果不正确;
-
echo $? 命令可以获取最近一次执行完毕进程的退出码;

-
main函数返回值的意义:返回给上一级进程,用来评判该进程的执行结果;
判断返回值是否正确,来确定main函数的返回码;


可以通过main函数的返回码来判断结果是否正确; -
非0值有无数个,可以通过退出码来定位该进程对应出错的原因;
需要将退出码转化为字符串描述,使用strerror接口;


ls命令错误的退出码:

-
程序崩溃的时候,退出码就没有意义了,因为一般而言程序崩溃后,退出码对应的return语句没有被执行;
3.用代码终止一个进程
(1)使用return来终止进程
- return语句就是终止进程的,return 退出码;
- 但是return只有在main函数中才代表着进程退出,在其他函数中就只是返回值;
(2)使用exit来终止进程
- exit指令在任意位置调用,都表示进程直接终止;

参数status是进程退出码;

上面代码的运行结果为:

可以看到进程退出码是222,是在sum函数中进程就退出了;
(3)使用_exit来终止进程

_exit同样可以用来终止进程;
- exit:

- 上面的代码使用exit函数退出进程,没有\n刷新缓冲区,打印结果不会立马出来;

exit函数会在终止进程前刷新缓冲区,将结果打印出来; - 换成_exit函数:

运行结果:

系统并没有刷新缓冲区,因为_exit是系统接口,exit是库函数;

- printf的数据是保存在缓冲区的,数据缓冲区是不在操作系统内部的,是C标准库帮我们维护的;
三、进程等待
1.进程等待的必要性
- 子进程退出,如果父进程不管不顾,就会造成子进程变成僵尸进程,造成内存泄漏;
- 进程一旦变为僵尸状态,就刀枪不入,kill -9也无法杀死进程;
- 父进程派给子进程的任务完成的如何,父进程需要知道;
- 父进程通过进程等待的方式,回收子进程资源,获取子进程退出信息;
2.进程等待的方法
(1)wait函数

- 等待进程去改变状态;
- 成功:返回子进程的PID;失败:返回-1;
先创建一个僵尸进程:
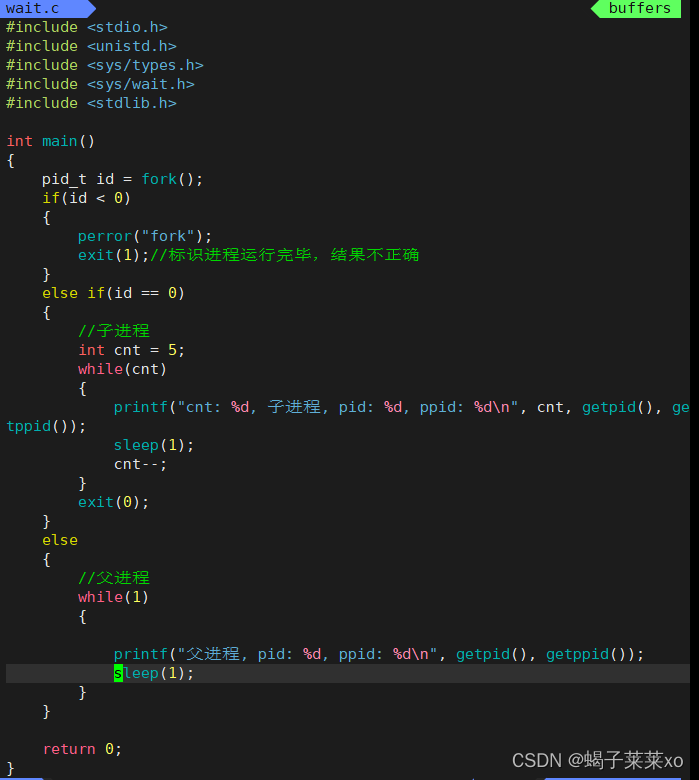

- 在父进程内使用wait函数回收僵尸子进程:

wait是阻塞式等待,父进程执行到wait语句时就一直阻塞式的等待,不会向下执行了,直到子进程退出,再回收子进程;
运行结果为:


可以看到父进程等待成功,并成功将已经变为僵尸进程的子进程回收掉;
(2)waitpid函数

参数:
-
pid:
pid = -1:等待任一个子进程,与wait等效;
pid > 0:等待其进程ID与pid相等的子进程; -
status:输出型参数,可标识子进程退出的结果(与wait的status一样);
-
options:默认为0,表示阻塞等待;
-
返回值:
成功:返回子进程PID;
失败:返回-1; -
在父进程内使用waitpid函数回收僵尸子进程

父进程可以通过status拿到子进程的退出结果;


从结果可以看出,waitpid函数也可以回收僵尸进程,但是status并不是子进程的退出码; -
因为status不是按照整数来整体使用的,而是按照比特位的方式,将32个比特位进行划分,我们只学习低16位:
-
在进程正常终止的情况下:status的次低8位表示子进程的退出码;
-
在进程被信号所杀的情况下,status最低的7个比特位表示进程收到的信号,第8个比特位是core dump标志;

-
拿到子进程退出结果和终止信号的方法:

-
拿到子进程退出结果和终止信号的简单方法
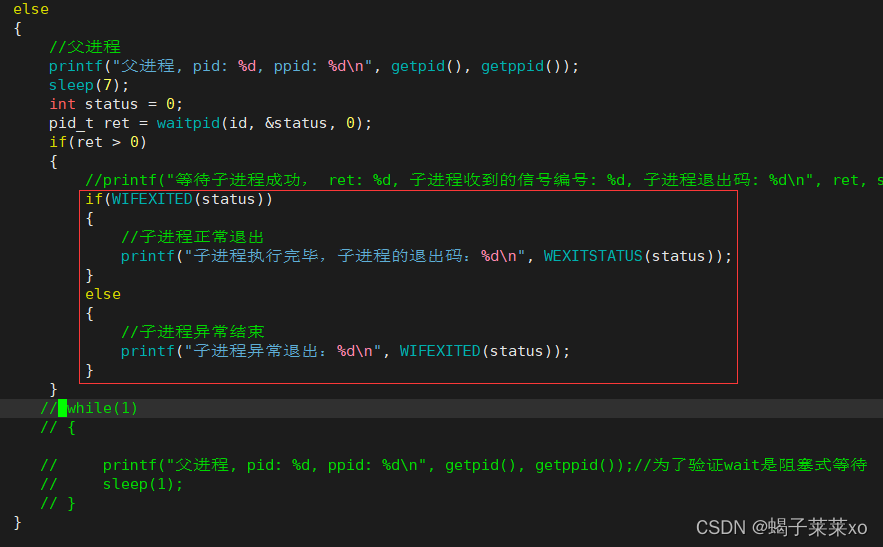
基于wait和waitpid的监测功能,操作系统为用户准备了两个宏,来完成对status中信息的提取,无需用户进行位操作:
WIFEXITED(status):若为正常终止的子进程返回的状态,则为真(查看进程是否正常退出);
WEXITSTATUS(status):若WIFEXITED非0,提取子进程的退出码(查看进程的退出码);
子进程监测的代码可以这样写:

3.wait、waitpid函数的意义
- 因为进程具有独立性,那么数据就要发生写时拷贝,父进程无法直接拿到子进程的数据,需要通过这两个函数来进行;
- 父进程为什么可以通过wait、waitpid函数拿到子进程的退出信息?
因为僵尸进程至少会保留进程的PCB信息,task_struct里面保留了任何进程退出时的结果信息;
wait、waitpid是系统调用,可以拿到这些数据;
4.父进程非阻塞等待
waitpid函数的第三个参数:
- options:默认为0,代表阻塞等待;
WNOHANG:代表非阻塞等待;
WNOHANG其实就是宏定义;
- 阻塞等待:上面使用wait和waitpid函数实现的都是阻塞等待,就是父进程在内核中阻塞,等待被唤醒;父进程没有被CPU调度,要么在阻塞队列中,要么是等待被调度,伴随着被切换;
进程阻塞,本质是进程阻塞在系统函数的内部,后面的代码不执行了,进程挂起;当条件满足的时候,父进程被唤醒,从EIP寄存器中读取挂起前进程的程序指针,继续向下执行; - 非阻塞等待:父进程通过调用waitpid来进行等待,如果子进程没有退出,waitpid这个系统调用立马return返回;
使用waitpid函数进行非阻塞等待:
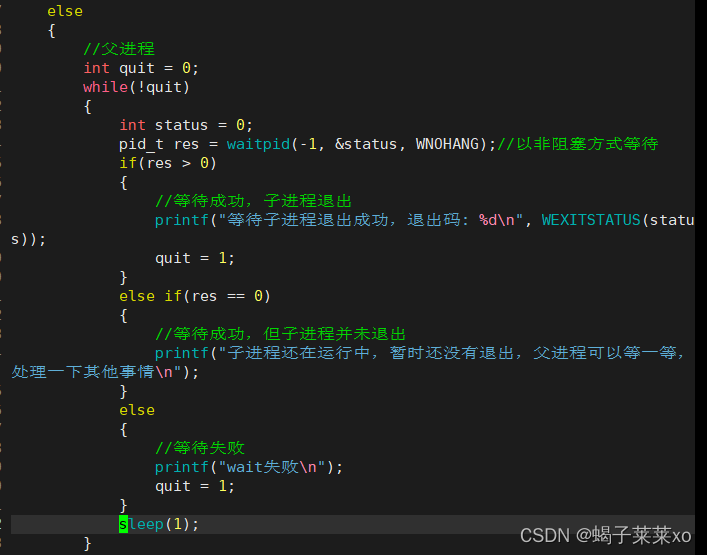
- 运行结果:
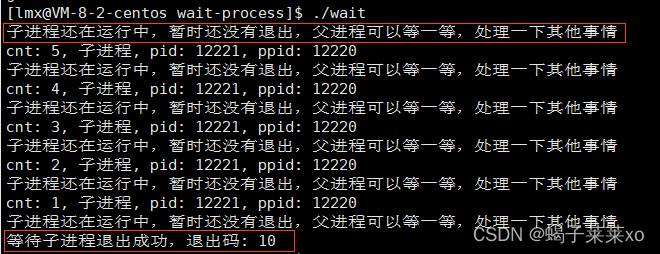
我们可以看到,子进程还未退出时,父进程可以进行打印,而不是像阻塞等待一样,什么都做不了,非阻塞等待waitpid是直接返回结束了的,父进程可以进行其他操作;只要一直循环检测子进程的退出状态就可以了,一旦子进程退出,waitpid返回值不为0,就将标志位quit置1,循环结束; - waitpid的返回值:
上面提到waitpid函数的返回值,在子进程正常退出时,返回值大于0,返回的是子进程的退出码;
当子进程异常退出时,返回值小于0;
当waitpid是非阻塞等待时,等待成功且子进程还未退出时,waitpid会直接执行return 0,返回值也就是0;
5.非阻塞等待时父进程执行其他函数
注:c++文件的三种后缀格式:
- .cpp
- .cc
- .cxx
使用函数回调的方式,让父进程在非阻塞等待时,能够执行其他函数:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <vector>
using namespace std;
typedef void (*handler_t)(); //函数指针类型
vector<handler_t> handlers; //函数指针数组
void fun1()
{
printf("fun1\n");
}
void fun2()
{
printf("fun2\n");
}
//设置对应的方法回调
void Load()
{
handlers.push_back(fun1);
handlers.push_back(fun2);
}
int main()
{
pid_t id = fork();
if(id < 0)
{
perror("fork");
exit(1);//标识进程运行完毕,结果不正确
}
else if(id == 0)
{
//子进程
int cnt = 5;
while(cnt)
{
printf("cnt: %d, 子进程, pid: %d, ppid: %d\n", cnt, getpid(), getppid());
sleep(1);
cnt--;
}
exit(10);
}
else
{
//父进程
int quit = 0;
while(!quit)
{
int status = 0;
pid_t res = waitpid(-1, &status, WNOHANG);//以非阻塞方式等待
if(res > 0)
{
//等待成功,子进程退出
printf("等待子进程退出成功,退出码: %d\n", WEXITSTATUS(status));
quit = 1;
}
else if(res == 0)
{
//等待成功,但子进程并未退出
printf("子进程还在运行中,暂时还没有退出,父进程可以等一等,处理一下其他事情\n");
if(handlers.empty())
{
Load();
}
for(auto iter : handlers)
{
//执行处理其他任务
iter();
}
}
else
{
//等待失败
printf("wait失败\n");
quit = 1;
}
sleep(1);
}
}
return 0;
}


将函数指针存入数组中,通过函数回调的方式,就可以在父进程等待时调用其他函数;