[牛客小白赛复盘] 牛客小白月赛74
- 总结
- A 简单的整除
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- B 整数划分
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- C 传送阵
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- D 修改后的和
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- E 幼稚园的树2
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- F 最便宜的构建
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- G 跳石头,搭梯子
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- 六、参考链接
总结
- 做了5题就下班跑路了哈哈,路上看了FG题面,G不会证明。
- A 模拟。
- B 模拟。
- C 贪心+哈希表。
- D 贪心排序
- E 分类讨论,数学
- F 二分答案+并查集
- G 单调栈+贪心+树状数组RURQ

A 简单的整除
链接: [简单的整除](https://ac.nowcoder.com/acm/contest/59284/A
1. 题目描述
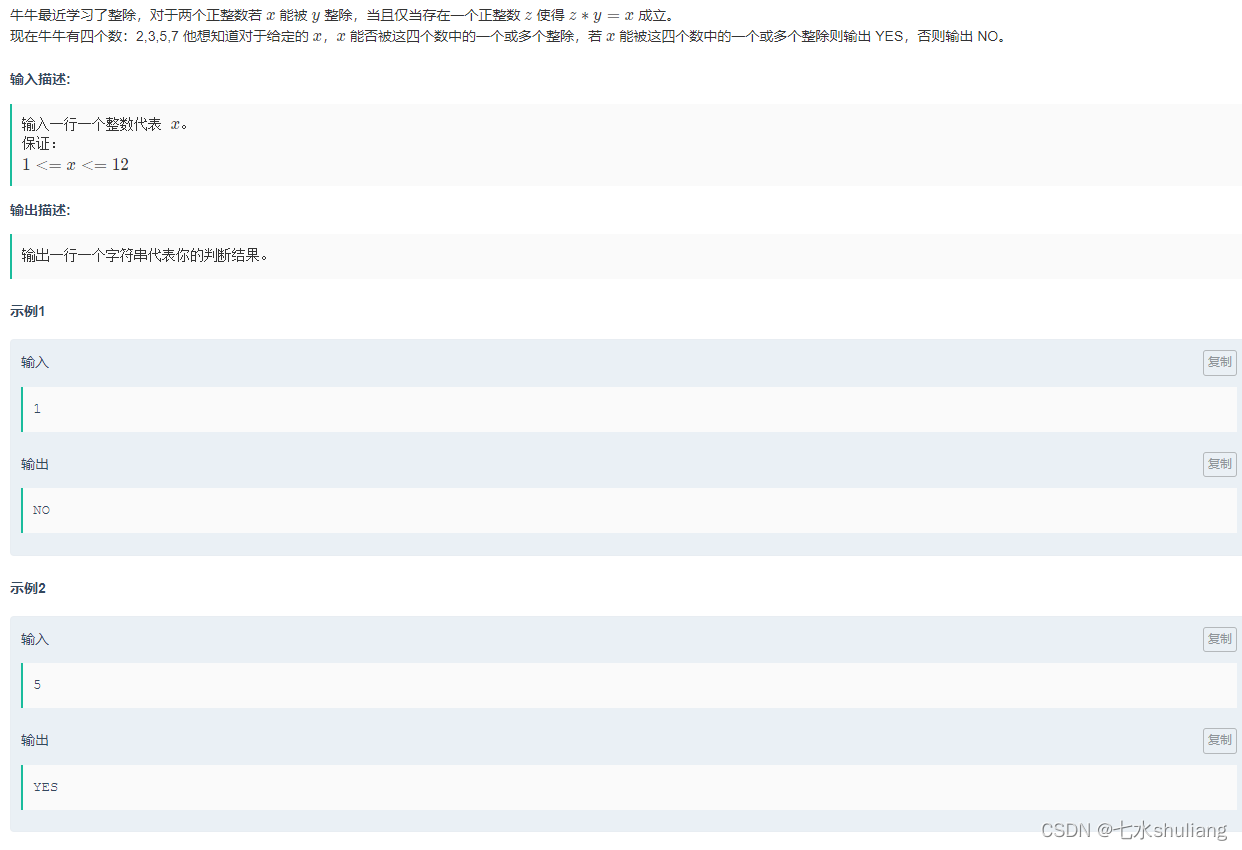
2. 思路分析
- 模拟。
3. 代码实现
# Problem: 简单的整除
# Contest: NowCoder
# URL: https://ac.nowcoder.com/acm/contest/59284/A
# Memory Limit: 524288 MB
# Time Limit: 2000 ms
import sys
import random
from types import GeneratorType
import bisect
import io, os
from bisect import *
from collections import *
from contextlib import redirect_stdout
from itertools import *
from array import *
from functools import lru_cache, reduce
from heapq import *
from math import sqrt, gcd, inf
if sys.version >= '3.8': # ACW没有comb
from math import comb
RI = lambda: map(int, sys.stdin.buffer.readline().split())
RS = lambda: map(bytes.decode, sys.stdin.buffer.readline().strip().split())
RILST = lambda: list(RI())
DEBUG = lambda *x: sys.stderr.write(f'{str(x)}\n')
# print = lambda d: sys.stdout.write(str(d) + "\n") # 打开可以快写,但是无法使用print(*ans,sep=' ')这种语法,需要print(' '.join(map(str, p))),确实会快。
DIRS = [(0, 1), (1, 0), (0, -1), (-1, 0)] # 右下左上
DIRS8 = [(0, 1), (1, 1), (1, 0), (1, -1), (0, -1), (-1, -1), (-1, 0),
(-1, 1)] # →↘↓↙←↖↑↗
RANDOM = random.randrange(2**62)
MOD = 10**9 + 7
PROBLEM = """
"""
def lower_bound(lo: int, hi: int, key):
"""由于3.10才能用key参数,因此自己实现一个。
:param lo: 二分的左边界(闭区间)
:param hi: 二分的右边界(闭区间)
:param key: key(mid)判断当前枚举的mid是否应该划分到右半部分。
:return: 右半部分第一个位置。若不存在True则返回hi+1。
虽然实现是开区间写法,但为了思考简单,接口以[左闭,右闭]方式放出。
"""
lo -= 1 # 开区间(lo,hi)
hi += 1
while lo + 1 < hi: # 区间不为空
mid = (lo + hi) >> 1 # py不担心溢出,实测py自己不会优化除2,手动写右移
if key(mid): # is_right则右边界向里移动,目标区间剩余(lo,mid)
hi = mid
else: # is_left则左边界向里移动,剩余(mid,hi)
lo = mid
return hi
def bootstrap(f, stack=[]):
def wrappedfunc(*args, **kwargs):
if stack:
return f(*args, **kwargs)
else:
to = f(*args, **kwargs)
while True:
if type(to) is GeneratorType:
stack.append(to)
to = next(to)
else:
stack.pop()
if not stack:
break
to = stack[-1].send(to)
return to
return wrappedfunc
def solve():
x, = RI()
print("YES" if x % 2 == 0 or x % 3 == 0 or x % 5 == 0 or x % 7 == 0 else 'NO')
if __name__ == '__main__':
t = 0
if t:
t, = RI()
for _ in range(t):
solve()
else:
solve()
B 整数划分
链接: 整数划分
1. 题目描述
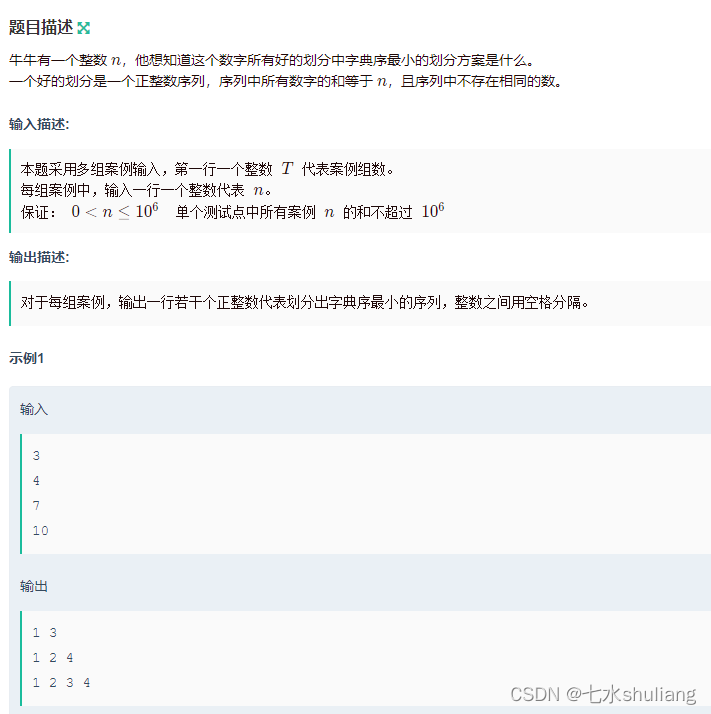
2. 思路分析
- 由于要最小字典序,那么前边就是1 2 3 4…连续的。
- 那么为了不使用重复数,最后一个数一定要>倒数第二个数。拆分时要注意。
3. 代码实现
def solve():
n, = RI()
ans = []
i = 1
while True:
if n-i > i:
ans.append(i)
n -= i
i += 1
else:
ans.append(n)
break
print(*ans)
C 传送阵
链接: 传送阵
1. 题目描述
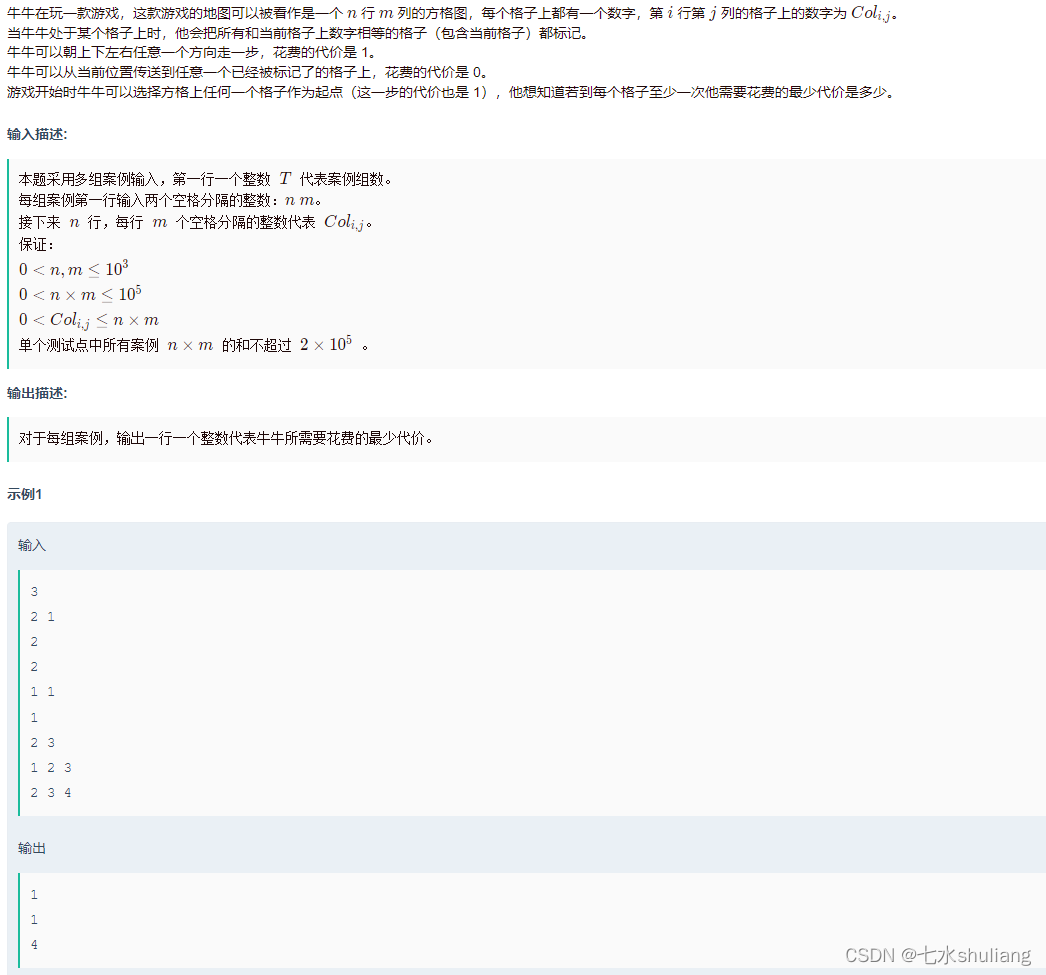
2. 思路分析
- 题目看似唬人,仔细想想就会发现,每次花费代价可以经过一类数字所有。而且一定可以移动到边界上,去下一个数。
- 那么所有数字去重看看有多少种即可。
3. 代码实现
def solve():
n,m = RI()
s = set()
for _ in range(n):
r = RILST()
s|=set(r)
print(len(s))
D 修改后的和
链接: 修改后的和
1. 题目描述
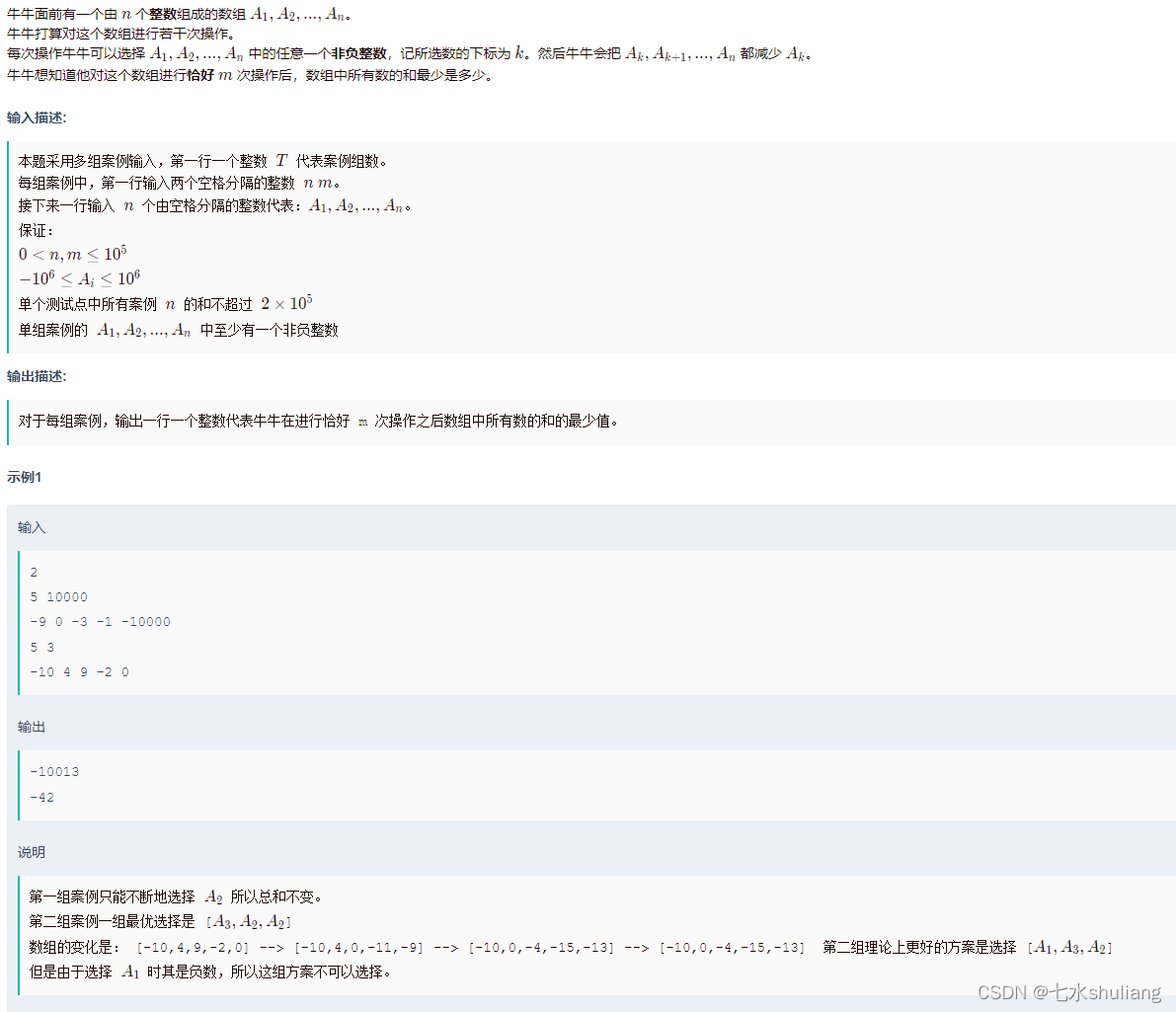
2. 思路分析
- 每次操作都会把这个数变0,换言之每个数只需要操作1次。而它的价值是固定的就是v*len。
- 那么把每个操作的价值排序,从大到小取m个即可。
- 你可能会担心操作的顺序会不会影响后续的价值,那么从后往前操作即可不会影响。
3. 代码实现
def solve():
n, m = RI()
a = RILST()[::-1]
p = []
for i, v in enumerate(a, start=1):
if v > 0:
p.append(v * i)
p.sort(reverse=True)
print(sum(a) - sum(p[:m]))
E 幼稚园的树2
链接: 幼稚园的树2
1. 题目描述
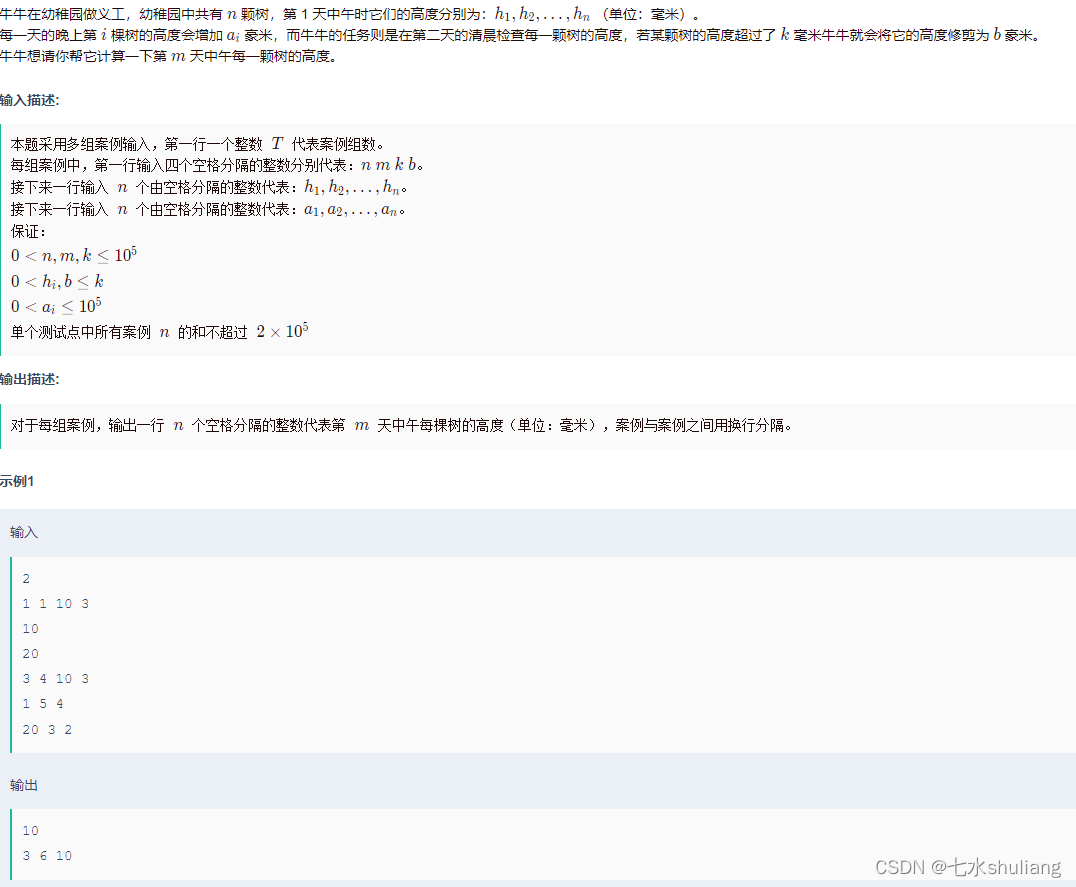
2. 思路分析
我仿佛在做小学奥数。
- 对每颗树的答案单独计算,疯狂分类讨论即可。
- 如果m天根本长不过k,那么可以直接计算。
- 否则,先计算第一次长过k需要几天:
- 由于必须长过k,即至少要到k+1,那么要长k+1-hi,速度是ai,用上取整公式算出第一次被剪成b的花费天数one。
- 那么还剩p=m-1-one天可以长,从b开始。
- 显然,每隔几天就会超过k,变成b,这个周期是per=ceil((k+1-b)/ai)。
- 那么实际有效的天数就是p%per。
- ans[i]=b+p*ai
3. 代码实现
# ms
def solve():
n,m,k,b = RI()
h = RILST()
a = RILST()
ans = [0]*n
for i,(x,y) in enumerate(zip(h,a)):
if x + y*(m-1) <= k:
ans[i] = x + y*(m-1)
continue
one = (k+1-x+y-1)//y
p = m -1 - one # 还能长p天
if p == 0:
ans[i] = b
continue
per = (k+1-b+y-1)//y # 每per天会被剪到b
p %= per
ans[i] = b + p*y
print(*ans)
F 最便宜的构建
链接: 最便宜的构建
1. 题目描述
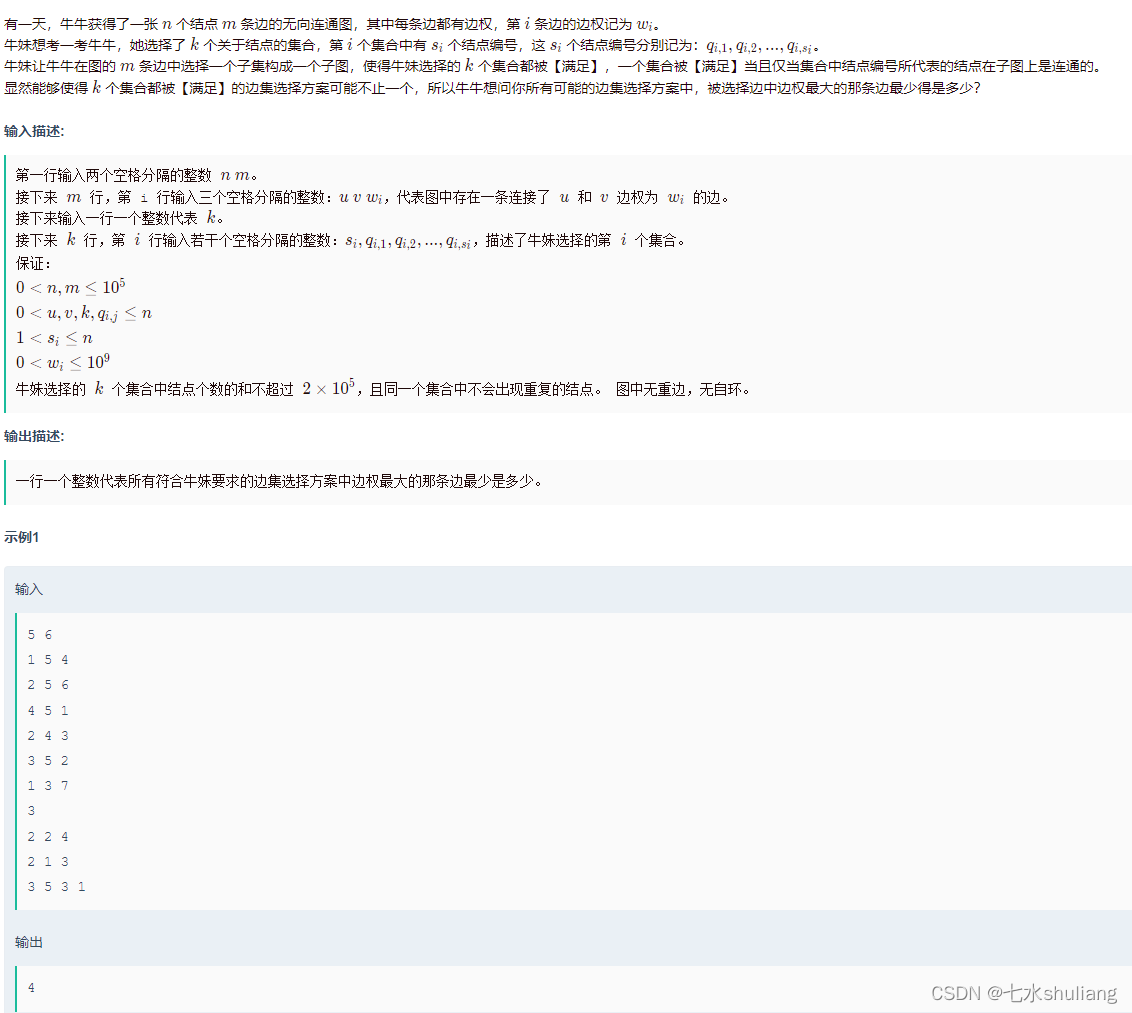
2. 思路分析
题目很长,抓住关键词最小化最大值。
- 二分答案。
- 由于边不怕加多,直接尽可能的加边,则要求的集合更有可能连通。
- 最大边越大,能加的边越多,更可能连通;最大边越小,加的边少,越不会连通;满足二段性。
- check时,把小于mid的边全部加进并查集,然后检查每个集合的连通性即可。
- 答案的上下界可以直接写0,1e9。也可以写min(w),max(w)
3. 代码实现
# ms
def lower_bound(lo: int, hi: int, key):
"""由于3.10才能用key参数,因此自己实现一个。
:param lo: 二分的左边界(闭区间)
:param hi: 二分的右边界(闭区间)
:param key: key(mid)判断当前枚举的mid是否应该划分到右半部分。
:return: 右半部分第一个位置。若不存在True则返回hi+1。
虽然实现是开区间写法,但为了思考简单,接口以[左闭,右闭]方式放出。
"""
lo -= 1 # 开区间(lo,hi)
hi += 1
while lo + 1 < hi: # 区间不为空
mid = (lo + hi) >> 1 # py不担心溢出,实测py自己不会优化除2,手动写右移
if key(mid): # is_right则右边界向里移动,目标区间剩余(lo,mid)
hi = mid
else: # is_left则左边界向里移动,剩余(mid,hi)
lo = mid
return hi
class DSU:
"""基于数组的并查集"""
def __init__(self, n):
self.fathers = list(range(n))
self.size = [1] * n # 本家族size
self.edge_size = [0] * n # 本家族边数(带自环/重边)
self.n = n
self.set_count = n # 共几个家族
def find_fa(self, x):
fs = self.fathers
t = x
while fs[x] != x:
x = fs[x]
while t != x:
fs[t], t = x, fs[t]
return x
def union(self, x: int, y: int) -> bool:
x = self.find_fa(x)
y = self.find_fa(y)
if x == y:
self.edge_size[y] += 1
return False
# if self.size[x] > self.size[y]: # 注意如果要定向合并x->y,需要干掉这个;实际上上边改成find_fa后,按轶合并没必要了,所以可以常关
# x, y = y, x
self.fathers[x] = y
self.size[y] += self.size[x]
self.edge_size[y] += 1 + self.edge_size[x]
self.set_count -= 1
return True
# ms
def solve():
n, m = RI()
es = []
for _ in range(m):
u, v, w = RI()
es.append((w, u - 1, v - 1))
es.sort()
k, = RI()
s = []
for _ in range(k):
si, *ss = RI()
s.append(ss)
def ok(x):
dsu = DSU(n)
for w, u, v in es:
if w > x: break
dsu.union(u, v)
for ss in s:
p = dsu.find_fa(ss[0] - 1)
for u in ss[1:]:
if dsu.find_fa(u - 1) != p:
return False
return True
print(lower_bound(min(es)[0], max(es)[0], ok))
G 跳石头,搭梯子
链接: 跳石头,搭梯子
1. 题目描述
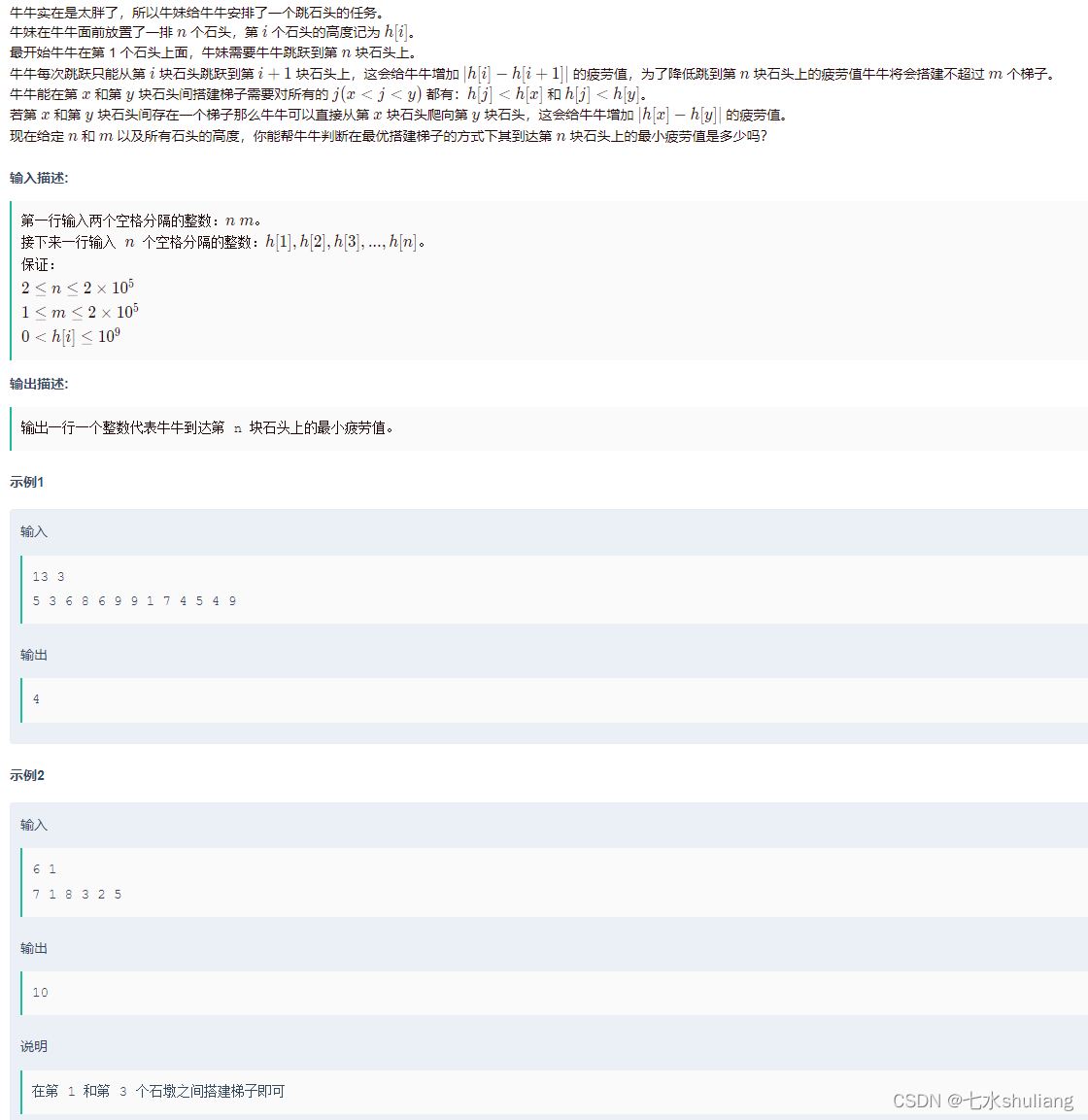
2. 思路分析
过是过了,排序贪心那步没证出来。
- 一看搭梯子的条件是中间的梯子必须短于两段,那么考虑单调递减栈。
- 单减栈出栈时,当前i是栈顶右边第一个大于栈顶的位置。
- 入栈时,栈顶是当前i左边第一个大于i的位置。
- 意味着中间的数都是小于两端,可以搭梯子。
- 注意不要搭相邻的两个数。
- 找到所有梯子,考虑用类似D题的方法,计算每个梯子的贡献和原本总花费,用总花费减去最优的m个梯子即可。
- 如何计算贡献。
- 显然贡献=这段的原花费-梯子花费。
- 按贡献排序,取最大的m个梯子,但梯子不能重叠,直到取到m个梯子即可。
- 这里不知道怎么证明,但是ac。直觉上:
- 由于花费是abs的,因此越宽的梯子越nb,毕竟两端是超过中间的,它们天然的会排在前边。
- 如何计算贡献。
- 剩下的问题是怎么快速判断重叠,由于py没有有序集合,我贴了个RURQ的树状数组,它可以用log的时间操作。
- 注意梯子两端是可以重叠的,是中间不能重叠,那么选择把左端点右移一位,正好可以给BIT用。
3. 代码实现
class BinIndexTreeRURQ:
"""树状数组的RURQ模型"""
def __init__(self, size_or_nums): # 树状数组,区间加区间求和,下标需要从1开始
# 如果size 是数字,那就设置size和空数据;如果size是数组,那就是a
if isinstance(size_or_nums, int):
self.size = size_or_nums
self.c = [0 for _ in range(self.size + 5)]
self.c2 = [0 for _ in range(self.size + 5)]
else:
self.size = len(size_or_nums)
self.c = [0 for _ in range(self.size + 5)]
self.c2 = [0 for _ in range(self.size + 5)]
for i, v in enumerate(size_or_nums):
self.add_interval(i + 1, i + 1, v)
def add_point(self, c, i, v): # 单点增加,下标从1开始;不支持直接调用,这里增加的是差分数组的单点,同步修改c2
while i <= self.size:
c[i] += v
i += -i & i
def sum_prefix(self, c, i): # 前缀求和,下标从1开始;不支持直接调用,这里求和的是差分数组的前缀和;传入c决定怎么计算,但是不要直接调用 无视吧
s = 0
while i >= 1:
s += c[i]
i -= -i & i
return s
def add_interval(self, l, r, v): # 区间加,下标从1开始,把[l,r]闭区间都加v
self.add_point(self.c, l, v)
self.add_point(self.c, r + 1, -v)
self.add_point(self.c2, l, (l - 1) * v)
self.add_point(self.c2, r + 1, -v * r)
def sum_interval(self, l, r): # 区间求和,下标从1开始,返回闭区间[l,r]上的求和
return self.sum_prefix(self.c, r) * r - self.sum_prefix(self.c2, r) - self.sum_prefix(self.c, l - 1) * (
l - 1) + self.sum_prefix(self.c2, l - 1)
def query_point(self, i): # 单点询问值,下标从1开始,返回i位置的值
return self.sum_prefix(self.c, i)
def lowbit(self, x):
return x & -x
"""
先用单调栈求出所有可以搭的桥
记录每个桥如果搭,贡献是多少,显然是 原花费-过桥的花费
把桥按贡献排序,从大到小取m个,但不能重叠
答案就是 原花费-桥的贡献
证明:请木木大佬补充
"""
# 1113ms
def solve():
n, m = RI()
a = RILST()
ans = 0
p = [0] * n # 相邻差的前缀和
for i in range(1, n):
d = abs(a[i] - a[i - 1])
ans += d
p[i] = d + p[i - 1]
# print(p)
st = []
lines = []
for i, v in enumerate(a):
while st and a[st[-1]] < v:
j = st[-1]
if j + 1 < i:
lines.append((abs(v - a[j]) - (p[i] - p[j]), j, i)) # j~i可以搭梯子
st.pop()
if st and st[-1] + 1 < i:
j = st[-1]
if j + 1 < i:
lines.append((abs(v - a[j]) - (p[i] - p[j]), j, i)) # j~i可以搭梯子
st.append(i)
lines.sort()
tree = BinIndexTreeRURQ(n)
for w, l, r in lines:
if not m:
break
if tree.sum_interval(l + 1, r) == 0:
ans += w
m -= 1
tree.add_interval(l + 1, r, 1)
# print(lines)
print(ans)
六、参考链接
- 无






![[ruby on rails] passenger+nginx 部署rails](https://img-blog.csdnimg.cn/955ea138599c4145897de8c17df6c6ab.png)




