文章目录
- 1. 目标检测的基本范式
- 1.0-1 目标检测简介
- 1.0-2 基本概念
- 1.1 滑窗
- 1.1.1 滑窗基本思想
- 1.1.2 滑窗效率问题改进
- 1.1.3 感受野计算
- 1.2-1 使用卷积实现密集预测
- 1.2.1 在特征图上进行密集预测
- 1.2.2 边界框回归
- 1.2.3 非极大值抑制(Non-Maximum Suppression)
- 1.2.4 使用密集预测模型进行推理
- 1.2.5 如何训练
- 1.2.6 密集预测的基本范式
- 1.3 密集预测范式的改进:多尺度预测
- 1.3.1 锚框
- 1.3.2 图像金字塔
- 1.3.3 基于层次化特征
- 1.3.4 特征金字塔(FPN)(2016)
- 1.3.5 多尺度的密集预测
- 2. 单阶段&无锚框检测器选讲
- 2.1 RPN(2015)
- 2.1.1 基本原理
- 2.2.2 RPN-head代码
- 2.2.3 RPN-基于loU的匹配
- 2.2 YOLO(2005)
- 2.2.1 Yolo模型
- 2.2.2 Yolo的匹配和框编码
- 2.2.3 Yolo的损失函数
- 2.2.4 YOLO的优点和缺点
- 2.3 SSD(2016)
- 2.4 Focal Loss与RetinaNet(2017)
- 2.5 YOLO系列选讲
- 2.5.1 YOLOv3(2018)
- 2.5.2 YOLOv5(2020)
- 2.6 无锚框检测算法
- 2.6.1 重叠问题
- 2.6.2 FCOS(2019)
- 2.6.3 CenterNet(2019)
- 2.6.4 YOLOX(2021)
- 2.6.5 YOLO v8
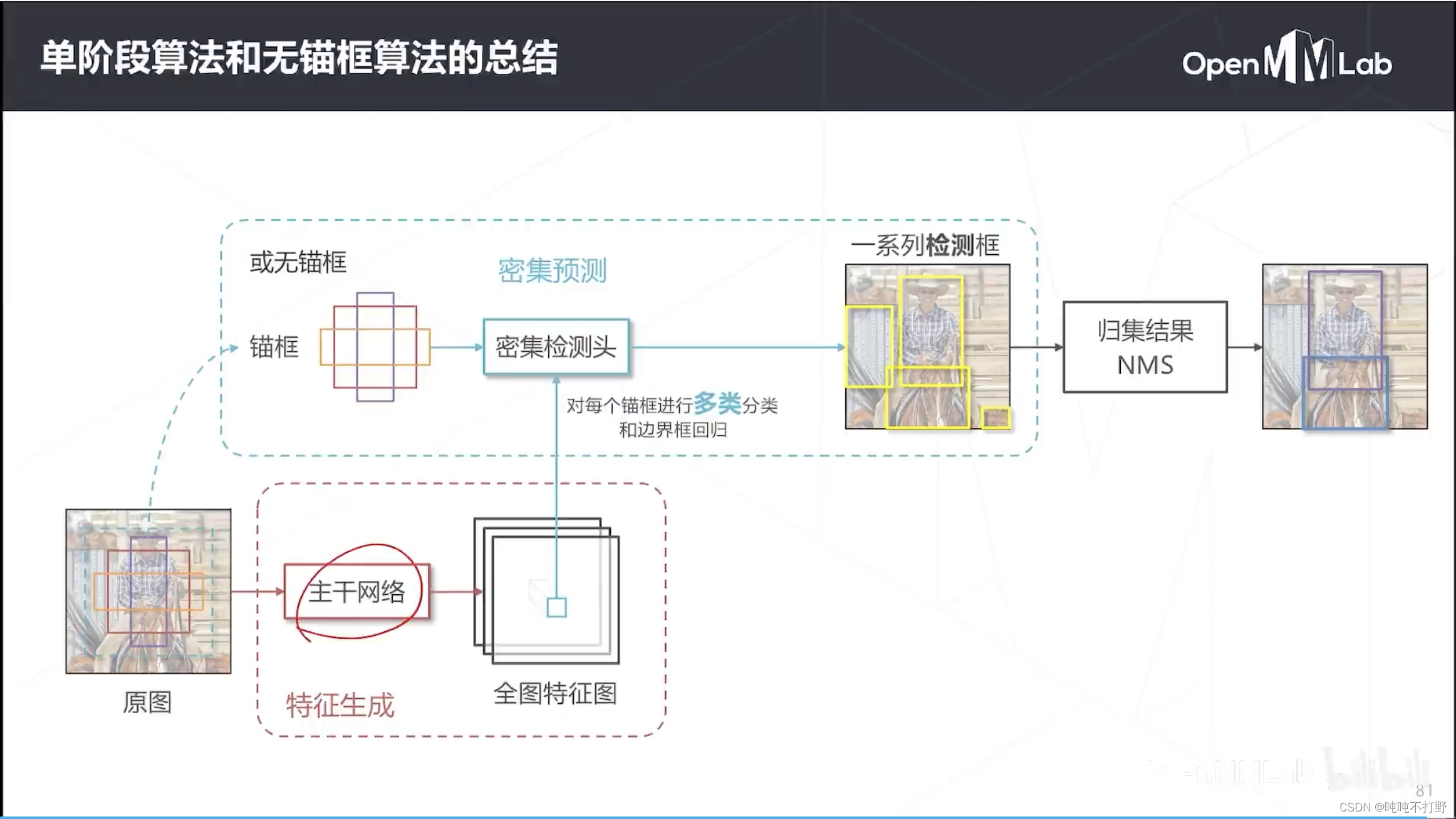
- 2.7 总结
如果还想看这个王若晖老师的相关课程,还可以看看AI实战营的第一期课程:合集·OpenMMLab AI 实战营
对应视频链接:目标检测与MMDetection
1. 目标检测的基本范式
1.0-1 目标检测简介

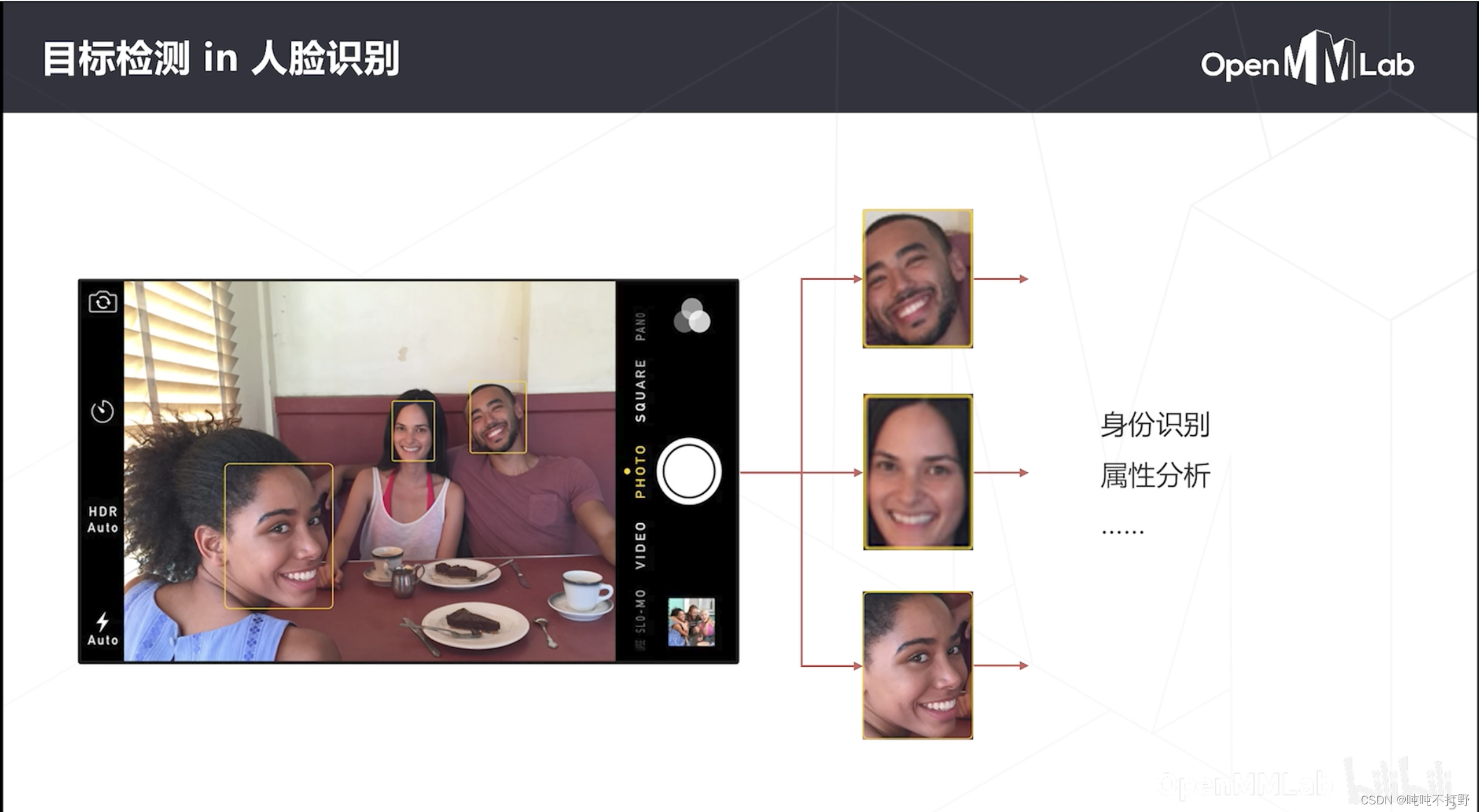
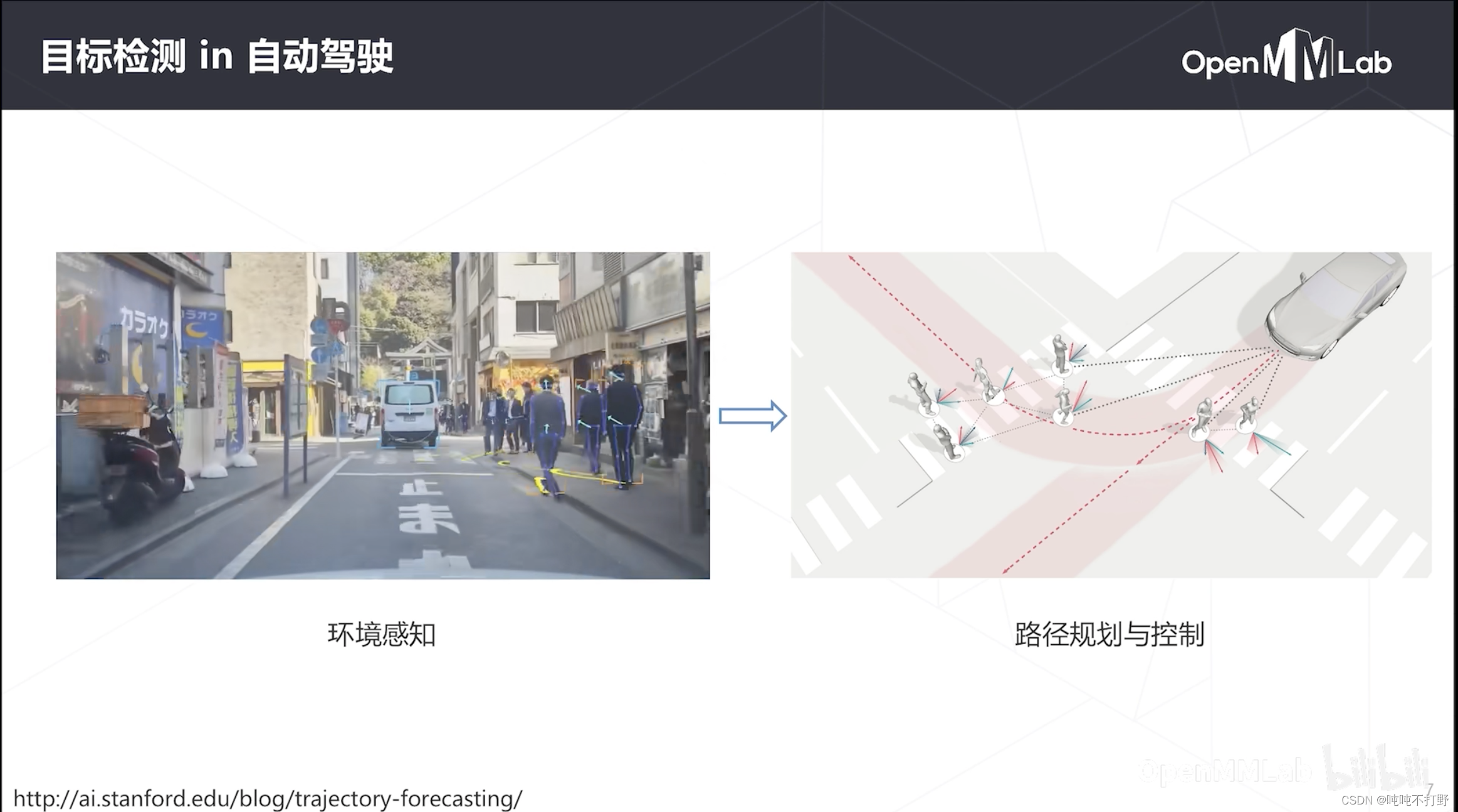
定位+分类

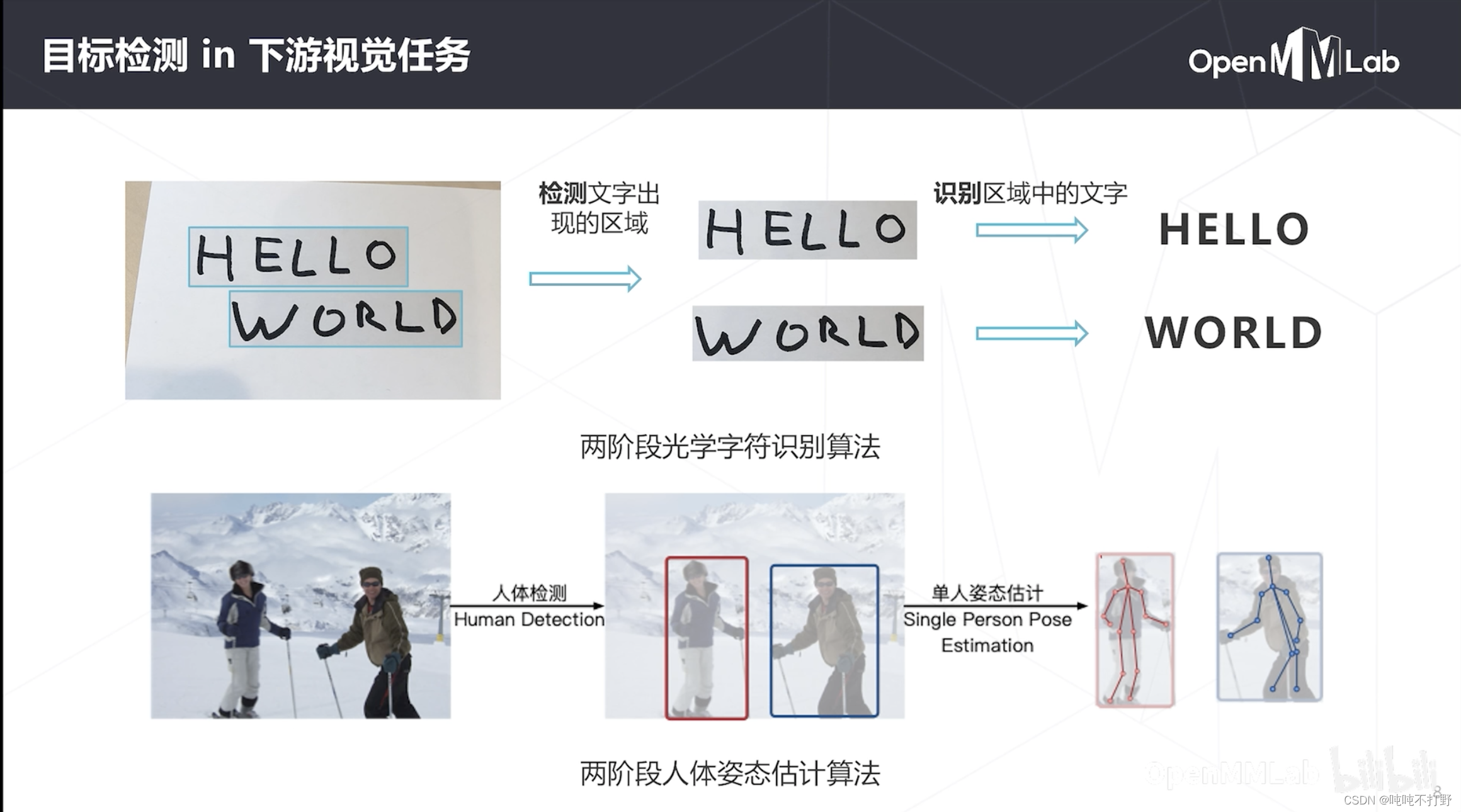
- DPM:Deformable Part Model,可形变组件模型,
- 于2008年提出,并发表了一系列的cvpr,NIPS。并且还拿下了2010年,PASCAL VOC的“终身成就奖”
- DPM用到了HOG的东西,是用传统算法做的。
- 详见:
- CSDN博客-DPM(Deformable Part Model)原理详解
- 博客园博客-关于DPM(Deformable Part Model)算法中模型可视化的解释,算法提出者使用的是matlab写得源码
- opencv有对应的c++实现:https://docs.opencv.org/3.4/d9/d12/group__dpm.html
- 目标检测(二)传统目标检测与识别的特征提取(一文讲懂Haar-like特征,HOG特征,DPM特征)
- github上有个python实现,但是很少:https://github.com/Alarnti/dpm
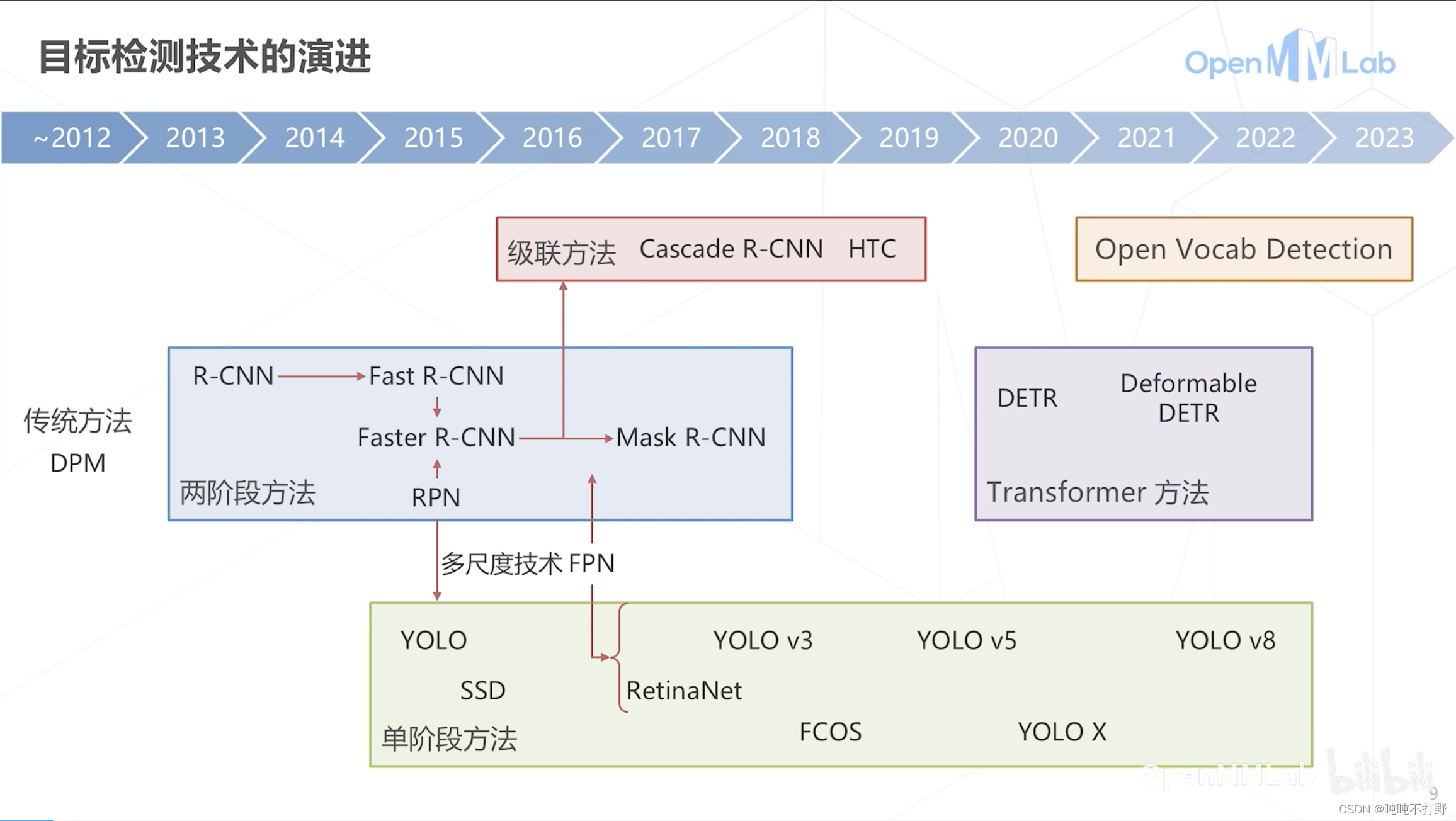
- 单阶段方法一开始因为精度问题,没有两阶段的受欢迎,后面改进,在精度和部署上都很优秀,所以现在YoLo系列是主流。2020年之后的Transformer方法因为精度很好,所以也逐渐成为目标检测中受欢迎的方法
b站上有一个课,讲了传统和深度的目标检测:100集深度学习目标检测算法教程
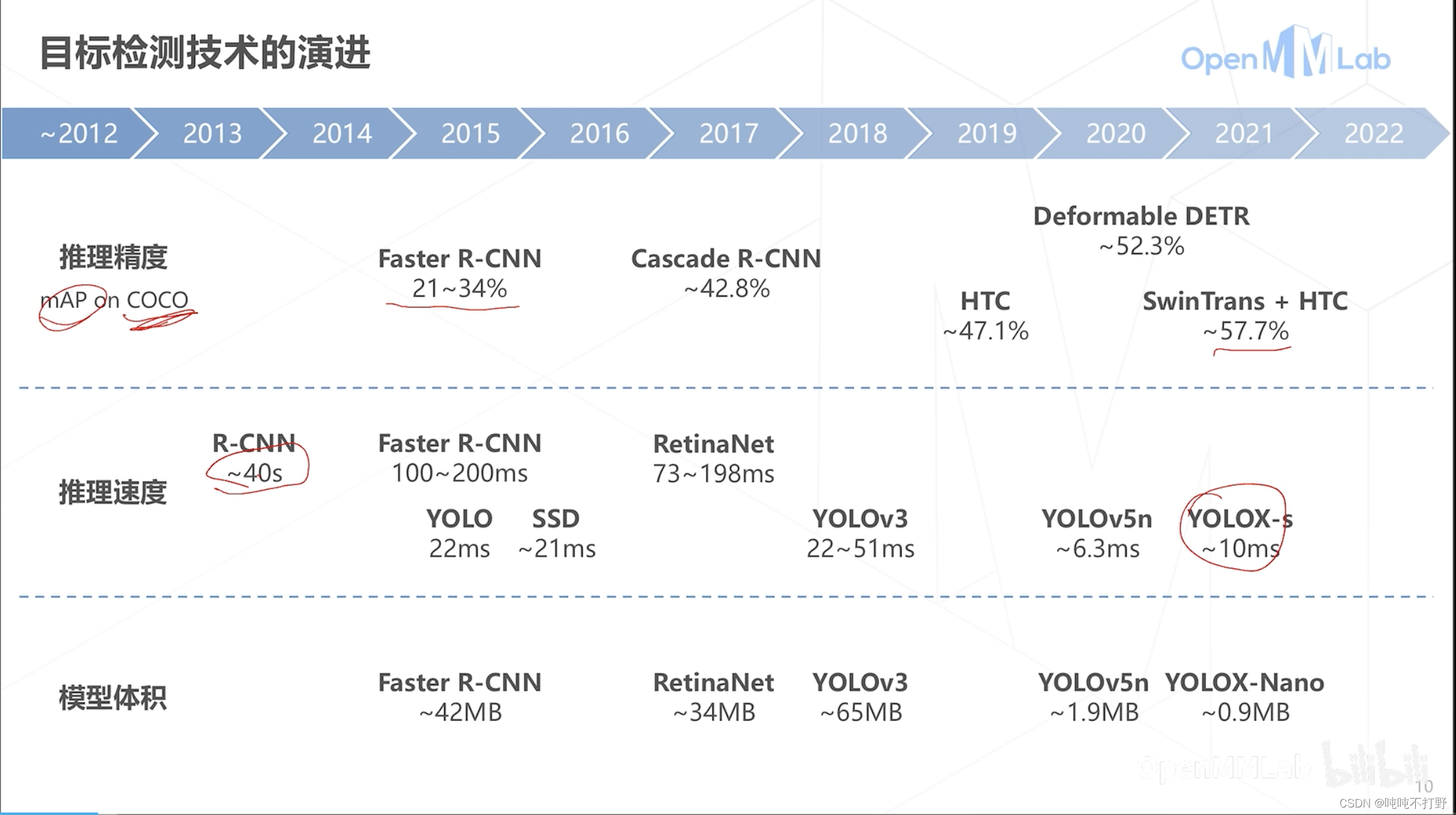
推理精度:
- 早年COCO数据集上的准确度大概在21%~34%,现在最新的采用SwinTrans+HTC的已经可以达到57.7
- coco leaderboard,点击这里,Evaluate->选择Detection 就可以看到了
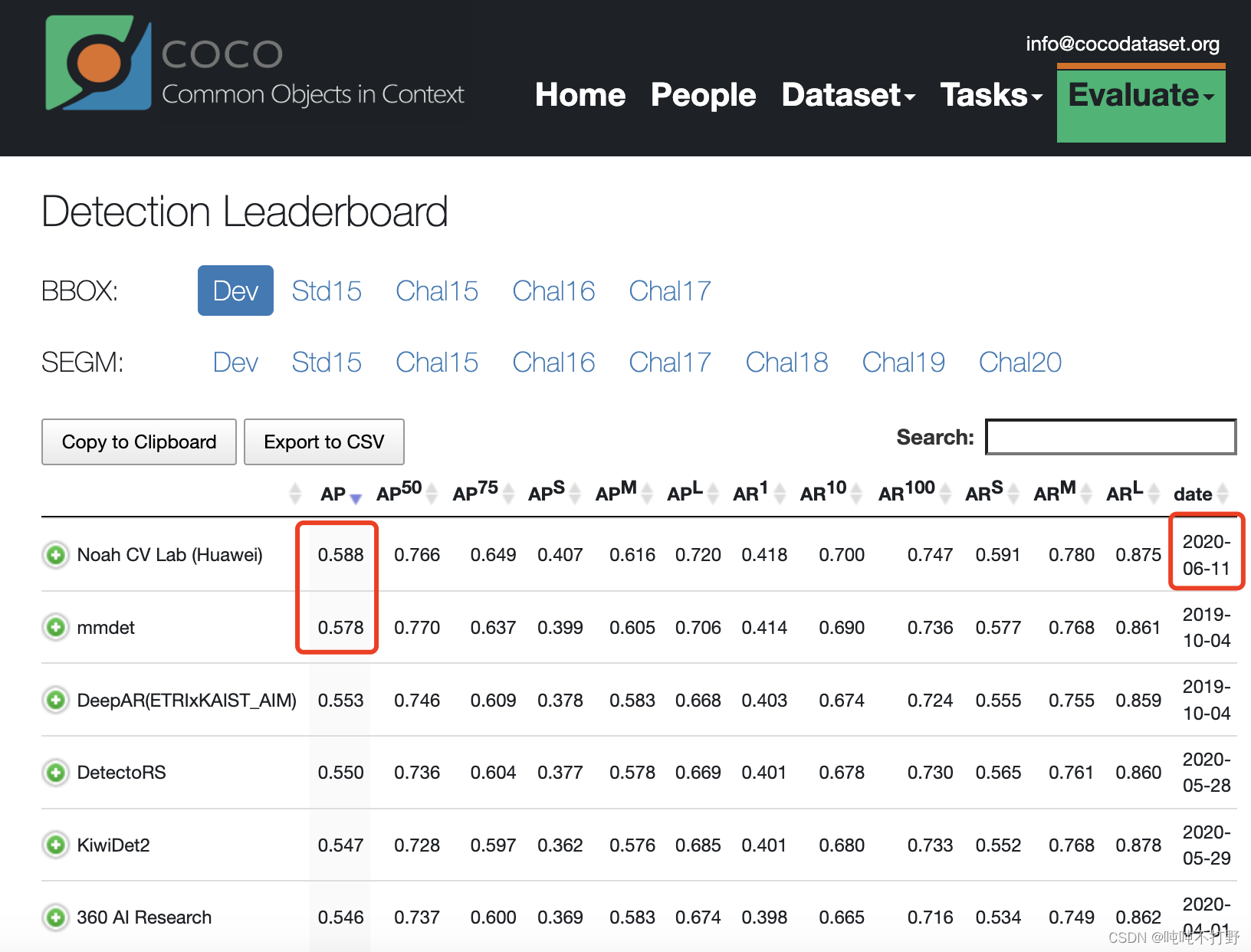
- 不会再有COCO 2021 Challenge比赛了,取而代之的是ICCV2021 LVIS Challenge ,上面介绍的SwinTrans+HTC方案就是这个比赛里出的,详见:腾讯优图斩获ICCV2021 LVIS Challenge Workshop冠军及最佳创新奖
- 另外,虽然COCO不再举行官方赛事,但是还是有人在刷分,
- paperwithcodes上:Object Detection on COCO test-dev,目前排名第一的是:OpenGVLab/InternImage
- 关于OpenGVLab,详见:上海人工智能实验室联合商汤科技发布通用视觉开源平台OpenGVLab
推理速度和模型体积
- 都是YoLo系列最好,所以落地部署基本都是yolo和ssd
- YoLoX-s推理速度大概10ms,1000ms/10ms=100帧,每秒差不多就是100帧的速度。。
1.0-2 基本概念

- 一般要求目标检测的边界框是平行于图像边界的,如果不平行的话,会有个专门叫做旋转框的方式去处理
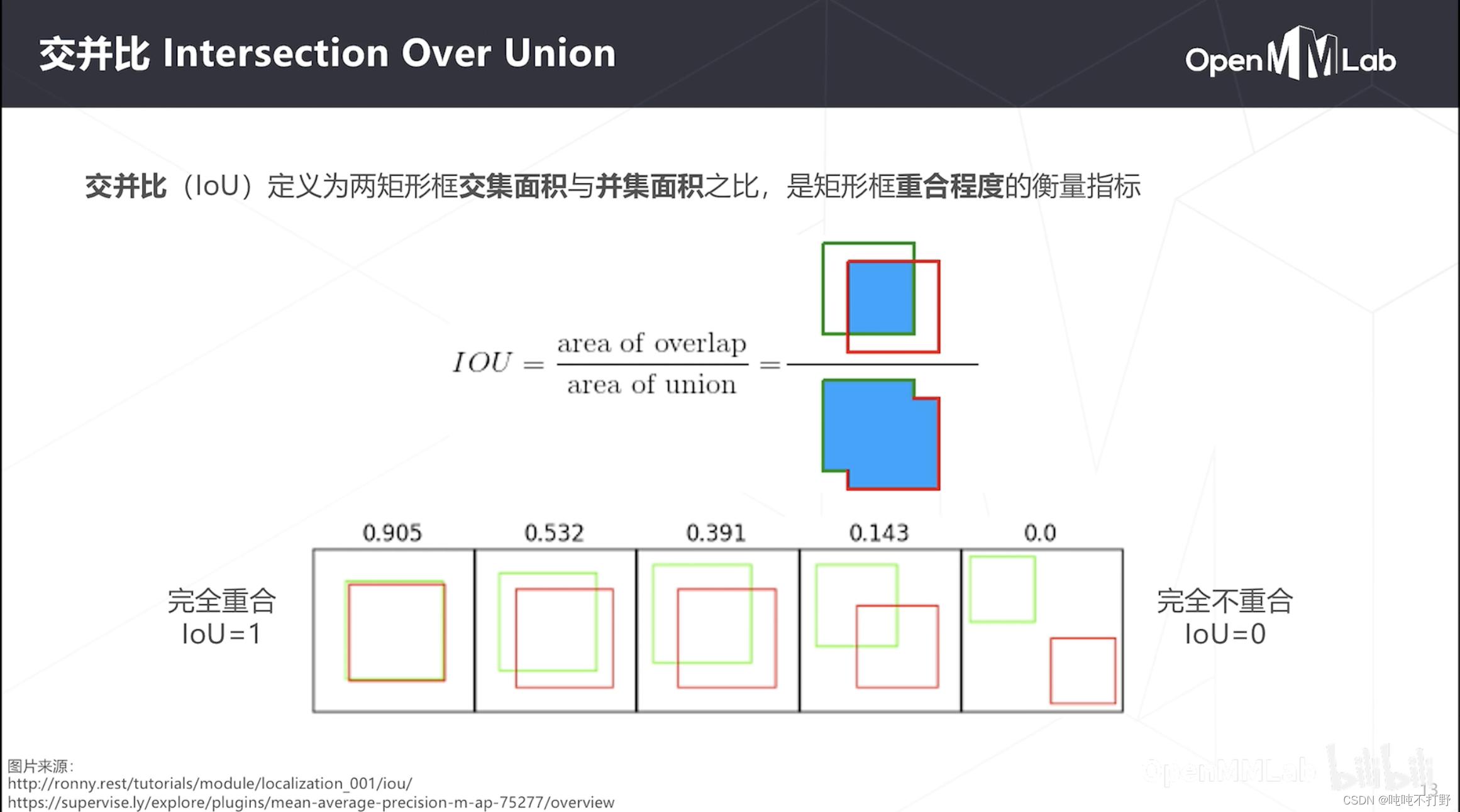
都是算重叠区域,和DICE很像,但是不一样,衡量的都是重叠程度,但是计算方式不一样。
关于这两个指标的异同和使用场景,可以看看:
- CSDN博客:分割网络评价指标)dice系数和IOU之间的区别和联系
- 知乎文章:有关IoU和Dice
- 博客园文章:语义分割评价指标(Dice coefficient, IoU)
- 影像切割任務常用的指標-IoU和Dice coefficient
- stackexchange-F1/Dice-Score vs IoU
- stackoverflow.com-Why Dice Coefficient and not IOU for segmentation tasks?
- towardsdatascience-Metrics to Evaluate your Semantic Segmentation Model
1.1 滑窗
目标检测的基本思路:从滑窗到密集检测
1.1.1 滑窗基本思想

目标检测是基于分类任务进行的,所以分类是OK的,需要解决的主要就是定位的问题。
- 是什么,比较好解决
- 在哪里,定位,受到物体位置、数量、尺度的变化影响。

最简单(朴素思想)的一种思路:
- 设定一个固定大小的框
- 用这个框去遍历整个图像,每次把框中的部分图像送入分类器去识别,比如:背景、长椅
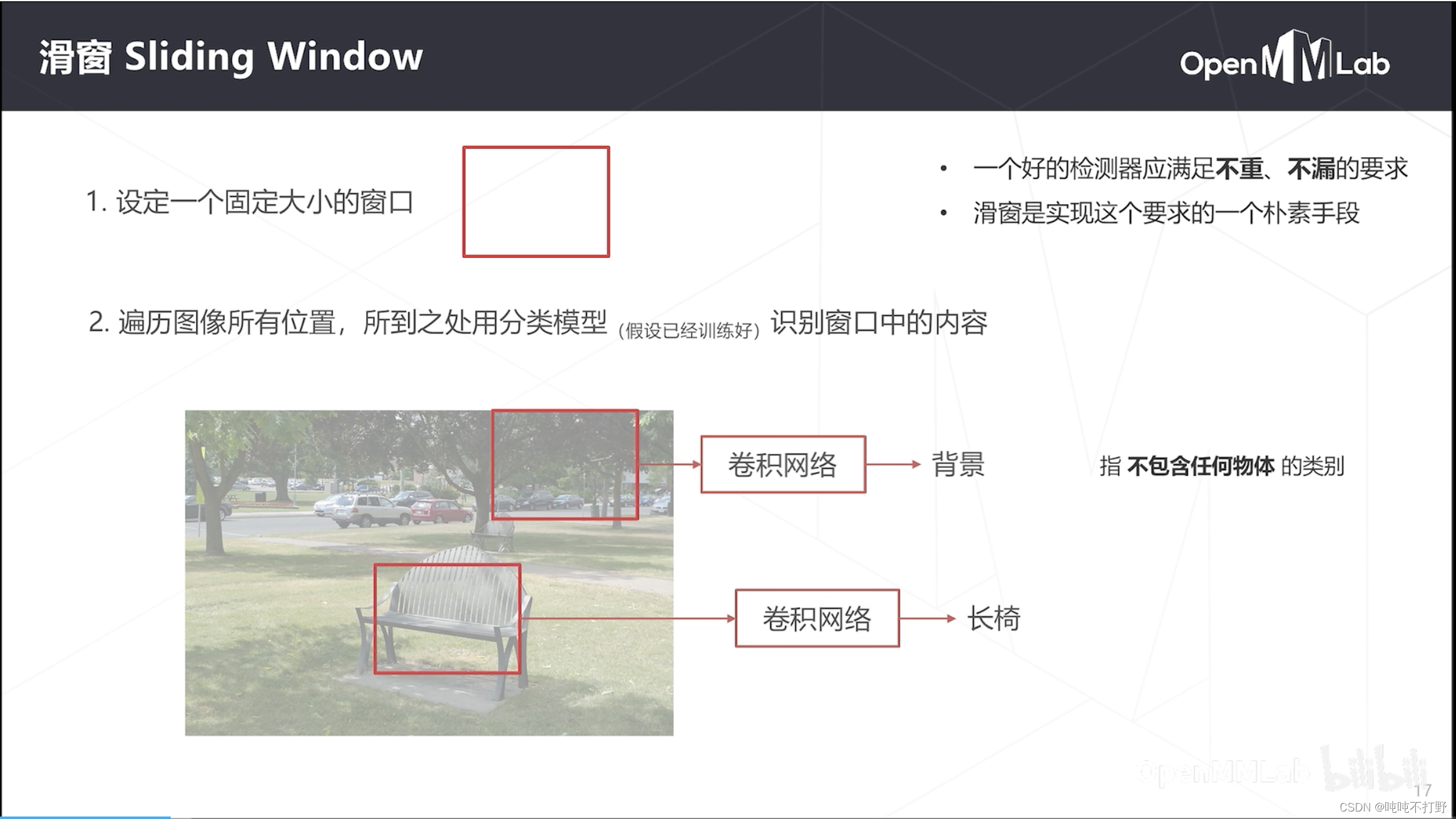
- 同时为了检测不同大小、不同形状的物体,可以使用不同大小、长宽比的窗口,扫描图片

1.1.2 滑窗效率问题改进

滑窗的思想很简单,但是会有一个效率问题:
- 例如:一张1000x600的图,窗口大小是100x100,每滑动20像素分类一次,
- 则需要滑动的次数就是(1000-80)/20* [(600-80)/20]=46*26≈1200
- 若还要使用其他尺寸的不同窗口,则需要进行分类的次数就更多了
- 滑窗顺序,串行进行分类,也可以考虑多个方向同时进行,利用并行提高速度
改进思路:
- 使用启发式算法替换暴力遍历,
- 用相对低计算量的方式粗筛出可能包含物体的位置,再用卷积网络预测
- 早期二阶段方法使用,依赖外部算法,系统实现复杂
- 以前的RCNN和Fast RCNN用的是这个,现在也不怎么用了
- 减少冗余计算,使用卷积网络实现密集预测
- 目前普遍采用的方式,所以下面主要讲这种
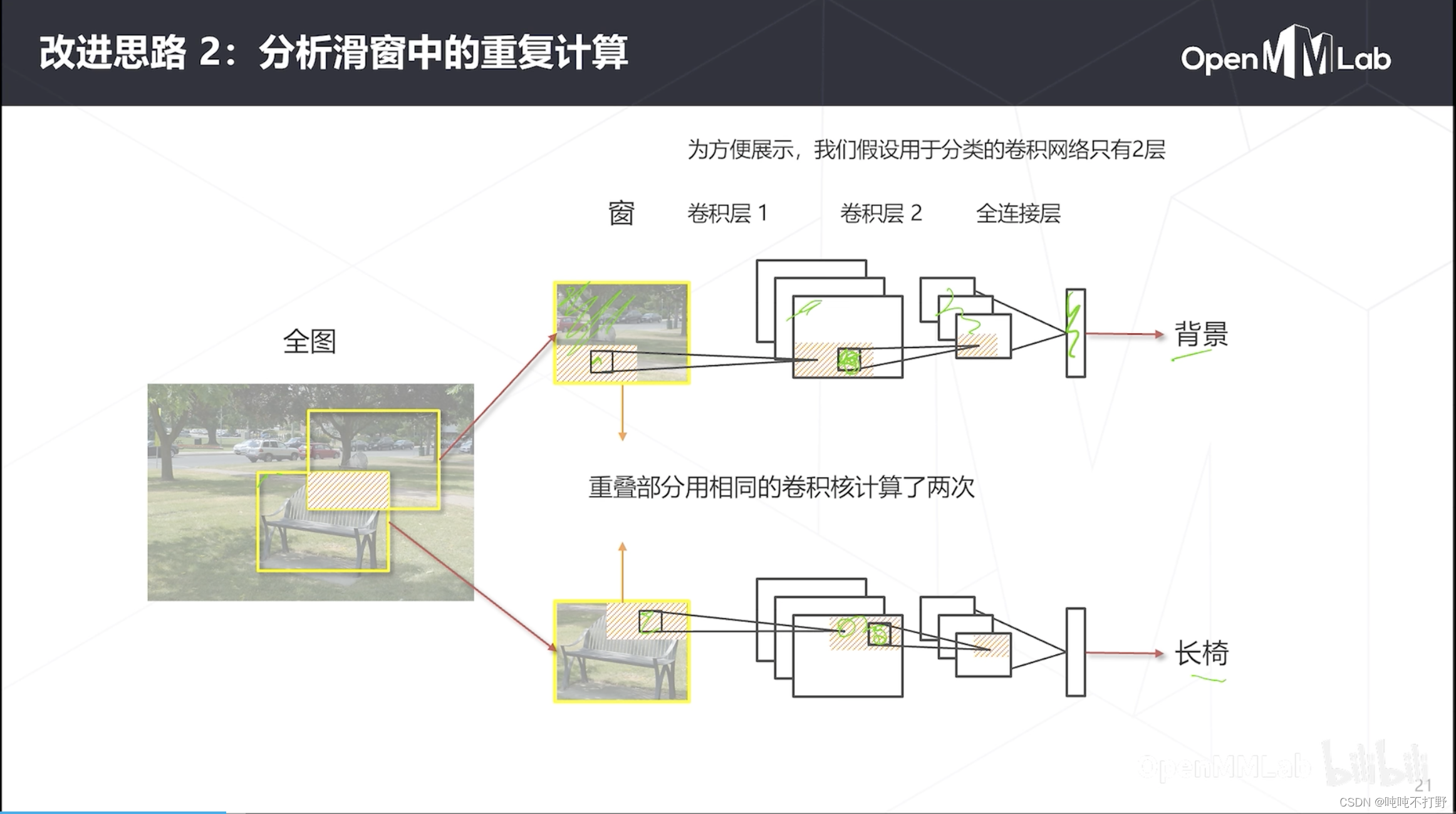
对这个滑窗框住的图像,
- 进行一次前传,前传就是:多层不同卷积核进行计算,第一层卷积核扫截出来的图像,第二层卷积核扫前一步得到的特征图,依次继续。之后特征拼起来,进行分类预测
- 可以看到,对于两个滑窗,其实有一部分重叠区域会被卷积核卷多次。
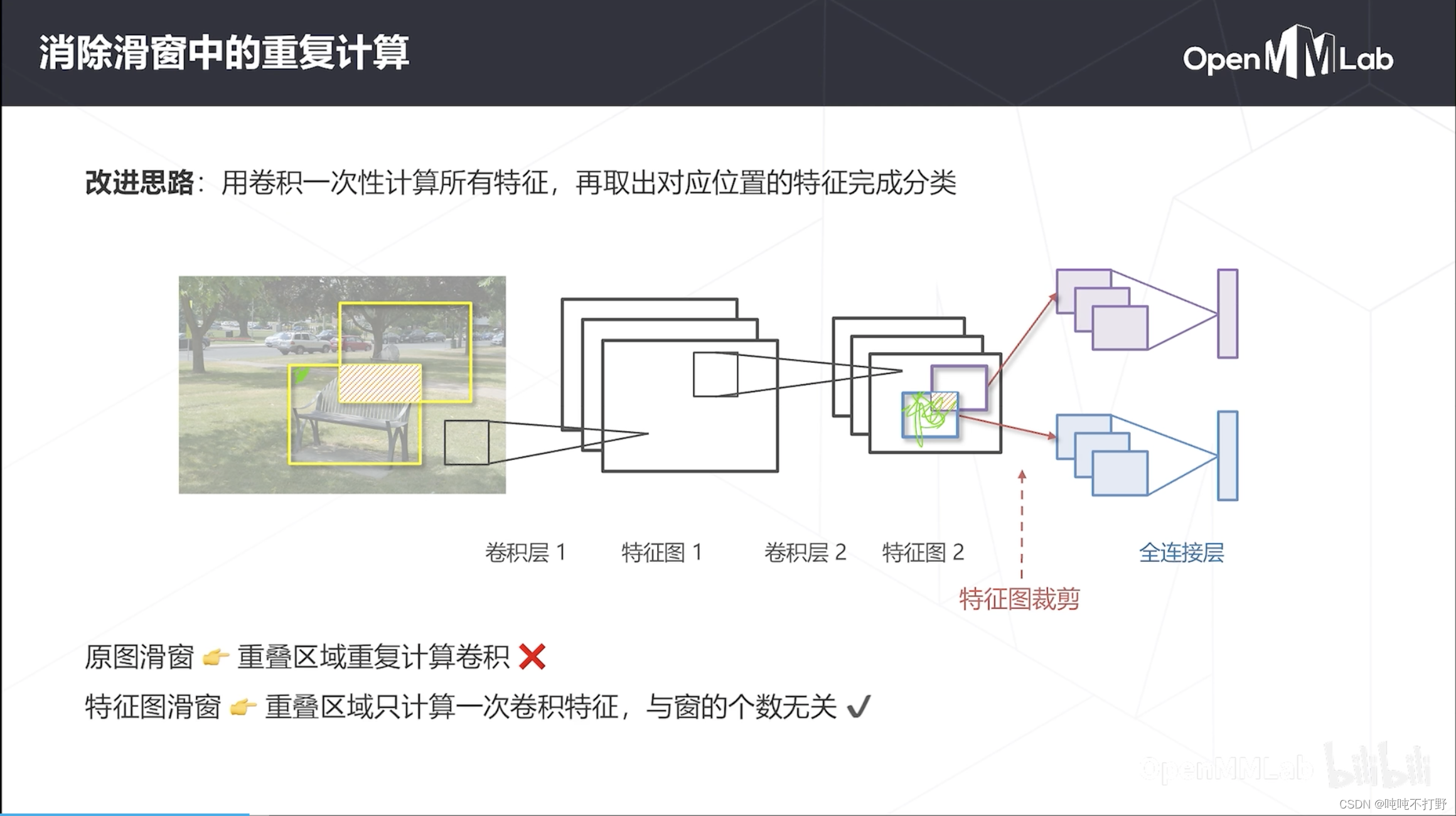
改进思路:用卷积一次性计算所有特征,再取出对应位置的特征完成分类。
- 如果要对上图两个窗进行分类,可以直接计算出全图的特征图;然后再按照位置关系,把窗对应的部分投影到特征图上,把对应的特征裁剪出来,进行后续的分类
- 因为卷积本身是具有位置不变性的,同一个卷积核在不同的位置,计算时那个系数是一致的。也就是说:先把窗扣出来算,还是算完全图再扣出来,结果是一样的(忽略padding那些带来的影响的话)
- 第一个卷积层的滑窗可能是100x100,卷积后在特征图上,滑窗大小会发生变化(但是要保证对应的感受野不变,有相应的计算公式),后续也是如此。
相比之前:
- 之前是在原图上进行滑窗,每次滑窗都要计算卷积核,重叠区域会重复计算卷积(每层都这样),每层都会进行滑窗,再计算卷积。
- 现在是直接在特征图上滑窗(注意,滑窗和卷积不一样,滑窗的固定框大小一般大于卷积核),只在最后一层特征图上滑
- 把所有的卷积层都计算完,直接在最后的特征图上,在卷积层不使用滑窗。。。只在最后用滑窗对应的特征图部分拿出来进行分类
- 重叠区域只计算一次卷积特征,与窗的个数无关(卷积计算次数和窗的个数无关)
1.1.3 感受野计算
参考:
- 之前TensorFlow有一个脚本专门用来算感受野的
- https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/receptive_field,这个文件已经不见了
- https://github.com/timsainb/tensorflow-2-feature-visualization-notebooks
- https://github.com/google-research/receptive_field,但是也有使用到它的

感受野就是神经网络中,一个神经元能看到的原图的区域
- 如右图,2层3x3卷积,在layer3的一个神经元,其实看到的是layer1的5x5的区域
- 可以说layer3的神经元表达了layer1中5x5区域的内容,也就是说layer1中5x5区域的特征是layer3的神经元
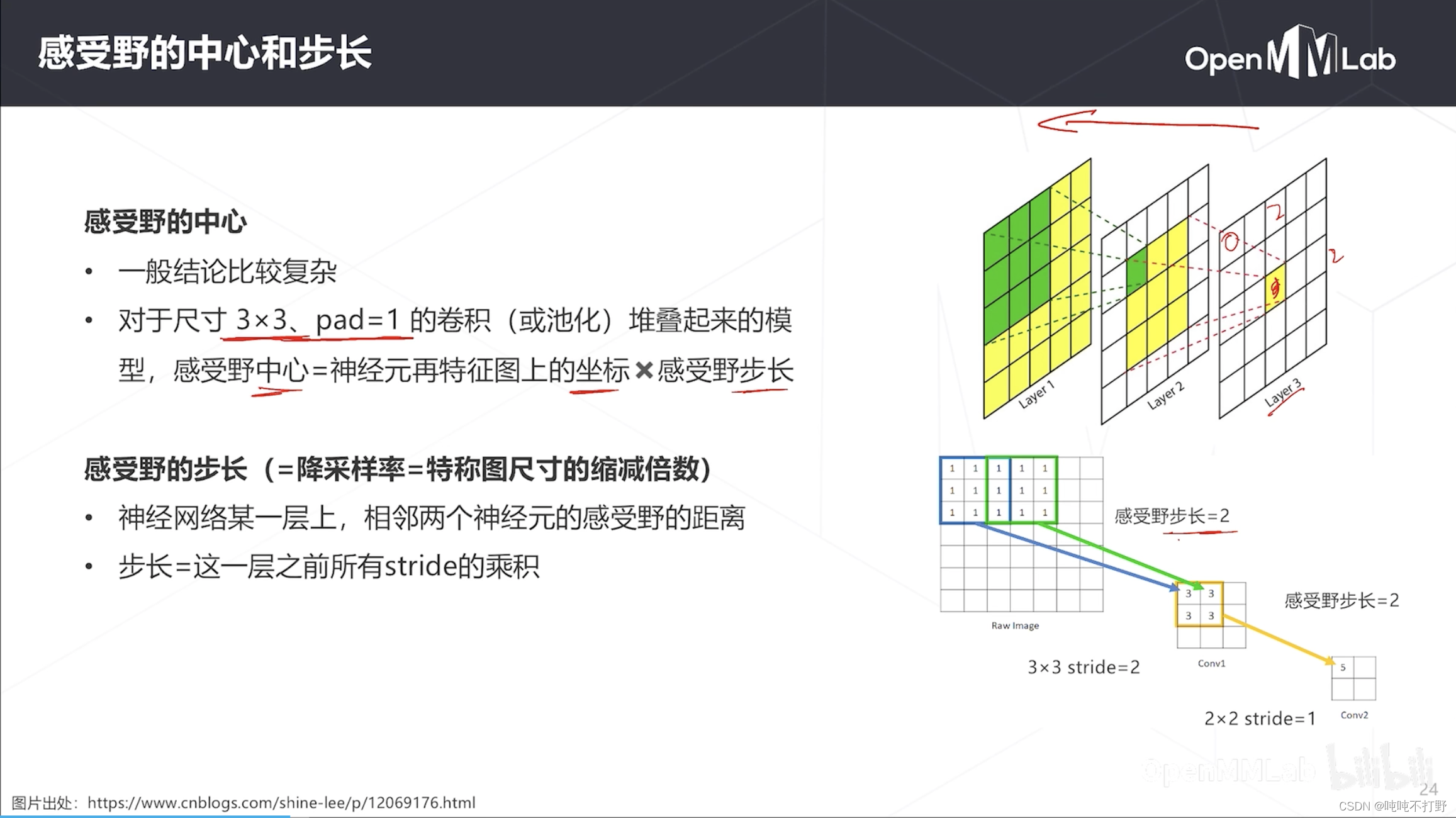
感受野的计算一般比较复杂,但是对于常见的卷积核是3x3,pad是1的卷积或池化堆起来的模型(每个卷积层/池化层都是这种设置)
- 则 感受野中心坐标 = 神经元在特征图上的坐标 × 感受野步长
- 感受野步长=降采样率/特征图尺寸的缩减倍数
- 神经网络某一层上,相邻两个神经元的感受野的距离
- 步长=这一层之前所有stride的乘积
以右图下面的带数字的示意图为例,计算Conv2上的神经元的感受野中心坐标(layer1是Raw Image)
- 则Conv2(layer3)上数值为5的神经元在Conv2这个特征图上的坐标就是(0,0),从0开始计数
- 感受野步长,从Conv2到原图,中间所有卷积层、池化层等包含stride的,把这些stride累乘起来,就是Raw Image→Conv1的stride=2,Conv1→Conv2的stride=1,则感受野步长=2x1=2
- 上面的示意图有问题。。图画的不好,也没有加padding
关于感受野的计算,可以看看:
- distill.pub-Computing Receptive Fields of Convolutional Neural Networks
- Understanding the receptive field of deep convolutional networks
- 其他中文感受野计算好像很多还有问题,也基本上是从distill那篇翻译过来的。。。有空自己研究研究吧

除了感受野中心,其实还有感受野大小,但是感受野大小不是一个很有用的东西。。
- 对于一个神经元来说,其激活值更多受到感受野中心附近图像的影响(即:对感受野中心的位置更敏感),而感受野边缘的这些值,通常对神经元激活值计算的影响不大,以下图为例
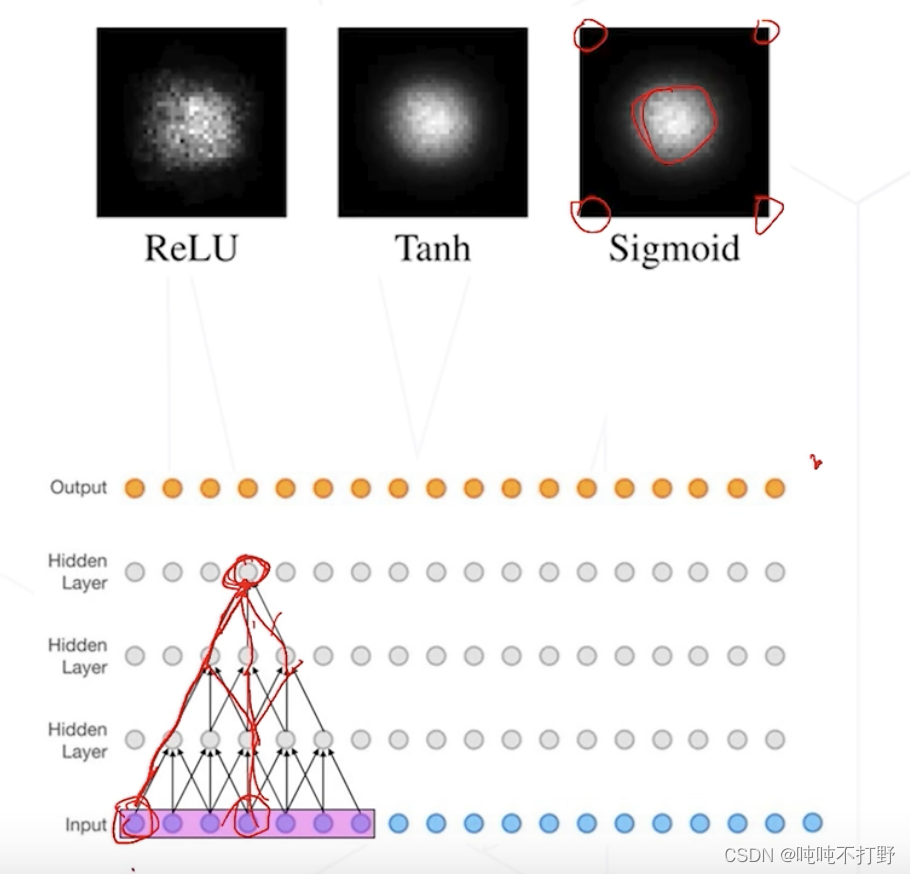
- 对顶部的这个神经元(假设是 y y y)来说,假设跟下面的神经元层的连接权重都是1(也就是卷积核的值都是1),
- 则Input中紫色框里最中间的那个(假设是 x 3 x_3 x3)的梯度,就是 ∂ y ∂ x 3 \frac{\partial y}{\partial x_3} ∂x3∂y=从 y y y到 x 3 x_3 x3所有可行路径的个数,像个pascal三角形一样扩散开。(其实就是杨辉三角,详见:神奇的帕斯卡三角形
- 而Input中紫色框里边缘部分的像素,梯度就很小,只有1条路径
- 即顶部的神经元对边缘像素的导数只有1,对中间就很大
1.2-1 使用卷积实现密集预测
1.2.1 在特征图上进行密集预测
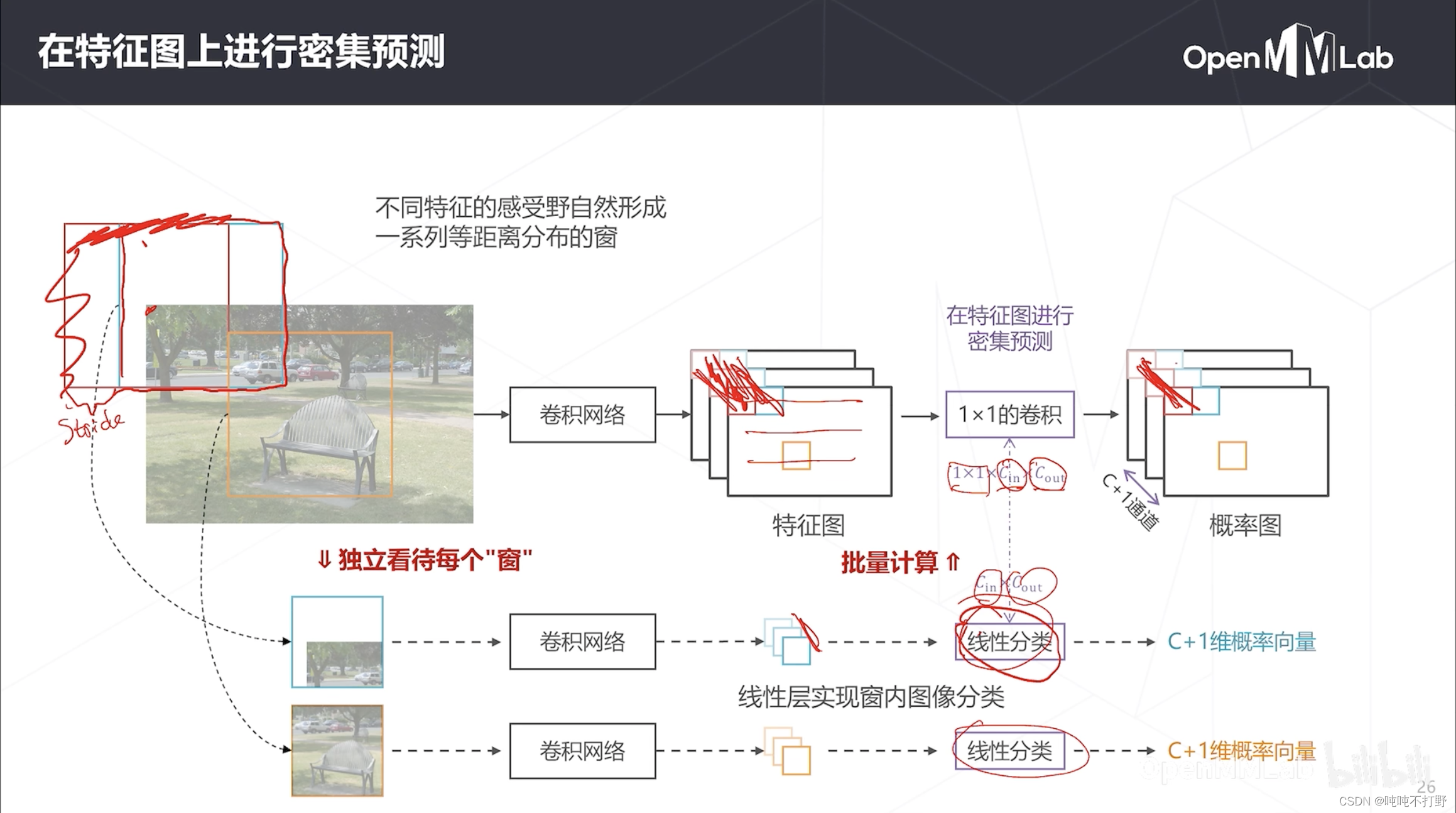
这页ppt动态的,很多内容,所以下面分小图分别说

以特征图的左上角为例,其对应的就是图像的左上角部分。
- 像红色框对应的感受野,可能会由于padding,所以就在图像外面了
- 特征图上相邻两个特征(红色和蓝色),对应在图像上红色和蓝色框的偏移量(起点的差值),其实就是stride,就是图像的感受野步长/降采样率/特征图尺寸的缩减倍数,就是上面说的:神经网络某一层上,相邻两个神经元的对应的感受野的距离;( 步长=这一层之前所有stride的乘积)
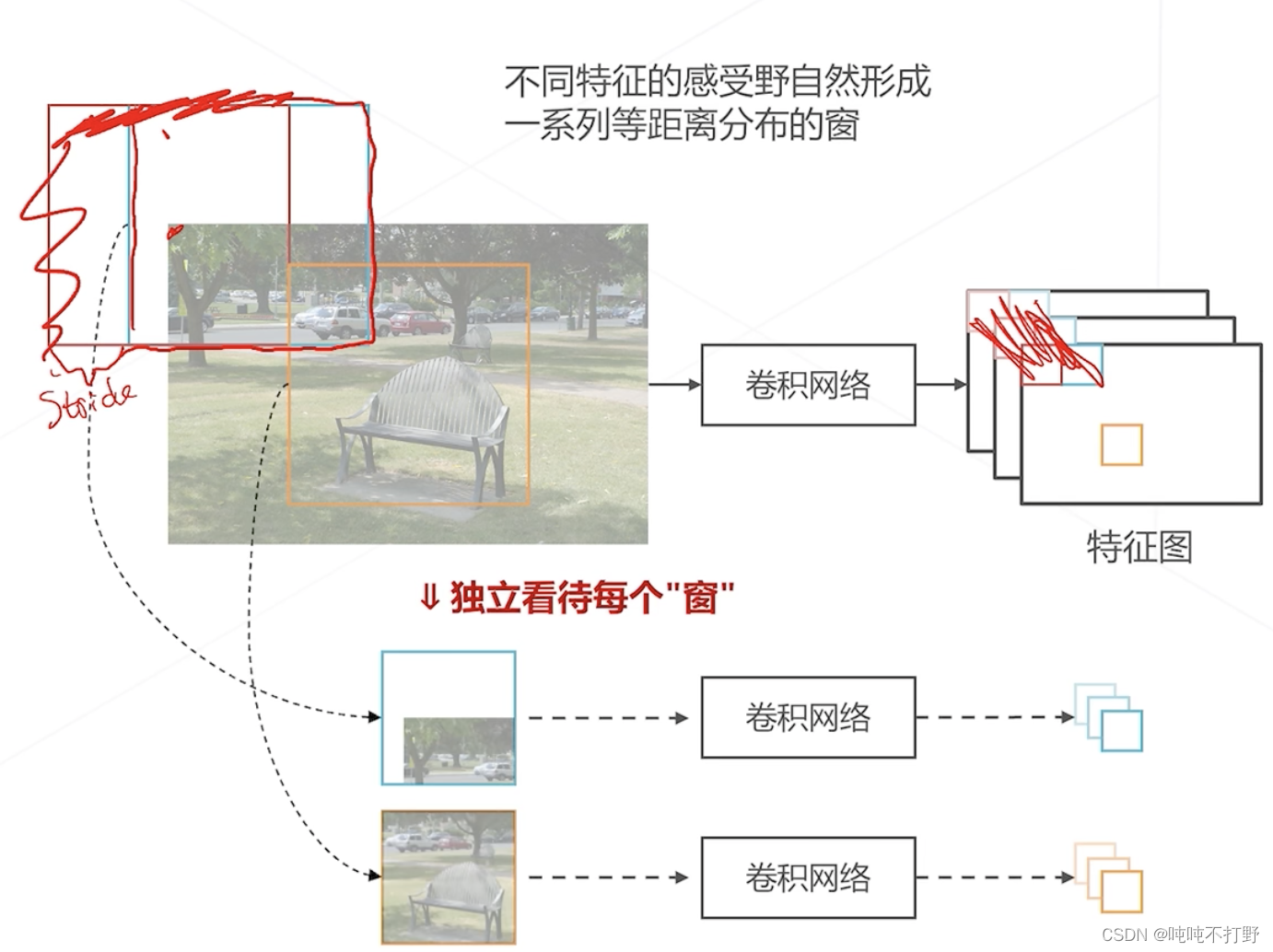
其实在卷积过程中,特征图上每一个值都对应一个感受野区域。
- 不同特征对应的感受野区域,自然形成了一系列等距离分布的窗(和滑窗的效果其实一样)
- 如果按照感受野的步长去设置滑窗,则实际上滑窗算法和一次性计算出全图的特征图的算法,就是一样的计算了
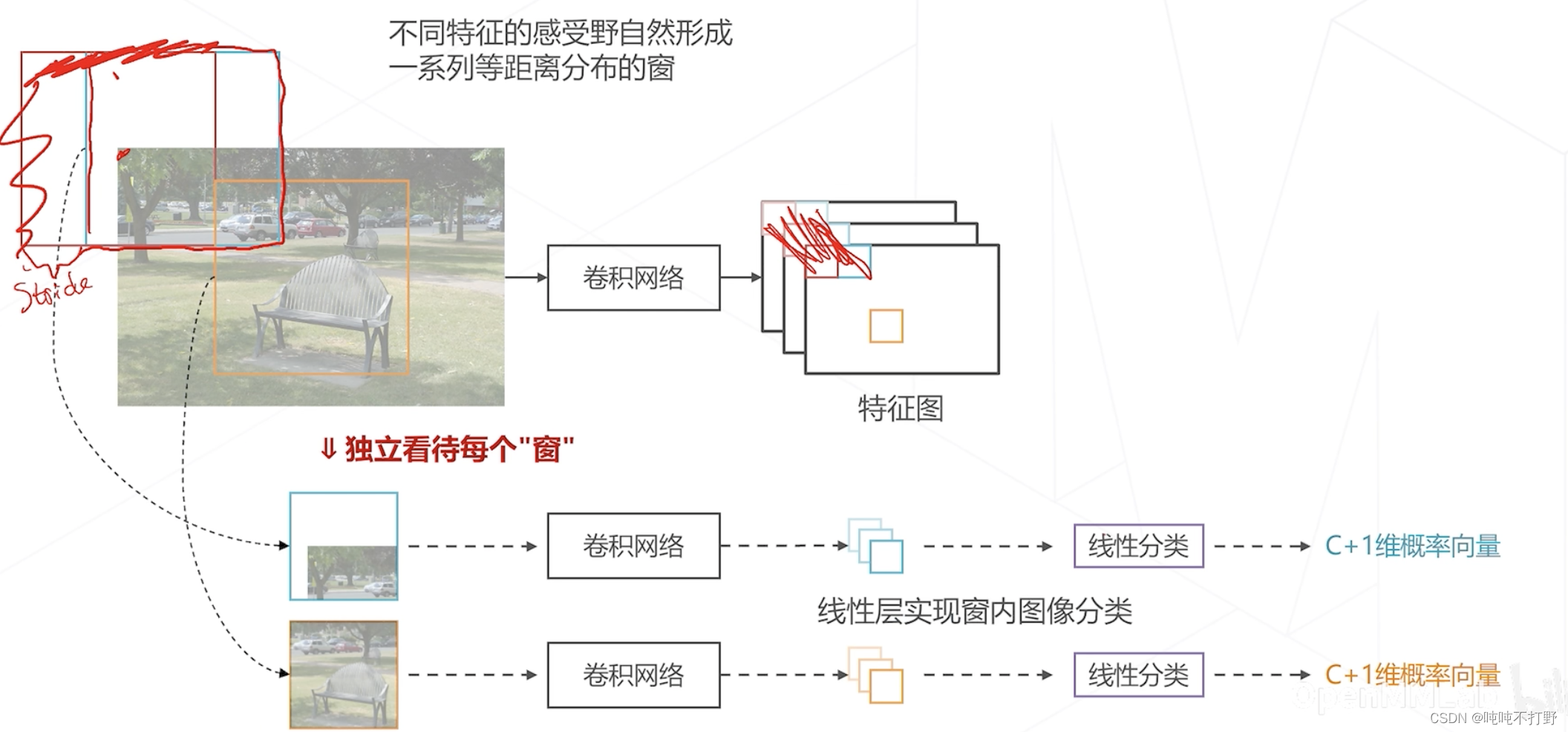
如果把感受野形成的区域看成是窗,那么按照以前的滑窗算法的思路,
- 经过卷积网络得到特征之后,还需要进行分类,比如说用线性层进行分类
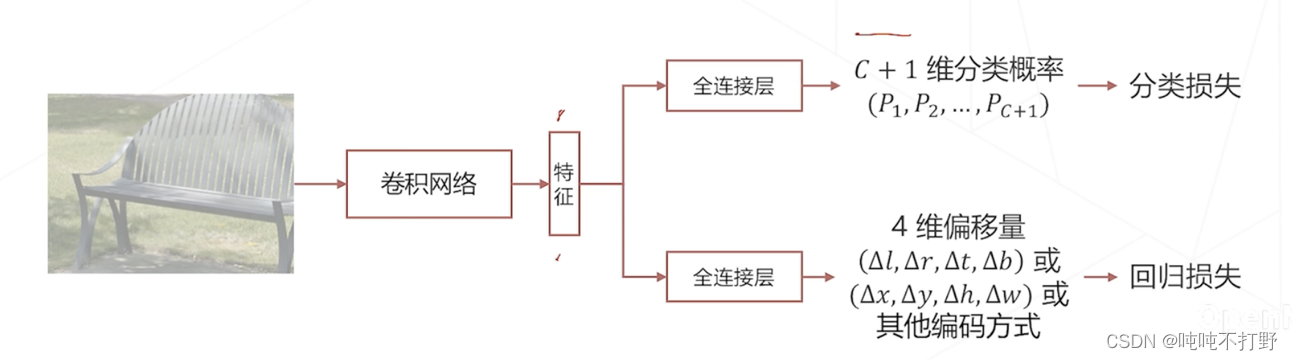
- 如果物体是 C C C个类别,加上一个背景类,就是 C + 1 C+1 C+1个类别,那么线性层就需要输出 C + 1 C+1 C+1维度的logistics(就是sigmoid函数),输出0和1之间的值,一般会在后面再接一个softmax,输出1个框分别属于 C + 1 C+1 C+1个类别的概率,概率最大的就是当前这个框对应物体所述类别
- 关于logistics函数,详见:动手学深度学习V2.0(Pytorch)——10.感知机(激活函数)-4.4 sigmoid和logistics部分
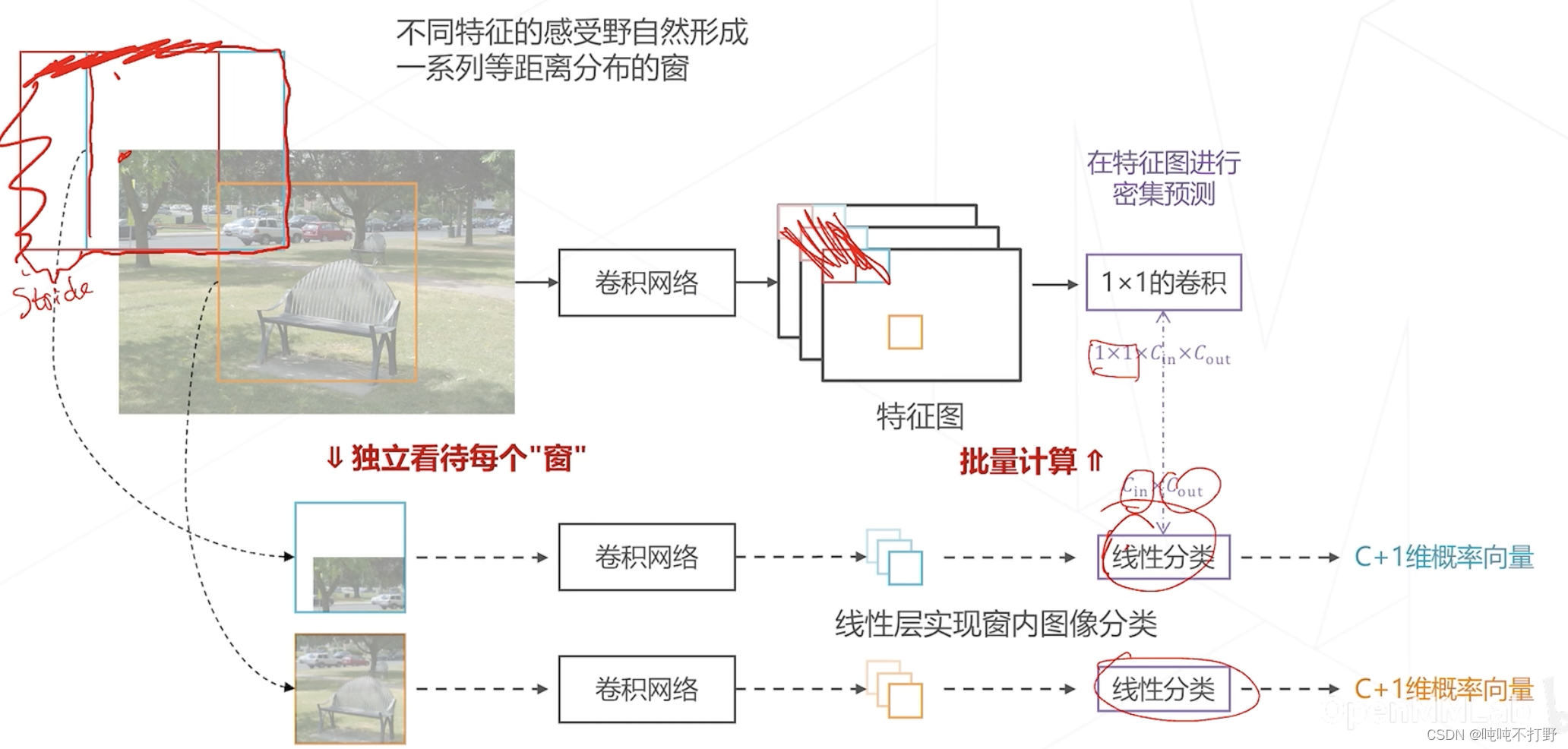
考虑有没有可能把这个线性分类也放在特征图上一次做完?
- 是可以的,因为不同窗用的线性分类参数是一样的(同一个线性层),也就是进行的计算是一样的
- 所以可以把这个线性分类层变成一个卷积层(1x1的卷积就是全连接层。。。详见:动手学深度学习V2.0(Pytorch)——21. 卷积层里的多输入多输出通道-1.6 1X1卷积层)
- 比如线性分类层的维度是
C
i
n
×
C
o
u
t
C_{in}\times C_{out}
Cin×Cout,则对应就可以找一个
1
×
1
1\times 1
1×1的卷积层,
- 即每个特征图/通道的大小是1,输入通道数是 C i n C_{in} Cin,就是线性层的输出,输出通道数是 C o u t C_{out} Cout,就是一个 C + 1 C+1 C+1维度的向量
- 这里其实是进行了一个转置,把线性分类的特征维度,变成了卷积层的特征维度
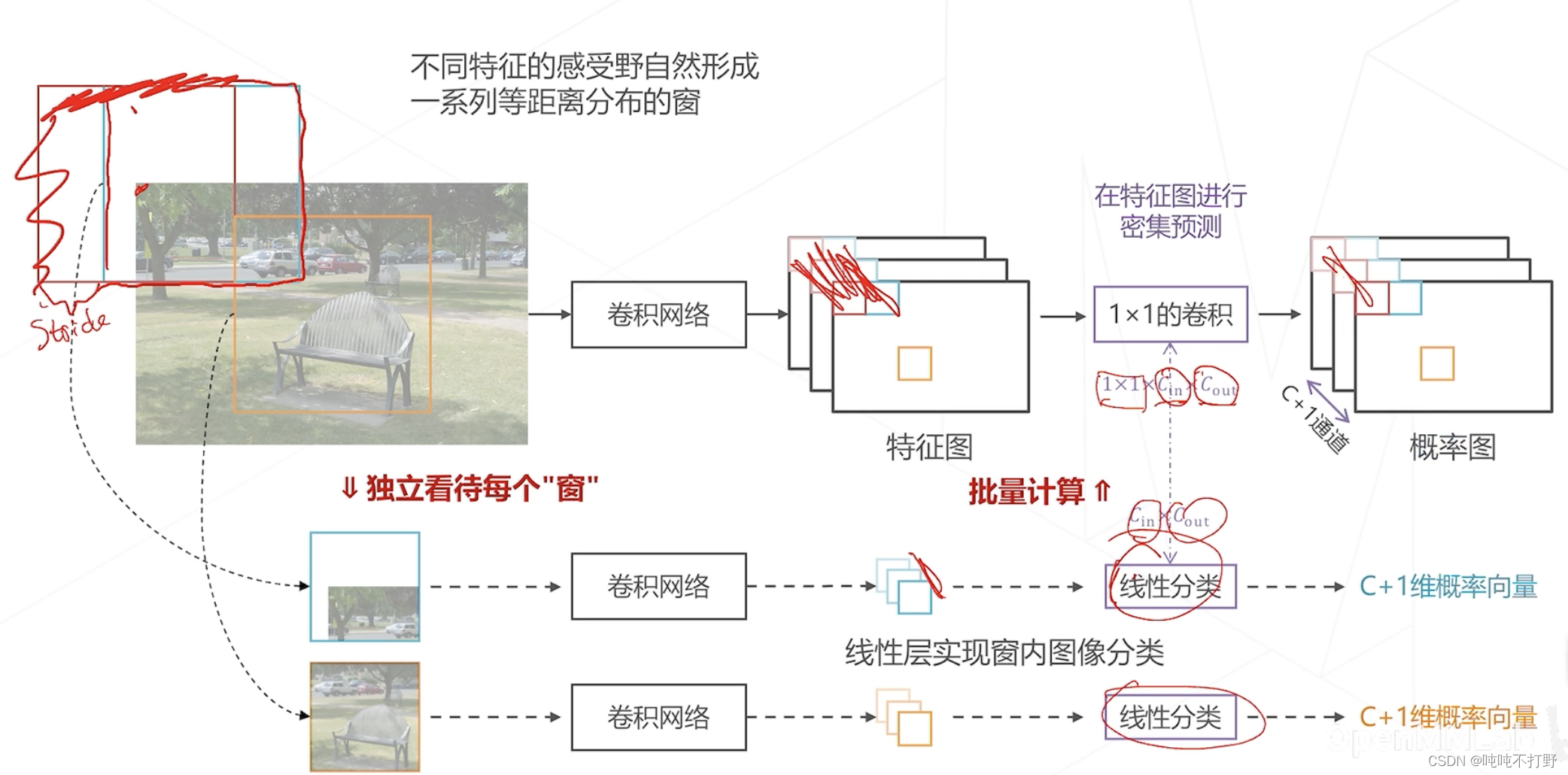
那么经过这个1x1的卷积之后,实际上得到的也是
C
+
1
C+1
C+1个logistics,卷积层一般也是用sigmoid做激活函数的。
- 如果非要得到概率图,那么在卷积层输出的特征图的通道维度上,再做一次softmax就行
- 这样的话,把特征计算和概率计算这两个步骤合起来,得到了一种更高效的计算方式,但是效果和滑窗算法一模一样
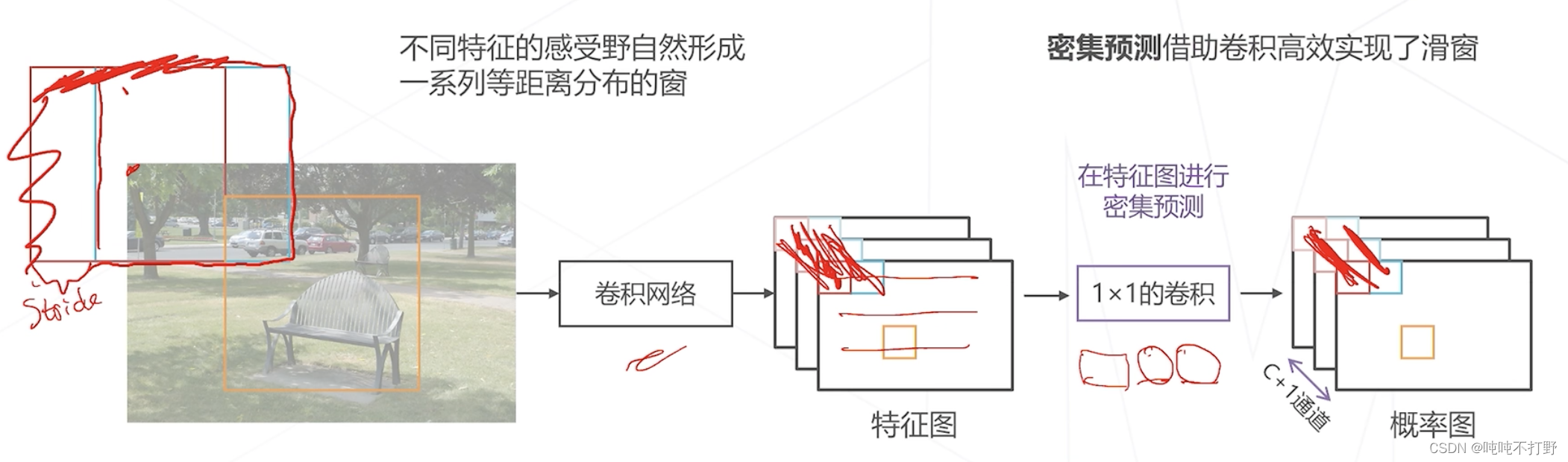
这就是所谓的密集预测,借助卷积高效实现了滑窗算法。
- 用卷积一次性计算出所有位置包含什么样物体的概率
1.2.2 边界框回归
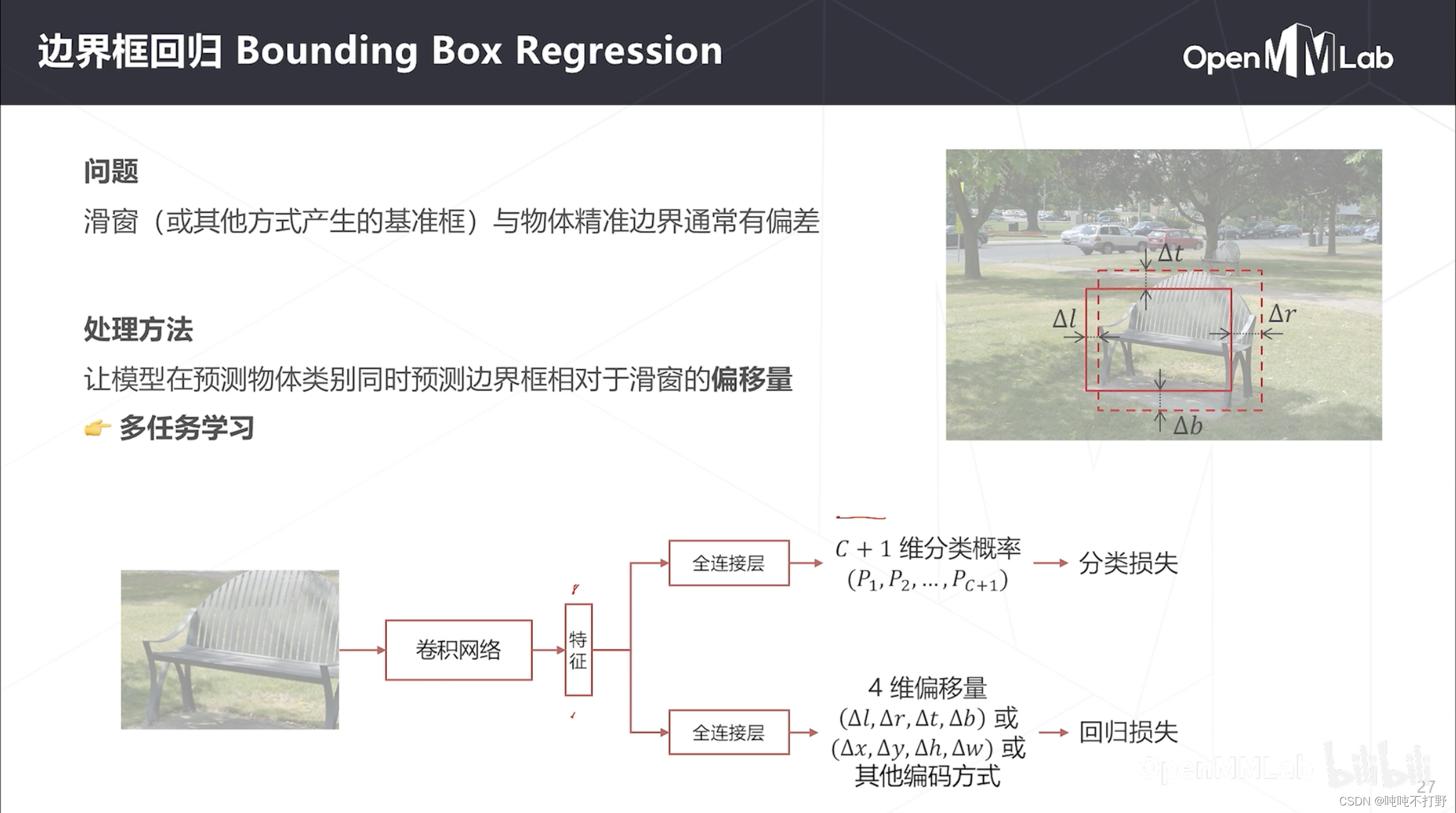
滑窗算法中固定的窗和密集预测中感受野对应的窗,和真实的物体精准边界通常存在一定差异。
- 为了实现边界框的精确定位,通常还需要进行一个额外的步骤,即在预测物体类别的同时,还需要预测一下物体的准确位置
- 一般对卷积网络得到的特征:
- 一个分支经过全连接层,用sigmoid和softmax求概率,使用分类损失
- 另一个分支经过全连接层,预测真实边界框相对于之前 窗 的偏移量,4维偏移量,比如左上右下偏移,或者中心点的x、y偏移+长宽的偏移,使用回归损失
- 由于是使用同一种特征做了两个任务的预测,所以这种也称为多任务学习。
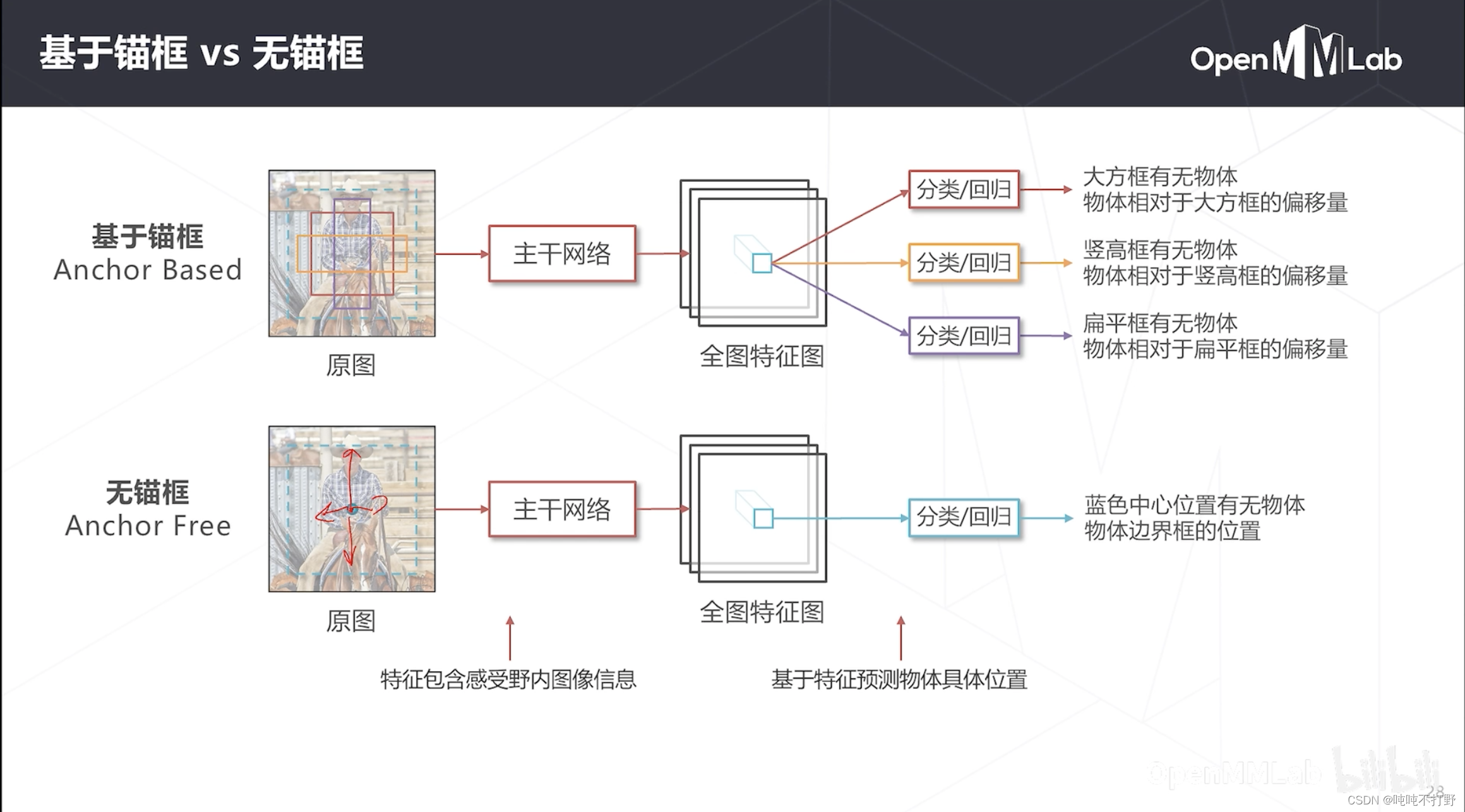
基于锚框(Anchor Based)的方法:
- 在图像上设置一些大小不同的基准框(不是滑窗,不做卷积计算),在进行边界框回归时,是基于这些基准框进行的。
- 例如:上图中蓝色框是True Label
- 人相较于紫色框,有多少偏移量,计算出这个东西(基于锚框的偏移)
无锚框(Anchor Free)的方法
- 直接回归,物体边界相对于感受野中心的偏移量(无锚框,直接求基于感受野中心的偏移)
但是神经网络进行准确的回归任务要比分类任务困难一些,所以基于锚框的方法会降低回归的难度,
- 但是锚框方法并不只是纯粹为了边界框回归而设置的,或者说锚框不仅只有降低回归难度这一个作用
- 基于锚框还可以检测:同一个位置,不同大小甚至有所重叠的一些物体
1.2.3 非极大值抑制(Non-Maximum Suppression)

滑窗和密集预测这类算法通常还会面临一个问题:会在一个物体周围产生很多重叠的框
- 滑窗/感受野对应窗,窗是重叠的,很可能多个窗都包含了同一个物体的不同部分,导致输出结果的时候,这个物体周围有很多框。
- 虽然这些框比真实的框有所偏移,不那么精确,但是还是包含了同一个物体。
- 这些不同偏移的窗在特征图上有不同的位置,都有可能会被预测成同一个类别,对应的前景框就会被保留下来,但是实际上这些前景框在原图上的位置是大幅度重叠的
- 对于检测算法来说,上面右图猫的位置只希望输出一个检测框就足够了,重叠的框是没有必要的,需要把多余的框去除掉。
- 去除重叠框的算法,就叫做:非极大值抑制算法,字面意思就是:只保留置信度最大的,不是最大的都删除(非极大值,抑制)
- 所以在之前的Fast RCNN算法里,会有个NMS的参数,配置最后输出的框的数量,一个物体周围只保存1个或者几个
整体的NMS非极大值抑制算法,是一个贪心算法,主要步骤:
- 把所有检测框(全图的,不是针对一个物体的,比如所有框是 B B B集合)按照置信度排名
- 找出置信度最高的框 B i B_i Bi,放到结果集 R R R中去,找到 B B B集合中剩下的与 B i B_i Bi重合的框(即IoU>0.7的框),把这些框删掉,这些框大概率和 B i B_i Bi指向的是同一个物体,但是置信度又比 B i B_i Bi低,因此删除。
- 继续进行步骤2,只保留所有重叠框里置信度最大的那个框,放到结果集 R R R,直到 B B B集合为空,说明已经处理完所有的检测框,此时输出 R R R结果集,就是非极大值抑制的结果

置信度(Confidence Score):模型认可自身预测结果的程度
- 通常会为每个框(滑窗/感受野对应的窗)预测一个置信度
置信度计算的方法一般有两种:
- 直接用之前分类预测头得到的概率作为置信度,比如对某个框,之前分类头预测的是长椅的概率是0.9,可能这个框附近重叠的另一个框,分类头预测是长椅的概率是0.8,使用这个概率作为置信度。用分类结果的概率作为置信度的衡量标准,感觉是比较合理的。
- 不使用分类的概率,让模型另外预测一个置信度,因为有真实的目标检测框,基于这个信息,可以根据框的偏移作为评判框的质量(置信度)的好坏
1.2.4 使用密集预测模型进行推理

得到一个训练好的密集预测的模型,如何去进行推理:
- 把待推理图像送到训练好的模型,得到那个预测图
- 包含分类和回归结果,分类:每个类别对应的概率;回归:每个边界框的偏移量(基于锚框或者无锚框)
- 保留预测类别不是背景的框(分类有一个背景类,删除背景类概率最大的框)
- 基于框中心,和边界框回归结果,进行边界框解码
- 比如对于基于锚框的方法,就是基准框+预测出的偏移量,得到比较精确的边界框结果
- 提前删除不是背景的框是为了避免不必要的计算开销
- 后处理,进行非极大值抑制
- 在比较精确的边界框结果的基础上,再去删除重叠的框,保留置信度高的框,比较合理
1.2.5 如何训练

重点其实在于,网络前传之后,怎么去把模型得到的一个结果,和真值进行比较,怎么去设计损失函数(返传loss的梯度)
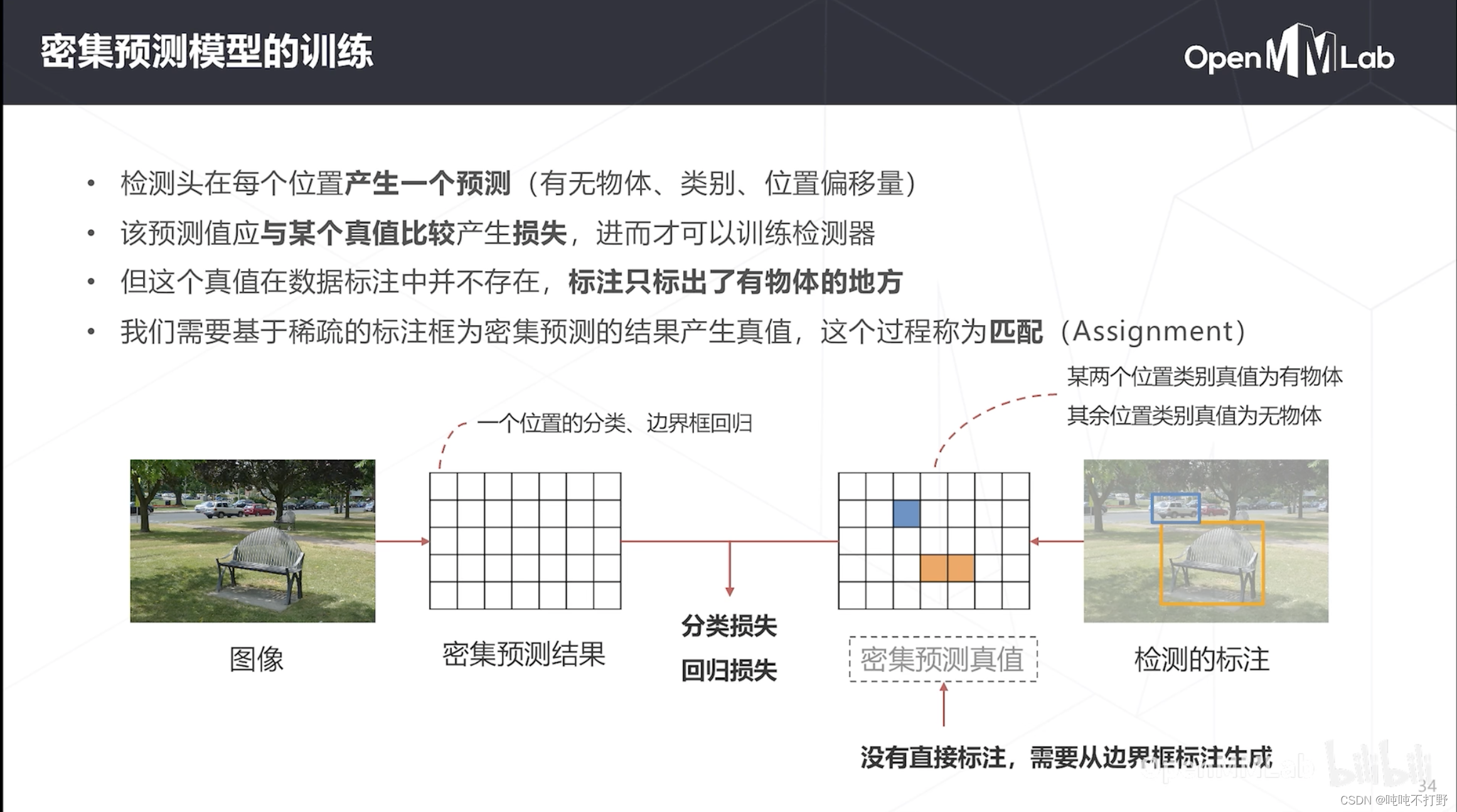
输入图像,模型输出的其实是包含位置类别和边界框回归结果的一个array of prediction results,
- 注意,每个位置都产生一个预测,这里密集预测结果的大小,并不等于图像的大小,是降采样之后的一个结果。结合上面的对特征图进行密集预测,这里密集预测的结果的大小应该是 C i n × C o u t C_{in}\times C_{out} Cin×Cout,对 C + 1 C+1 C+1通道做了softmax,已经知道每个位置的分类了,不需要保留 C + 1 C+1 C+1个通道,1个就够了
- 那么这里需要建立对应的GT(ground truth),很明显,示意图中密集预测结果的这个表格,肯定不是天然存在的,是需要根据真实的标注框去生成的。
- 原图像有物体的标注框,怎么把这个标注框的类别对应到密集预测真值上,即基于稀疏的标注框,为密集预测的结果产生真值,这个过程称为匹配(Assignment)

根据感受野的计算公式,不难知道,特征图和原图在位置上存在一个比较简单的对应关系。
- 之前是特征图上的点求对应的感受野中心,现在是要找到原图上标注框对应在特征图上的点的位置
- 对应点的类别真值就是物体标注框类别,边界框回归的真值可以是这个框的位置,也可以是框相对于中心位置的偏移量
- 对于每个标注框,其实在特征图上都可以找到与其最接近的位置(可以不止一个),接近程度由中心位置或者与基准框的IoU判断。
- 比如上图中汽车对应密集预测真值的蓝框,椅子对应两个黄框
- 其他部分的类别真值就是背景
- 这样就可以把原图上稀疏的标注,变成密集预测真值图上密集排列数组标注结果。
- 将密集预测真值和密集预测结果相减,算loss求和,就可以得到检测器的损失
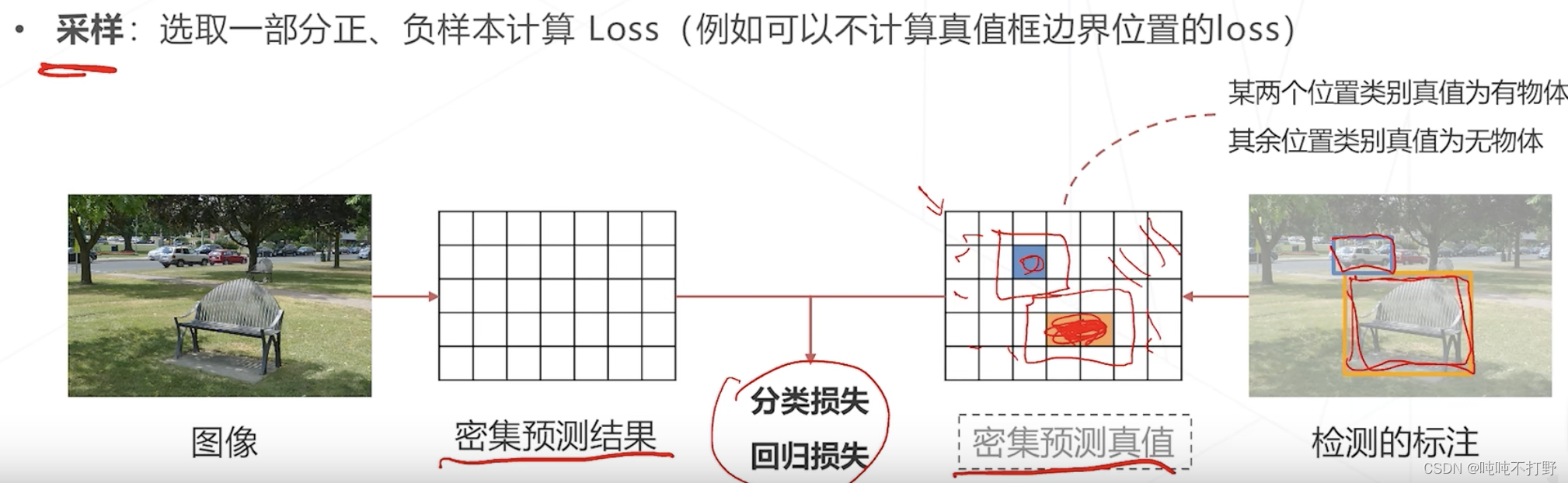
- 另外,还有个步骤:采样,
- 不是所有密集预测图上的结果都参与计算,只会选取一部分正样本和负样本进行计算
- 很明显,密集预测图上大部分都是负样本(背景),只有少数的是正样本(前景物体),全都算的话,样本数量就很不平衡了,模型可能会更多给出背景的预测,这不是我们想要的。
- 同时,对于密集预测图上,有物体的真值框的边界位置,由于是前景物体和背景的分界,所以归到哪一类都不太好,还容易给模型带来困扰,这种一般不参与loss计算。
有些匹配和采样的策略,在不同的算法里也有所区别,mmdetection的配置文件里也会有相应的标注。
这是个检测任务
- 不能单纯像分类任务一样,比较最终类别的差异;
- 这里输出的内容既有分类,又有回归,而且是基于密集预测图进行的比较,所以要基于标注框先生成密集预测图真值。
- 就像人体姿态检测,基于标注结果和高斯函数假设,生成真值热力图,与模型生成的预测热力图进行比较,以热力图的差值作为损失函数。
1.2.6 密集预测的基本范式
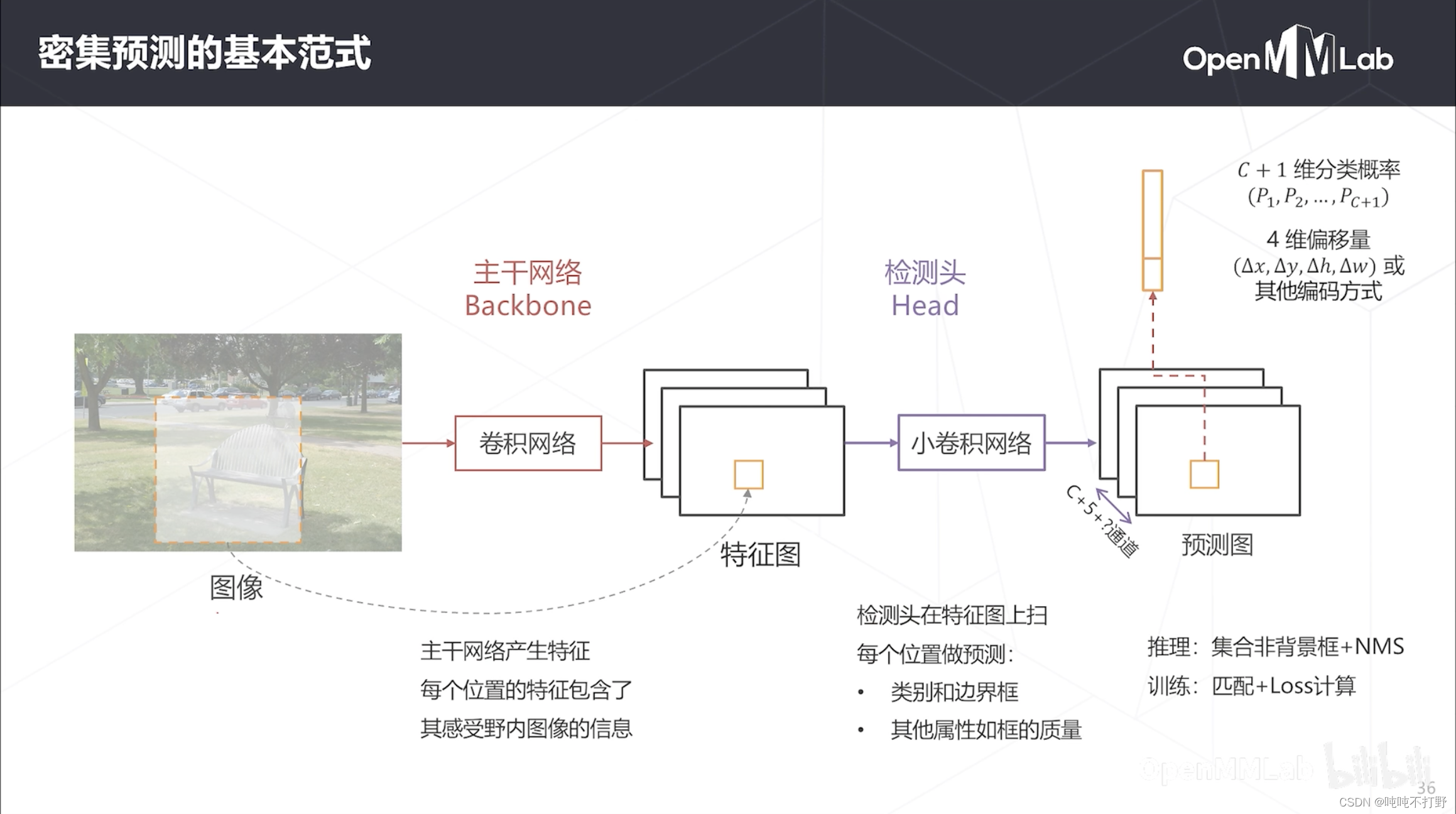
整体是一个框架性的设计思路,不是针对某个具体的网络进行说明:
- 图像首先送入backbone(主干网络,在CV里一般是卷积网络),得到特征图,特征图中每个点都是对应的原图中某个感受野区域的一个特征表达
- 得到特征图之后,用一个1x1的卷积去扫(小卷积网络/检测头),相对于在每个位置上进行线性分类,对于预测图中的每个位置,其包含:
- 该位置对应的类别和边界框(感受野的范围),以及边框回归的偏移量(如果不使用概率作为置信度的话,可能还会预测一个置信度)
- C+5+?来自于C+1(C+1个类别)+4(4个偏移量),C是类别种类,?表示可能还会预测别的东西,比如:置信度等
- 预测图的空间分辨率和特征图一样,
推理:
- 得到密集预测图,对非背景的框进行非极大值抑制
训练:
- 匹配生成密集预测图真值,包括类别真值和边界框回归真值
- 把模型生成的密集预测图和 密集预测图的Ground Truth进行loss计算,梯度回传,参数更新等。
1.3 密集预测范式的改进:多尺度预测

图像中物体大小可能有很大差异,比如可能同时存在100px的椅子和20px的汽车,
- 如果使用上面说的朴素的密集预测范式,即只检测头(head)部分,基于主干网络(backbone)的最后一层或者倒数第二层的特征图进行预测。
- 受限于结构(感受野),只擅长中等大小的物体(和卷积网络的设计,stride及卷积层等的层数有关)
- 深层的特征图经过多次降采样,位置信息逐层丢失,小物体检测能力弱,定位精度低(pooling位置精度变低,/2)
- 如何让网络可以支持多种尺度物体的检测,锚框是一种可以选择的技术
1.3.1 锚框
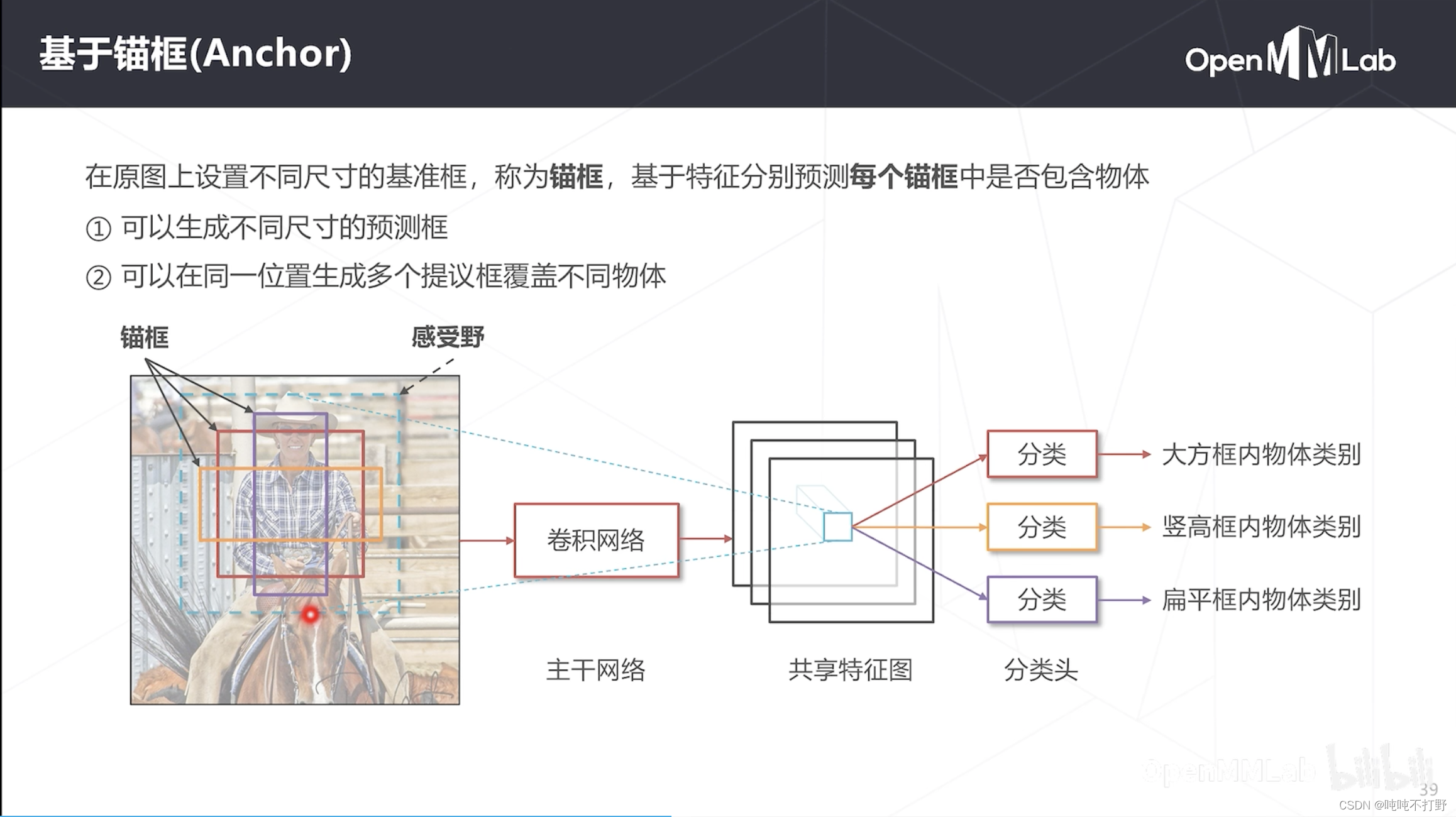
可以在原图上设置不同尺寸的基准框(锚框),基于特征分别预测每个锚框中是否包含物体
- 对于特征图中每个位置,都可以在原图找到对应的感受野(蓝色虚线框),在感受野范围内,生成锚框,可以是多种尺度和多种长宽比的。
- 但是由于锚框还是基于某个特征图的,特征图确定了,感受野范围和特征抽象程度就确定了,锚框最多能处理感受野内1倍~2倍尺度变化的物体,更大尺度变化的物体还是无法处理的
所以锚框对于处理多尺度的作用还是有限的
1.3.2 图像金字塔

其实还有一种思路,图像金字塔
- 虽然模型不能变,模型只能比较好的适应某一个尺度的物体(中等尺度)。。。
- 但是输入图像的大小可以变(可以把要检测的物体变大/变小)来适应模型可以检测的物体尺度,则:
- 在变大的图像上(小物体变成中等尺度的物体),模型就能更好的检测小物体
- 在变小的图像上(大物体变成中等尺度的物体),模型就能更好的检测大物体
这种方式
- 优势:算法不经改动就可以适应不同尺度的物体
- 劣势:计算成本成倍增加。
- 图像金字塔有多少级图像,计算成本就增加多少倍;可以用在模型集成等不在意计算成本的情况下
图像金字塔这种技术和模型没有关系,随便哪个模型配上这个技术都可以去检测不同尺度的物体(检测多尺度物体的能力进一步增加)
- 更多作为一种辅助手段来用,
- 比如有个训练好的模型,加上图像金字塔,得到多个尺度下的框,然后把这些框收集起来,一起做NMS
- 有些软件里也会有这种test time augmentation的操作
图像金字塔,只是一种辅助手段,更多还是希望从模型本身出发,来提高模型检测多尺度物体的一种能力
关于test time augmentation(测试时数据增强-TTA),
- 通常我们说的数据增强是针对训练集的,主要是为了增加训练集样本数量,让模型看的更多
- 而TTA是为了让模型对每个图像做出更多的预测,得到每个图像预测结果的合集。
- 详见:使用 测试时数据增强(TTA)提高预测结果
1.3.3 基于层次化特征

卷积神经网络本身就是一种层次化结构
- 深层的特征图对应的感受野就更大,抽象级别更高
- 低层特征图对应的感受野小,位置精度就比较高。
- 可以借助卷积神经网络本身天然的特征图层次结构特征,来检测不同尺度的物体,
- 相对于图像金字塔,这种的计算成本就会低很多,不需要把输入图像resize好几遍,forward好几遍产生多次预测结果
这种方式:
- 优势:计算成本低
- 劣势:低层特征抽象级别不够,可能只能看到边缘,去预测物体类别还是有些困难。虽然定位精度高,但是语义信息比较弱
- 改进方式:把高层特征融入低层特征,补充低层特征的语义信息,可以帮助进行小物体的预测
- 这个思路就是特征金字塔的思路
1.3.4 特征金字塔(FPN)(2016)
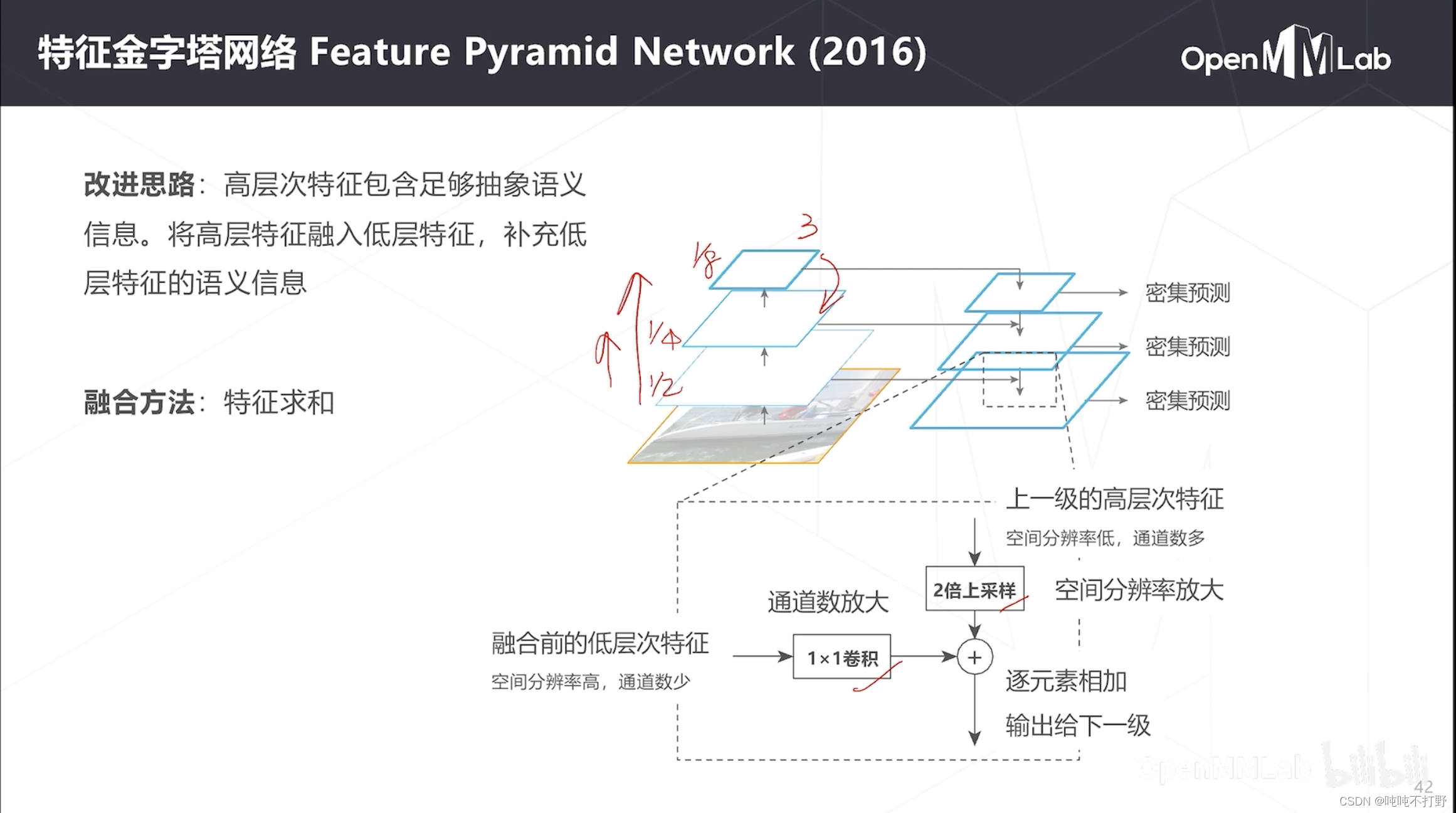
特征金字塔:feature pyramid network。以右图为例:
- 一般每次卷积,都是通道数加倍,特征图(空间分辨率)减半,所以卷积时,三个卷积的特征图的大小分别是原图的 1 / 2 1/2 1/2, 1 / 4 1/4 1/4和 1 / 8 1/8 1/8
- 那么要把高层次特征(如最高层(3层))融入到低层次特征(次高层(2))里,即对于第二层来说:采取的操作
- 把上一级的高层次特征,进行2倍上采样,特征图分辨率X2。因为从2层→3层的时候,特征图减半,所以2层的特征图本身大小就是3层的2倍,因此需要把3层的特征图放大两倍,和当前2层特征图分辨率一致
- 由于2层→3层的时候,通道数加倍,因此2层的通道数是3层的一半,所以2层自己要通过一个1x1卷积把通道数加倍。
- 这样之后,2层的特征和3层的特征维度就一样了,就可以对应相加
- 这种多尺度特征图融合,和之前人体姿态里讲的:HRNet,思路差不多,详见:OpenMMLab-AI实战营第二期——2-1.人体关键点检测与MMPose-2.2.4 HRNet(2019)
1.3.5 多尺度的密集预测
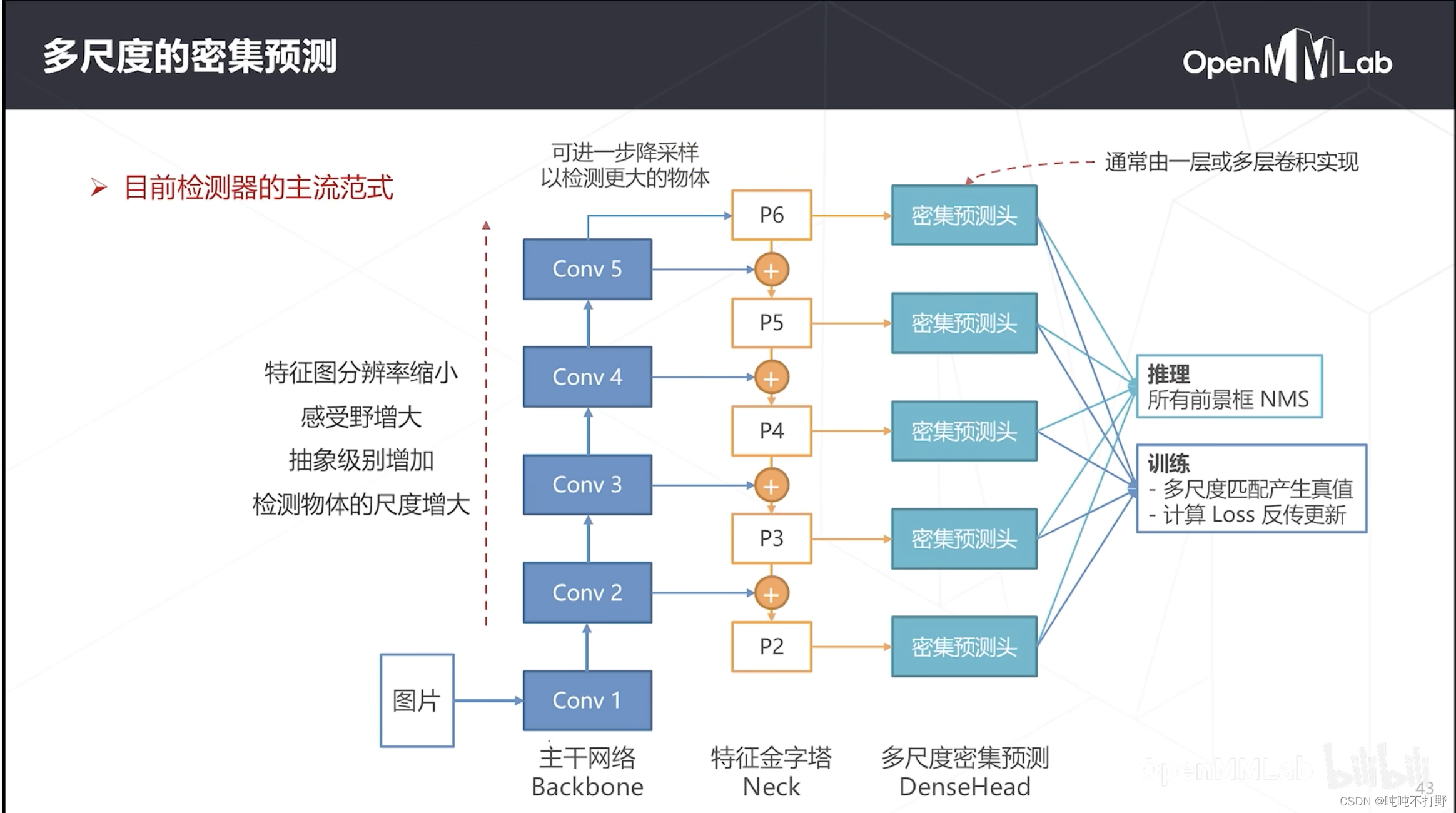
目前FPN已经是主流目标检测模模型里的一个标配了,把FPN放到密集预测里,整个网络的架构如上图,整体分为三个部分:
- 主干网络(backbone:进行特征提取),比如:Resnet,5个stage就是5个级别的特征
- 特征金字塔(neck:对主干网络的特征进行进一步处理),对多层次的特征进行融合(相邻层的高融合到低,没有跨层)
- 多尺度密集预测头(head:适应具体的任务,分类头或者回归头等),比如:上面朴素密集检测是1x1卷积,实际上可能会是多层卷积
- 推理:把所有尺度的前景框都拿出来,进行NMS后处理
- 训练:这里有多个密集预测头,即有多个密集预测的推理结果,那么就需要多组真值(多尺度匹配产生多个密集预测的真值)。可以去看看上面 1.2.5部分的如何训练,就懂了。
2. 单阶段&无锚框检测器选讲
主要选一些实用性比较强的单阶段算法进行讲解
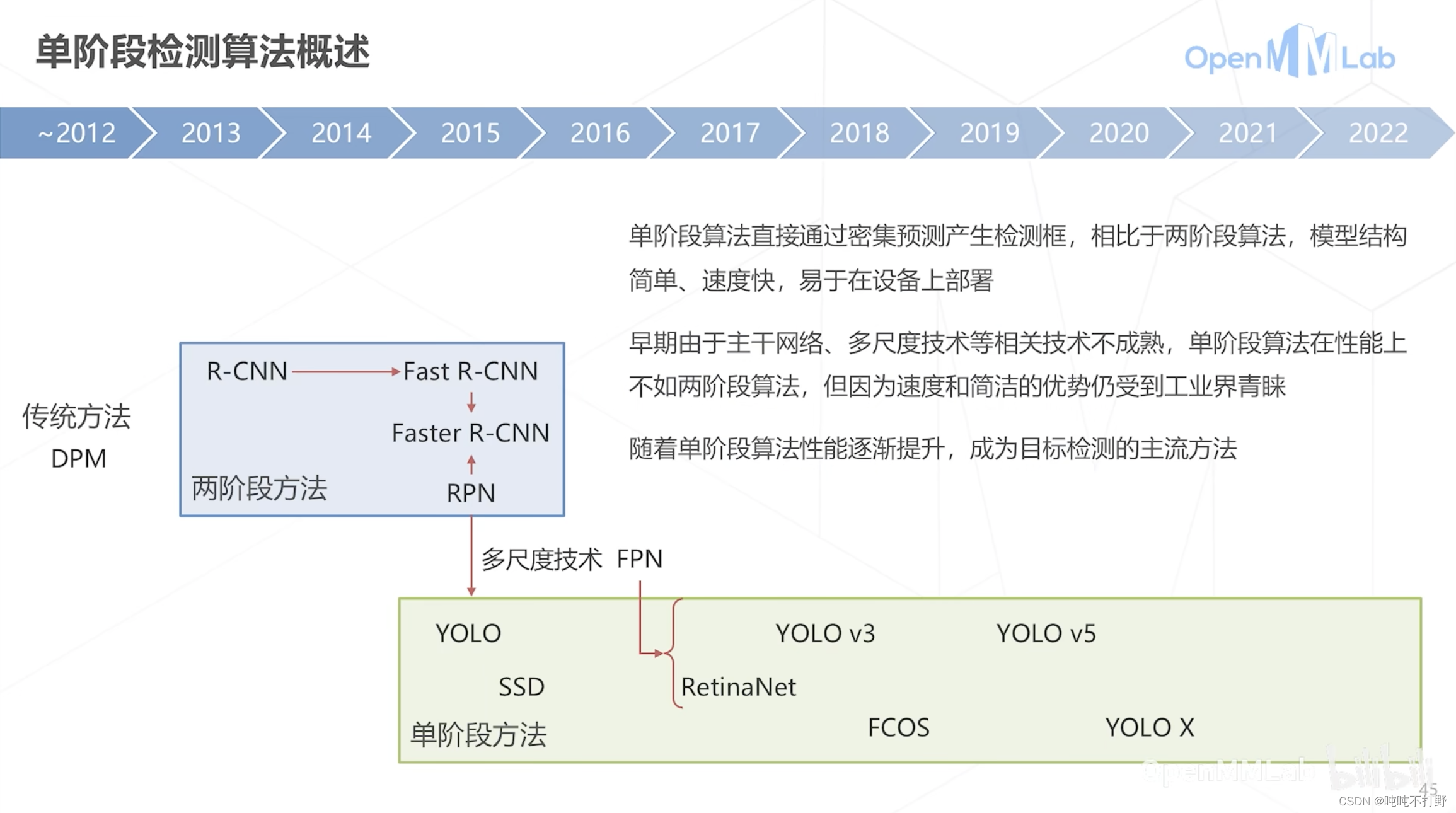
早期性能不行,所以主要是二阶段,后面单阶段性能上来了,就逐渐替代了二阶段,成为主流(17~20我上学的那三年还是二阶段比较火,工作之后单阶段逐渐就兴起了)
2.1 RPN(2015)
2.1.1 基本原理
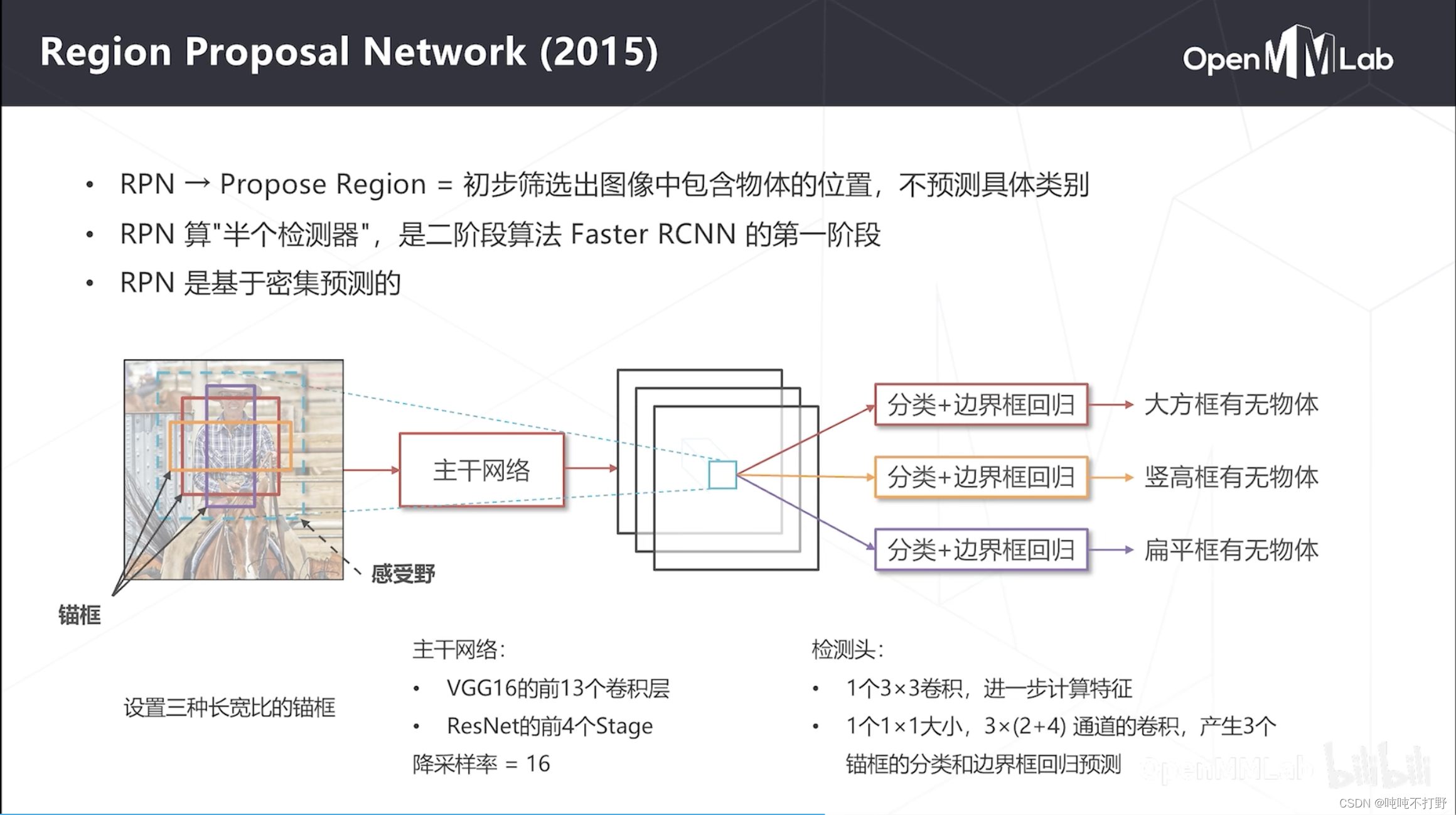
RPN严格来说不是一个目标检测算法,是半个检测算法,是Faster RCNN的第一阶段,用来初步筛选图像中包含物体的位置,不预测具体的类别。
- 可以认为是个简化的一类检测器,C=1,只检测前景和背景
- RPN应该是第一个基于密集预测的模型
只包含两个部分:主干网络和检测头,不包含FPN的特征金字塔neck
- 主干网络一开始用的是VGG16的前13个卷积层(前4个stage),后来Resnet出现了,就用ResNet的前4个Stage,经过4次降采样,所以降采样率=16(得到的特征图是原图的 1 / 16 1/16 1/16)
- 检测头是1个3x3卷积和1个1x1卷积,前者进一步压缩特征,后者产生3个锚框的分类(2:前景+背景)和边界框回归预测(4个偏移值)。这里规定只生成3个锚框
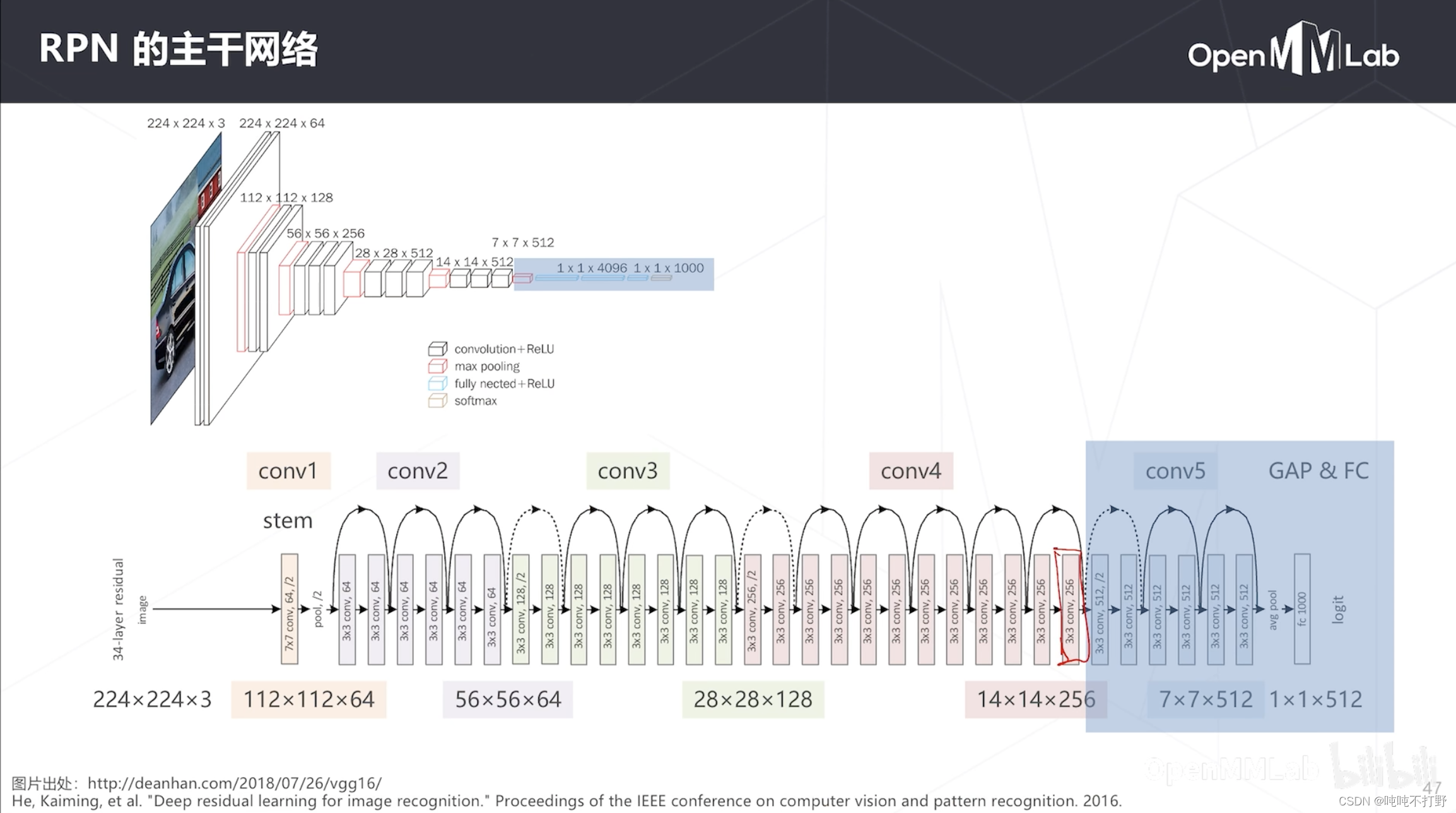
- 上面是VGG的结构,也是把蓝色的部分去掉,只用到14x14这个特征图做预测(224/14=16,下采样率=16)
- 下面是ResNet的结构,把蓝色框的第五级stage去掉,只用14x14的这个特征图做密集预测
2.2.2 RPN-head代码
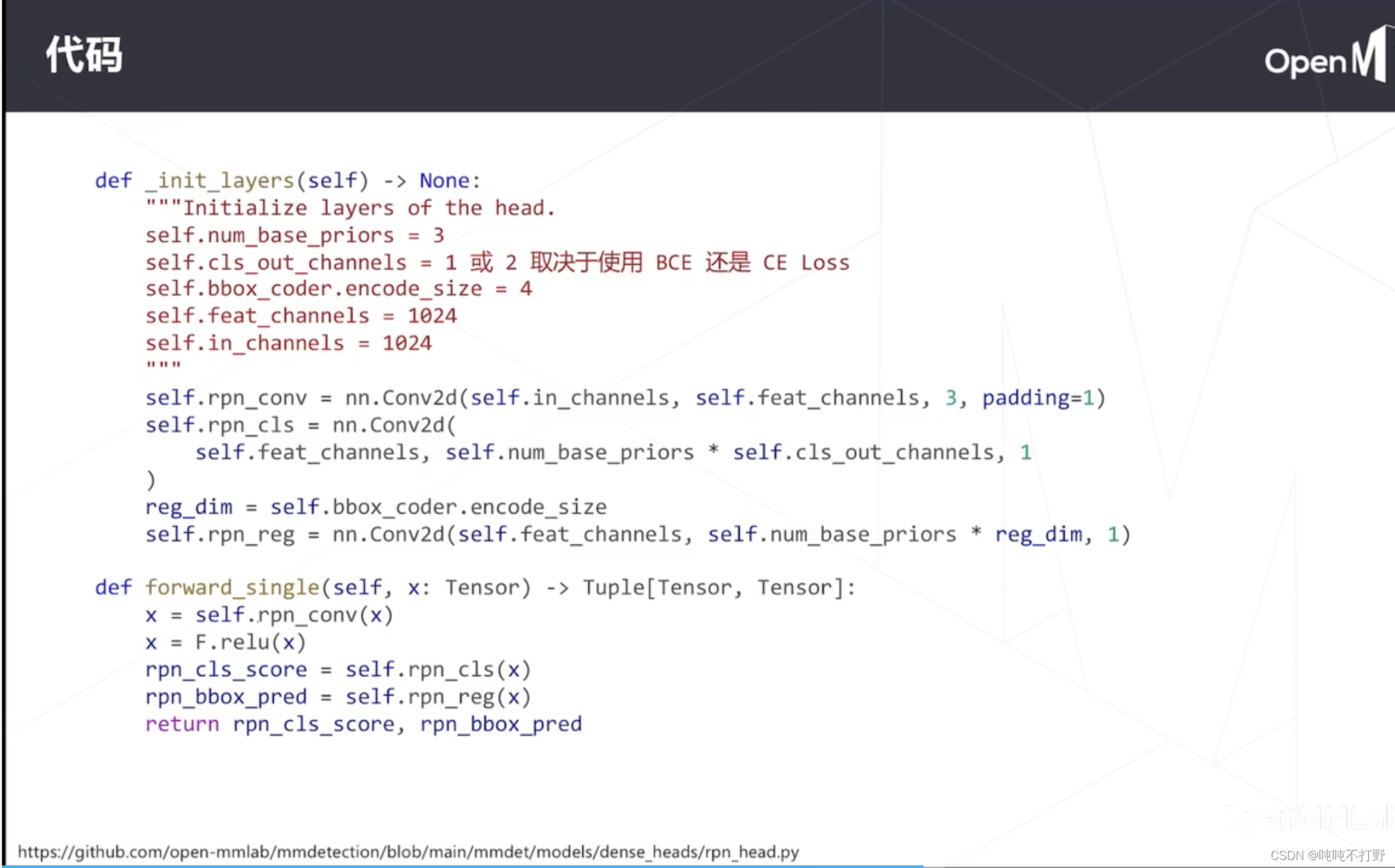
上面这个图的代码可能比较老一点,也更清晰一点。主要是forward部分,这个只是rpn网络的head,没有主干部分
# self.cls_out_channels=1或者2取决于使用BCE(Binary CrossEntropy Loss)还是CE loss(Cross Entropy),如果是2分类的CE loss,输出就是2
self.rpn_cls = nn.Conv2d(self.feat_channels,self.num_base_priors * self.cls_out_channels,1)
reg_dim = self.bbox_coder.encode_size # 这里就是4
self.rpn_reg = nn.Conv2d(self.feat_channels,self.num_base_priors * reg_dim, 1)
def forward_single(self, x: Tensor) -> Tuple[Tensor, Tensor]:
x = self.rpn_conv(x) # 1个3x3卷积,进一步计算特征
x = F.relu(x) # 经过relu
# 3x(2+4) 这里用了把之前的1x1卷积分成了两个,但是输入都是x,输出不一样,所以用了分开的两个1x1卷积表示
# 上面的num_base_priors实际上就是锚框的个数
rpn_cls_score = self.rpn_cls(x) # 1x1卷积,锚框的分类
rpn_bbox_pred = self.rpn_reg(x) # 1x1卷积,锚框的回归
return rpn_cls_score, rpn_bbox_pred
这个代码其实和之前 1.2.2 边界框回归部分的网络结构也很像
链接:mmdetection/mmdet/models/dense_heads/rpn_head.py
def _init_layers(self) -> None:
"""Initialize layers of the head."""
if self.num_convs > 1:
rpn_convs = []
for i in range(self.num_convs):
if i == 0:
in_channels = self.in_channels
else:
in_channels = self.feat_channels
rpn_convs.append(ConvModule(in_channels,self.feat_channels,3,padding=1,inplace=False))
self.rpn_conv = nn.Sequential(*rpn_convs)
else:
self.rpn_conv = nn.Conv2d(self.in_channels, self.feat_channels, 3, padding=1)
self.rpn_cls = nn.Conv2d(self.feat_channels,self.num_base_priors * self.cls_out_channels,1)
reg_dim = self.bbox_coder.encode_size
self.rpn_reg = nn.Conv2d(self.feat_channels,self.num_base_priors * reg_dim, 1)
def forward_single(self, x: Tensor) -> Tuple[Tensor, Tensor]:
x = self.rpn_conv(x)
x = F.relu(x)
rpn_cls_score = self.rpn_cls(x)
rpn_bbox_pred = self.rpn_reg(x)
return rpn_cls_score, rpn_bbox_pred
2.2.3 RPN-基于loU的匹配
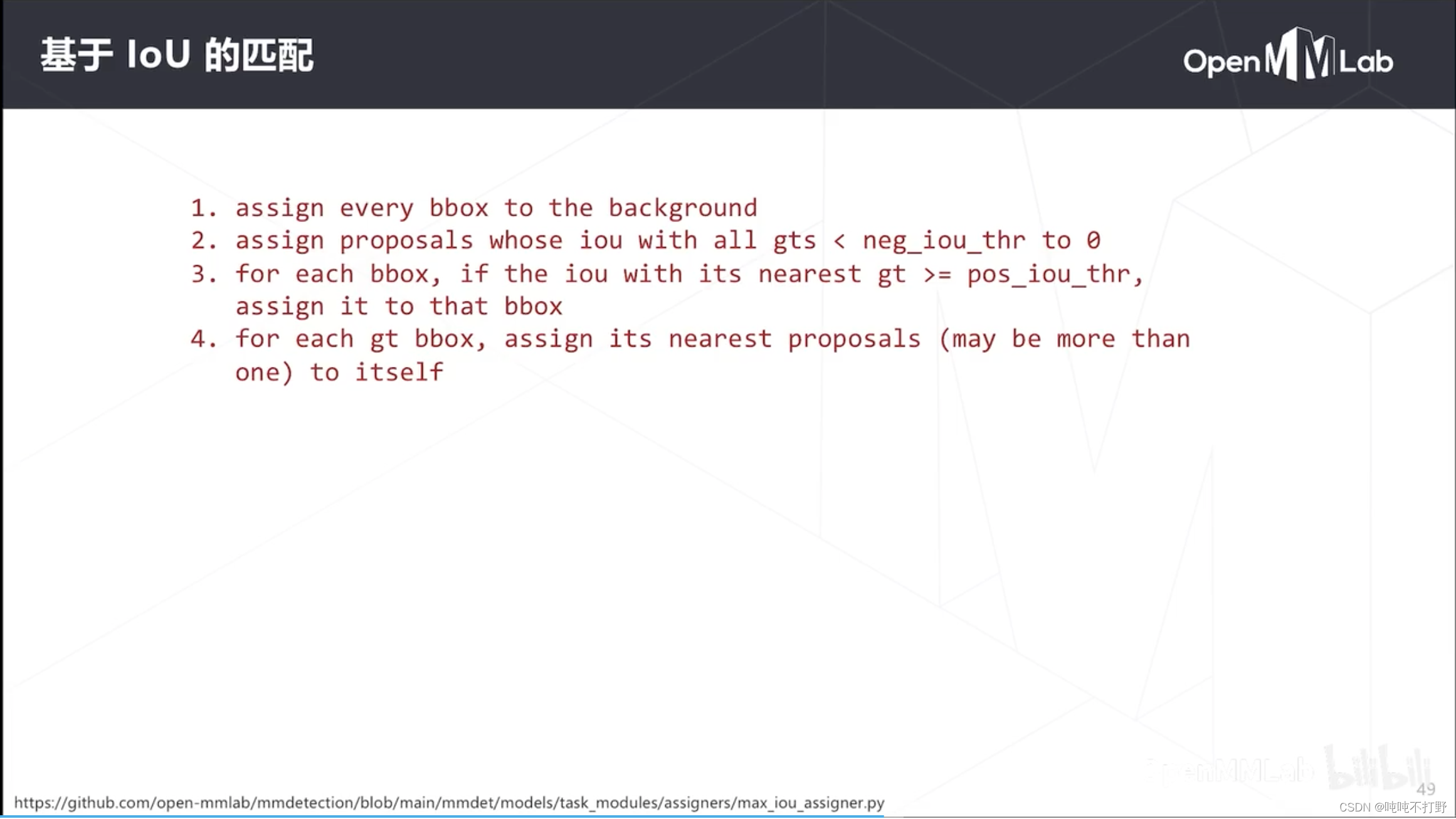
链接:mmdetection/mmdet/models/task_modules/assigners/approx_max_iou_assigner.py
这里的bbox指的就是每个位置的每个Anchor(锚框),每个锚框生成一个分类结果和边界框回归结果。proposal,候选框,其实指的还是bbox(锚框)
这里主要介绍下大致步骤,详情可以去看代码:
- 把所有锚框的类别都设置为背景(初始化,给个默认值,可以认为是类别-1,不是负样本,可以认为一开始是个空值,不属于任何类别)
- 把那些和
所有GT(真值标记框,有物体的框)的iou都小于neg_iou_thr(一般是个很小的值,比如0.3)的候选框设置成0,即这些框被认为是背景。一个框和所有有物体的真值框的重叠程度(交并比)都很小,比如低于0.3,就认为这个候选框是背景。 - 对每个框,如果这个框和离它最近的真值框(GT)的交并比大于某个阈值,那么就把这个GT对应的物体类别分配给这个框。可以在上面的代码链接页面搜索一下
pos_iou_thr,就能看到说明了 - 经过第3步之后,还有一些GT框没有被使用过,直接把这些GT框的类别分配给离他们最近的锚框(可能会有多个)。要保证每个ground truth,
基于稀疏的标注框,为密集预测的结果产生真值,这个过程称为匹配(Assignment)
- 但是这里基于IoU的匹配,是给锚框分配分类真值,一个锚框其实对应密集预测图中的一部分
- 可以结合 1.2.5 如何训练 部分匹配的内容来理解这部分
2.2 YOLO(2005)
2.2.1 Yolo模型
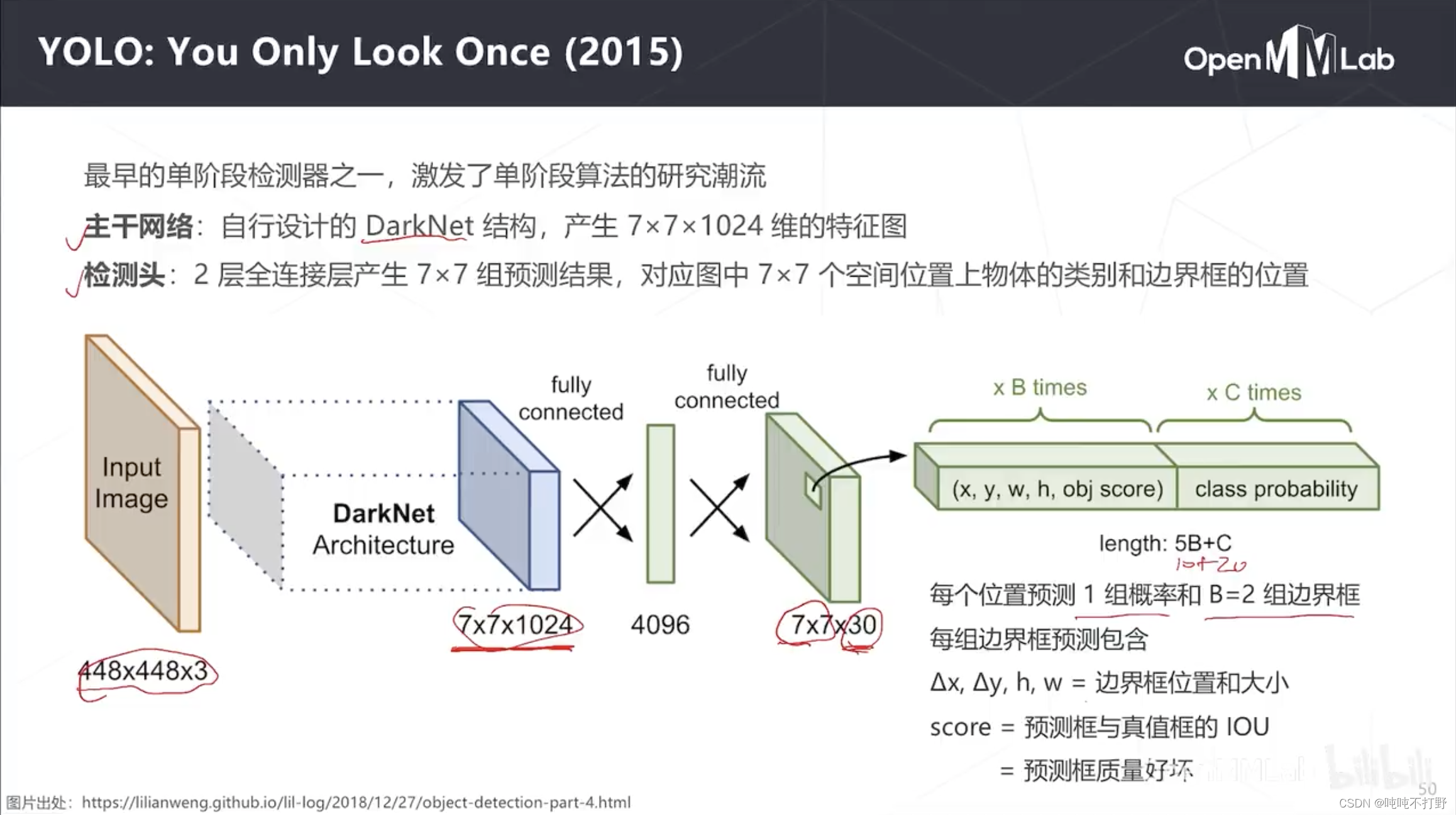
和RPN同年,出现了yolo,
- 图片出处:https://lilianweng.github.io/lil-log/2018/12/27/object-detection-part-4.html,这好像是个大佬,主页很好看,如果要基于github搭建博客,可以参考这个人的
Yolo也是一个单尺度模型,只有主干网络和检测头,没有多尺度模块
- 主干网络是自己设计的19层的DartNet结构, 448 × 448 × 3 448\times448\times3 448×448×3 的输入,卷积后产生 7 × 7 × 1024 7\times7\times1024 7×7×1024的输出
- 预测头是一个两层的全连接层,生成
7
×
7
7\times 7
7×7组预测结果,对应图中
7
×
7
7\times 7
7×7个空间位置上物体的类别和边界框的位置。
- 预测头仍然保持特征图的空间结构(与主干网络输出的特征图空间分辨率一致,都是 7 × 7 7\times 7 7×7),输出是30个通道
- 这30个通道包括:类别C=20(最早用于coco数据集,20分类),两组边界框(包括2个中心点的偏移和边界框的大小,1个Score/置信度(模型额外预测的,训练的时候实际上看的是预测框和真实框的IOU))
2.2.2 Yolo的匹配和框编码
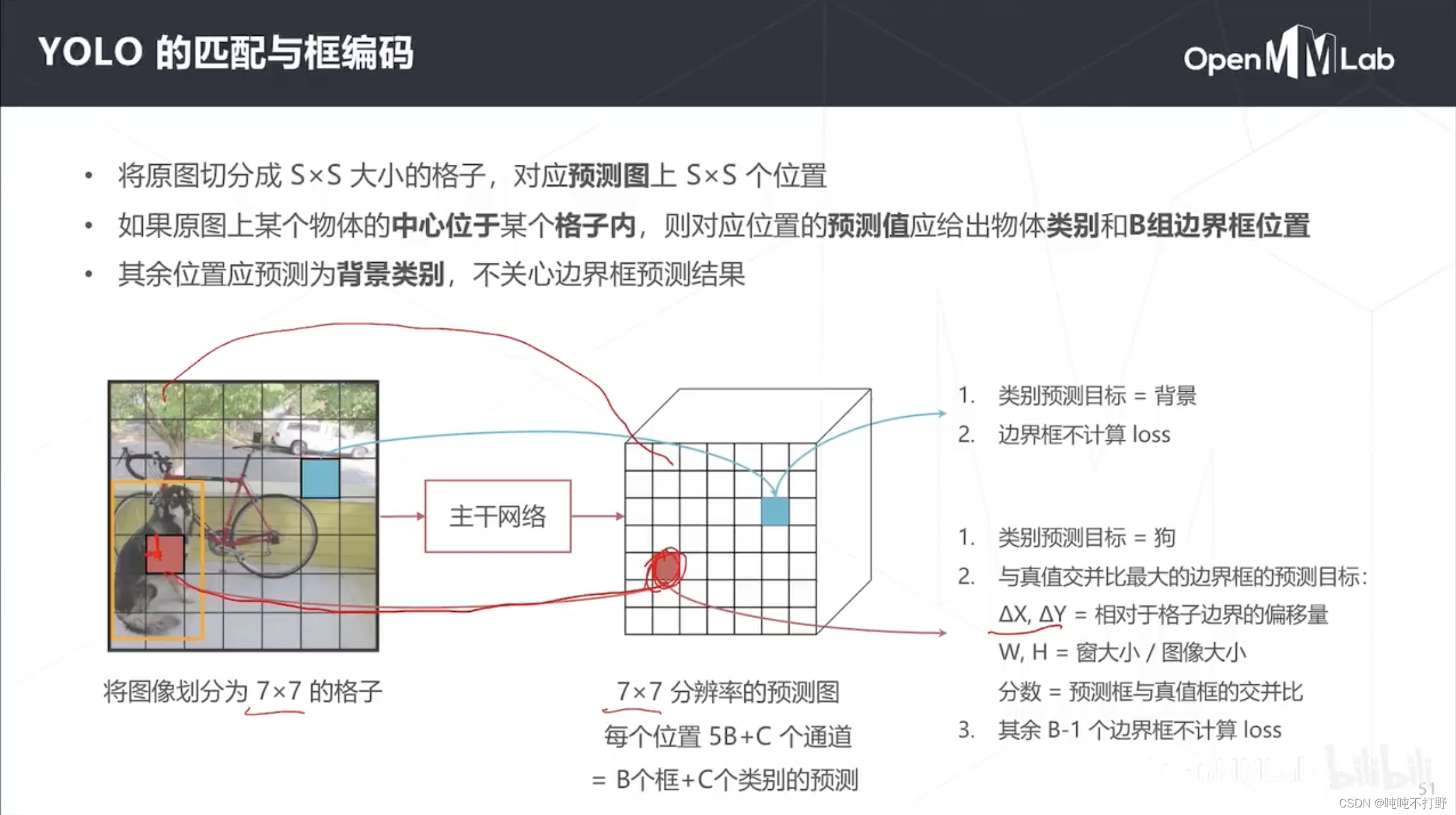
YoLo的匹配和之前说的不太一样,这部分才是理解yolo的关键,
- 整体思路:将输入图像按照模型的输出网格(比如7x7大小)进行划分,划分之后就有很多小cell了。我们再看图片中物体的中心是落在哪个cell里面,落在哪个cell哪个cell就负责预测这个物体
具体而言:
- 预测图是7x7,即预测图中一共可以有49个物体/位置的预测结果,则真值图也是7x7。
- 那么把原图也对应划分成7x7的格子(一般就是均分),但是注意:原图上1个格子≠1个像素,一般是一个小区域。因为原图的7x7和预测图的7x7肯定还是存在一些位置的对应关系(卷积位置不变性)
- 比如上图,狗的中心位于原图的红色格子,则生成密度预测真值时(匹配),
- 就认为密度预测真值图对应的位置的红色格子的类别就是狗,
- 同时该物体的标准框也就是对应的真值图上该位置的边界框真值(用偏移量来算, △ X , △ Y \vartriangle X, \vartriangle Y △X,△Y指是狗的中心到红色格子的边缘的偏移量;W和H指的是黄色那个窗相对于整个图像的比例)
- score就是交并比
- 为了可以预测准一点,一般特征图上每一个cell都对应两组(B组)边界框的预测,不过算loss的时候,只算和真值框IoU最大的那个预测框,剩下的是不计算loss的
- B组边界框其实是为了预测不同大小的物体而设置的,同时背景的边界框也是不参与loss计算的
参考:
- 可以看看你真的读懂yolo了吗?,这个人也是个大佬,可以看看他的其他东西。
- 也可以看看这个ppt,很清晰: YOLO
2.2.3 Yolo的损失函数

这里的损失函数都是示性函数,想打出这个符号需要latex支持,CSDN的katex不怎么支持,详见:How do you get \mathbb{1} to work (characteristic function of a set)?
- 第一部分:表示有物体的位置,才去计算边界框loss(没有物体的位置,只计算分类损失),分别是中心和长宽计算(很少看到平方差了,基本都是cross entropy)
- 第二部分:置信度回归损失,也是平方差loss
示性函数概念:
- 百度百科-示性函数
- stackexchange:YOLO v2 loss function,在这里面搜索
indicator functions - stackexchange:How to read out the loss function in YOLO algorithm?,在这里面搜索
indicator functions
2.2.4 YOLO的优点和缺点
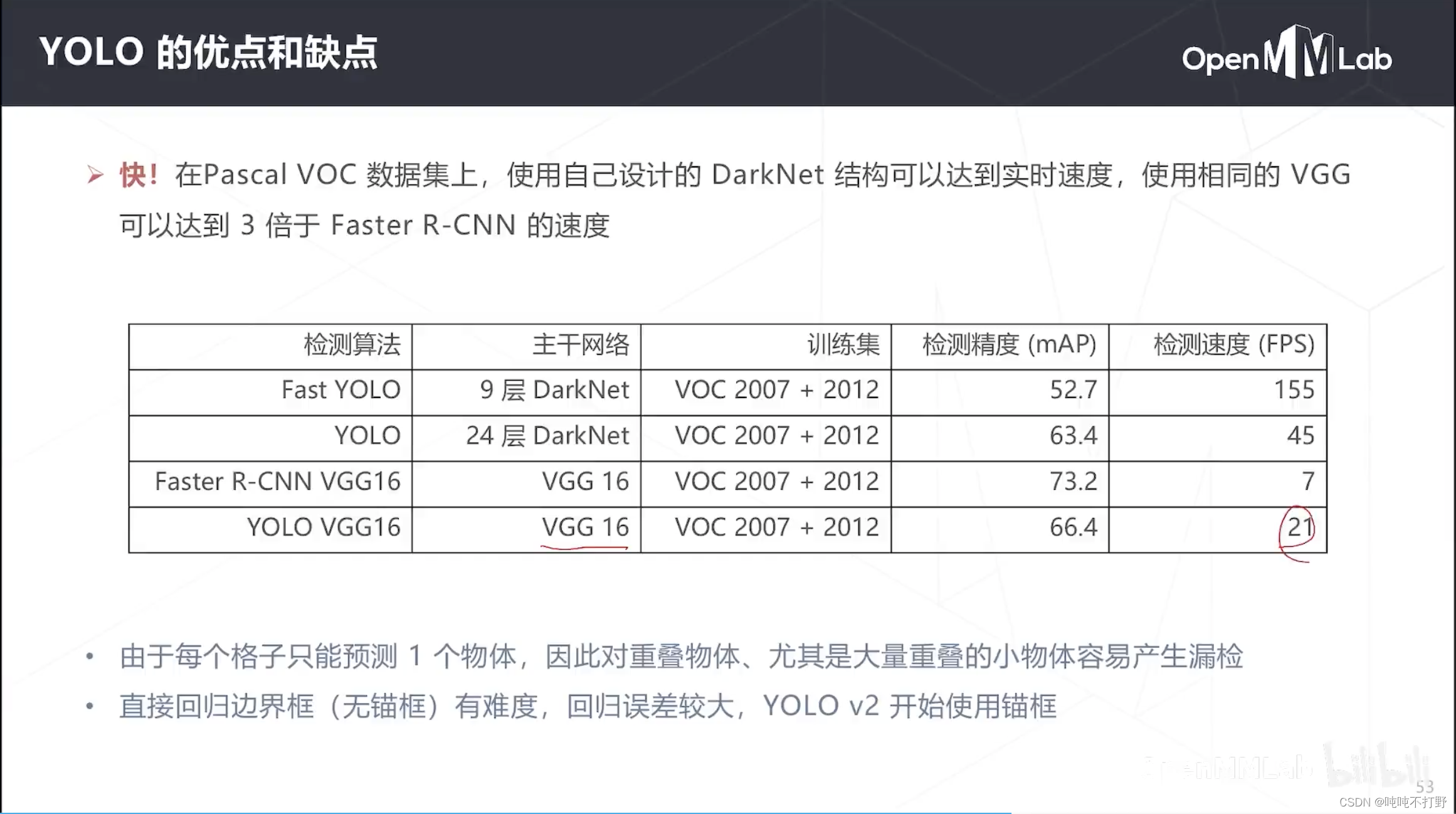
- 优点就是快,最初版本的yolo已经基本可以达到实时的速度了,如果使用原始的9层DarkNet,速度非常宽,即便是VGG的YOLO,也有21FPS(每秒21帧)
- 缺点就是因为是对原图做比较粗糙的划分格子,所以对于重叠物体,无法一个cell检测两个类别
2.3 SSD(2016)
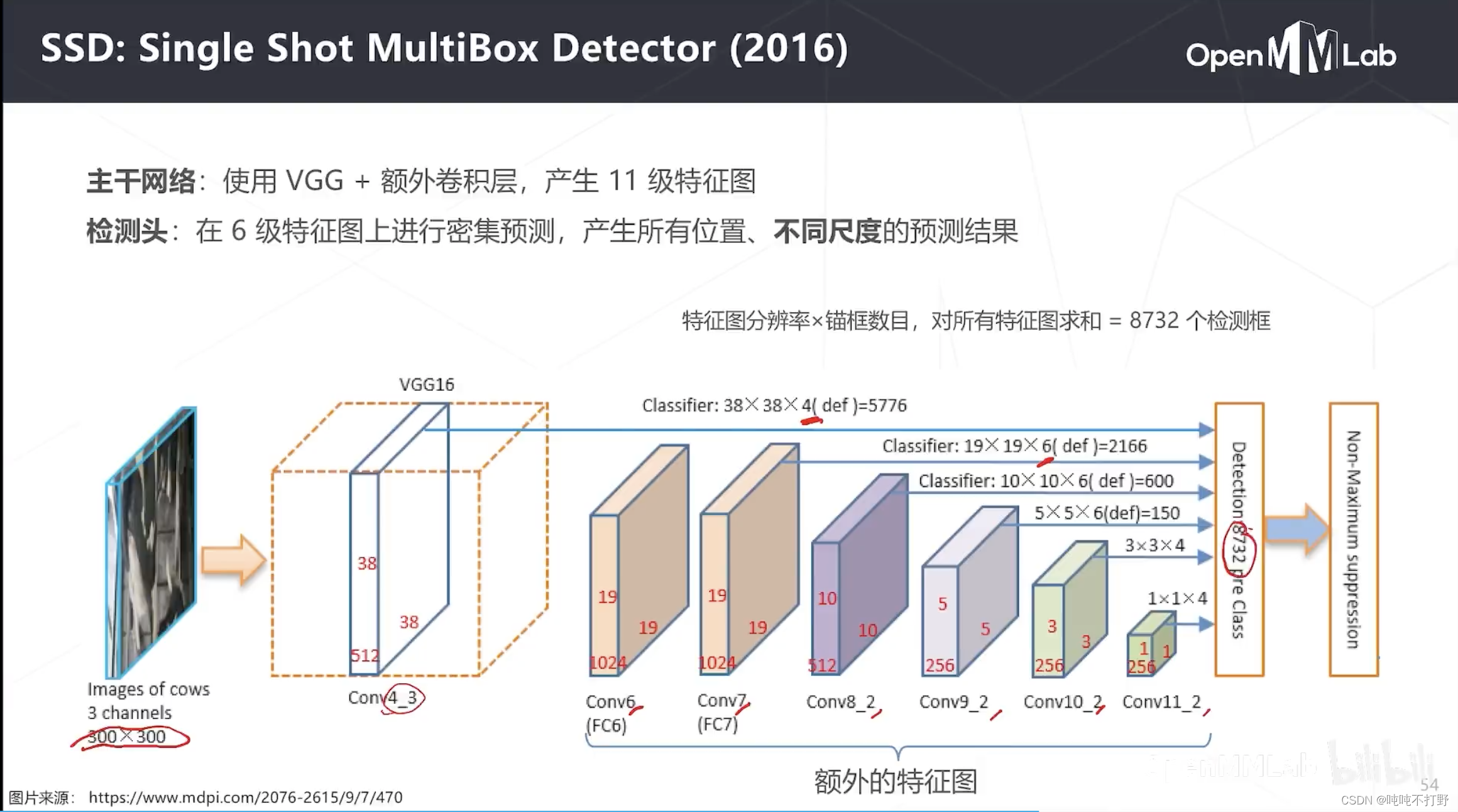
上面介绍的RPN和YOLO都是基于单级特征图进行检测的(都是只使用了主干网络的最后一层的特征图),SSD是第一个尝试使用多级特征图去检测的模型
- 使用了VGG的Conv4_3(VGG第四阶段的第三个特征图)+一些额外的卷积层产生的特征图
- 基于每个特征图进行密集预测,不同特征图的锚框数量不同,比如:VGG的那个特征图是4个锚框,Conv7是6个锚框…
- 最终在300x300的图像上,一共产生了有大有小的8732个锚框
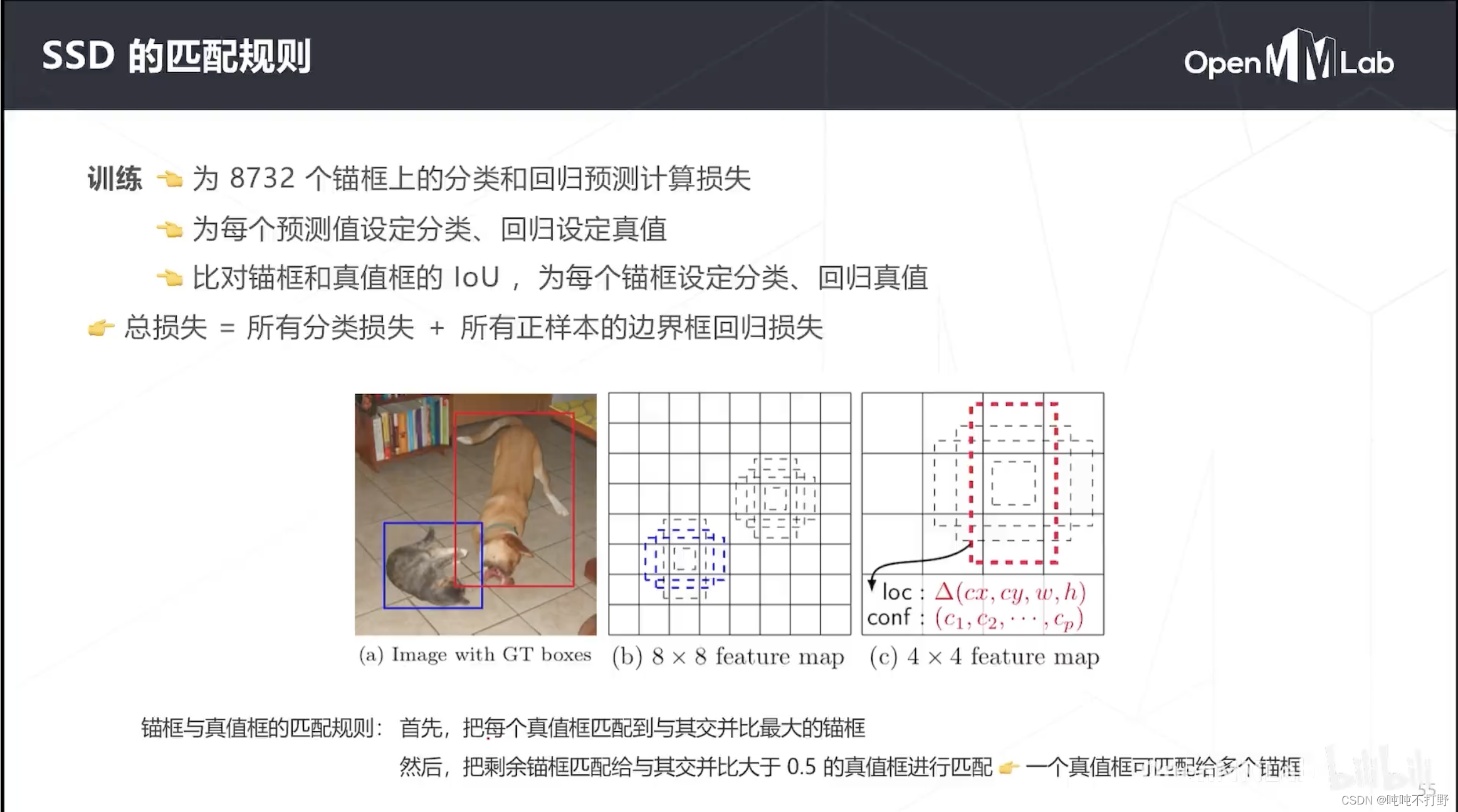
为了给上面那8000多个锚框生成真值,SSD也采用了基于IOU的匹配规则。
- 首先,把每个真值框匹配到与其交并比最大的锚框
- 把剩余锚框匹配给与其交并比大于0.5的真值框进行匹配,一个真值框可以匹配给多个锚框。这样做也是为了增加正样本的个数,来抗衡训练中大量的负样本(背景样本)
2.4 Focal Loss与RetinaNet(2017)
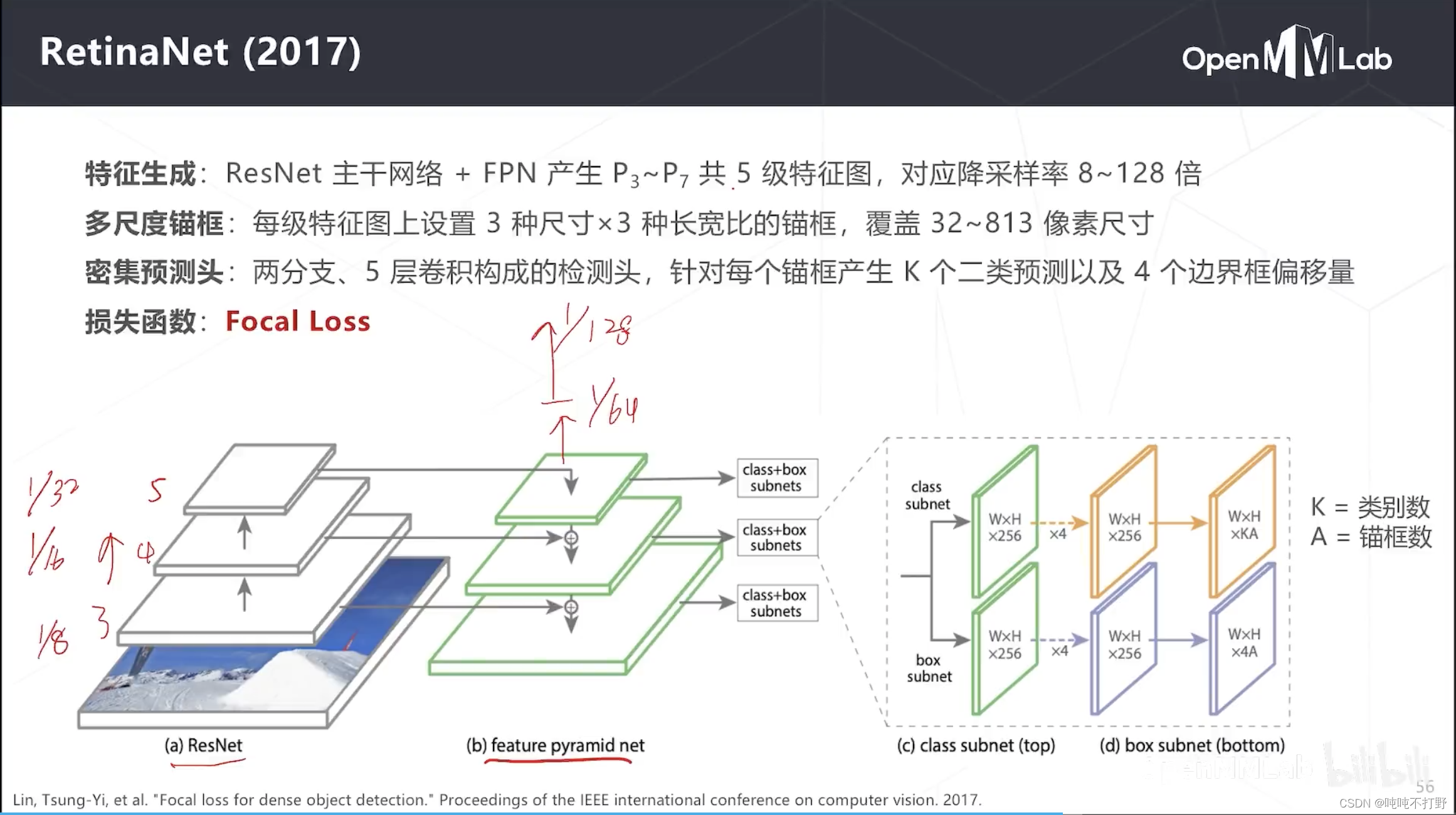
从RetinaNet开始,FPN(特征金字塔)就成为了检测算法的一个主要模块。其主要结构:
- Resnet主干网络,实际上只用了Resnet的3-5层,每层的特征图是原图的 1 / 8 1/8 1/8, 1 / 16 1/16 1/16, 1 / 32 1/32 1/32。
- Neck使用FPN进行多尺度检测,除了画出来的这三层,其实上面还有额外进行降采样的两层,分别是
1
/
64
1/64
1/64和
1
/
128
1/128
1/128,可以用来检测特别大的物体。
- 所以一共有5级特征图,对应降采样率是8~128倍。
- 每级特征图设置3种尺寸x3种长宽比的锚框,覆盖32~813像素尺寸。
- 5层卷积构成检测头(密集预测头),分成了两支,分别检测类别和边界框,
- 在类别分支,WxH就是空间分辨率,K是类别数,A是锚框;在box分支,4A(就是为每个锚框预测4个偏移量)
- 即为每个位置的每个锚框产生K个类别预测和4个box偏移量预测
- 提出了FocalLoss去计算分类损失,主要解决类别不平衡问题
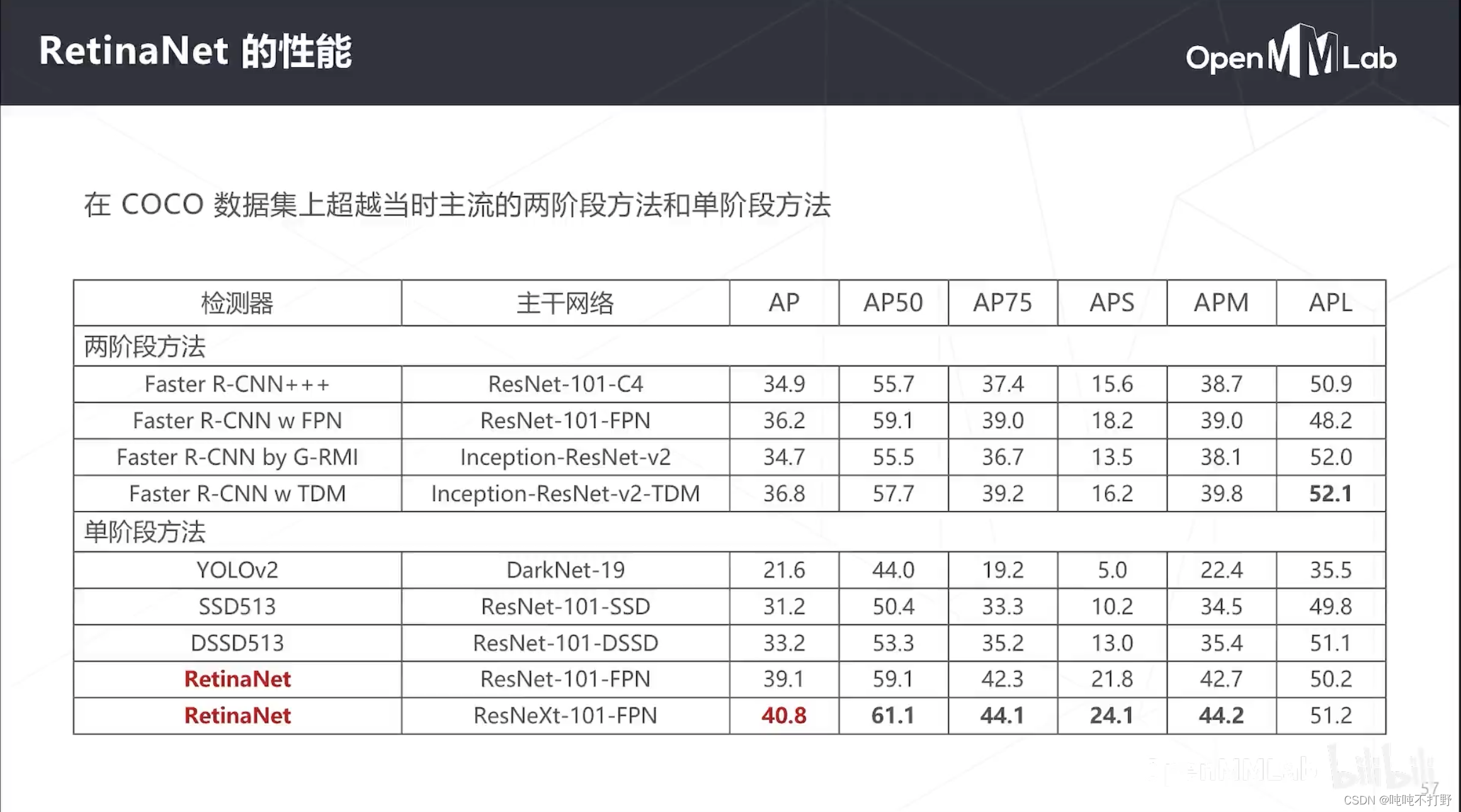
RetinaNet当时出现也是引起了轰动,在COCO数据集上,单阶段超越当时最先进的两阶段Faster R-CNN。
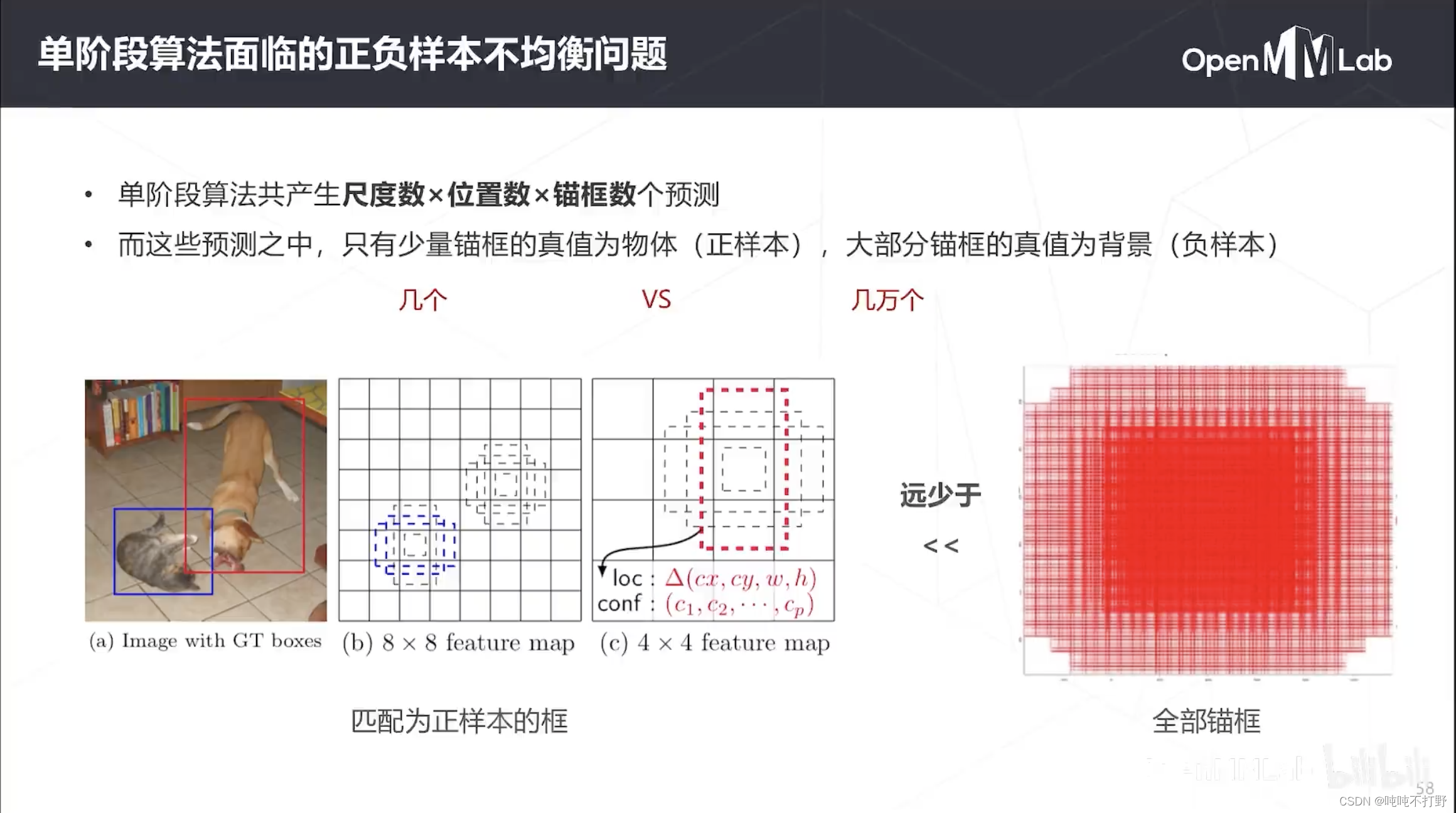
当时单阶段算法面临的一个巨大的问题就是:正负样本不均衡问题
以SSD的图为例:
- 原图的ground truth是非常稀疏的(需要检测的有物体的框很少),比如上图只有两个(猫和狗)
- 即便可以把正样本匹配到多个锚框上,那也就只有几个锚框(正样本);而我们生成的锚框可能有成千上万个(SSD生成的锚框数量是8000多个),也就是除了那几个之外,都是负样本(背景)

- 则在分类时,由于负样本数量过多,导致计算loss时,背景类占据了主导,导致模型偏向背景预测。
- 即朴素(原始)的分类不损,不能保证检测器在有限的能力下,达到漏检和错检之间的平衡
- 模型把所有框都预测成背景,正确率依然很高,所以直接错检也没啥
- 即原始的这种分类损失和目标检测的目标并不匹配,目标检测更想要检测的是样本稀少的正样本,而不是均等的检测每个类
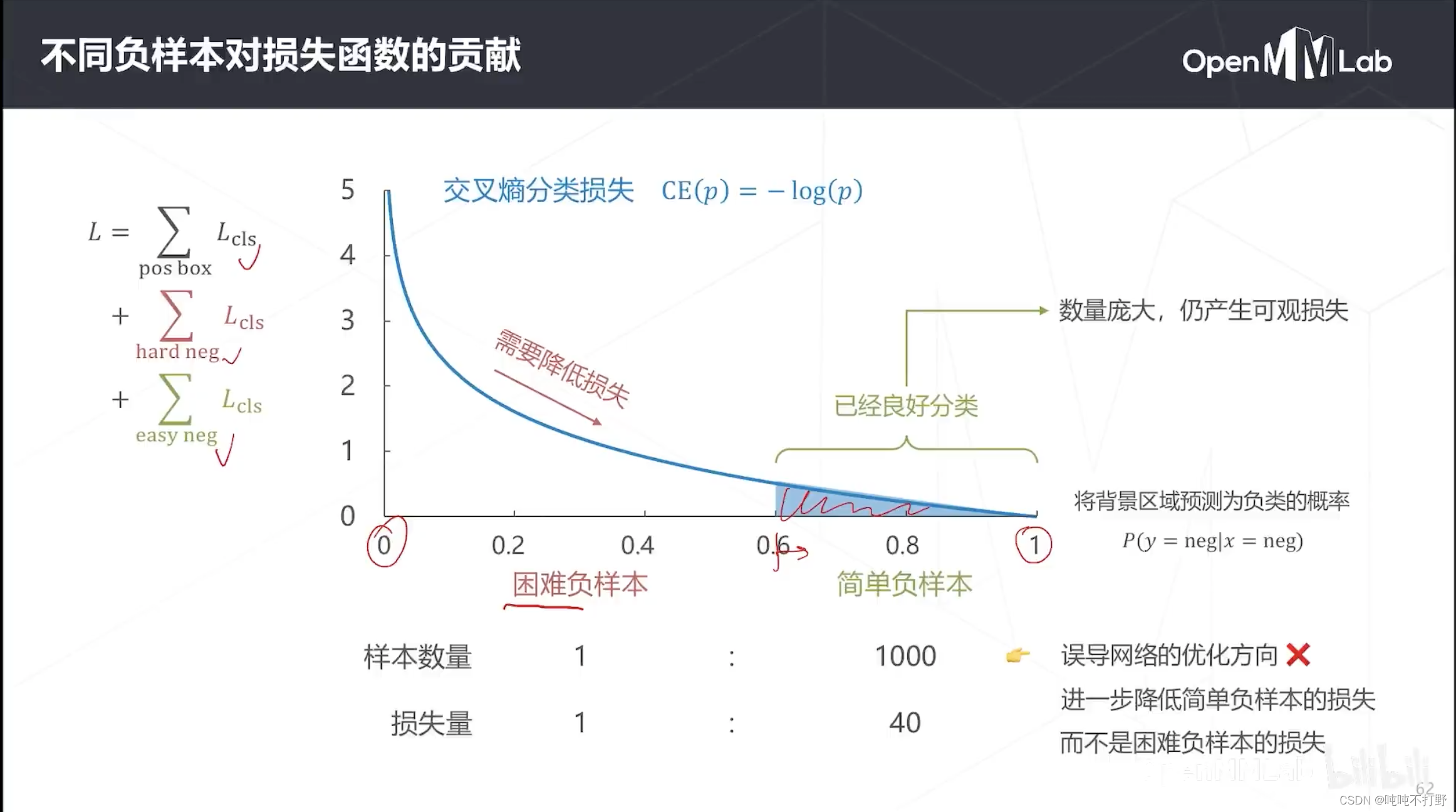
FocalLoss一开始就分析了一下损失函数的组成部分,
- 正样本框的损失
- 难负样本的损失(GT是负样本(背景),但是不好分的那种锚框)
- 简单负样本(容易分的负样本)
由于负样本占大多数,所以先分析负样本的损失,
- 上图是交叉熵损失的曲线,横轴是模型把背景预测为负样本的概率,纵轴是损失
- 理想情况下,希望背景预测为负样本的概率为1,此时负样本的损失就是0,对应上图最右边曲线和x轴的交点
- 如果模型完全预测错误,即把背景预测成负样本的概率为0,那么此时损失就是无穷大
- 但是模型不会那么准确,能得到把背景预测成负样本的概率是1,但是即便预测概率在0.6以上,图上可以看到多多少少也都还是有些损失。
- 但是实际上,预测概率在0.6以上其实就够了,不是非要让模型预测成1才可以,这部分其实已经没必要参与loss的计算了
- 对那些困难负样本,正确预测为负样本的概率就比较低,损失就会比较大,所以需要优化的这些困难负样本的概率。
但是实际上,简单负样本反倒是负样本中比例非常大的部分,虽然每个都只产生了一点点损失,但是其实它们才是负样本损失贡献最大的部分。
- 导致模型优化的时候主要去进一步降低简单负样本的损失,而不是困难负样本的损失(以及正样本的损失)
- 优化方向错误
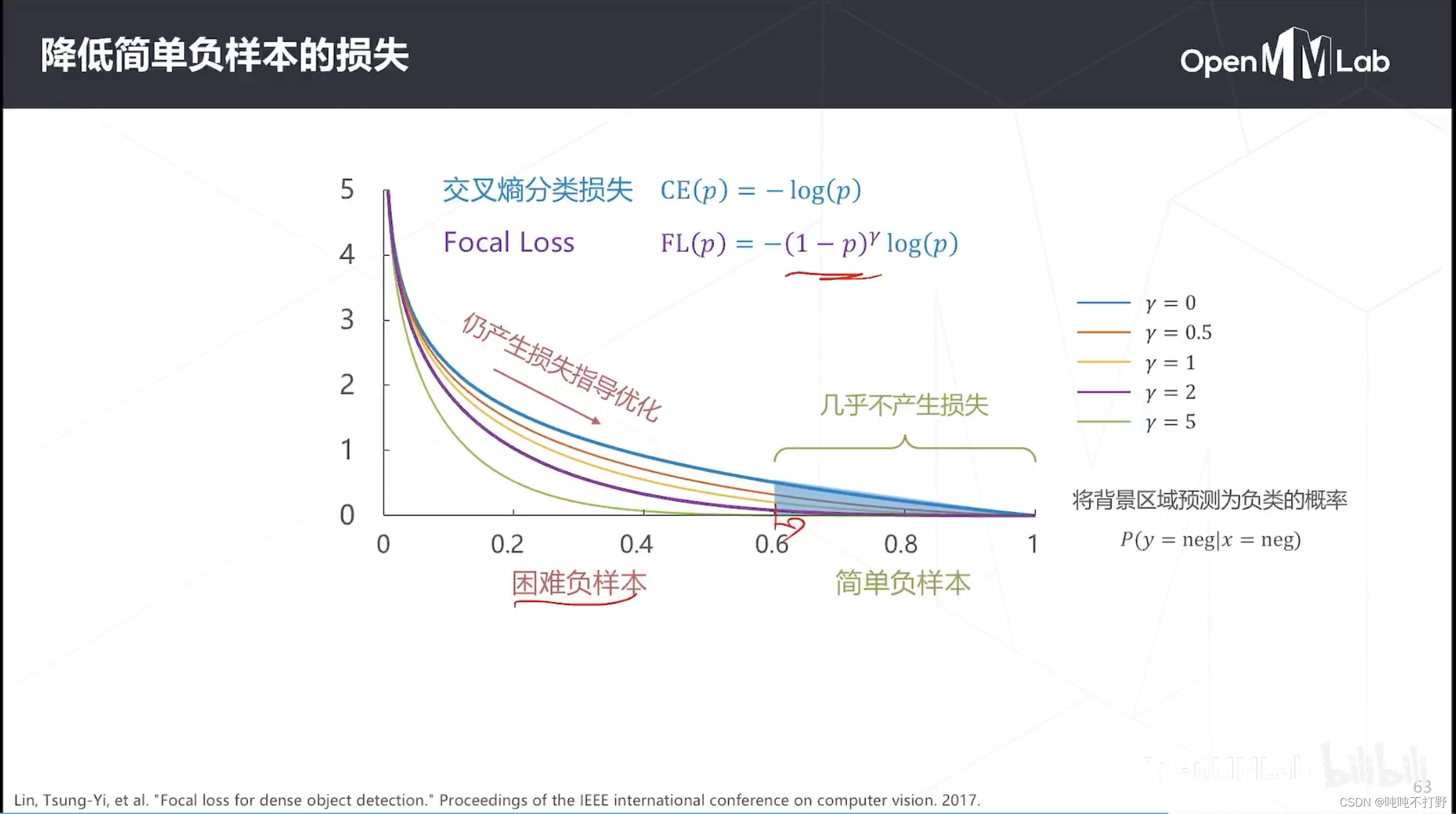
FocalLoss就是在这个观察的基础上诞生的,
- 主要就是在交叉熵损失函数前面加了一个系数,降低了简单负样本的损失,
- 比如设定参数 γ \gamma γ(是一个可调的参数),让预测背景为负样本的概率是0.6以上的基本就没有loss了,大大降低简单负样本在loss中的占比。
- 让困难负样本和少量正样本的误差成为loss中的主导,纠正模型的优化方向
不同的 γ \gamma γ会有不同的结果:
- γ = 0 \gamma=0 γ=0,FocalLoss退化成CE(cross entropy)
- γ \gamma γ越大,对简单负样本的损失的抑制越强
- 通常 γ = 2 \gamma=2 γ=2是一个经验性的比较好的结果

- 完整的FocalLoss其实还有个系数,调节的事正负样本的比例。
- 论文里给出的实验结论是: γ = 2 , α = 0.25 \gamma=2, \alpha=0.25 γ=2,α=0.25时会产生最好的实验结果。
2.5 YOLO系列选讲
2.5.1 YOLOv3(2018)
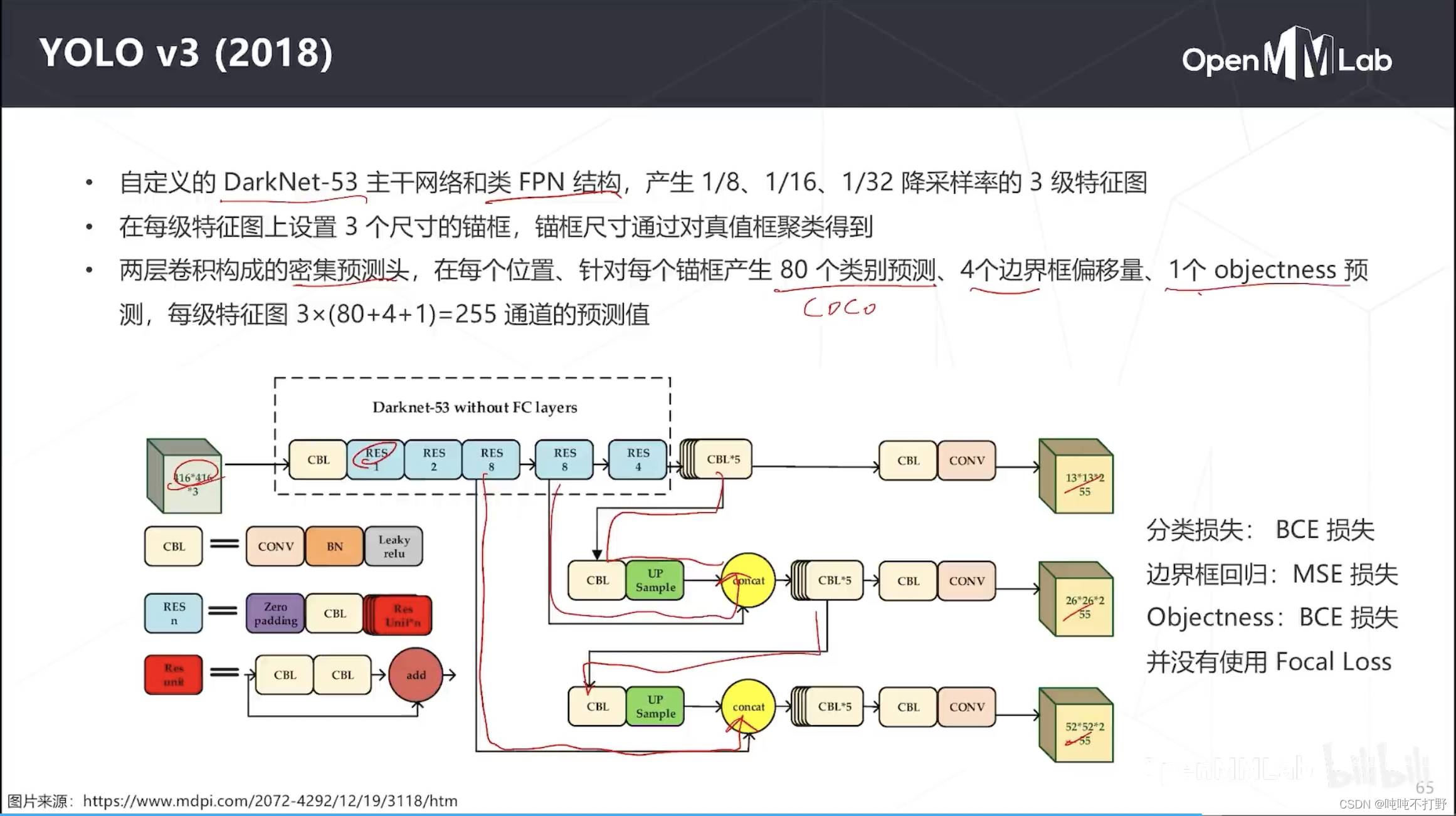
在RetinaNet和FocalLoss出现之后,单阶段有了希望。YOLOv3集百家之所长,出现了
- 主干网络,DarkNet变成了53层,加入了ResNet模块,还加入了类FPN(特征金字塔网络)结构,CBL+上采样+concat,有特征融合(高层CBL经过上采样与低层RES8融合),这里是3级特征图(13x13, 26x26, 52x52),相对于原图降采样率就是32、16和8。RetinaNet是5级
- head密集预测头,两层卷积组成(CBL+CONV),每个位置三个锚框,coco数据集那时候是80个类别,所以每级特征图对应位置要产生3x(80+4+1)=255个通道的预测值
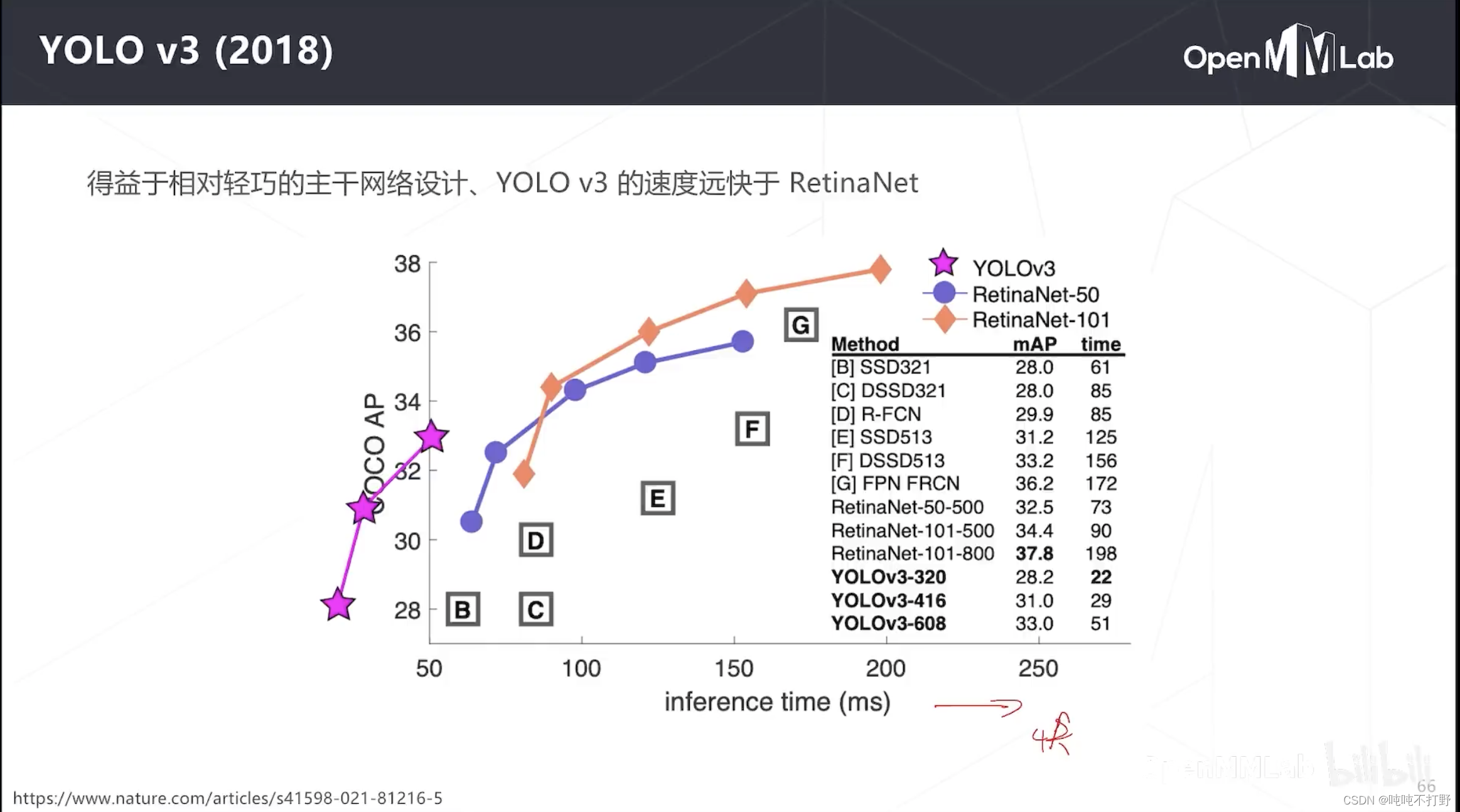
YOLO就是快啊,画条横线,同等精度下,YOLO最快
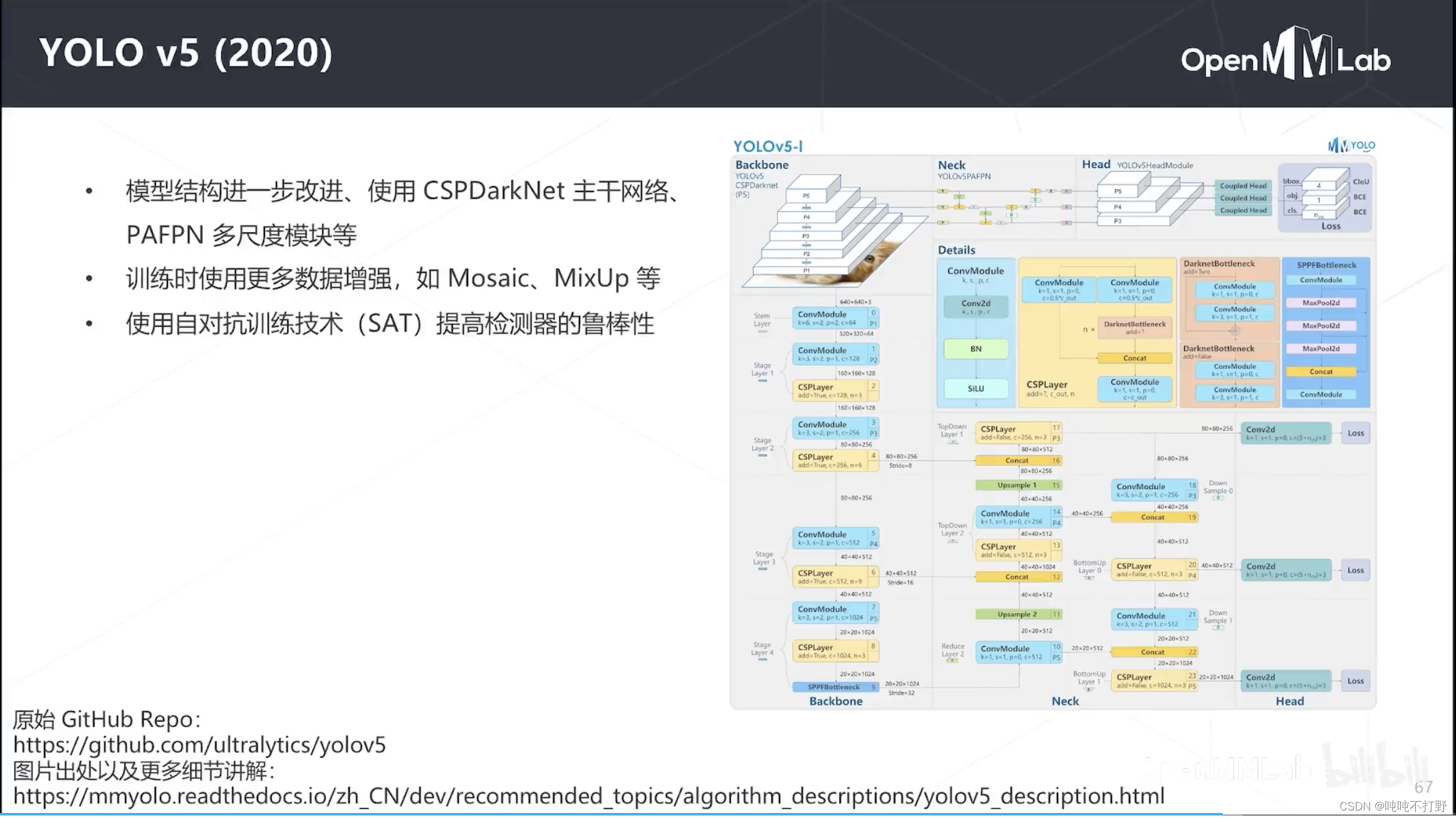
2.5.2 YOLOv5(2020)
2.6 无锚框检测算法
2.6.1 重叠问题

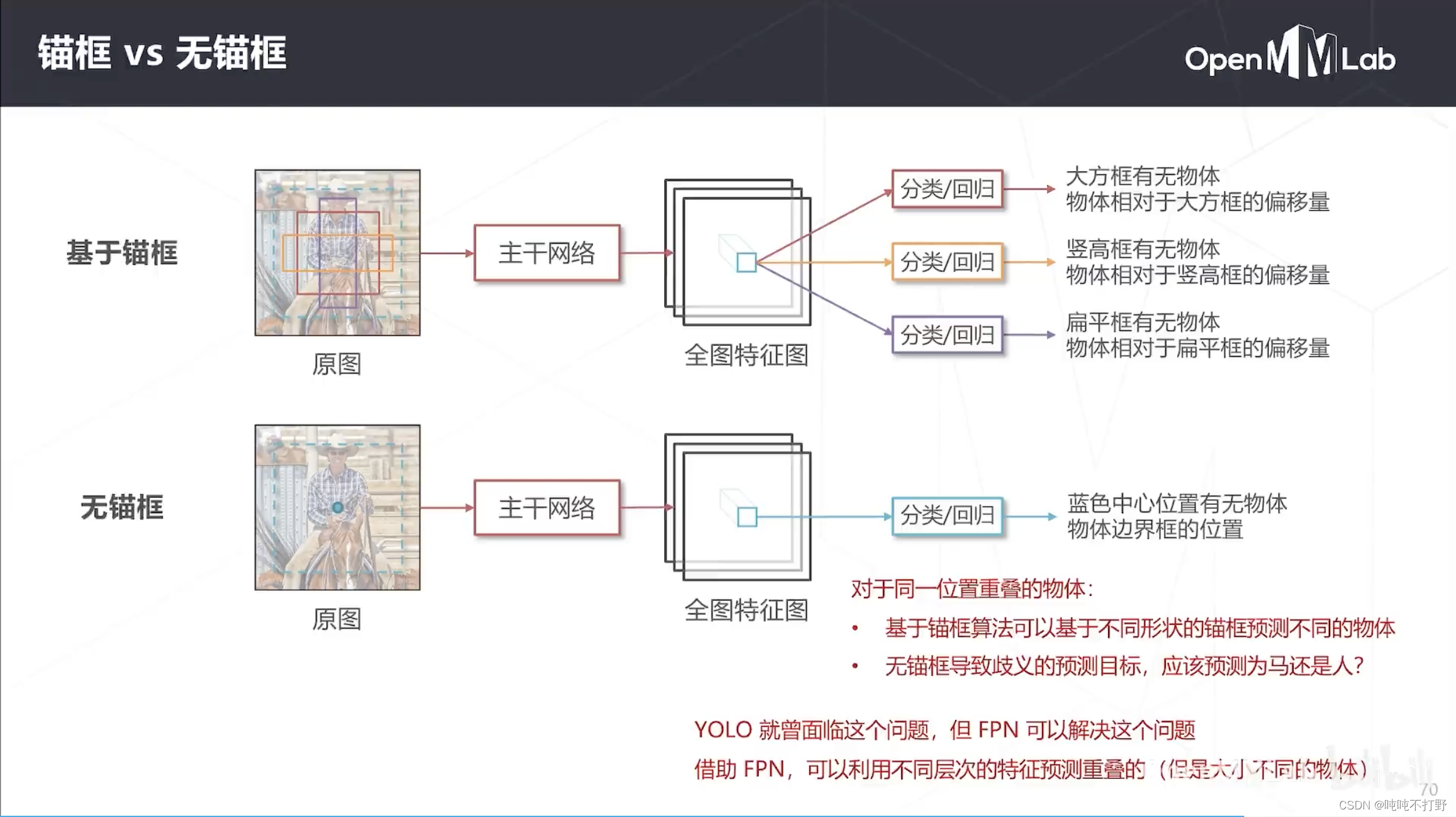
YoLo就是无锚框的,所以以前无法解决重叠物体,但是FPN可以解决问题。
朴素的想法:同一个位置重合的物体,如果大小有所不同的话,实际可以由不同级别的特征图来进行预测的。
2.6.2 FCOS(2019)
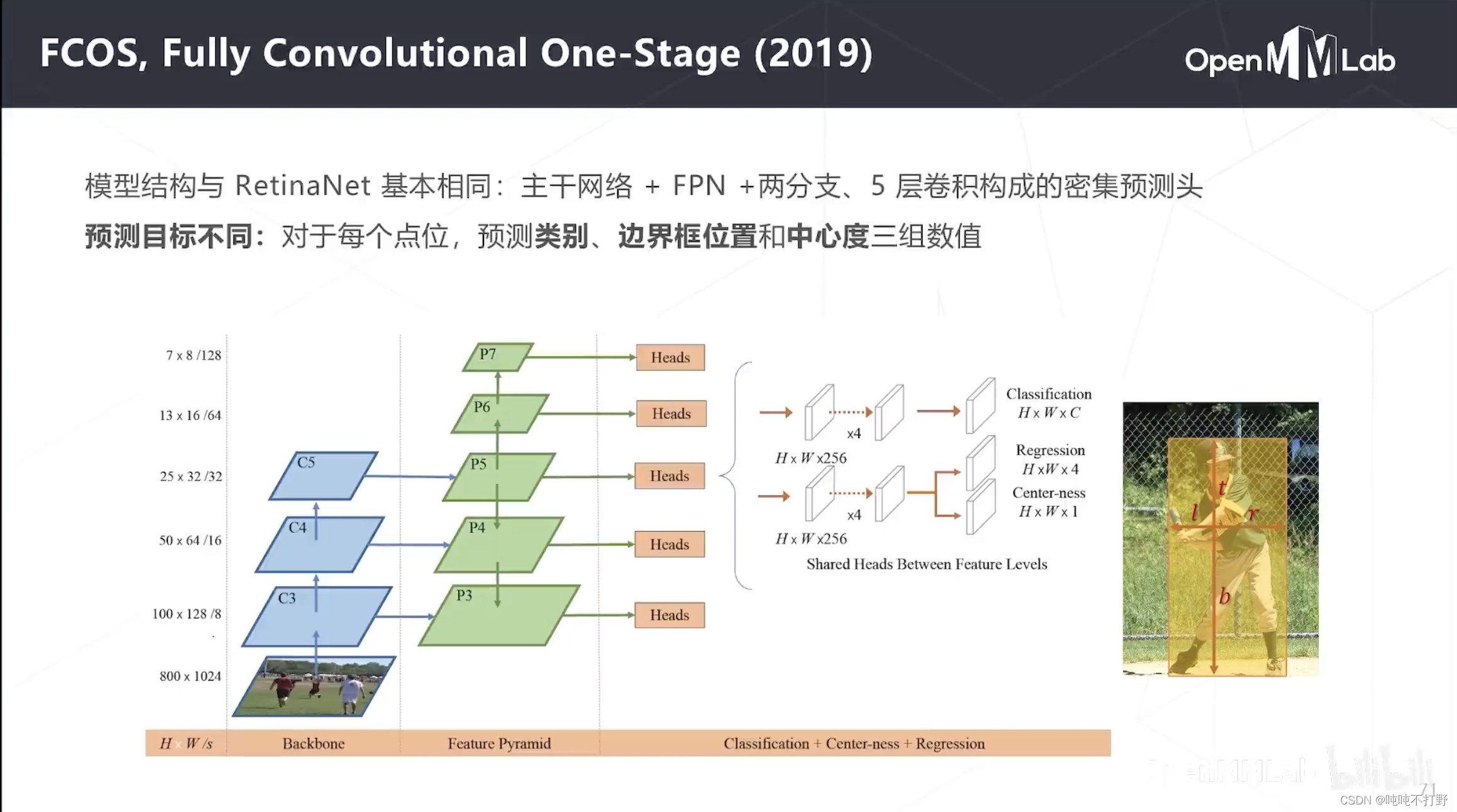
- FCOS就是基于:同一个位置重合的物体,如果大小有所不同的话,实际可以由不同级别的特征图来进行预测的。 这一想法来实现的。
- 模型结构和RetinaNet大致相同,8~128倍降采样率,有多个密集检测头,可以进行多尺度物体的检测
- 区别在于FCOS是无锚框的,所以预测目标和RetinaNet就会有所不同
- 分类是差不多的,
- 主要是边界框,之前RetinaNet是真实位置相对于锚框的偏移量;现在FCOS是物体上下左右边界相对于中心的偏移量,centerness和yolo里框的质量/置信度差不多是一个作用,评判当前这个中心点是不是在物体最中心的位置,在中心,值就是1,在边上,值就是0

为了适应无锚框的算法,FCOS提出了一种新的匹配规则(生成密集预测真值图的方式)
相对于之前的锚框基于IOU的匹配,FCOS的匹配会生成更多的正样本,正样本多一点,对训练来说,是好事。
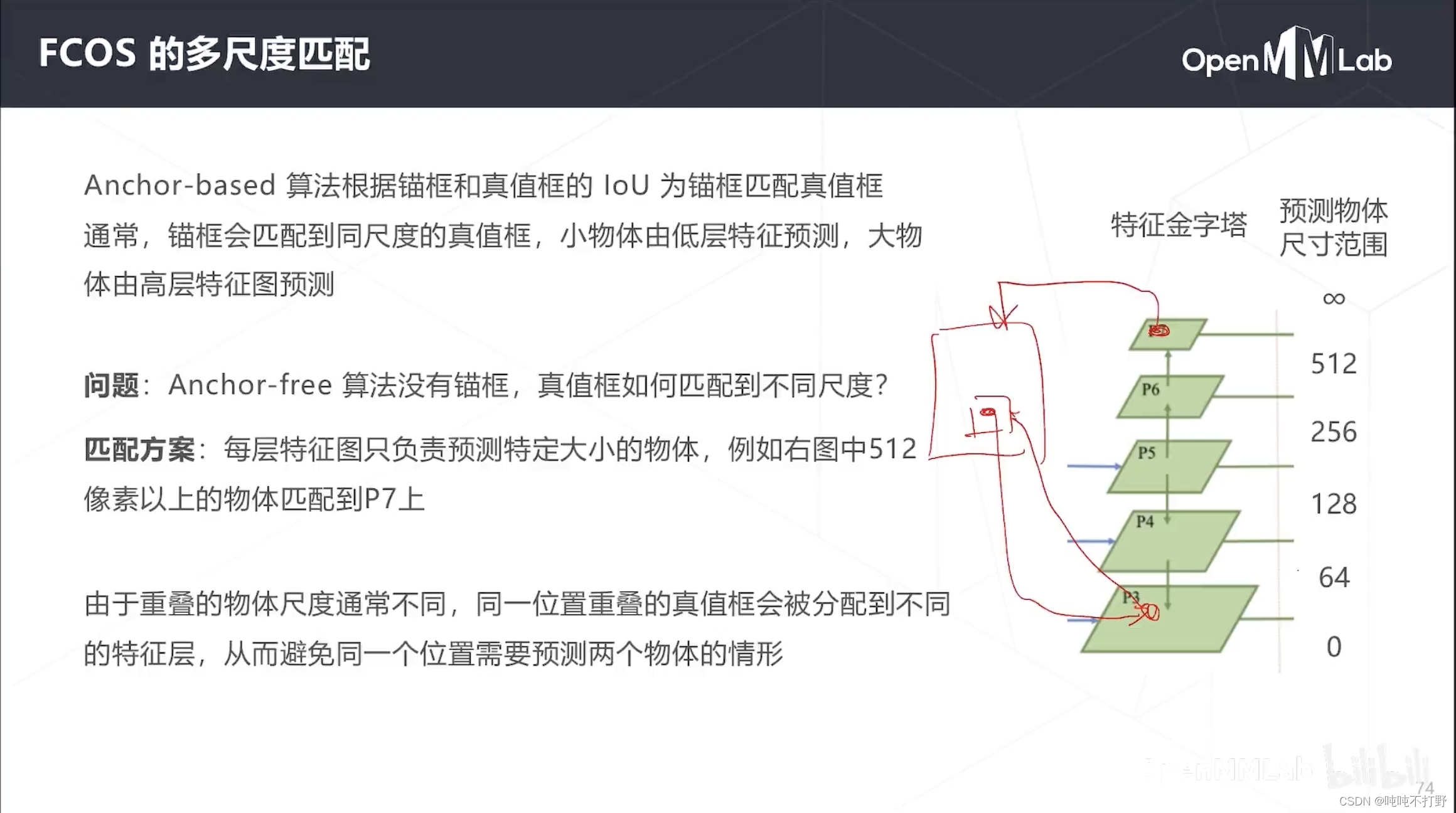
- 重叠的物体一般不会一模一样大,一模一样肯定就有个看不见的,看不见的就没必要预测了
- 假设有个位置,有1大1小两个预测框,怎么去判断取哪个?
- 如果这个位置对应的特征图是P3,那么就预测小物体
- 对应的是高层特征图,就预测大物体。
- 即:锚框匹配同尺度的真值框(同级别)
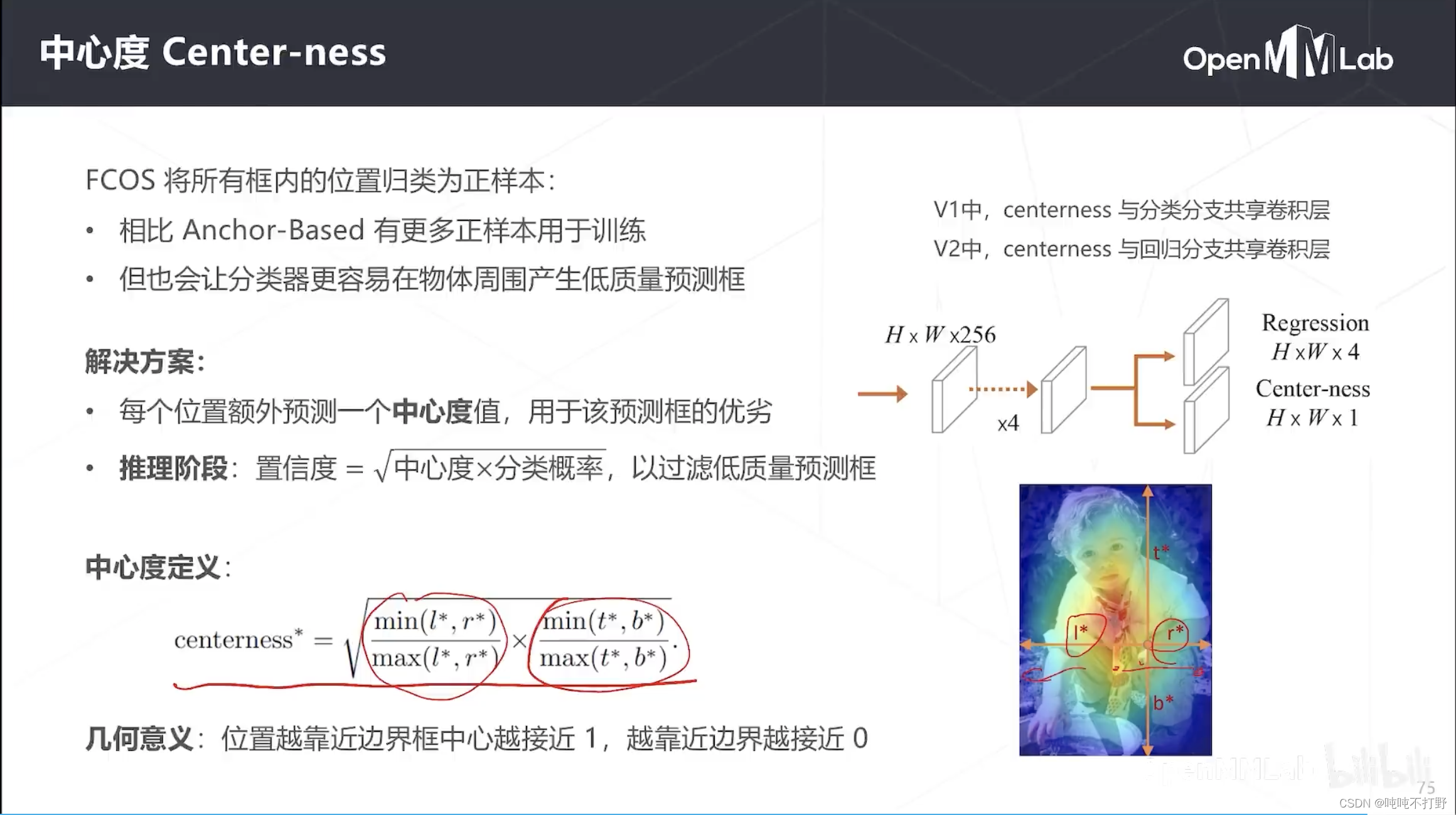
- 中心度定义:是横竖两个方向中心度的几何平均值, l ∗ , r ∗ l^*, r^* l∗,r∗分别表示中心点到左侧边界和右侧边界的距离

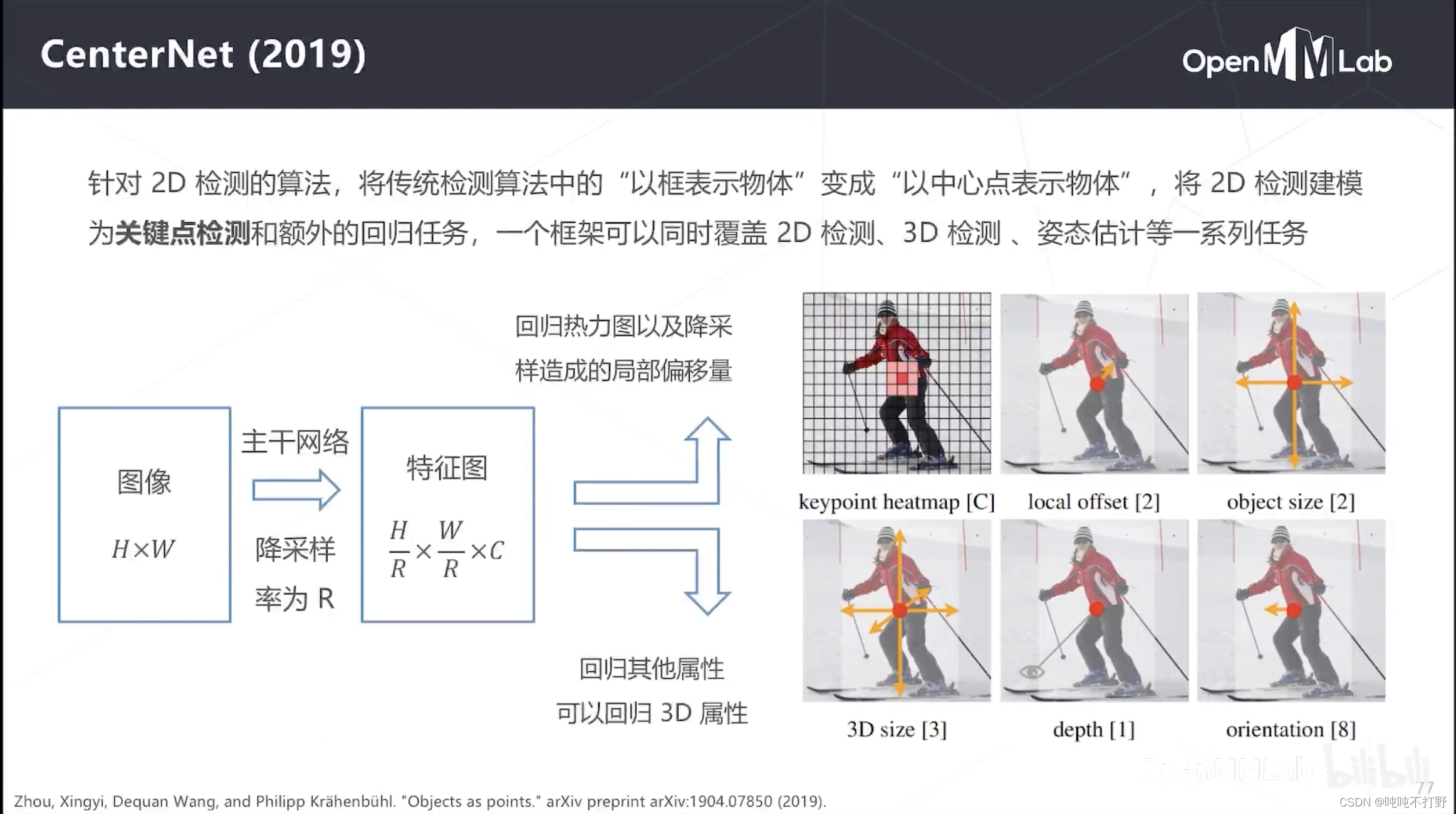
2.6.3 CenterNet(2019)
2.6.4 YOLOX(2021)
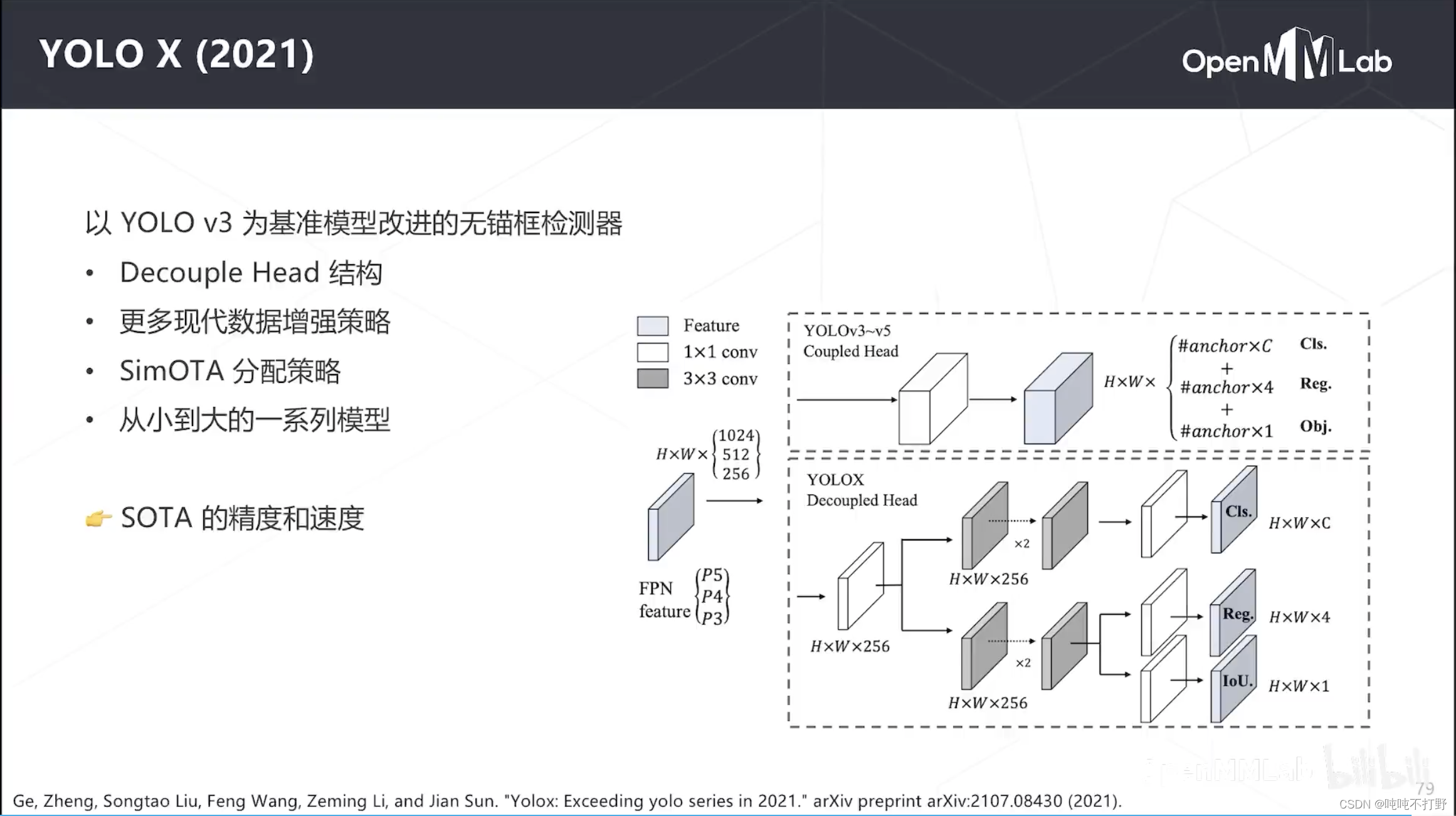
和同期的YOLOv5在精度和速度上都是差不多的
2.6.5 YOLO v8
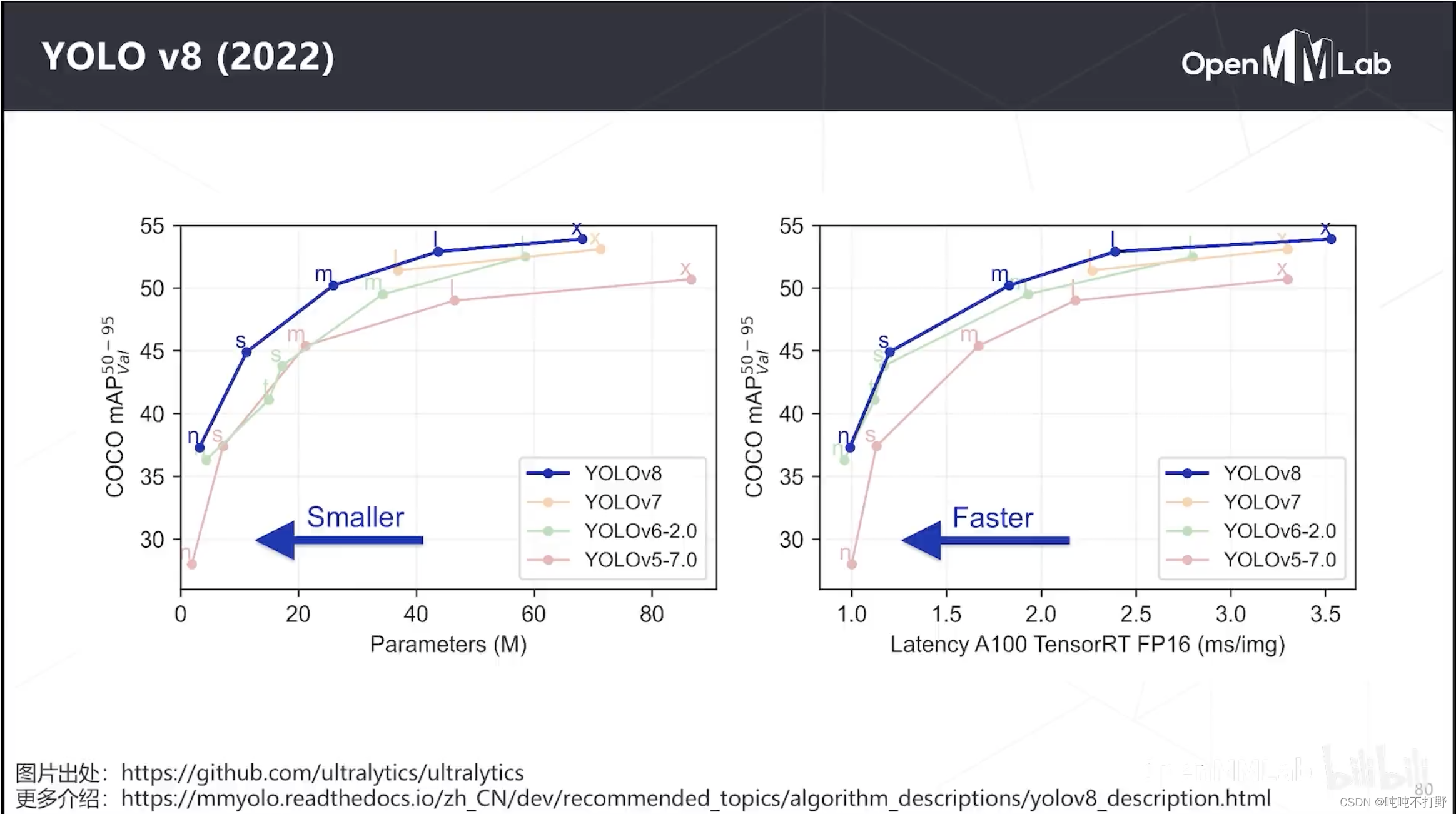
把YOLO系列上了一个新台阶
2.7 总结





![[ruby on rails] passenger+nginx 部署rails](https://img-blog.csdnimg.cn/955ea138599c4145897de8c17df6c6ab.png)