个人名片:
🐅作者简介:一名大二在校生,热爱生活,爱好敲码!
\ 💅个人主页 🥇:holy-wangle
➡系列内容: 🖼️ tkinter前端窗口界面创建与优化
🖼️ Java实现ATP小系统
✨个性签名: 🍭不积跬步,无以至千里;不积小流,无以成江海
好久没写文章了,今天把之前参加认证杯第一阶段的比赛经历分享一下!这次我和我的小组是获得了一等奖,差几分就获得特等奖了,很遗憾哈!只能后续再继续努力了!

认证杯的比赛流程:
比赛时间只有三天,在三天内你必须选择一个课题(A/B/C),完成对应的论文,然后提交。
我们选择的C题,题目如下:

后面还有一个问题,不在同一页就没有截图了。需要题目,或者数据可以私聊我哦!
问题分析
问题的研究对象是正常与不正常的心搏,研究的内容为其中心电波形功率谱密度的变化情况。该问题描述了心律失常时不同心搏的类别变化特点,并在不同的异常心率搏动下提出了分类排序的要求:
2.1对问题1的分析
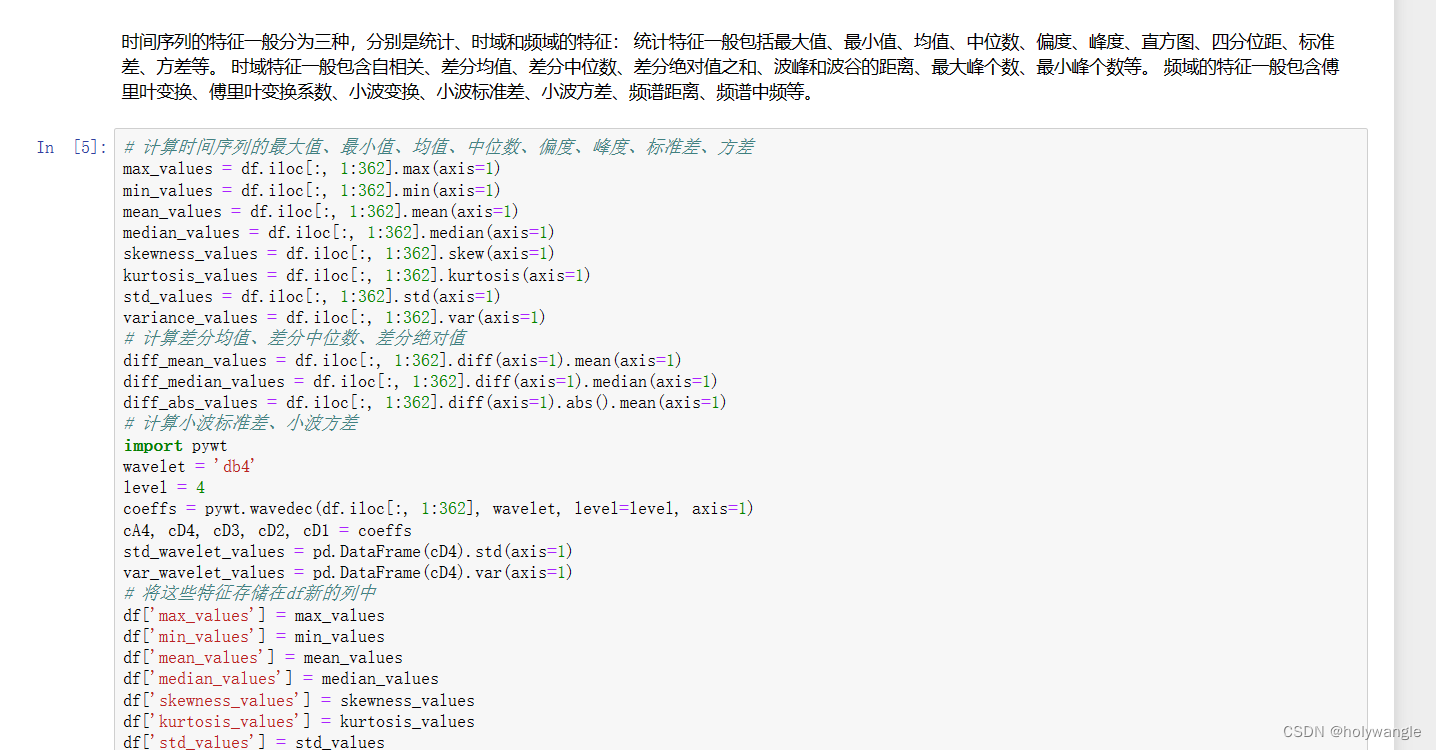
针对问题1:可以将问题分为两个小问题。首先对本文数据异常心搏整合,并进行其特性的分析。因为每个csv的文件都是2s的时间序列数据,直接使用时间序列建模明显数据过于繁琐,并不可取。因此,按照思路可以利用这些数据时间序列去提取统计特征、频域特征、时域特征,并存储于数据集中。根据上述的特征,对每个样本提取特征,并对正常的标记 0,异常的标记 1。 使用监督学习方法,建立机器学习模型进行训练和调参。其次,对心律失常的情况进行分类,这部分类别 label 题目没有给,因此属于无监督学习聚类分析。然后通过使用基于质心的聚类算法,自己决定类的数目。
2.2对问题2的分析
针对问题2:将第一问所得数据集分为数据集和测试集,然后更新聚类中心。可以参考统计模型中的多元线性回归分析的标准化回归系数和机器学习模型的特征重要性分析。这一步的思想是将第一问打的 label 作为 target 进行拟合模型,让模型本身来判断哪些特征是重要的分类依据。具体需要先将数据标准化,将 label 作为因变量,可以带入多元线性回归模型观察标准化回归系数的大小,或者带入机器学习分类模型观察特征重要性的大小,直接量化各个特征的分类重要性。最后将特征值可视化,再去量化其标准。
2.3对问题3的分析
针对问题3:这题可以根据问题1和问题2的结论去分析,一般来说,心搏数据与正常心搏偏离越大则越危险,可以直接与其比较得出统计特征以此做出统计分类。然后,采用机器学习分类中的置信度,假设有3种异常,将正常编号为0,异常的分程度标记为1、2、3,再机器学习进行数据拟合,若心搏数据越偏离正常,则情况越紧急,标记分级更高,若心搏数据偏向正常,则情况越轻缓,标记分级低。
问题一的模型建立与求解:
由于心电监测仪的处理器数据速度和容量有限,会大大限制心电监测长时间的数据计算,因此如何在2s内将心率异常状况分类是一个重点问题。因此:
可通过机器学习输入样本集:会将数据集划分为两部分:训练集和测试集。训练集用来训练模型,测试集用来评估模型的性能。通过训练集,可以得到一个模型,然后用测试集来评估这个模型的泛化能力。如果模型在测试集上的表现很好,那么就可以认为这个模型具有很好的泛化能力,可以用来预测新的数据。在数学建模中,建立训练集和测试集的过程与机器学习中的过程类似。通常会将数据集划分为训练集和测试集,然后使用训练集来建立模型,使用测试集来评估模型的性能。这个过程可以帮助确定模型的参数和超参数,并且评估模型的预测能力。通过这个过程,可以得到一个可靠的模型,用来解决实际问题。
四种模型
使用心跳频率去分析异常情况,可以通过监测心跳频率的变化来判断患者是否出现了心脏疾病等异常情况。以下是四种常用的机器学习模型对心跳频率异常情况的分析:
①Logistics模型:Logistics模型可以用来预测二元分类问题,如判断患者是否有心脏疾病。通过输入患者的心跳频率等特征,Logistics模型可以输出一个概率值,表示患者是否有心脏疾病的可能性。如果概率值大于0.5,则认为患者有心脏疾病;否则,认为患者没有心脏疾病。
Logistic回归模型对因变量y直接进行建模,而是对y取某个值的概率进行建模,即p{y=1|x}进行建模。这个概率的取值只有0或1两种情况。那么可以得到p{y=1|x}与x的关系建立模型:
②决策树模型:决策树模型可以用来预测多元分类问题,如判断患者是否有不同类型的心脏疾病。通过输入患者的心跳频率等特征,决策树模型可以逐步判断患者是否有不同类型的心脏疾病。例如,如果患者的心跳频率小于60次/分钟,则认为患者可能患有心房颤动等疾病。
③随机森林模型:随机森林模型可以用来预测多元分类问题,如判断患者是否有不同类型的心脏疾病。与决策树模型不同的是,随机森林模型会生成多个决策树,并且每个决策树都是基于不同的随机样本和特征生成的。通过对多个决策树的预测结果取平均值,随机森林模型可以更准确地预测患者是否有心脏疾病。
④XGBoost模型:XGBoost模型是一种高效的集成学习模型,可以用来预测二元或多元分类问题。与随机森林模型类似,XGBoost模型也是基于多个决策树生成的。但是,XGBoost模型在生成决策树时采用了一些优化技术,如梯度提升和正则化等,可以更准确地预测患者是否有心脏疾病。
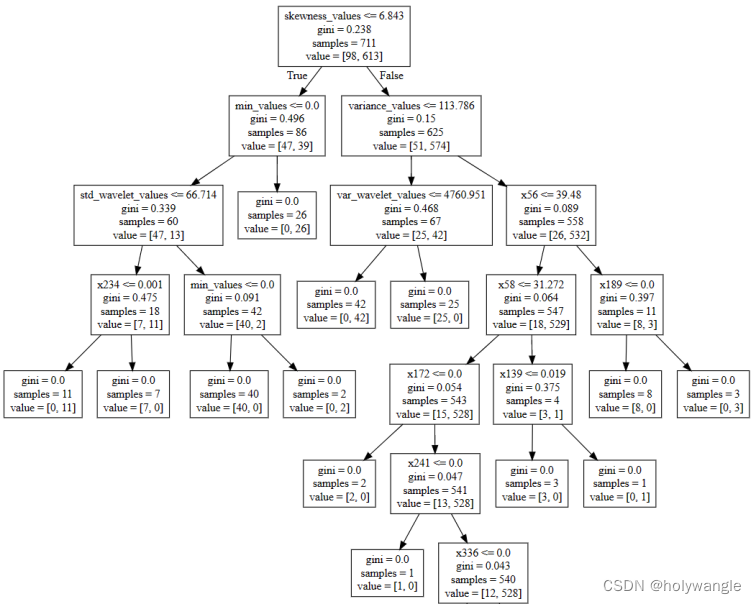
利用文本数据生成的决策树模型部分图
问题二的模型建立与求解:
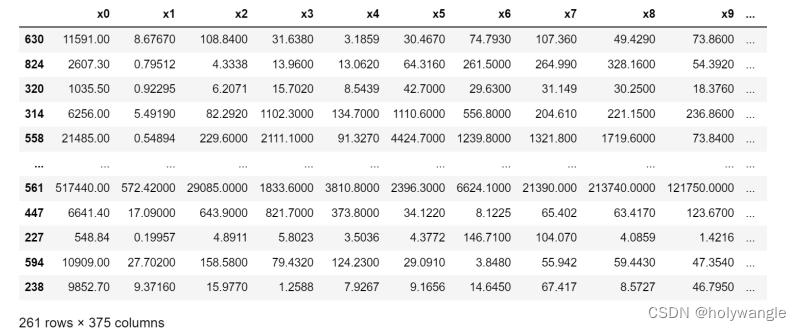
利用文本数据生成的心搏数据
由上图可知,不会存在完全一致的心搏频率图,因此如何衡量出一个标准应用于心电监测仪去判断心律失常的类别尤为重要。
因此,在通过机器学习后,将测试集整理出来:
部分机器学习后心搏频率测试数据
经过大量的测试数据分析,最终选用了logistic模型、决策树模型、随机森林模型和xgboost模型进行比较。
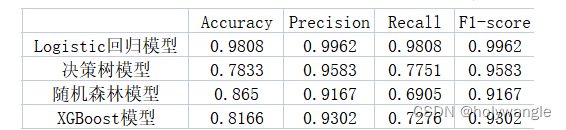
机器学习后四种模型的性能度量指标折线图
机器学习后四种模型的性能度量指标表
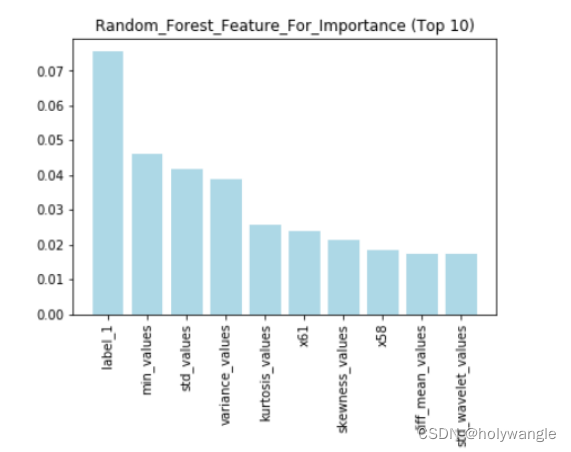
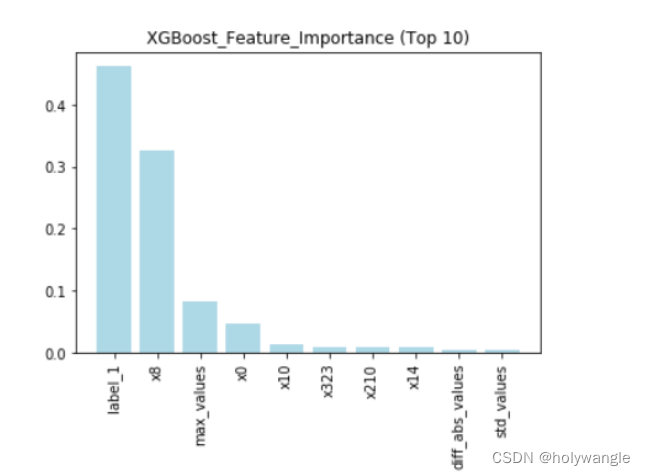
通过在对比分析的结果中不难发现,发现随机森林模型和XGBoost模型表现更加优秀,因此建议在实际应用中使用这两种模型,以获得更好的预测效果。因此选用随机森林模型和XGBoost模型的前十项指标数据进行分析:
随机森林最重要的十个特征索引图
XGBoost最重要的十个特征索引图
最后,则是对重要的特征进行可视化。假设x1,x2,x3,x4,x5是最重要的特征,则将他们三三排列组合成10种,绘制三维散点图,将不同label的点用不同颜 色标记,这样可以直观看出哪些点在哪些取值下会严重影响分类的性能,得到判断依据。


问题三的模型建立与求解:
1)危险程度衡量的指标分析
本题主要是对问题一和问题二的总结,利用问题一中求出的异常种类以及问题二得出的异常心率标准。可以根据心率失常的类型以及临床表现,将异常心率的失常程度分为:低危型心率失常、中危型心率失常和高危型心率失常。
根据上述的分类,不但可以以每个片段的分类顺序从上到下分为高中低三个等级,还可以依据每种等级内会发生的心律失常类型进一步排序,而为了实现心律失常 风险评估和排序,使用了一种基于机器学习的方法,具体步骤如下:
Step1:
像解决问题一的同样方法,在标注完正常心率与异常心率的图标中,对每个片段,计算其各类型的特征值,并将其当做改片段的特征向量。
Step2:
根据心电图中已知的正常心搏频率和异常心搏频率进行区别标注,方便下一步让电脑明白数据,例如:正常心搏数据标记为0,异常拼搏数据从低到高依次为1、2、3。
Step3:
在数据预处理完成后,使用已经标注好的样本数据来进行训练学习,采用四种聚类分析模型,分别是:Logistic模型、决策树模型、随机森林模型和XGBoost模型。在分析求证后,最终使用了Logistic模型。
Step4:
在模型训练完成后,使用新的心电图数据输入模型中,就可以依靠2s的心电频谱检测出每个片段的危险等级,将预测的结果排序好和分级,更有利于医生能够更加快速地诊断和处理。
2)实际上的聚类分析得出的结论
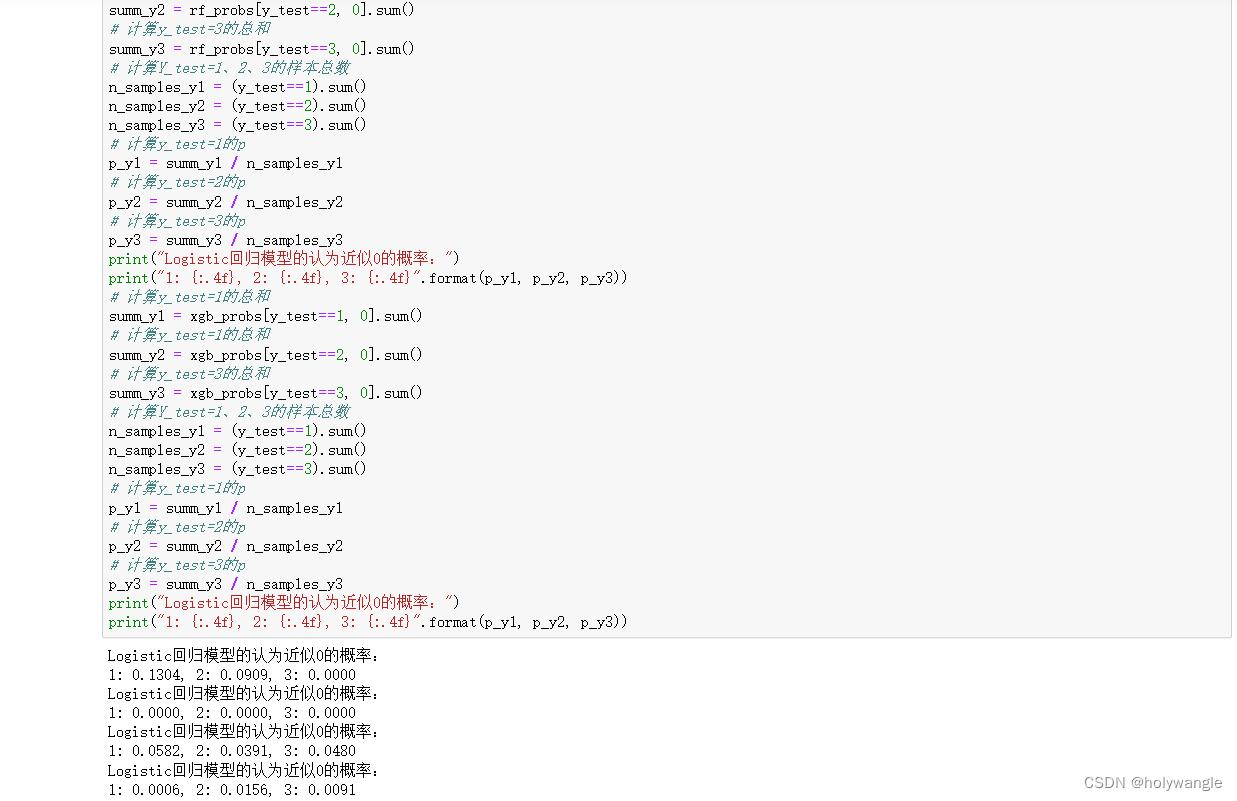
使用logistci模型,可得Logistic回归模型的认为近似0的概率分别如下
类型
近似0的概率
1
0.058
2
0.0327
3
0.046
根据逻辑回归模型进行对数据进行预估,将预估值里面是心率失常而且类型不同的人分别对应求总和,不同类型心率失常的人分别求其样本总数,将其对应求概率,该概率为求近似0(正常心率的人)的概率,概率越低证明他与正常人的心率相差更大,即表明该人心率失常就更为严重。
部分代码展示:





总结:
这个比赛多查资料肯定是真谛。而且论文是重要参考的,记得要花很多很多很多时间写论文,伙伴们!!!
上面提供的思路也只是给各位参考参考而已,希望大神来指点指点,一起学习。
这个代码格式是ipynb格式的,我这里不可能一条条复制,所以有需要的伙伴们点赞评论收藏之后都可以私聊我要代码资料哦,谢谢!

感谢各位的观看,创作不易,能不能给哥们来一个点赞呢!!!
好了,今天的分享就这么多了,有什么不清楚或者我写错的地方,请多多指教!
私信,评论我呗!!!!!!
关注我下一篇不迷路哦!