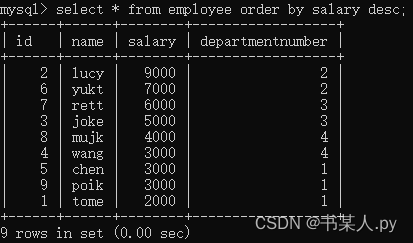
在vscode上使用maven构建spark的scala编程环境,很大程度上需要不断地从网络上下载各种依赖和插件,而且这一过程复杂而不可控。下面这段,是整个安装过程中/root目录下不断增加的内容。
[root@d7ff8f448a0d /]# cd /root
[root@d7ff8f448a0d ~]# ls -a
. .. .bash_logout .bash_profile .bashrc .cshrc .ssh .tcshrc .vscode-server anaconda-ks.cfg hadoop init-vscode.sh m2repo maven spark
[root@d7ff8f448a0d ~]# ls -a
. .bash_history .bash_profile .cshrc .ssh .vscode-server hadoop m2repo program
.. .bash_logout .bashrc .pki .tcshrc anaconda-ks.cfg init-vscode.sh maven spark
[root@d7ff8f448a0d ~]# ls -a
. .bash_history .bash_profile .cache .dotnet .ssh .vscode-server hadoop m2repo program
.. .bash_logout .bashrc .cshrc .pki .tcshrc anaconda-ks.cfg init-vscode.sh maven spark
[root@d7ff8f448a0d ~]# ls -a
. .bash_history .bash_profile .cache .dotnet .ssh .vscode-server hadoop m2repo program
.. .bash_logout .bashrc .cshrc .pki .tcshrc anaconda-ks.cfg init-vscode.sh maven spark
[root@d7ff8f448a0d ~]# ls -a
. .bash_history .bash_profile .bloop .config .dotnet .pki .ssh .vscode-server hadoop m2repo program
.. .bash_logout .bashrc .cache .cshrc .m2 .redhat .tcshrc anaconda-ks.cfg init-vscode.sh maven spark
[root@d7ff8f448a0d ~]# ls -a
. .bash_history .bash_profile .bloop .config .dotnet .m2 .redhat .tcshrc anaconda-ks.cfg init-vscode.sh maven spark
.. .bash_logout .bashrc .cache .cshrc .local .pki .ssh .vscode-server hadoop m2repo program
[root@d7ff8f448a0d ~]#
另一方面,vscode的离线安装也需要匹配容器中code与外部code的版本。所以完全构造一个不依靠网络随时可启动、还适配任何主机vscode的scala环境着实困难,甚至直接从构建完成的容器导出的镜像,都很难保证再次导入后可用。所以最终我还是放弃了基于Dockerfile构建离线可用的容器环境,转为在所有环境构建完成后,通过export继而import导入最终的镜像。
一、编译容器的Dockerfile
先准备一个安装了各种语言开发包的容器,以便以后使用vscode连接。当然,为了能够进行hadoop和spark编程,我们把这两个的单机安装过程也跑一遍。装上ssh,这样就可以从vscode连接了。
FROM centos:centos7
#口令参数需要从外部传入
ARG password
#构造更改了清华镜像源的centos7镜像
RUN sed -e 's|^mirrorlist=|#mirrorlist=|g' \
-e 's|^#baseurl=http://mirror.centos.org/centos|baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos|g' \
-i.bak \
/etc/yum.repos.d/CentOS-*.repo\
&& yum clean all
ADD hadoop-3.3.5.tar.gz /root
ADD spark-3.4.0-bin-hadoop3.tgz /root
#拷贝SSH免密登录的相关密钥文件,目前只放置了15个
COPY .ssh /root/.ssh
#拷贝所有待安装软件
COPY ./rpm /root/rpm/.
#拷贝初始化脚本
COPY ./init-vscode.sh /root/.
#构造可swarm一健部署的SSH免密登录镜像-------------------------------------------------------------
#设置初始化脚本的可执行属性
#更改私钥文件属性为仅root用户可见,否则ssh会拒绝执行
#需要为root用户设置口令,否则免密登录还会弹出框,docker镜像默认没有密钥
#安装openssh,并生成服务端密钥,更改强制指纹验证配置项为no,以免弹出指纹询问框
RUN chmod 0400 /root/.ssh/id_rsa \
&& chmod 0600 /root/.ssh/authorized_keys \
&& echo ${password} | passwd --stdin root \
&& yum localinstall /root/rpm/*.rpm -y \
&& /sbin/sshd-keygen \
&& echo -e '\nHost *\nStrictHostKeyChecking no\nUserKnownHostsFile=/dev/null' >> etc/ssh/ssh_config \
&& rm /root/rpm -rf \
&& chmod +x /root/init-vscode.sh \
&& mv /root/hadoop-3.3.5 /root/hadoop \
&& echo -e "export HADOOP_HOME=/root/hadoop\nexport PATH=\$PATH:\$HADOOP_HOME/bin\n" >> /root/.bashrc\
&& mv /root/spark-3.4.0-bin-hadoop3 /root/spark\
&& echo -e "export SPARK_HOME=/root/spark \nexport PATH=\$PATH:\$SPARK_HOME/bin">>/root/.bashrc\
&& echo -e "export JAVA_HOME=/usr/java/latest">>/root/.bashrc \
&& echo -e "export SCALA_HOME=/usr/share/scala">>/root/.bashrc
#默认启动脚本
CMD ["/root/init-vscode.sh"]
所以初始化脚本的主要作用是把sshd启动起来:
#! /bin/bash
source ~/.bashrc
/sbin/sshd -D &
tail -f /dev/null
二、 远程VSCODE安装
在windows本地安装vscode之类的啥就不提了,直接从安装好了开始:
1. 远程SSH连接容器
只需要在创建ssh连接的时候填入 ssh root@pighost1 -p9025即可
仅仅是比原先多了一个端口设定,以便连接到容器绑定的端口上。

2. 插件安装
安装插件主要是2个大包。
(1)Extension Pack for java

(2)Extension Pack for scala
不过这个包会捆绑一些我们当下其实并不需要的一些东西,而且在没有注册的时候还经常报错,很是烦人,所以我们也可以选择手动安装必要的插件,主要包括:
Scala(Metals)

Scala Syntax(official)
Scala Language Server
Scala Snippets
亲测这4个装完完全够scala开发了。
3. Metals环境安装
此时点击Metals图标,会开始安装,等待就好
里里外外会下载还几个G的东西,所以等待时间会比较长。下载完成后会警告说没有编译工具对象,大意就是指maven的那个pom文件。没关系,还没构建呢。
4. 使用Mave创建一个Scala工程

构建scalameta/maven-scala-seed.g8,
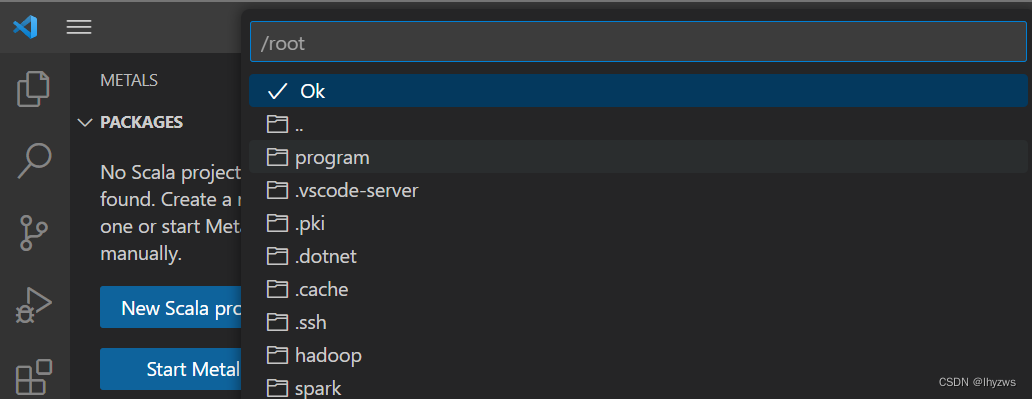
点击program(之前我们建的文件夹),再点击ok后,会要求给一个名字,默认是maven-scala-seed。
然后安静等待,视网络情况,可能得一会儿生成器才会开始工作…这个“一会儿”可能长达一分钟,所以一定要选择 相信 …注意看网络速率那里(如果有装相关的监视软件或者杀毒软件小插件之类的话)其实一直在下载,在没有下载完成之前,这个自动生成的操作是不会开始的。
生成结束后,vscode会询问是否在新窗口中打开项目,选择yes(这样项目会跳到pom文件所在的目录下,从而不会导致生成可执行文件时遭遇no target错误)。
 关闭原来的窗口,使用新打开的窗口就好。此时项目的目录结构应该时这样的,可以看到pom文件已经出现了:
关闭原来的窗口,使用新打开的窗口就好。此时项目的目录结构应该时这样的,可以看到pom文件已经出现了:

这时一般vscode会很贴心的问要不要import build一下。此时千万不要import!!!此时千万不要import!!!此时千万不要import!!!
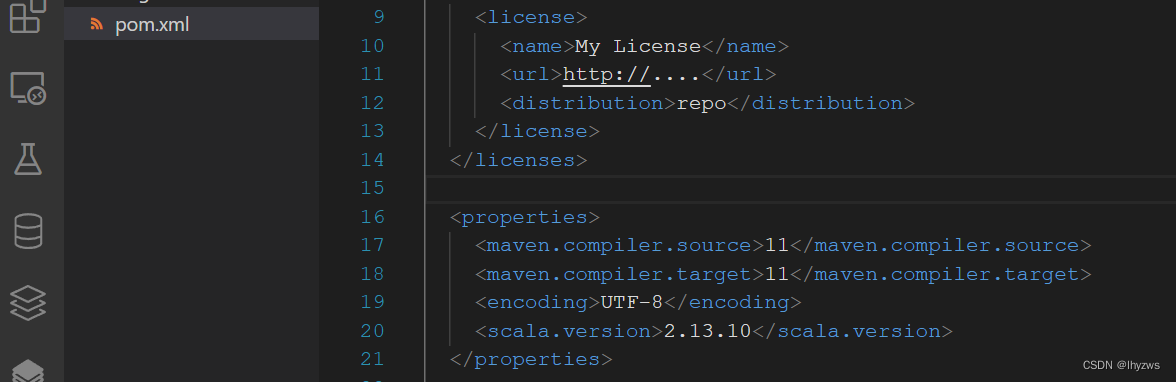
否则可能会由于java版本不匹配造成某些地方的配置错误,我也不知道错在哪(估计是在metals的java环境同步设置中,懒得找了)。pom文件中默认配置jdk是1.8版本的。由于我们使用的是jdk 11,所以pom文件的这里需要改动一下:

1即可:
然后这次VS从的仍然会询问是否import,这次就可以选择import build了

import过程中,maven会运行bloopinstall,这个也需要花很长时间。
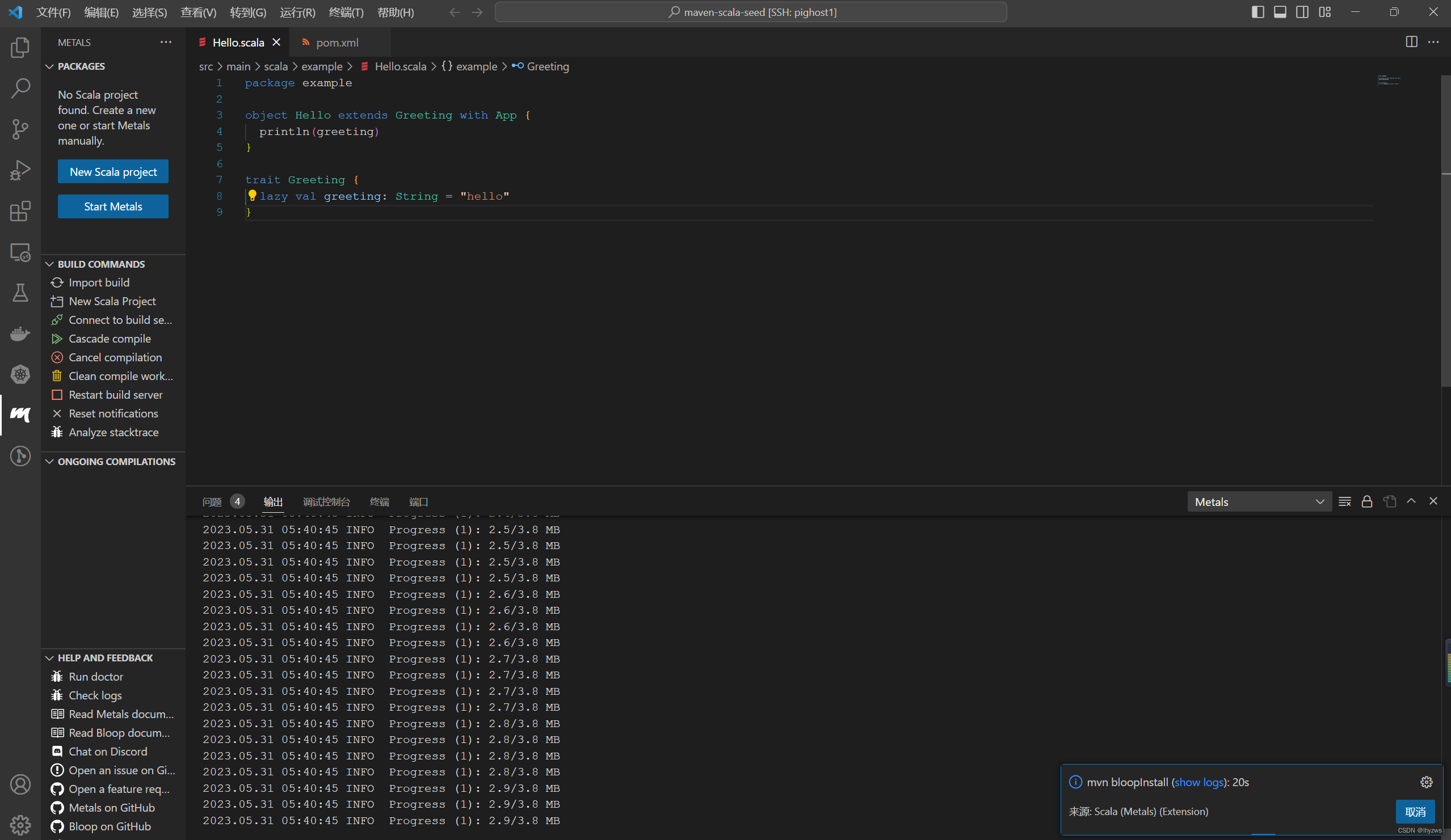
最后在输出窗口中会看到SUCCESS。但是不要以为这就是结束。

然后就是需要继续观察下载速率,等待下载……总之装这个一路都很玄学,因为有些下载在输出窗口里面是能看到的(如果选择了观察logs),有些下载操作在窗口是什么都看不到的——如果你以为什么动静都看不到就是装完了而试图区执行代码的时候,一般会收到internal error。
信则有,不信就没有。我们要坚定地相信vscode会帮助我们搞定一切的(=反正不信也没有别的什么办法……)。直到所有配置工作搞定之后,应该能发现示例代码可执行的类上方出现了“run | debug”这样的图标,代表vscode准备好了。
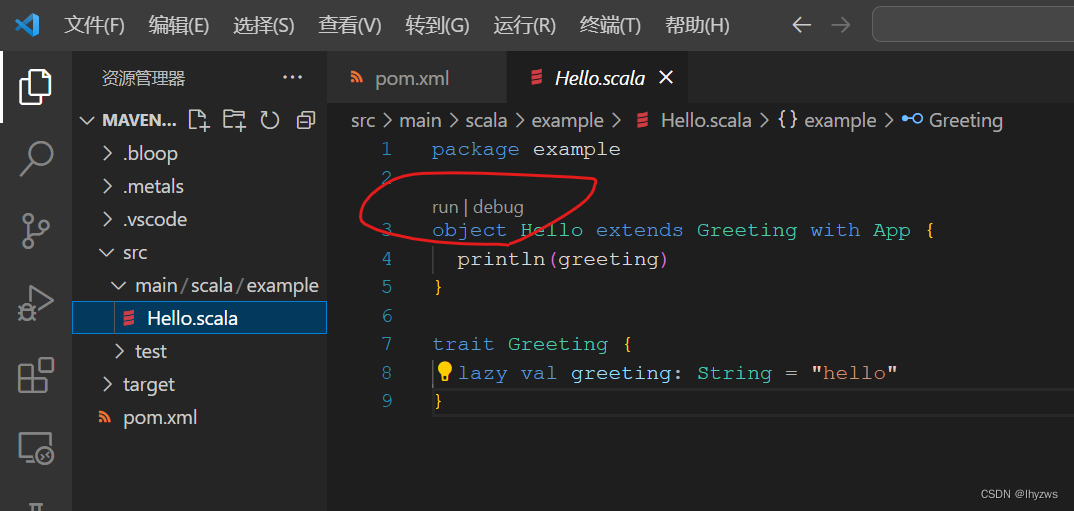
如果怎么都等不到这个结果,不妨直接运行一下代码,当然会收到Internal error的错误。不过这次运行似乎会刺激metals继续工作。因为不久后右下角会出现indexing以及scalafix工作的字样,完成后一般metals的packages窗口内会出现内容,而不是那两个找不到scala程序及要求创建的按钮:
如果是jdk11的环境(我也不知道1.8会不会有类似问题……因为下面这一步我没有配置的时候也能成功,但有时候不配就是不成功:)
在帮助栏中执行run doctor:
得到如下界面:
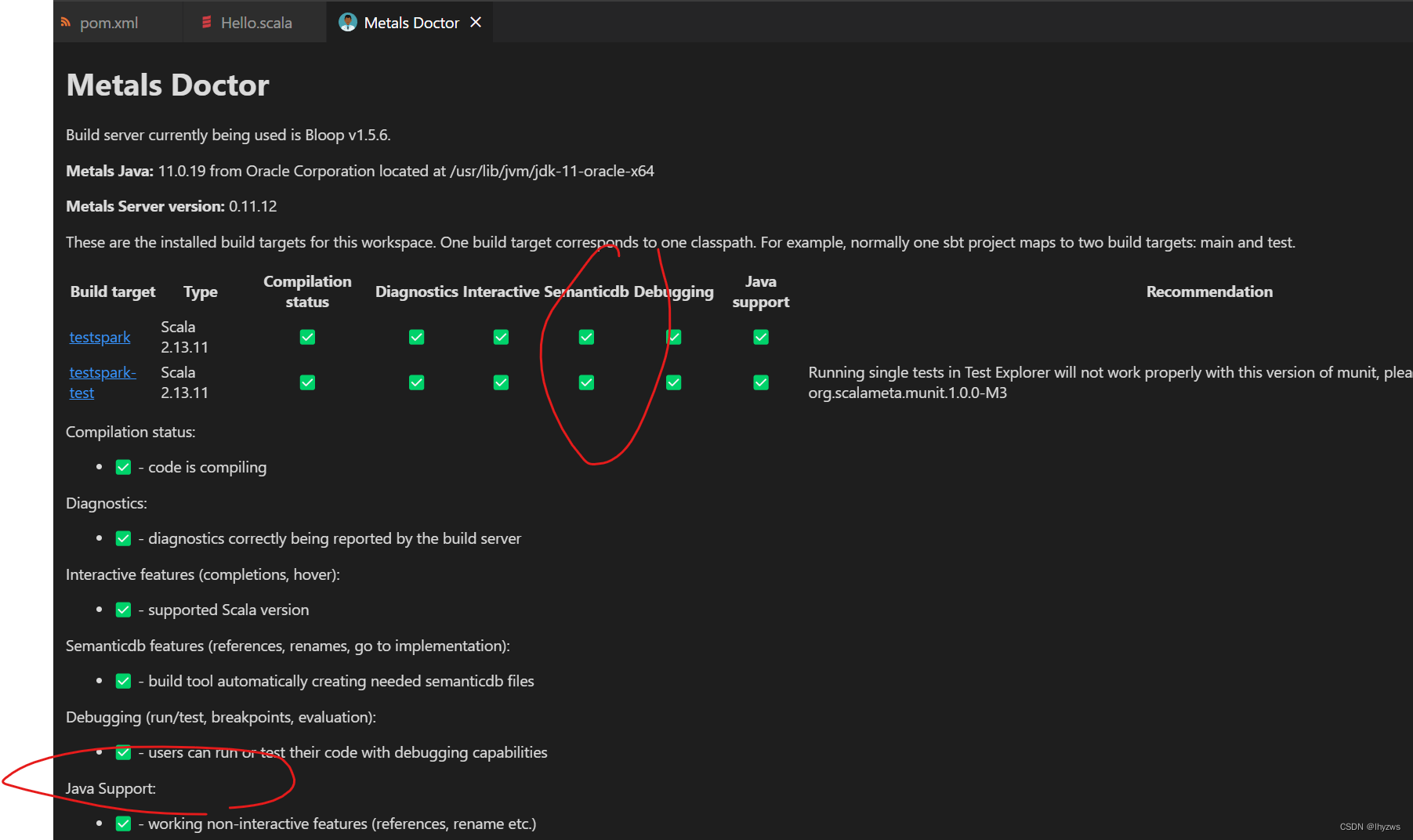
错误的图木有了,正确的图示如上,总之这个semanticdb插件没有的话,就不行,还得手动安装一下。——到maven仓库里面找到,在pom文件中添加如下即可:
<!-- https://mvnrepository.com/artifact/org.scalameta/semanticdb -->
<dependency>
<groupId>org.scalameta</groupId>
<artifactId>semanticdb_2.12</artifactId>
<version>4.1.6</version>
</dependency>此时执行程序,应该结果就不会有问题了:

5. 导入Spark依赖

对于Spark,需要向pom文件中导入对应的依赖,如上。
最终的pom文件:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>testspark</artifactId>
<version>1.0-SNAPSHOT</version>
<name>testspark</name>
<description>A minimal Scala project using the Maven build tool.</description>
<licenses>
<license>
<name>My License</name>
<url>http://....</url>
<distribution>repo</distribution>
</license>
</licenses>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.13.11</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.13.11</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.scalameta/semanticdb -->
<dependency>
<groupId>org.scalameta</groupId>
<artifactId>semanticdb_2.12</artifactId>
<version>4.1.6</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.13</artifactId>
<version>3.4.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.13</artifactId>
<version>3.4.0</version>
<scope>provided</scope>
</dependency>
<!-- Test -->
<dependency>
<groupId>org.scalameta</groupId>
<artifactId>munit_2.13</artifactId>
<version>0.7.29</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<!-- see http://davidb.github.com/scala-maven-plugin -->
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.3.2</version>
<configuration></configuration>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args></args>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
然后就是继续等待vscode下载。当然,一般来说这些java包下载存储在 ~/.m2下。我们也可以直接从mave repository上下载java包放到对应目录下即可。
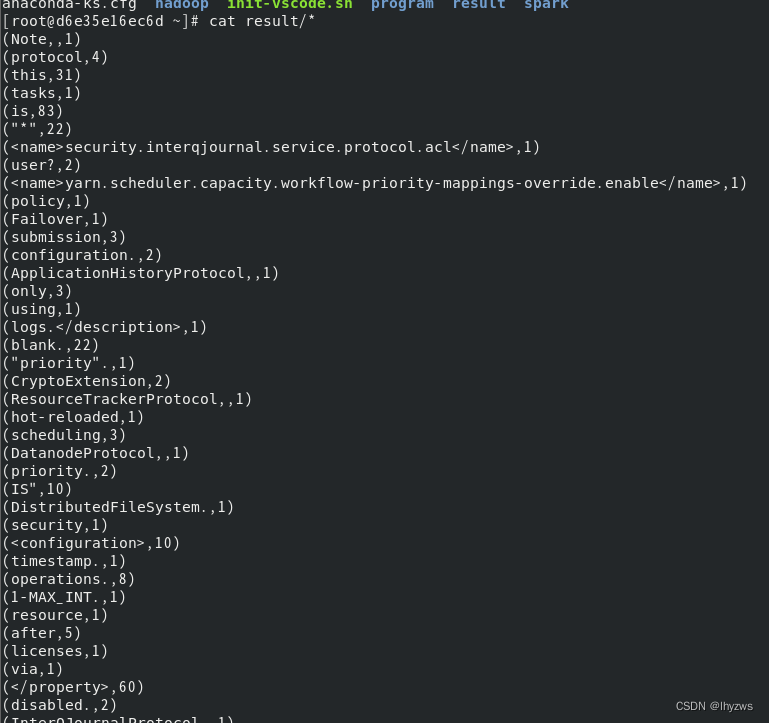
放上经典的分词并且计数代码,执行:
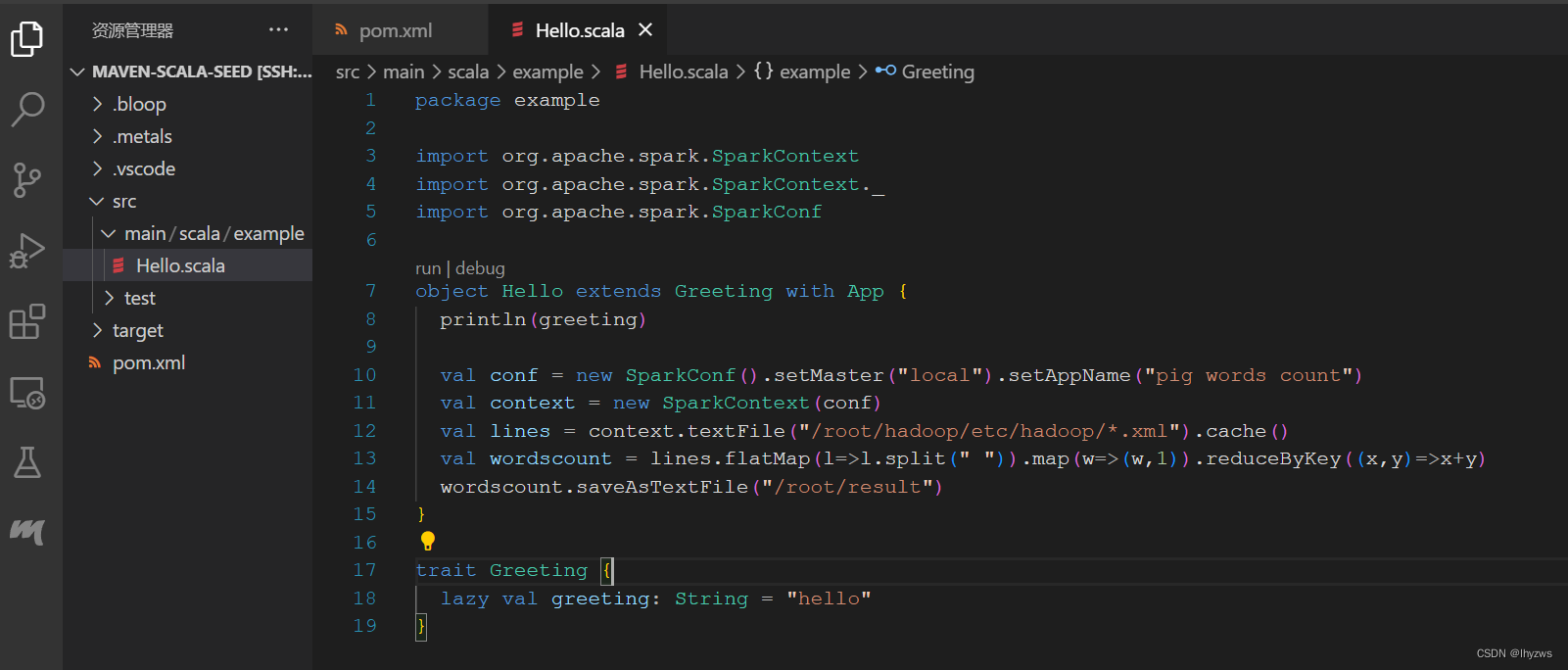
结果可以到容器里面观察一下:
6. Scala 和 Java 混合编程
Scala本身就是从Java生长出来的,所以在scala环境中使用java代码,或者在java中使用scala代码应该说是很直接的需求。要满足这样混合编程的条件,需要在pom文件的plugin中添加插件:
<!--为混合编程添加-->
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>build-helper-maven-plugin</artifactId>
<executions>
<execution>
<id>add-source</id>
<phase>generate-sources</phase>
<goals>
<goal>add-source</goal>
</goals>
<configuration>
<sources>
<source>src/main/scala</source>
</sources>
</configuration>
</execution>
<execution>
<id>add-test-source</id>
<phase>generate-sources</phase>
<goals>
<goal>add-test-source</goal>
</goals>
<configuration>
<sources>
<source>src/test/scala</source>
</sources>
</configuration>
</execution>
</executions>
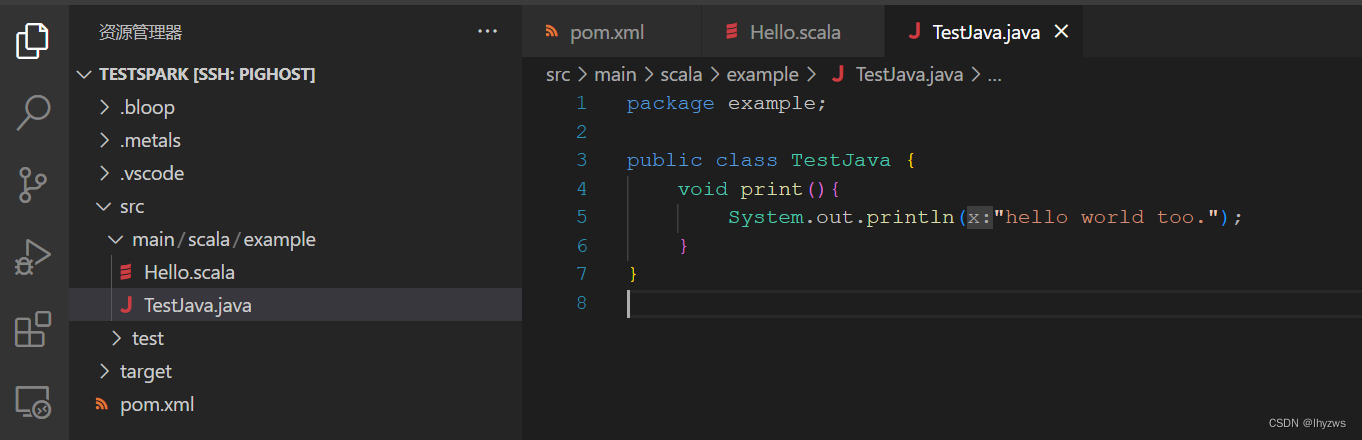
</plugin>然后直接在工作目录中增加java文件:
就可以在scala中调用了:

结果如下: 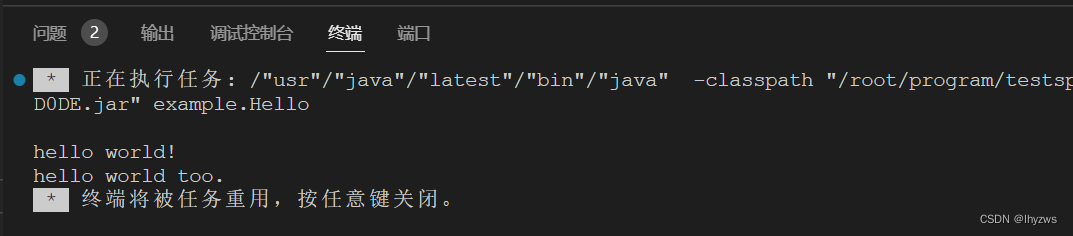
三、导出镜像
1. 使用docker export导出当前的容器
[root@pighost share]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
76d0b875683b pig/vscode "/root/init-vscode.sh" 8 minutes ago Up 8 minutes 0.0.0.0:9025->22/tcp, :::9025->22/tcp pig
[root@pighost share]# docker export -o pigvscode.tar pig2. 使用dockers import构建镜像
[root@pighost share]# docker import pigvscode.tar pig/vscode:scala
sha256:ed572d045eba3c481dc557b2646958548a3e6f469ece866c5605aaef3cdccdc3
[root@pighost share]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
pig/vscode scala ed572d045eba 9 seconds ago 4.49GB
centos centos7 eeb6ee3f44bd 21 months ago 204MB
3. 基于镜像启动容器
由于我们是直接使用容器构建的镜像,所以初始化脚本不会在容器载入时执行了,需要我们在载入过程中显示指定。(当然,这样我们以后就无法在swarm中使用了。如果需要,应该基于该镜像,重新使用Dockerfile构建一个新的镜像并指明CMD就好了。)
[root@pighost share]# docker run -itd --name pig -p 9025:22 pig/vscode:scala /root/init-vscode.sh
37b6651fe96fe58ae17eda584310e83778a6d3d012ba55584a53a42c1ecd7065
[root@pighost share]#
然后启动vscode直接进行远程连接就可以了。
四、Spark-shell交互式分析
使用scala编程,有很多事可做。当然,在开始编程之前,使用spark-shell交互式环境,体验一下scala的使用效果,也是不错的。直接在命令行中执行spark-shell就可以了:
1. 读csv文件:
val df = spark.read.option("header",true).csv("/sample/DOS/*.csv")
或
val df = spark.read.option("header",true).format("csv").load("/sample/DOS/*.csv")
scala> val df = spark.read.option("header",true).csv("/sample/DOS/*.csv")
df: org.apache.spark.sql.DataFrame = [sid: string, message_type: string ... 23 more fields]
2. 查看读入文件的统计信息
df.count
df.columns
scala> df.count
res0: Long = 155395
scala> df.columns
res1: Array[String] = Array(sid, message_type, attack_type, src_ip, src_port, src_mac, src_country, src_province, src_city, src_location, dest_ip, dest_port, dest_mac, dest_country, dest_province, dest_city, dest_location, device_id, application_protocol, protocol, ip_version, timestamp, risk_level, length, message)
3. 查看读入数据的模式信息
df.schema
scala> df.schema
res2: org.apache.spark.sql.types.StructType = StructType(StructField(sid,StringType,true),StructField(message_type,StringType,true),StructField(attack_type,StringType,true),StructField(src_ip,StringType,true),StructField(src_port,StringType,true),StructField(src_mac,StringType,true),StructField(src_country,StringType,true),StructField(src_province,StringType,true),StructField(src_city,StringType,true),StructField(src_location,StringType,true),StructField(dest_ip,StringType,true),StructField(dest_port,StringType,true),StructField(dest_mac,StringType,true),StructField(dest_country,StringType,true),StructField(dest_province,StringType,true),StructField(dest_city,StringType,true),StructField(dest_location,StringType,true),StructField(device_id,StringType,true),Stru...
scala> df.printSchema
root
|-- sid: string (nullable = true)
|-- message_type: string (nullable = true)
|-- attack_type: string (nullable = true)
|-- src_ip: string (nullable = true)
|-- src_port: string (nullable = true)
|-- src_mac: string (nullable = true)
……………………
|-- device_id: string (nullable = true)
|-- application_protocol: string (nullable = true)
|-- protocol: string (nullable = true)
|-- ip_version: string (nullable = true)
|-- timestamp: string (nullable = true)
|-- risk_level: string (nullable = true)
|-- length: string (nullable = true)
|-- message: string (nullable = true)
刚导入进来的全是string格式
4. 列操作
(1)选择列
scala> val smalldf = df.select(col("src_ip"),col("src_port"),col("dest_ip"),col("dest_port"),col("message"))
scala> smalldf.show()
+---------------+--------+---------------+---------+--------------------+
| src_ip|src_port| dest_ip|dest_port| message|
+---------------+--------+---------------+---------+--------------------+
| 192.168.11.20| 38021|172.0.1.68 | 123|FRN DOS Possible ...|
………………………………
| 192.168.11.20| 47430|172.0.1.68 | 123|FRN DOS Possible ...|
+---------------+--------+---------------+---------+--------------------+
only showing top 20 rows
smalldf: Unit = ()
选择列的简单方式:
scala> lines.select('src_ip).show()
+---------------+
| src_ip|
+---------------+
| 192.168.1.46|
| 192.168.1.46|
| 192.168.1.46|
…………………………
only showing top 20 rows(2)增加列
scala> lines.select('src_ip).withColumn("count",lit(1)).show
+---------------+-----+
| src_ip|count|
+---------------+-----+
| 192.168.1.111| 1|
| 192.168.1.112| 1|
5. 去重
去重只有distinct可用,如果是只正对一个字段的话,得把这个字段选出来
scala> lines.count
res9: Long = 155395
scala> lines.distinct.count
23/05/24 02:01:31 WARN package: Truncated the string representation of a plan since it was too large. This behavior can be adjusted by setting 'spark.sql.debug.maxToStringFields'.
res10: Long = 154022
scala> lines.select('src_ip).distinct.count
res11: Long = 1454
scala>
可以看出效果截然不同
6. 过滤
scala> lines.count
res16: Long = 155395
scala> lines.filter("dest_port='123'").count
res17: Long = 97147
scala> lines.filter("src_ip='192.168.0.11' and dest_port='123'").count
res18: Long = 3202
where 就是sql语句where后面得表达式
scala> lines.where('dest_ip.like("192%")).select('src_ip,'src_port,'dest_ip,'dest_port).show
+---------------+--------+---------------+---------+
| src_ip|src_port| dest_ip|dest_port|
+---------------+--------+---------------+---------+
| 192.168.1.11 | 38021| 172.18.0.13| 123|
列语法糖 $ === =!=
scala> lines.filter($"protocol"==="tcp").select('src_ip,'src_port,'dest_ip,'dest_port,'protocol).show
+---------------+--------+--------------+---------+--------+
| src_ip|src_port| dest_ip|dest_port|protocol|
+---------------+--------+--------------+---------+--------+
| 192.168.1.112| 61841| 172.17.0.1| 2710| tcp|
7. 统计
scala> lines.groupBy('dest_ip).count().orderBy('count.desc).show()
+---------------+-----+
| dest_ip|count|
+---------------+-----+
| 192.168.1.11| 273|
| 192.168.1.12| 148|
| 192.168.1.13| 142|
8. 类型转换
spark有3中主要类型,RDD、Dataframe和Dataset,各有各的优势,所以经常需要转换使用。
(1)DataFrame转Dataset
scala> val fivetuples = lines.select('src_ip,'src_port,'dest_ip,'dest_port,'protocol)
fivetuples: org.apache.spark.sql.DataFrame = [src_ip: string, src_port: string ... 3 more fields]
scala> case class FIVETUPLE(src_ip:String,src_port:String,dest_ip:String,dest_port:String,protocol:String)
defined class FIVETUPLE
scala> val fset = fivetuples.as[FIVETUPLE]
fset: org.apache.spark.sql.Dataset[FIVETUPLE] = [src_ip: string, src_port: string ... 3 more fields]
(2)DataSet转DataFrame
scala> val fdf = fset.toDF
fdf: org.apache.spark.sql.DataFrame = [src_ip: string, src_port: string ... 3 more fields]
scala> fdf.columns
res31: Array[String] = Array(src_ip, src_port, dest_ip, dest_port, protocol)
(3)DataFrame转RDD
scala> val frdd = fdf.rdd
frdd: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[124] at rdd at <console>:23
(4)RDD转DataFrame
转回来需要map一下
scala> val fdf2 = frdd.map(l=>FIVETUPLE(l(0).toString(),l(1).toString(),l(2).toString(),l(3).toString(),l(4).toString())).toDF
fdf2: org.apache.spark.sql.DataFrame = [src_ip: string, src_port: string ... 3 more fields]
(5)RDD和DataSet互转
scala> val fset2 = frdd.map(l=>FIVETUPLE(l(0).toString(),l(1).toString(),l(2).toString(),l(3).toString(),l(4).toString())).toDS
fset2: org.apache.spark.sql.Dataset[FIVETUPLE] = [src_ip: string, src_port: string ... 3 more fields]
scala> fset2.rdd
res32: org.apache.spark.rdd.RDD[FIVETUPLE] = MapPartitionsRDD[129] at rdd at <console>:24
9. 碰撞
在交互式环境中进行碰撞操作,可以将需要碰撞的一个集合通过array或者list导出来。比如:
(1) 获取array
scala> val ip11 = lines.where('dest_ip.like("%11")).select('dest_ip).collect()
ip11: Array[org.apache.spark.sql.Row] = Array([192.168.………………(2)获取List
scala> val ip11 = lines.where('dest_ip.like("%11")).select('dest_ip).collectAsList()
ip11: java.util.List[org.apache.spark.sql.Row] = [[192.168.……(3)转为可用的数组或列表
但以上两种获得的都是Row类型,在碰撞程序中不好用。要获得程序中好用的List,需要转化为rdd,然后使用map方法将row中的元素提取出来:
scala> val ip11 = lines.where('dest_ip.like("%111")).distinct.select('dest_ip).rdd.map(r=>r(0)).collect()
ip11: Array[Any] = Array(192.168.0.111,………………可再使用toList转为List
(4)碰撞发现ip名单内的数据
scala> lines.where('src_ip.isin(ip11:_*)).show
(5)碰撞排除ip名单内的数据
scala> lines.where(!'dest_ip.isin(ip11:_*)).select('dest_ip).show
10. SQL操作
scala> val lines = spark.read.option("header",true).csv("/sample/DOS/*.csv")
lines: org.apache.spark.sql.DataFrame = [sid: string, message_type: string ... 23 more fields]
scala> lines.createOrReplaceTempView("mytable")
scala> spark.sql("select src_ip from mytable").show
+---------------+
| src_ip|
+---------------+
| 192.168.1.1|
(1)分组统计排序
scala> spark.sql("select dest_ip,dest_port,count(*) as count from mytable group by dest_port,dest_ip order by count desc").show
+---------------+---------+-----+
| dest_ip|dest_port|count|
+---------------+---------+-----+
| 192.168.1.111| 123| 240|
| 192.168.1.112| 123| 122|
(2)对分组排序条件进行限制
scala> spark.sql("select dest_ip,dest_port,count(*) as count from mytable group by dest_port,dest_ip having count<20 order by count desc").show
+---------------+---------+-----+
| dest_ip|dest_port|count|
+---------------+---------+-----+
| 192.168.21.222| 111| 19|
| 192.168.21.222| 111| 19|
scala> spark.sql("select dest_ip,dest_port,count(*) as count from mytable where dest_ip like '173%' group by dest_port,dest_ip having count<20 order by count desc").show
+---------------+---------+-----+
| dest_ip|dest_port|count|
+---------------+---------+-----+
|173.112.111.111| 111| 19|
|173.112.111.112| 111| 19|
(3)嵌套碰撞
scala> spark.sql("select src_ip from mytable where src_ip in (select dest_ip from mytable)").show
+---------------+
| src_ip|
+---------------+
| 10.0.0.1|
(4)仅显示5行:
scala> spark.sql("select src_ip,count(*) as count from mytable group by src_ip having count>100 limit 5").show
+---------------+-----+
| src_ip|count|
+---------------+-----+
| 192.168.1.1| 726|
| 192.168.1.2| 2030|
| 192.168.1.3| 328|
| 192.168.1.4| 204|
| 192.168.1.5| 190|
(5)去重
scala> spark.sql("select protocol from mytable").show
+--------+
|protocol|
+--------+
| udp|
| udp|
| udp|
…………
| udp|
| udp|
+--------+
only showing top 20 rows
scala> spark.sql("select distinct protocol from mytable").show
+--------+
|protocol|
+--------+
| tcp|
| udp|
+--------+
11. DataSet操作
Dataset操作和Dataframe操作类似:
过滤 分组聚合 排序
scala> fset.select('src_ip,'dest_ip).groupBy('src_ip).count.orderBy('count.desc).show
+---------------+-----+
| src_ip|count|
+---------------+-----+
| 10.0.0.1|19720|
| 10.0.0.2| 8037|
| 10.0.0.3| 5778|
可以map
scala> fset.map(l => (l.src_ip,1)).show
+---------------+---+
| _1| _2|
+---------------+---+
| 192.168.10.11| 1|
| 192.168.10.12| 1|
| 192.168.10.12| 1|
| 192.168.10.11| 1|
reduce 统计行数
scala> fset.map(l=>1).reduce(_+_)
res44: Int = 155395
scala> fset.count
res45: Long = 155395
12. RDD操作:
RDD的最大好处就是可以支持灵活的map-reduce,最重要的事可以支持K-V操作。
按src ip过滤
scala> frdd.count
res53: Long = 155395
scala> frdd.filter(l => l(0)=="192.168.0.1").count
res54: Long = 3202
转KV操作
scala> frdd.keyBy(l=>l(0)).first
countByKey
scala> frdd.keyBy(l=>l(0)).countByKey