我们知道丰富数据对于很多的应用来说非常重要。这涉及到访问不同的表格,并进行搜索匹配。找到最为相近的结果并进行丰富数据。针对 Elasticsearh 来说,我们可以通过 enrich processor来进行丰富。你可以阅读我之前的文章来了解更多:
-
Elasticsearch:enrich processor (7.5发行版新功能)
-
Elasticsearch:如何使用 Elasticsearch ingest 节点来丰富日志和指标
-
Elasticsearch 的新 range 丰富策略使上下文数据分析更上一层楼 - 7.16
事实上,我们甚至可以在 Logstash 的 pipeline 中采用 Elasticsearch filter 来丰富数据。你可以参考我之前的文章 “Logstash:运用 Elasticsearch 过滤器来丰富数据”。
在今天的文章中,我来采用一个简单的例子来展示如何使用 Elasticsearch filter 来丰富地理数据。这个在实际的使用中非常有用。比如你采集的数据含有传感器 id,但是在采集的数据里可能并不包含地理位置信息。我们可以通过 Elasticsearch filter 来丰富数据的地理位置信息,这样可以在地图上进行展示。

安装
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考文章:
- 如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
- Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,请参考 Elastic Stack 8.x 的安装指南进行安装。
在 Elasticsearch 中创建 enrich 索引
我们在 Elasticsearch 中创建一个可以在 Logstash 中被引用的索引。它的 mapping 是这样的:
PUT myindex
{
"mappings": {
"properties": {
"address": {
"properties": {
"city": {
"type": "text"
},
"number": {
"type": "keyword"
},
"street_name": {
"type": "text"
},
"zipcode": {
"type": "keyword"
}
}
},
"location": {
"type": "geo_point"
}
}
}
}我们接下来写入如下的一个文档:
POST myindex/_doc/1
{
"address": {
"zipcode": "17000",
"number": "23",
"city": "Beijing",
"street_name": "wang jing road"
},
"location": {
"lon": 116.478598,
"lat": 39.995007
}
}从上面的数据中,我们可以看到除了含有 address 信息之前,它还含有一个地理位置的信息 location。在实际的使用中,那个 address 甚至可以是传感器的 id 信息。
如果我们知道 address 信息,那么我们可以通过如下的查询来获得该位置的地理信息:
GET myindex/_search?search_type=dfs_query_then_fetch&filter_path=**.hits
{
"size": 1,
"query": {
"bool": {
"should": [
{
"match": {
"address.number": "23"
}
},
{
"match": {
"address.street_name": "wang jing road"
}
},
{
"match": {
"address.city": "Beijing"
}
}
]
}
}
}上面的搜索返回如下的信息:
{
"hits": {
"hits": [
{
"_index": "myindex",
"_id": "1",
"_score": 1.4384104,
"_source": {
"address": {
"zipcode": "17000",
"number": "23",
"city": "Beijing",
"street_name": "wang jing road"
},
"location": {
"lon": 116.478598,
"lat": 39.995007
}
}
}
]
}
}很显然,它含有 location 的地理位置信息。
在 Logstash 中使用 Elasticsearch filter 来丰富数据
接下来,我们创建如下的一个 Logstash 配置文件:
logstash.conf
input {
http { }
}
filter {
elasticsearch {
query_template => "search-by-name.json"
index => "myindex"
fields => {
"location" => "[location]"
"address" => "[address]"
}
remove_field => ["headers", "host", "@version", "@timestamp"]
ca_file => "/Users/liuxg/elastic/elasticsearch-8.5.2/config/certs/http_ca.crt"
ssl => true
api_key => "Rf-_4IQB-Ec0fhu3PjhI:JlZ0cA8lRQGRDxhWwdDJVg"
}
}
output {
stdout { codec => rubydebug }
}如上所示,我们使用 http input 来做测试。在上面,我们使用 elasticsearch filter 来丰富数据。我们希望得到的是 location 及 address。在上面,我们定义 search-by-name.json 如下:
search-by-name.json
{
"size": 1,
"query":{
"bool": {
"should": [
{
"match": {
"address.number": "%{[address][number]}"
}
},
{
"match": {
"address.street_name": "%{[address][street_name]}"
}
},
{
"match": {
"address.city": "%{[address][city]}"
}
}
]
}
}
}在上面,我们设置 size 为 1,也即采用最为匹配的那个结果。上面其实就是一个搜索。我们把上述文件置于 Logstash 的安装目录下。另外,我们需要定义证书及 API key。你需要根据自己的配置来对上面的配置进行修改。如果你还不值得如何得到 API key,请阅读我之前的文章 “Logstash:如何连接到带有 HTTPS 访问的集群”。当然如果你的 Elasticsearch 不具有安全配置,那么你就不需要进行任何的配置了。
我们使用如下的命令来进行运行:
./bin/logstash -f logstash.conf 
我们接下来在另外一个 terminal 中打入如下的命令:
curl -XPOST "localhost:8080" -H "Content-Type: application/json" -d '{
"test_case": "Address with text",
"name": "Joe Smith",
"address": {
"number": "23",
"street_name": "wang jing road",
"city": "Beijing",
"country": "China"
}
}'请注意在上面的命令中,它并没有 location 的任何信息。等执行完后,我们可以在 Logstash 的 terminal 中看到如下的输出:
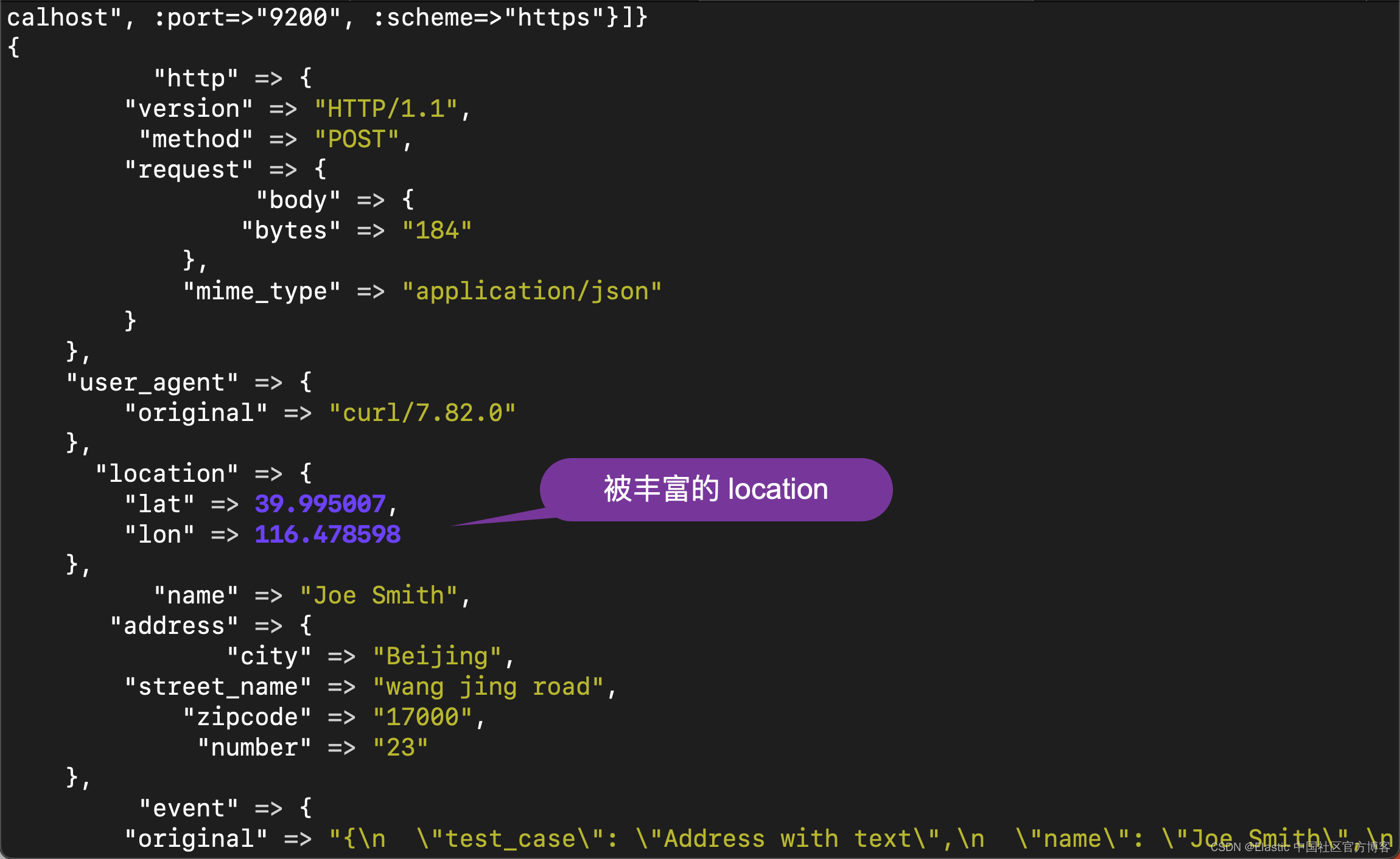
如上所示,我们可以看到被丰富的 location 信息。这个信息来源于 Elasticsearch 中的 myindex 索引。
现在你只需要改变输入部分来读取你的数据源,例如从数据库:
jdbc {
jdbc_driver_library => "mysql-connector-java-6.0.6.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/person?useSSL=false"
jdbc_user => "root"
jdbc_password => ""
schedule => "* * * * *"
parameters => { "country" => "France" }
statement => "SELECT p.id, p.name, p.dateOfBirth, p.gender, p.children, a.city, a.country, a.countrycode, a.lat, a.lon, a.zipcode FROM Person p, Address a WHERE a.id = p.address_id AND a.country = :country AND p.id > :sql_last_value"
use_column_value => true
tracking_column => "id"
}关于这个部分的详细操作请参考文章 “Elasticsearch:将关系数据库中的数据提取到 Elasticsearch 集群中”。