浅析 xml 数据格式文件
xml ( Extensible Markup Language ) 全称 -> 可拓展的标记语言;
xml文件的主要用途:xml文件主要用于数据的 传输 和 存储,并不是展示;
xml标签与html的区别:节点的标签使用方式和 html 十分相似,不同的是 xml 中的标签需要自定义;且语法相较于html来说更加严格(必须是成对标签,且区分大小写);
语法注意:xml 文件节点最外层必须是 root 根节点 [ 当然根节点不一定非得命名为 root,也可以是其他的自定义名称,但是一般来说大家都默认定义根节点为 root ];
这是一个简单的 xml 文件,如下所示 ->
<?xml version="1.0" encoding="utf-8" ?>
<root>
<name>澜色海湾</name>
<age>22</age>
</root>从语法上来说 -> 头声明可写可不写,不影响;
但是我还是建议大家写上 -> 因为头文件里面有一个 encoding 属性非常重要,这让我们在获取这些数据的时候知道应该用什么编码格式去读取他;
xml文件中,节点的内容如果带有特殊符号的话 ->
<?xml version="1.0" encoding="utf-8" ?>
<root>
<calculate>6 < 9</calculate>
<calculate>6 < 9</calculate><!--应该用这种形式-->
</root>如上述代码所示 -> 当我们 xml 节点内容中需要用到特殊字符例如 "<" (小于号) 时,必须要用实体转义字符;
假设我们用浏览器去读取 xml 中的内容,当浏览器读到 "<" 时会认为后面是标签名,实际上并不是标签,而是节点内容,就会出错;
当然字符替换为转义字符的这种解决方式,适用于特殊字符较少时;
如果特殊字符很多很多 -> 那么替换起来就会十分麻烦,我们可以采用 <![CDATA[内容]]> 的方式定义节点内容,这样浏览器就不会解析节点中的内容,而是原模原样的将节点内容打印展示出来 -> 如下所示 ;
<?xml version="1.0" encoding="utf-8" ?>
<root>
<msg><[!CDATA[2 < 8 , 9 > 6 , 99 < 100]]></msg>
</root>
下面给大家罗列出在xml中需要转义的字符 ->
| Original character | Escaped character |
| < | < |
| > | > |
| & | & |
| ' | ' |
| " | " |
Java 解析 xml 文件数据有四种方式,这里我用 dom 方式解析 xml 文件数据,代码如下所示 ->
在 xml 中有三种最常用的节点类型,分别是 Element(元素节点)、Attribute(属性结点)、Text(文本节点);
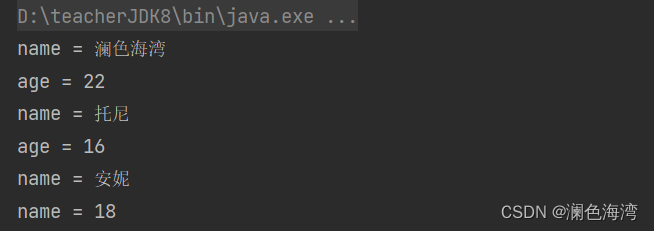
student.xml文件如下所示 ->
<?xml version="1.0" encoding="utf-8" ?>
<root>
<student>
<name>澜色海湾</name>
<age>22</age>
</student>
<student>
<name>托尼</name>
<age>16</age>
</student>
<student>
<name>安妮</name>
<name>18</name>
</student>
</root>
AnalisysXmlFileData.java文件如下所示 ->
public class AnalisysXmlFileData {
public static void analisysFileData() {
try {
DocumentBuilder documentBuilder = DocumentBuilderFactory.newInstance().newDocumentBuilder();
//xml文件绝对路径
Document parse = documentBuilder.parse("src/com/hkl/xmlFileAnalisys/student.xml");
//获取名称为 root 的节点
NodeList nodeList = parse.getElementsByTagName("root");
for(int i = 0;i < nodeList.getLength();i++) {
//获取第 i 个 root 节点
Node rootNode = nodeList.item(i);
//获取 root 节点中的所有子节点
NodeList studentList = rootNode.getChildNodes();
for(int j = 0;j < studentList.getLength();j++) {
//获取第 j 个子节点
Node student = studentList.item(j);
//获取子节点中所有的子节点
NodeList chlidNodeList= student.getChildNodes();
for(int k = 0;k < chlidNodeList.getLength();k++) {
//获取子节点中的第 k 个节点
Node stuAttr = chlidNodeList.item(k);
//如果该结点为 Element 节点
if(stuAttr.getNodeType() == Node.ELEMENT_NODE) {
System.out.println(stuAttr.getNodeName()+" = "+stuAttr.getFirstChild().getNodeValue());
}
}
}
}
}catch(Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
analisysFileData();
}
}
输出结果如下所示 ->