文章目录
- 一、前言
- 二、概述
- 三、数据存储方式:Varints
- (一)原理
- (二)举例
- (三)缺点
- 四、协议的数据结构
- (一)原理
- (二)举例
一、前言
最近刚刚从一家公司离职,在职的时候使用到了go语言的grpc库,了解了除了json之外的另一个专门用于远程调用的序列化工具protobuf。protobuf是Google开源的一款支持跨平台、语言中立的结构化数据描述和高性能序列化协议,此协议完全基于二进制,所以性能要远远高于JSON/XML。由于出色的传输性能因此常见于微服务之间的通讯,其中最为著名的是Google开源的 gRPC 框架,下面来谈一谈它的原理。
二、概述
- protobuf将消息里的每个字段进行编码后,再利用T-L-V或者T-V的方式进行数据存储。
- protobuf对于不同类型的数据会使用不同的编码和存储方式。
- protobuf的编码和存储方式是其性能优越、数据体积小的原因。
所以问题也就很明确了,只需要了解对于不同的数据类型,protobuf是怎么编码的,怎么存储的就可以了。
三、数据存储方式:Varints
(一)原理
Varints是一个变长保存数据的方法,在C++中一个整型数字通常使用4个字节来保存即int类型。但是对于Varints来说,小于128的数字可以使用一个字节来表示,而大于128的数字才会使用多个字节来表示。
下面来讲解它是怎么约束的:
在Varints编码中,它的每个字节的最高比特位有一定的含义,如果是1的话那么表示它后面的字节也是该数字的一部分,剩余的其他7个比特位才代表数字,这个思想和IP报文的分片挺相似的。所以就很容易理解为什么小于128的数字可以使用一个字节来表示了,因为第一位被占用了。
(二)举例
举两个例子:
表示65这个数字:

此时第一位为0,表示下面的字节和这个字节表示的数字不是同一个数字了。
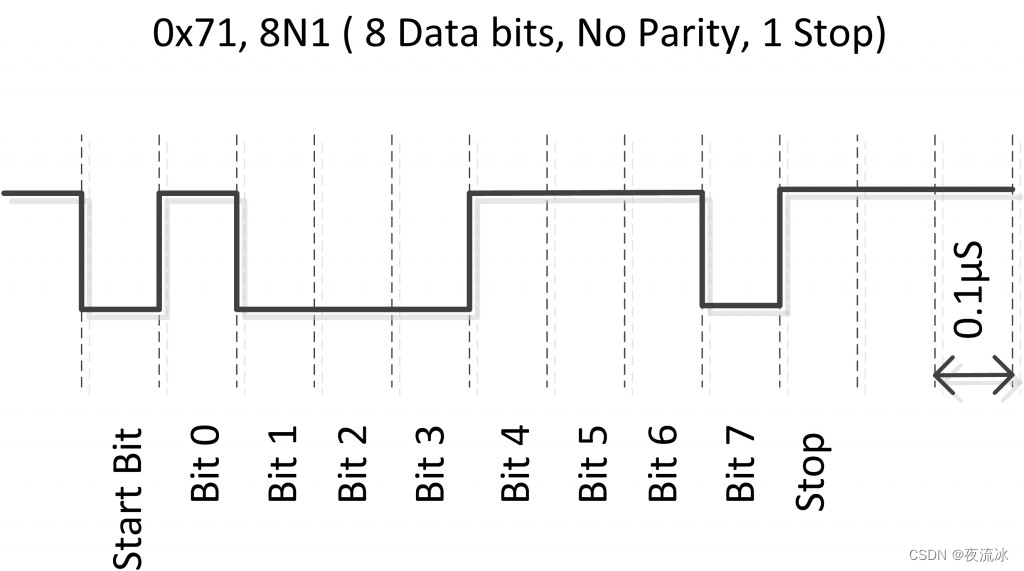
表示300这个数字:
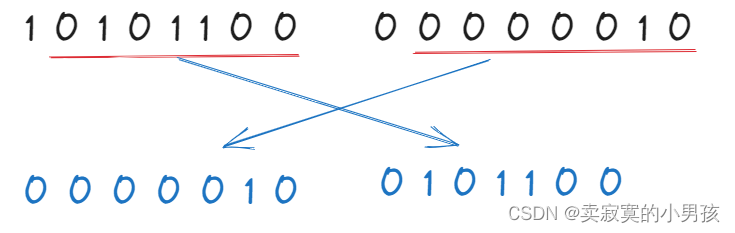
这里使用的是大端存储,高位低地址,低位高地址。第一个字节为1,表示它下一个字节存的数字和当前存的数字是同一个数字。
(三)缺点
这种存储方式对于小的数字比较友好,可以使用更少的字节数去存储,但对于大的数字就不太友好了。有的数字可能4个字节就可以搞定被生生存了5个字节。所以在protobuf中使用更小的数字才是效率更高的。
在协议的数据结构中,key使用的是varint编码,因此索引字段从1开始而不是负数,因为负数存的是补码通常占位比较多,影响了效率。
四、协议的数据结构
(一)原理
消息在经过序列化后会形成一个二进制数据流,流中数据为一系列的K-V对,Value怎么存上面已经介绍过了,这里介绍Key。
首先我们需要明确的是protobuf要存什么,一个是数据,也就是value,一个是key也就是索引字段,当我们使用protobuf定义一个message的时候通常是这样的:
message mystruct
{
int32 a=1;
int32 b=2;
}
其中1和2表示的是索引字段,它们具体的值就是value。
key除了作为value的索引之外,还需要指定value的编码格式,注意这里key使用的是varint的编码格式,但是不代表数据就使用该格式。
key值的计算公式为: (field_number << 3) | wire_type,其中field_number为索引字段,wire_type表示的是数据的格式,它的格式分五种:
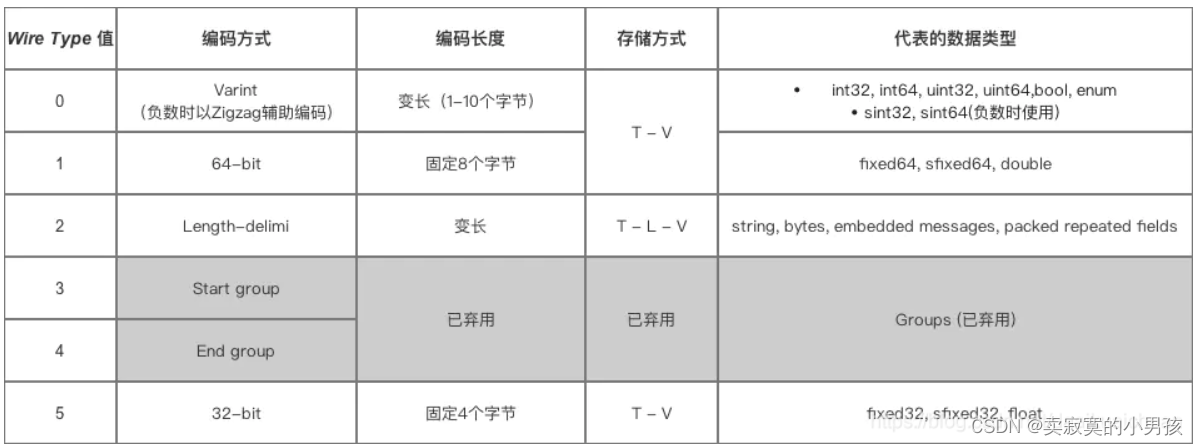
其实就只有五种,所以我们就知道了为什么它向左移动三位来为存放数据类型腾出空间。
(二)举例
举一个简单的例子:
message Test1 {
required int32 a = 1;
}
通过查表可以知道,int32类型即该字段是使用varint编码格式来存储的,所以计算key为:
(1<<3)|0
同时由于存储key使用的是varint编码,因此第一位为结束符,这里的索引使用一个字节就可以了,因此结束符是0:
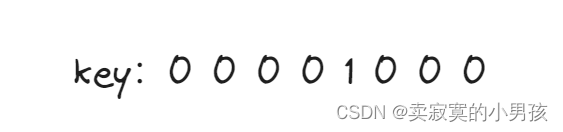
假设要传入的a的值是1,则a使用varint编码表示为:
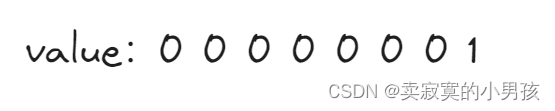
此时就弄出来了一个字段的kv结构。而一个message有很多个字段,它们的排列是线性的: