1.数据模型
数据模型 - Apache Doris
1.1 Aggregate 模型(聚合)
可以发现,user_id、date、age ...等没有设置 AggregationType, 那么这几个字段就成了一个key了。设置了 AggregationType 字段,说明该列的属性已经成value了。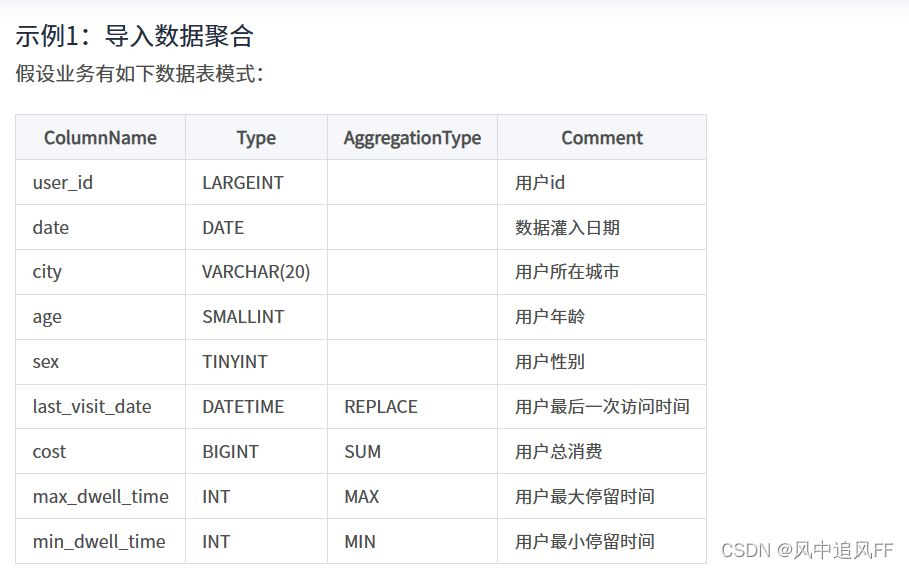
我们导入一张表
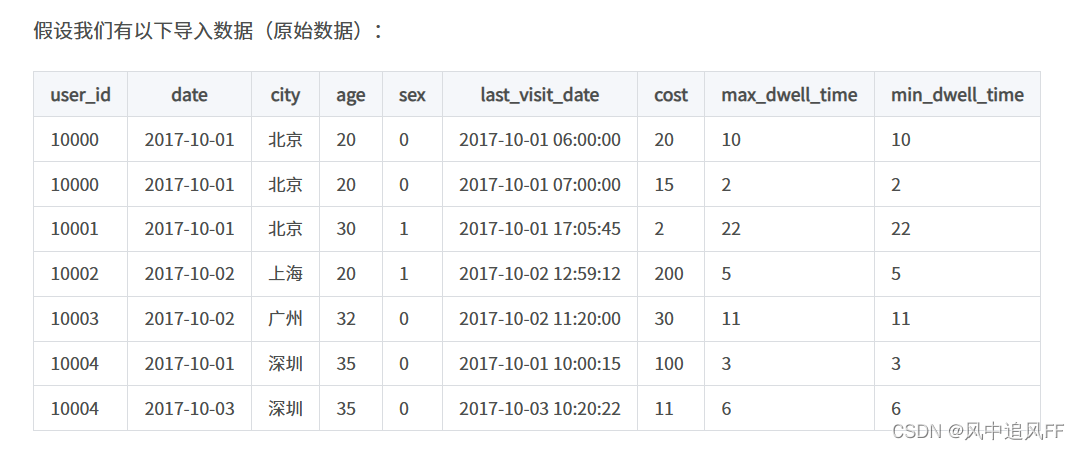
它在doris里实际存储为:
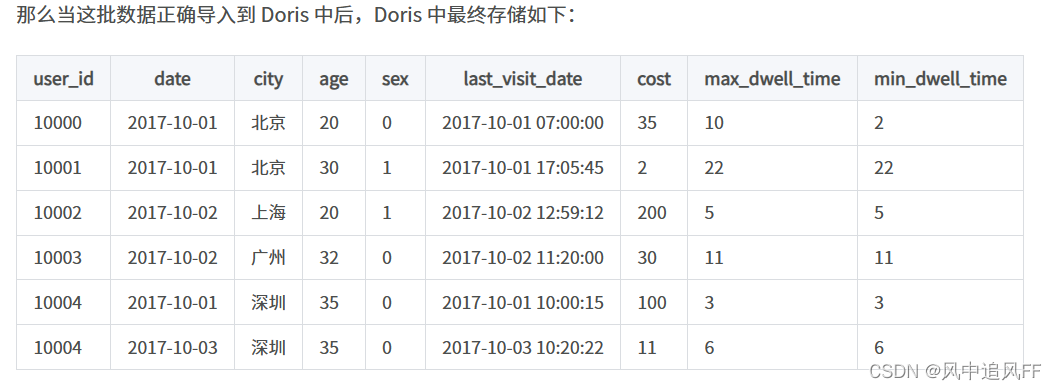
具体流程为:前两条记录属于是一个key(user_id、date、age 的值一样,就要合并这两条记录),然后cost选取的sum类型的。所以聚合结果就为35
1.1.1 在聚合模型下保存明细数据
可以通过 精细key里某个列属性来保存完成的。
比如加了一个精细的时间戳。

这样合并的就少了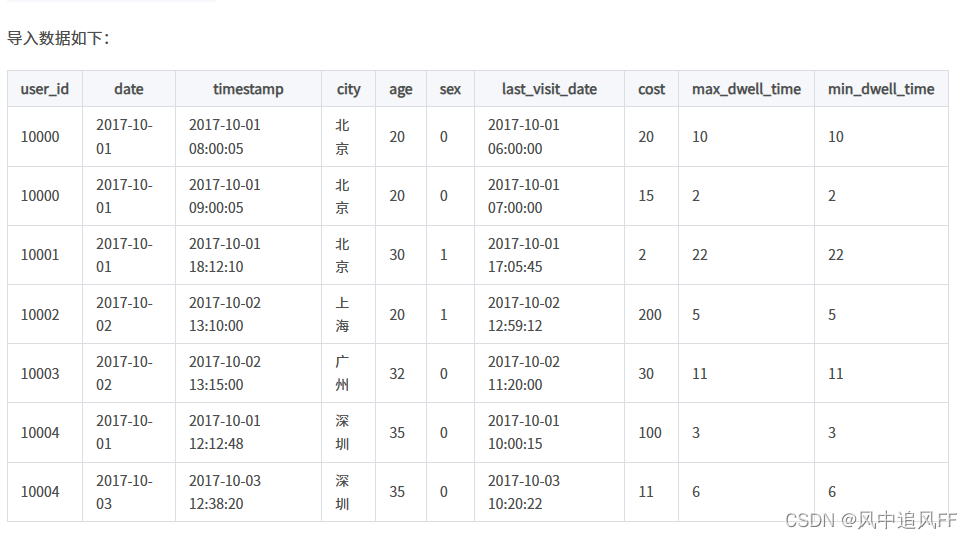
1.1.2 导入数据与已有数据合并
在用户的眼里,数据都是聚集成最后阶段的。
但在Doris的过程的不同阶段中,数据的聚集程度是不同德。
1.一批一批的聚合。
2.底层开始对这些不同批的聚合。
3.在最终查询阶段,会对涉及的数据,再进行最终的聚合。

1.2 unique模型
在某些多维的分析场景下,我们希望key是唯一的。
1.2.1 读时合并
在每次读的时候合并。
在1.2版本之前,该模型本质上是聚合模型的一个特例,也是一种简化的表结构表示方式。由于聚合模型的实现方式是读时合并(merge on read),因此在一些聚合查询上性能不佳(参考后续章节聚合模型的局限性的描述)。

建表语句
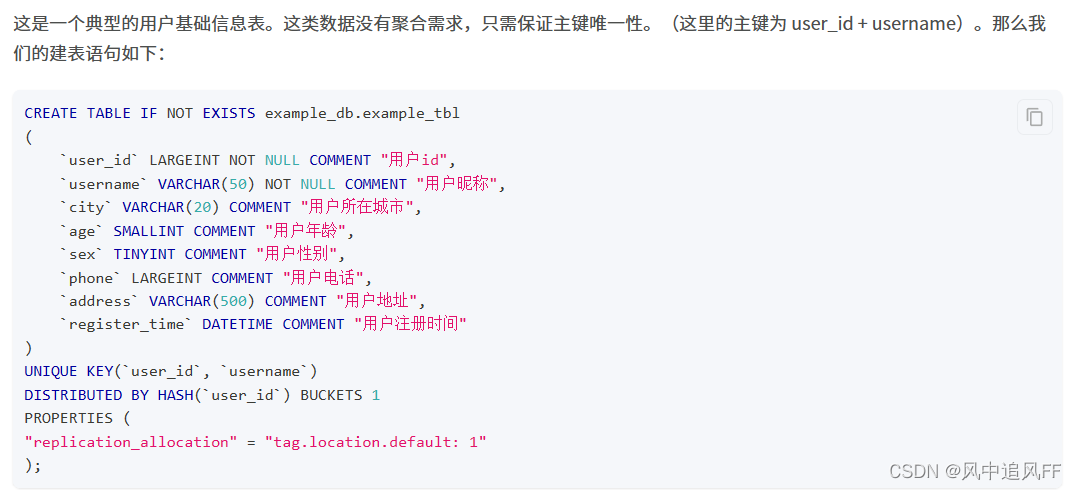
相当于聚合类型。
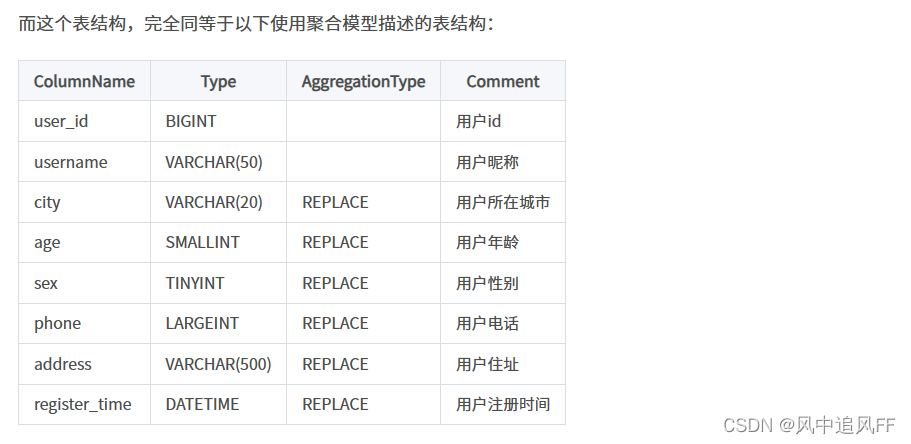
其建表语句为

1.2.2 写时合并
在每次写的时候合并

1.2.3 读时合并升级成写时合并