- 一、栈的多重含义
- 1.1 硬件栈
- 1.2 运行时栈
- 1.3 软件栈
- 1.4 技术栈
- 1.5 TCP/IP协议栈
- 二、数据结构中的栈
- 2.1 概念
- 2.2 栈的操作
- 2.3 数组栈(顺序栈)
- 2.31 数组栈特性
- 2.32 C语言实现
- ▶ 静态数组栈
- ▶ 动态数组栈
- 2.4链式栈
- 2.41 链式栈特性
- 2.42 C语言实现
- 三、进阶
- 3.1 块栈
- 3.2 双端栈
- 3.21 定义
- 3.22 C语言实现
- 3.3 并行栈
- 3.4 应用——括号匹配
- 完整示例:
一、栈的多重含义
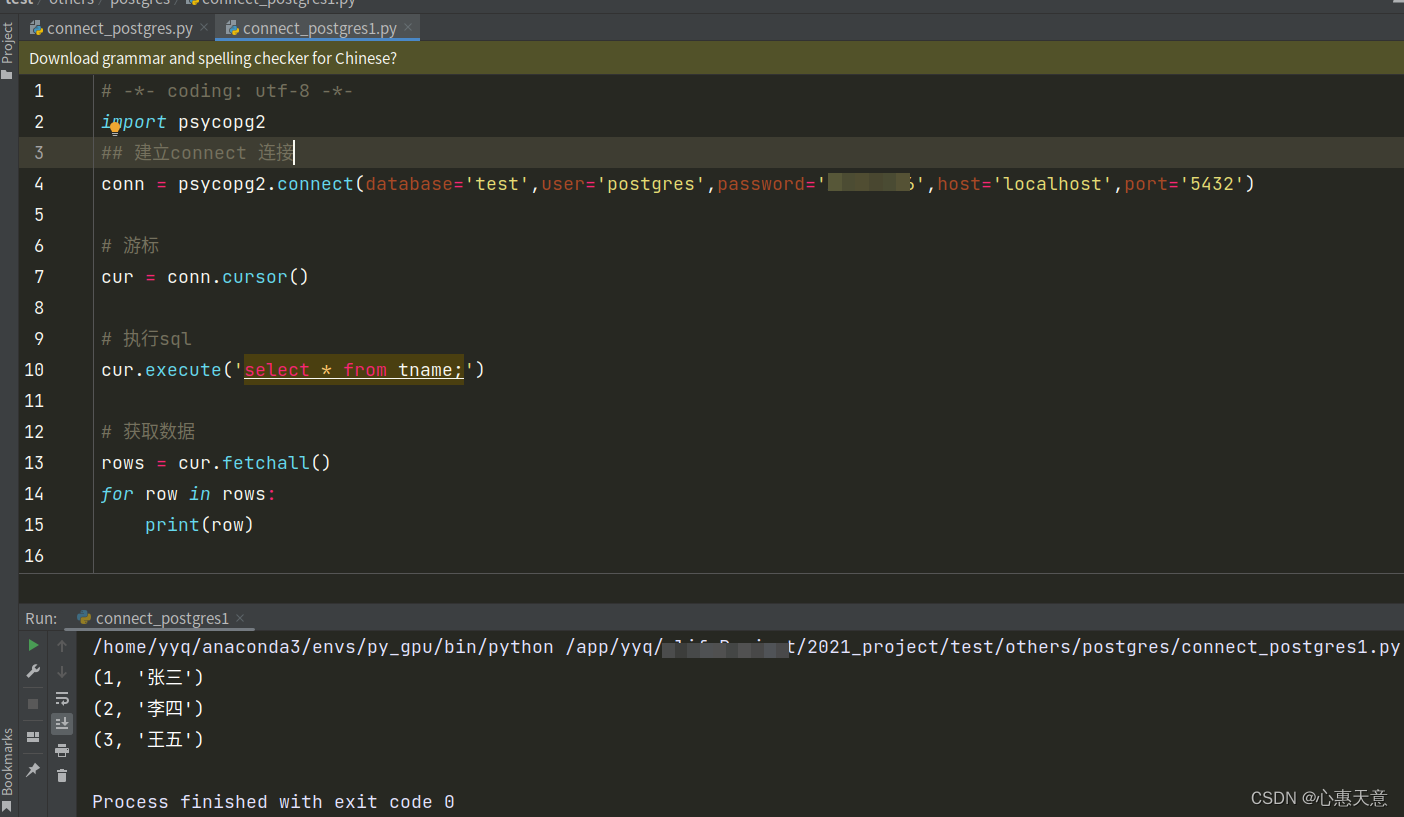
说到栈,最先想到的可能是数据结构中的那个先进后出的栈。
但你也听过一些其他的 “栈”:栈帧、硬件栈、软件栈、技术栈、协议栈…
"栈"这个词在很多领域中被使用,主要是因为栈的概念和特性在计算机科学和其他领域中具有普遍适用性和重要性。
下面挑几个“栈”简单介绍一下。
1.1 硬件栈
硬件栈(Hardware Stack)指的是计算机体系结构中的特定内存区域,通常位于处理器(CPU)的内部。它用于存储程序执行过程中的状态信息、返回地址以及函数调用和中断处理的上下文。
硬件栈是由处理器硬件提供的一块专用的内存区域,用于支持函数调用、中断处理和指令执行过程中的状态保存和恢复。它通常是在处理器的寄存器文件(Register File)中实现的,其中有一个指针寄存器(通常称为栈指针,Stack Pointer)用于指示当前栈顶的位置。
当函数调用发生时,处理器会将返回地址、函数参数以及其他相关的寄存器状态压入硬件栈中,以便在函数执行完毕后能够恢复到调用点。类似地,当中断发生时,处理器会将中断处理程序的返回地址和现场保存信息推入硬件栈中。
硬件栈的大小和组织方式取决于特定的处理器架构和设计。它在底层的计算机体系结构中起到重要的作用,支持程序的执行和控制流的管理。
硬件栈是与处理器硬件紧密相关的概念,而运行时栈(
Runtime Stack)则是在软件层面上实现的,由编程语言和操作系统的运行时系统管理。运行时栈利用硬件栈提供的支持来实现函数调用和局部变量的管理。
硬件栈的功能包括:
- 存储返回地址:当函数被调用时,当前执行指令的地址会被保存到硬件栈中。这样,当函数执行完成后,程序可以从栈中取回返回地址,继续执行调用函数的位置。
- 保存寄存器状态:硬件栈用于保存当前函数的寄存器状态,以便在函数执行完成后能够恢复到调用函数的状态。这样可以确保函数调用过程不会破坏调用者的寄存器值。
- 分配临时数据空间:硬件栈可以用于临时存储函数执行过程中需要的局部变量和临时数据。这些数据可以在函数执行期间被反复使用,而不需要额外的内存分配操作。
1.2 运行时栈
运行时栈(Runtime Stack)是计算机程序在执行过程中用于管理函数调用和局部变量(堆主要用于存储动态分配的对象和数据结构,如malloc、calloc)的一种数据结构。它是在程序的运行时环境中创建和维护的。
运行时栈由编程语言和操作系统的运行时系统(Runtime System)管理。它通常位于程序的内存空间中,并且在程序执行期间动态地增长和收缩。运行时栈使用一种称为栈帧(Stack Frame)的数据结构来表示函数的执行环境和局部变量。
下面是运行时栈的一些关键特性和功能:
-
函数调用:当一个函数被调用时,运行时栈会为该函数创建一个新的栈帧,并将其添加到栈的顶部。栈帧包含了函数的参数、返回地址、局部变量以及其他与函数执行相关的信息。这样,程序可以顺序执行函数调用,并在函数执行完成后按照相反的顺序返回。
-
栈帧结构:栈帧通常包含以下重要的组成部分:
- 返回地址:指向函数调用点的地址,用于在函数执行完成后返回到调用点。
- 参数和局部变量:用于存储函数的参数值和局部变量的值。
- 临时数据:用于存储函数执行过程中的临时数据,如临时变量、中间计算结果等。
- 上下文信息:保存函数执行过程中的其他上下文信息,如异常处理信息、状态标志等。
-
层次结构:运行时栈具有层次结构,每个栈帧代表一个函数的执行环境。当函数调用嵌套时,每个新的函数调用都会创建一个新的栈帧,形成栈的嵌套结构。这种层次结构使得函数调用可以按照嵌套的顺序进行,确保正确的函数返回顺序。
-
局部变量的生命周期管理:运行时栈用于存储函数的局部变量,这些变量的生命周期与函数调用的生命周期相对应。当函数调用结束时,对应的栈帧会被弹出,局部变量的内存空间会被释放。
-
递归调用支持:运行时栈也支持递归函数调用。当一个函数调用自身时,会创建一个新的栈帧,使得递归调用可以进行。递归的结束条件通常是通过一定的终止条件来判断。
1.3 软件栈
Software stack(软件栈)是指由一系列相互关联的软件组件组成的堆叠结构。它包含了在特定领域或应用程序中所需的软件层次结构和组件,用于实现特定的功能或提供特定的服务。

软件栈通常由多个层次组成,每个层次负责不同的功能或任务。每个层次的软件组件都构建在底层的组件之上,形成了一种嵌套的结构。
下面是一个示例软件栈的层次结构:
- 应用层:位于软件栈的顶部,包含特定应用程序或服务的逻辑和用户界面。
- 应用框架层:提供了开发应用程序所需的工具、库和框架。这些组件可以简化应用程序开发过程并提供常见功能,例如图形界面、网络通信等。
- 运行时环境层:包含操作系统和其他运行时库。它提供了底层的系统资源管理、进程调度、内存管理等功能,为上层应用程序提供运行环境。
- 中间件层:提供了一些通用的功能和服务,例如数据库访问、消息传递、身份验证等。中间件层通常用于连接应用程序和底层系统资源。
- 操作系统层:负责管理计算机系统的硬件资源和提供底层的系统功能。它包括操作系统内核、驱动程序和底层系统服务。
- 硬件层:表示计算机系统的实际硬件组件,包括处理器、内存、存储器、输入输出设备等。
软件栈的层次结构可以根据具体应用领域和需求而有所不同。不同的软件栈可以针对不同的应用场景和平台进行优化,以满足特定需求和提供所需的功能。
1.4 技术栈
技术栈(Tech Stack)是指在开发和实现软件应用程序时所使用的一组技术、工具和框架的集合。它代表了开发者在特定项目中所选择的技术堆叠,用于实现特定的功能或解决特定的问题。
技术栈通常包括以下组成部分:
- 编程语言:选择一种或多种编程语言作为开发的基础,如Java、Python、JavaScript等。
- 后端框架:用于开发服务器端应用程序的框架,如Django、Ruby on Rails、Spring等。
- 前端框架:用于开发用户界面的框架,如React、Angular、Vue.js等。
- 数据库:用于存储和管理数据的数据库系统,如MySQL、PostgreSQL、MongoDB等。
- 服务器环境:选择用于部署和运行应用程序的服务器环境,如Apache、Nginx等。
- 版本控制系统:用于管理和追踪代码版本的系统,如Git。
- 开发工具和集成开发环境(IDE):用于编写、测试和调试代码的工具,如Visual Studio Code、IntelliJ IDEA等。
- 前端样式和布局:用于设计和实现用户界面的样式和布局工具,如CSS、Bootstrap等。
- 部署和自动化工具:用于自动化部署和管理应用程序的工具,如Docker、Jenkins等。
技术栈的选择取决于具体的项目需求、开发者的技能和偏好以及可用资源等因素。不同的技术栈组合可以用于不同的应用类型,例如Web开发、移动应用开发、数据分析等。选择合适的技术栈能够提高开发效率、减少开发成本,并满足项目的需求和目标。
1.5 TCP/IP协议栈
TCP/IP协议栈是一组用于网络通信的协议集合,它是互联网的核心通信协议。TCP/IP(Transmission Control Protocol/Internet Protocol)协议栈定义了数据在网络中的传输和通信方式,它提供了可靠的数据传输、数据分段、路由和地址分配等功能。
TCP/IP协议栈由多个层次构成,每个层次都负责不同的功能。这些层次通常按照自下而上的顺序组织,包括以下主要层次:
- 物理层(Physical Layer):负责传输原始比特流,处理电信号、光信号或无线信号等。
- 数据链路层(Data Link Layer):在直接相连的节点之间传输数据,通过物理地址(MAC地址)进行识别和访问。
- 网络层(Network Layer):提供网络互连和路由功能,将数据从源节点传输到目标节点。其中,最常见的协议是Internet协议(IP),用于定义数据包的寻址和路由。
- 传输层(Transport Layer):负责可靠的端到端数据传输。最常见的协议是传输控制协议(TCP),它提供面向连接、可靠的数据传输,用于应用程序之间的数据交换。另外还有用户数据报协议(UDP),它提供无连接、不可靠的数据传输。
- 应用层(Application Layer):提供各种应用程序使用的协议和服务,例如HTTP、FTP、SMTP等。这些协议构建在底层的协议上,实现特定的应用功能。
TCP/IP协议栈是互联网上数据传输和通信的基础,它允许不同的设备和应用程序能够相互通信和交换数据。通过TCP/IP协议栈,计算机可以在全球范围内进行互联网连接,实现电子邮件、网页浏览、文件传输和即时通信等各种网络应用。
二、数据结构中的栈
2.1 概念
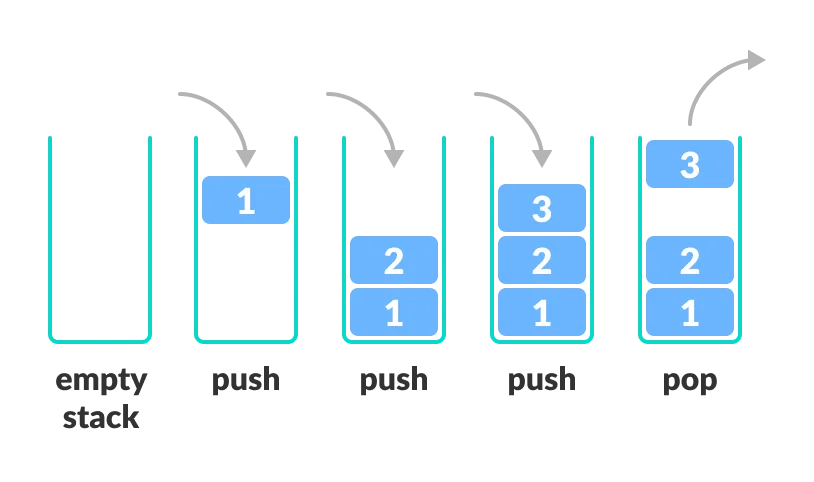
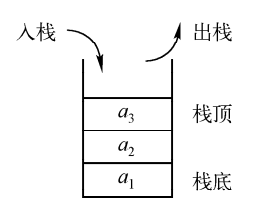
在数据结构中,栈(Stack)是一种线性数据结构,它按照先进后出(Last-In-First-Out,LIFO)的原则进行操作。
栈中的元素在插入和删除时只能在一端进行,这一端通常被称为栈顶(Top),另一端被称为栈底(Bottom)。
在编程中,栈的应用可以有:
- 表达式求值,如:中缀表达式转后缀表达式,然后利用后缀表达式进行计算。
- 缓冲区管理,如:字符串的拷贝、反转和匹配等操作可以使用栈来实现。
- 递归算法:递归是一种算法的编程技巧,其中函数可以调用自身。递归算法的实现通常使用栈来管理每次递归调用的状态。
- 临时变量的存储:在函数中,局部变量和临时变量通常被存储在栈上。当函数被调用时,局部变量的存储空间会被分配在栈上,函数执行完毕后,这些变量的空间会被释放。
- 函数调用和返回。
2.2 栈的操作
栈的主要操作包括两个核心操作:
-
入栈(
Push):将元素添加到栈顶。 -
出栈(
Pop):从栈顶移除元素。
栈还支持其他一些辅助操作,包括:
- 栈顶元素访问(Peek):获取栈顶元素的值,但不对栈进行修改。
- 栈的大小查询(Size):获取栈中元素的个数。
- 判空(Empty):检查栈是否为空。
栈可以通过数组或链表来实现。使用数组实现的栈称为数组栈,使用链表实现的栈称为链式栈。
2.3 数组栈(顺序栈)
2.31 数组栈特性
数组栈(Array Stack)是一种使用数组实现的栈数据结构。它利用数组的特性来存储和管理栈中的元素。数组栈的主要特点是固定大小和连续存储。
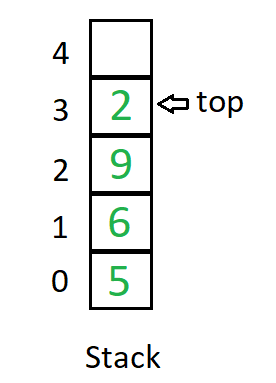
下面是数组栈的一些关键特性和操作:
- 固定大小:数组栈在创建时需要指定一个固定的大小(容量),即能容纳的最大元素数量。这是因为数组在内存中是连续分配的,大小固定,无法动态调整。
- 栈顶指针:使用一个指针来指示数组栈的栈顶位置。初始时,栈顶指针通常设置为-1,表示栈为空。随着元素的入栈和出栈操作,栈顶指针会相应地移动。
- 入栈操作:将元素插入到栈顶位置。入栈操作首先检查栈是否已满,即栈顶指针是否达到了数组的末尾。如果栈未满,则栈顶指针递增,然后将元素存储在新的栈顶位置。
- 出栈操作:从栈顶位置移除元素。出栈操作首先检查栈是否为空,即栈顶指针是否为-1。如果栈非空,则返回栈顶元素的值,然后栈顶指针递减。
- 栈空检查:检查栈是否为空,即栈顶指针是否为-1。如果栈顶指针为-1,则表示栈为空。
- 栈满检查:检查栈是否已满,即栈顶指针是否达到了数组的末尾。如果栈顶指针等于数组的容量减1,则表示栈已满。
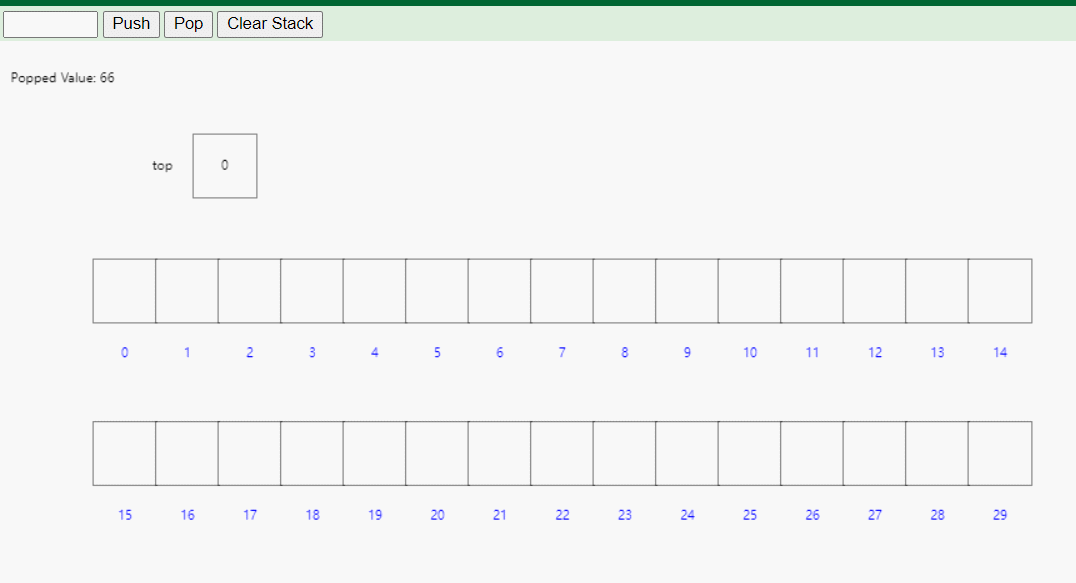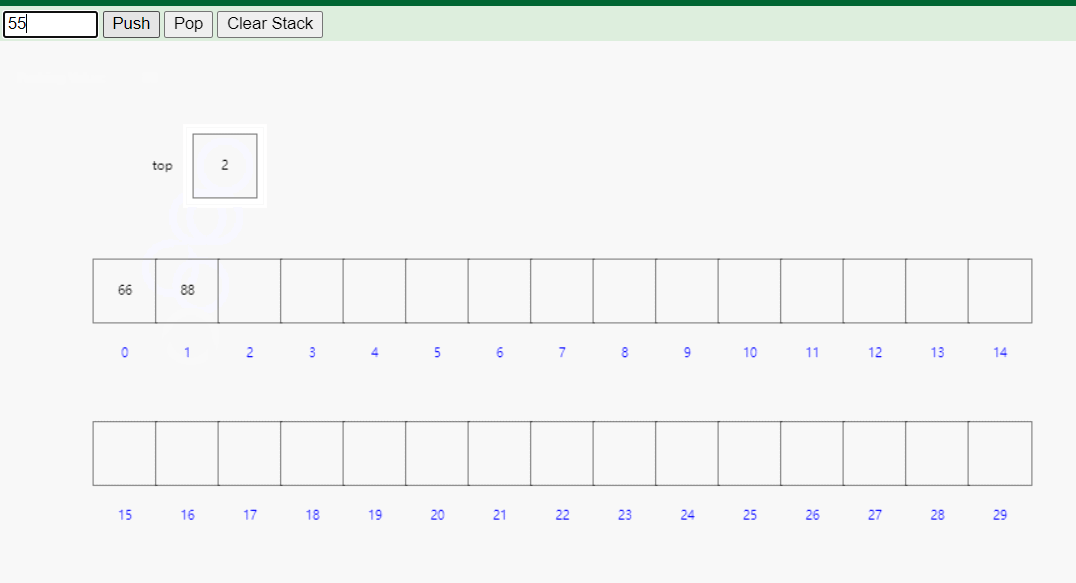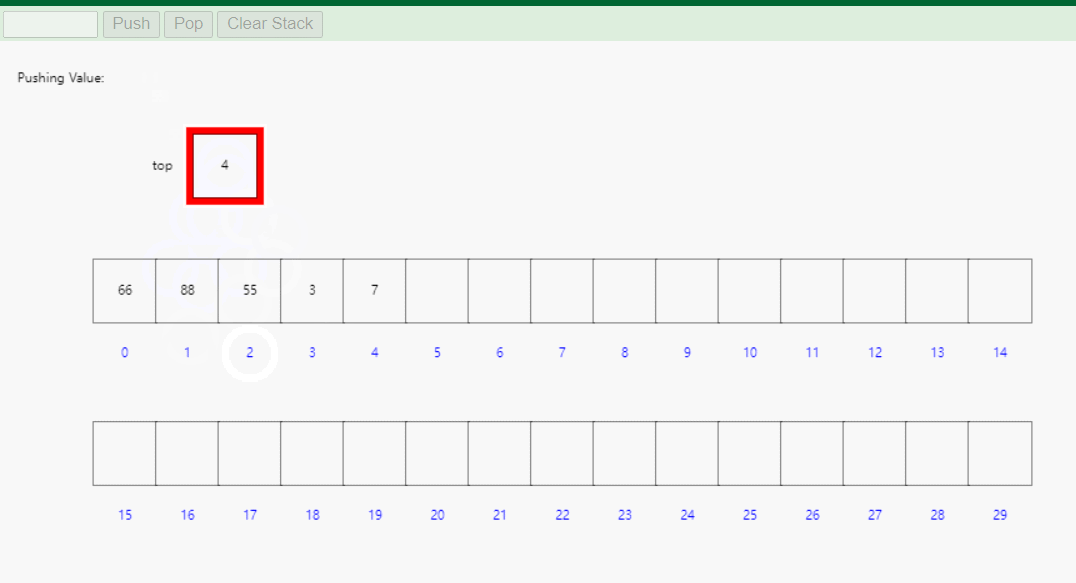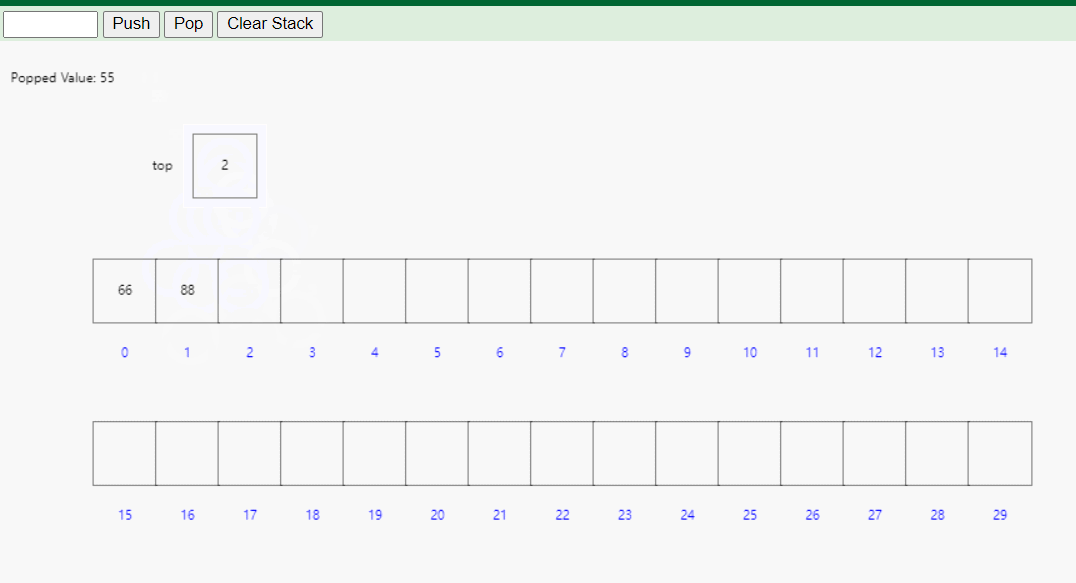
数组栈的优点包括实现简单、访问速度快、不需要额外的内存分配等。然而,它的缺点是容量固定,无法动态扩展,当栈元素数量超过容量时会导致溢出(静态数组栈)。
在C语言中,数组栈可以通过静态数组或动态分配的数组来实现。静态数组栈在编译时就确定了大小,而动态数组栈可以根据需要在运行时动态分配内存。
2.32 C语言实现
▶ 静态数组栈
// 数组栈,静态
#include <stdio.h>
#define MAX_SIZE 100
typedef struct {
int data[MAX_SIZE]; // 数组栈
int top; // 栈顶 指针(等于数组元素下标,-1表示空)
} ArrayStack;
void initStack(ArrayStack* stack) {
stack->top = -1; // 初始化栈顶指针为-1,表示栈为空
}
int isEmpty(ArrayStack* stack) {
return stack->top == -1; // 栈顶指针为-1表示栈为空
}
int isFull(ArrayStack* stack) {
return stack->top == MAX_SIZE - 1; // 栈顶指针等于最大容量减1表示栈已满
}
void push(ArrayStack* stack, int item) {
if (isFull(stack)) {
printf("Stack is full. Cannot push item %d.\n", item);
} else {
stack->data[++stack->top] = item; // 将元素入栈,并将栈顶指针加1
printf("Pushed item %d.\n", item);
}
}
int pop(ArrayStack* stack) {
if (isEmpty(stack)) {
printf("Stack is empty. Cannot pop item.\n");
return -1; // 返回一个特殊值表示栈为空
} else {
int item = stack->data[stack->top--]; // 栈顶元素出栈,并将栈顶指针减1
printf("Popped item %d.\n", item);
return item; // 返回出栈的元素值
}
}
// 取栈顶元素,并不弹出栈顶元素
int peek(ArrayStack* stack) {
if (isEmpty(stack)) {
printf("Stack is empty. Cannot peek.\n");
return -1; // 返回一个特殊值表示栈为空
} else {
return stack->data[stack->top]; // 返回栈顶元素的值
}
}
int main() {
ArrayStack stack;
initStack(&stack);
push(&stack, 10);
push(&stack, 20);
push(&stack, 30);
int topItem = peek(&stack);
printf("Top item: %d\n", topItem);
pop(&stack);
pop(&stack);
pop(&stack);
pop(&stack); // 出栈空栈
return 0;
}
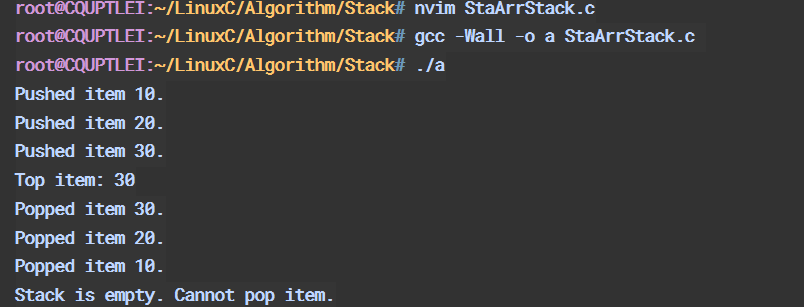
▶ 动态数组栈
动态分配内存大小,借助realloc函数,重新分配内存。
// 数组栈,动态
#include <stdio.h>
#include <stdlib.h>
typedef struct {
int* data; // 数据
int top; // 栈顶指针
int capacity; // 初始容量
} ArrayStack;
void initStack(ArrayStack* stack, int capacity) {
stack->data = (int*)malloc(capacity * sizeof(int));
stack->top = -1;
stack->capacity = capacity;
}
int isEmpty(ArrayStack* stack) {
return stack->top == -1;
}
int isFull(ArrayStack* stack) {
return stack->top == stack->capacity - 1;
}
void push(ArrayStack* stack, int item) {
if (isFull(stack)) {
// 动态调整容量
stack->capacity *= 2;
stack->data = (int*)realloc(stack->data, stack->capacity * sizeof(int));
}
stack->data[++stack->top] = item;
printf("Pushed item %d.\n", item);
}
int pop(ArrayStack* stack) {
if (isEmpty(stack)) {
printf("Stack is empty. Cannot pop item.\n");
return -1;
}
int item = stack->data[stack->top--];
printf("Popped item %d.\n", item);
// 动态调整容量
if (stack->top + 1 <= stack->capacity / 4) {
stack->capacity /= 2;
stack->data = (int*)realloc(stack->data, stack->capacity * sizeof(int));
}
return item;
}
int peek(ArrayStack* stack) {
if (isEmpty(stack)) {
printf("Stack is empty. Cannot peek.\n");
return -1;
}
return stack->data[stack->top];
}
void freeStack(ArrayStack* stack) {
free(stack->data);
}
int main() {
int capacity = 2;
ArrayStack stack;
initStack(&stack, capacity);
push(&stack, 10);
push(&stack, 20);
push(&stack, 30);
int topItem = peek(&stack);
printf("Top item: %d\n", topItem);
pop(&stack);
pop(&stack);
pop(&stack);
pop(&stack);
freeStack(&stack);
return 0;
}
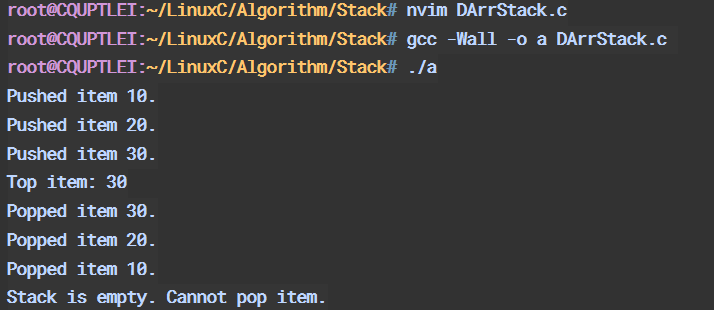
2.4链式栈
2.41 链式栈特性
链式栈(Linked List Stack)是一种使用链表实现的栈数据结构。与静态数组实现的顺序栈不同,链式栈的内存分配是动态的,可以根据实际需要进行扩展或缩减。
下面是链式栈的一些详细介绍:
-
结构:链式栈由一个链表组成,每个节点包含两部分数据:存储的元素值和指向下一个节点的指针。
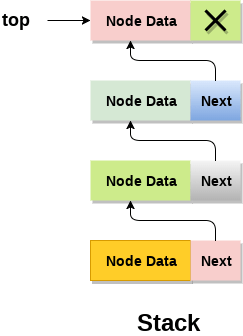
-
操作:链式栈主要支持以下几个操作:
- 入栈(Push):在栈顶插入一个新元素。
- 出栈(Pop):移除栈顶的元素,并返回该元素的值。
- 获取栈顶元素(Top):返回栈顶元素的值,但不移除该元素。
- 判空(IsEmpty):检查栈是否为空。
- 清空栈(Clear):移除栈中的所有元素。
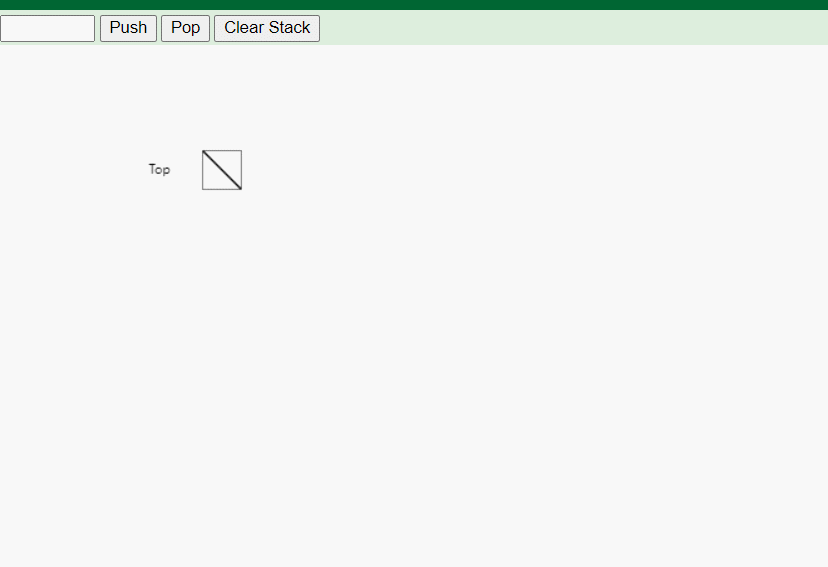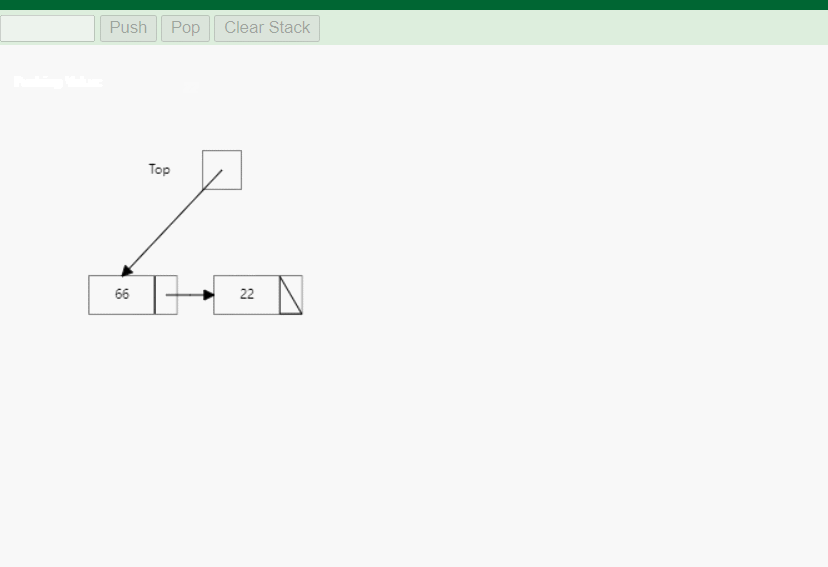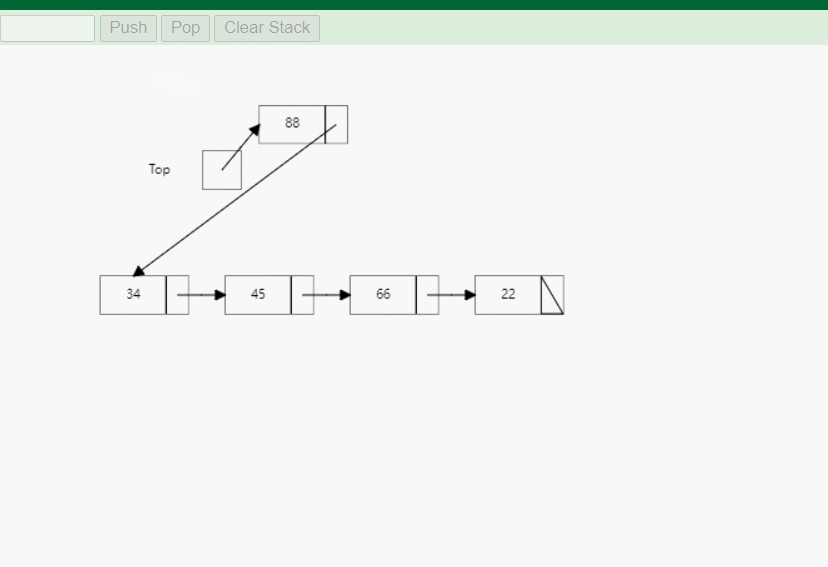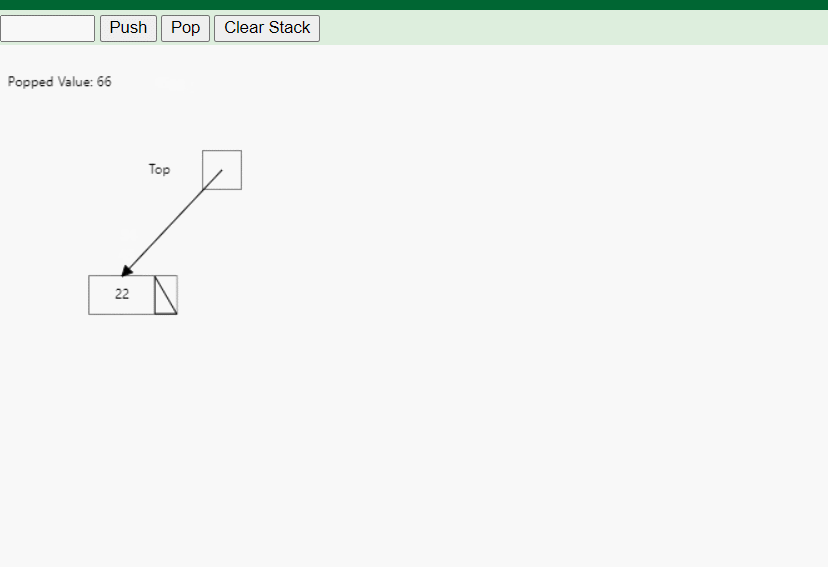
-
实现:链式栈的实现基于链表的插入和删除操作。入栈操作将新元素插入链表的头部,而出栈操作则删除链表的头节点。由于链表的动态特性,链式栈可以灵活地增加或减少容量,不会出现栈溢出的情况。
-
时间复杂度:链式栈的入栈、出栈、获取栈顶元素、判空等基本操作的平均时间复杂度都是O(1),即常数时间。这是因为在链表的头部进行插入和删除操作时,无需移动其他元素。
需要注意的是,链式栈相对于顺序栈的一个缺点是,它需要额外的指针来存储节点之间的链接关系,因此在存储上可能会占用更多的内存空间。此外,由于链式栈使用了动态内存分配,可能会涉及到内存管理的复杂性和性能开销。
链式栈是一种灵活的栈实现方式,适用于需要动态调整容量的场景,同时提供了常数时间复杂度的基本操作。
2.42 C语言实现
// 链式栈
#include <stdio.h>
#include <stdlib.h>
// 定义链式栈的节点结构
typedef struct Node {
int data; // 存储的元素值
struct Node* next; // 指向下一个节点的指针
} Node;
// 定义链式栈结构
typedef struct {
Node* top; // 栈顶指针
} Stack;
// 初始化链式栈
void initStack(Stack* stack) {
stack->top = NULL;
}
// 判断链式栈是否为空
int isEmpty(Stack* stack) {
return stack->top == NULL;
}
// 入栈
void push(Stack* stack, int value) {
Node* newNode = (Node*)malloc(sizeof(Node)); // 创建新节点
newNode->data = value;
newNode->next = stack->top; // 新节点指向当前栈顶
stack->top = newNode; // 更新栈顶指针
}
// 出栈
int pop(Stack* stack) {
if (isEmpty(stack)) {
printf("Stack is empty.\n");
return -1;
}
int value = stack->top->data; // 保存栈顶元素的值
Node* temp = stack->top; // 保存栈顶节点的指针
stack->top = stack->top->next; // 更新栈顶指针
free(temp); // 释放原栈顶节点的内存
return value;
}
// 获取栈顶元素的值
int top(Stack* stack) {
if (isEmpty(stack)) {
printf("Stack is empty.\n");
return -1;
}
return stack->top->data;
}
// 清空栈
void clear(Stack* stack) {
while (!isEmpty(stack)) {
pop(stack);
}
}
// 测试链式栈
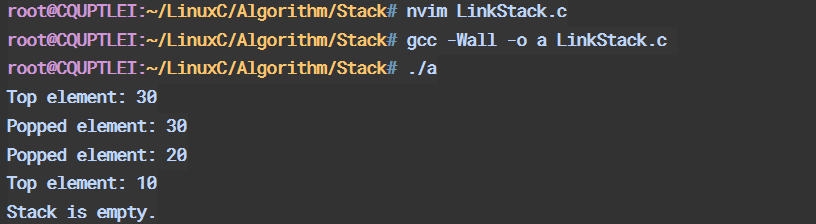
int main() {
Stack stack;
initStack(&stack);
push(&stack, 10);
push(&stack, 20);
push(&stack, 30);
printf("Top element: %d\n", top(&stack));
printf("Popped element: %d\n", pop(&stack));
printf("Popped element: %d\n", pop(&stack));
printf("Top element: %d\n", top(&stack));
clear(&stack);
if (isEmpty(&stack)) {
printf("Stack is empty.\n");
}
return 0;
}
三、进阶
3.1 块栈
块栈(Block Stack)是一种栈的实现方式,它使用链表的块状存储来减少指针的使用和内存分配的次数。块栈相对于普通链式栈,在内存分配和释放上具有一定的优势。
-
结构:块栈由一个或多个块(Block)组成,每个块包含多个节点。每个节点包含两部分数据:存储的元素值和指向下一个节点的指针。每个块通过指针链接起来,形成一个链表结构。
-
块状存储:与普通链式栈不同,块栈的内存分配是以块为单位进行的。每个块内部存储多个节点,减少了节点间的指针数量和内存分配次数,提高了内存的利用率。块栈的块大小可以根据实际需要进行配置,通常选择一个适当的块大小以平衡空间和时间开销。
-
块栈操作:块栈支持与链式栈相同的基本操作,包括入栈(Push)、出栈(Pop)、获取栈顶元素(Top)、判空(IsEmpty)和清空栈(Clear)等。这些操作在块栈的块内进行,只需要在块内部进行指针的修改和元素的读写操作,而不需要频繁的内存分配和释放操作。
-
内存管理:块栈的内存管理相对于链式栈来说更加高效。块栈可以预先分配一定数量的块,并使用一个空闲块列表来管理未使用的块。当需要扩展栈时,可以直接从空闲块列表中获取块,而无需进行频繁的内存分配。当块栈不再需要某些块时,可以将这些块添加到空闲块列表中,以便后续的重复利用。
块栈通过使用块状存储和空闲块列表来减少指针的使用和内存分配的次数,从而提高了内存的利用率和性能。它适用于需要频繁的入栈和出栈操作,以及对内存管理有一定要求的场景。然而,块栈的实现可能相对复杂一些,需要管理块的分配和释放,以及块内节点的管理。
3.2 双端栈
3.21 定义
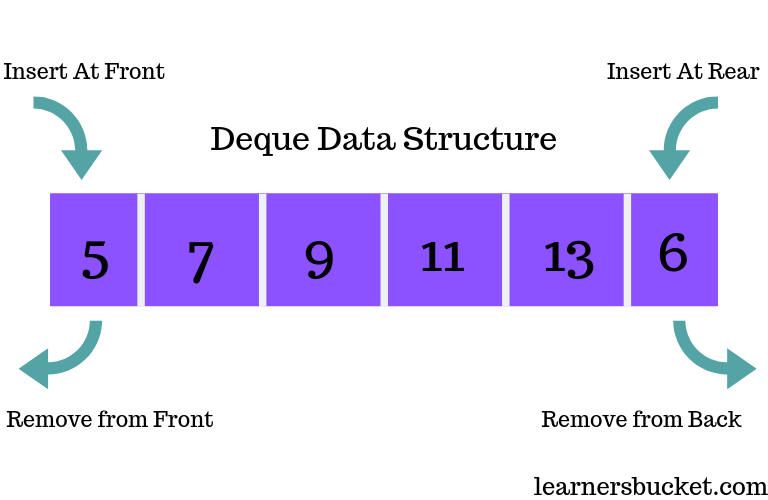
双端栈(Deque),也称为双向栈(Double-ended Stack),是一种支持在两端进行入栈和出栈操作的栈实现。它可以从栈的头部(前端)或尾部(后端)插入或删除元素,具有更灵活的操作方式。
-
结构:双端栈的底层数据结构可以是数组或链表。使用数组实现时,可以使用两个指针来分别指向双端栈的头部和尾部。使用链表实现时,每个节点包含两个指针,一个指向前一个节点,一个指向后一个节点。
-
操作:双端栈支持以下几个基本操作:
- 从头部入栈(PushFront):在双端栈的头部插入一个新元素。
- 从尾部入栈(PushBack):在双端栈的尾部插入一个新元素。
- 从头部出栈(PopFront):移除双端栈的头部元素,并返回该元素的值。
- 从尾部出栈(PopBack):移除双端栈的尾部元素,并返回该元素的值。
- 获取头部元素(Front):返回双端栈的头部元素的值,但不移除该元素。
- 获取尾部元素(Back):返回双端栈的尾部元素的值,但不移除该元素。
- 判空(IsEmpty):检查双端栈是否为空。
- 清空栈(Clear):移除双端栈中的所有元素。
-
时间复杂度:双端栈的头部入栈、头部出栈、获取头部元素的操作都具有常数时间复杂度O(1)。尾部入栈、尾部出栈、获取尾部元素的操作也是常数时间复杂度O(1)。双端栈的性能较高,可以快速在两个端口进行插入和删除操作。
双端栈的灵活性使得它适用于需要在两个端口进行插入和删除操作的场景。例如,可以用双端栈来实现双端队列(Deque)或进行某些特定的数据处理任务,如回文判断、表达式求值等。它提供了更多操作选项,使得编程时能够更加灵活地处理栈中的元素。
双端栈是一种栈的实现,它支持在栈的头部和尾部进行入栈和出栈操作,但不支持在中间插入或删除元素。双端栈在栈的两端都可以进行操作,可以从头部或尾部插入或删除元素。
双端队列是一种队列的实现,它也支持在队列的头部和尾部进行插入和删除操作,同时也支持在中间进行插入和删除。双端队列既可以像栈一样用作LIFO(后进先出)的数据结构,也可以像队列一样用作FIFO(先进先出)的数据结构。
虽然双端栈和双端队列具有一些相似之处,但它们的操作和应用场景有一些不同。双端栈主要用于需要在栈的两端进行灵活操作的场景,而双端队列则更适合需要在队列两端进行插入和删除操作的场景,并且可以同时支持栈和队列的功能。
3.22 C语言实现
// 双端栈
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 100
typedef struct {
int data[MAX_SIZE];
int front; // 头部指针
int rear; // 尾部指针
} Deque;
void initializeDeque(Deque* deque) {
deque->front = -1;
deque->rear = -1;
}
int isFull(Deque* deque) {
return (deque->front == 0 && deque->rear == MAX_SIZE - 1) || (deque->front == deque->rear + 1);
}
int isEmpty(Deque* deque) {
return deque->front == -1;
}
void pushFront(Deque* deque, int value) {
if (isFull(deque)) {
printf("Deque is full.\n");
return;
}
if (deque->front == -1) {
deque->front = 0;
deque->rear = 0;
} else if (deque->front == 0) {
deque->front = MAX_SIZE - 1;
} else {
deque->front--;
}
deque->data[deque->front] = value;
}
void pushBack(Deque* deque, int value) {
if (isFull(deque)) {
printf("Deque is full.\n");
return;
}
if (deque->front == -1) {
deque->front = 0;
deque->rear = 0;
} else if (deque->rear == MAX_SIZE - 1) {
deque->rear = 0;
} else {
deque->rear++;
}
deque->data[deque->rear] = value;
}
int popFront(Deque* deque) {
if (isEmpty(deque)) {
printf("Deque is empty.\n");
return -1;
}
int value = deque->data[deque->front];
if (deque->front == deque->rear) {
deque->front = -1;
deque->rear = -1;
} else if (deque->front == MAX_SIZE - 1) {
deque->front = 0;
} else {
deque->front++;
}
return value;
}
int popBack(Deque* deque) {
if (isEmpty(deque)) {
printf("Deque is empty.\n");
return -1;
}
int value = deque->data[deque->rear];
if (deque->front == deque->rear) {
deque->front = -1;
deque->rear = -1;
} else if (deque->rear == 0) {
deque->rear = MAX_SIZE - 1;
} else {
deque->rear--;
}
return value;
}
int getFront(Deque* deque) {
if (isEmpty(deque)) {
printf("Deque is empty.\n");
return -1;
}
return deque->data[deque->front];
}
int getBack(Deque* deque) {
if (isEmpty(deque)) {
printf("Deque is empty.\n");
return -1;
}
return deque->data[deque->rear];
}
void clearDeque(Deque* deque) {
deque->front = -1;
deque->rear = -1;
}
int main() {
Deque deque;
initializeDeque(&deque);
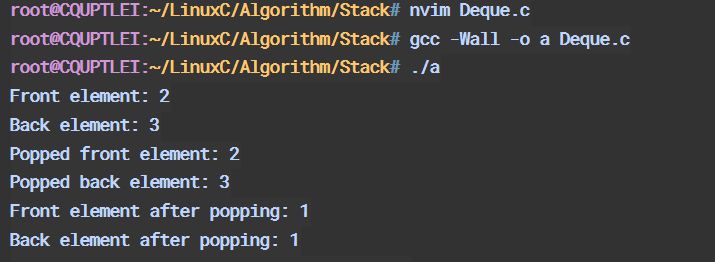
pushFront(&deque, 1);
pushFront(&deque, 2);
pushBack(&deque, 3);
printf("Front element: %d\n", getFront(&deque)); // Output: 2
printf("Back element: %d\n", getBack(&deque)); // Output: 3
printf("Popped front element: %d\n", popFront(&deque)); // Output: 2
printf("Popped back element: %d\n", popBack(&deque)); // Output: 3
printf("Front element after popping: %d\n", getFront(&deque)); // Output: 1
printf("Back element after popping: %d\n", getBack(&deque)); // Output: 1
clearDeque(&deque);
return 0;
}
3.3 并行栈
并行栈(Parallel Stack)是一种多线程环境下的栈实现,它能够支持并发的入栈和出栈操作。与传统的串行栈相比,并行栈可以在多个线程同时进行栈操作,提高了并发性能。
-
结构:并行栈的底层数据结构可以是数组、链表或其他数据结构。每个线程都有自己的栈顶指针,用于指示栈中的当前位置。在多线程环境下,多个线程可以同时访问并操作并行栈。
-
并发操作:并行栈的设计目标是支持高效的并发操作,使多个线程可以同时进行入栈和出栈操作。为了实现并发安全,通常需要使用同步机制(如锁、信号量或原子操作)来保护共享数据结构,避免多个线程同时修改栈结构导致的竞态条件和数据不一致问题。
-
入栈操作:多个线程可以同时进行入栈操作,向并行栈中添加元素。在执行入栈操作时,每个线程需要获取合适的同步机制来保证栈操作的一致性。具体的同步策略可以根据需求选择,例如使用互斥锁来实现互斥访问,或者使用无锁算法(如CAS操作)来实现无锁并发。
-
出栈操作:多个线程可以同时进行出栈操作,从并行栈中移除元素。与入栈操作类似,出栈操作也需要使用合适的同步机制来保证并发操作的正确性。特别要注意的是,当多个线程同时尝试出栈时,需要避免出现空栈的情况,以及保证只有一个线程成功出栈并返回正确的元素。
-
性能与负载均衡:并行栈的性能取决于并发操作的效率和负载均衡的程度。一个好的并行栈实现应该能够有效地处理多线程的竞争,并尽可能地平衡各个线程之间的负载,避免出现明显的线程饥饿或性能瓶颈。
并行栈通常用于多线程编程环境中,例如并行计算、多线程任务处理等场景。它能够提高并发性能,并充分利用多核处理器的计算能力。然而,并行栈的设计和实现相对复杂,需要处理多线程间的同步和竞争条件,因此在使用时需要注意线程安全性和正确性。
3.4 应用——括号匹配
思路:
当遇到开括号时,将其压入栈中。当遇到闭括号时,需要检查栈顶的括号是否与当前闭括号匹配。如果栈为空或栈顶的括号与当前闭括号不匹配,那么表达式中的括号就不是平衡的,返回0。如果匹配成功,则将栈顶的括号弹出,继续处理下一个字符。
最后,当遍历完整个表达式后,需要检查栈是否为空。如果栈为空,那么表达式中的所有括号都匹配,返回1;否则,栈中还有剩余的开括号,表示括号不匹配,返回0。
在主函数中,通过fgets函数从用户输入中获取一个表达式。然后调用isParenthesesBalanced函数来检查表达式中的括号是否平衡。如果返回值为1,则输出"Parentheses are balanced.“;如果返回值为0,则输出"Parentheses are not balanced.”。
程序使用栈的先进后出的特性,通过压栈和弹栈操作来实现括号的匹配检查。它可以处理各种类型的括号,包括圆括号、花括号和方括号(其他的自己加),并且支持嵌套的括号匹配。
int isMatchingPair(char opening, char closing) {
if (opening == '(' && closing == ')')
return 1;
else if (opening == '{' && closing == '}')
return 1;
else if (opening == '[' && closing == ']')
return 1;
else
return 0;
}
int isParenthesesBalanced(char* expression) {
Stack stack;
initializeStack(&stack);
for (int i = 0; expression[i] != '\0'; i++) {
if (expression[i] == '(' || expression[i] == '{' || expression[i] == '[') {
push(&stack, expression[i]);
} else if (expression[i] == ')' || expression[i] == '}' || expression[i] == ']') {
if (isEmpty(&stack) || !isMatchingPair(pop(&stack), expression[i])) {
return 0;
}
}
}
return isEmpty(&stack);
}
完整示例:

// 栈的应用:括号匹配
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 100
typedef struct {
char data[MAX_SIZE];
int top;
} Stack;
void initializeStack(Stack* stack) {
stack->top = -1;
}
int isEmpty(Stack* stack) {
return stack->top == -1;
}
int isFull(Stack* stack) {
return stack->top == MAX_SIZE - 1;
}
void push(Stack* stack, char c) {
if (isFull(stack)) {
printf("Stack is full.\n");
return;
}
stack->data[++stack->top] = c;
}
char pop(Stack* stack) {
if (isEmpty(stack)) {
printf("Stack is empty.\n");
return '\0';
}
return stack->data[stack->top--];
}
int isMatchingPair(char opening, char closing) {
if (opening == '(' && closing == ')')
return 1;
else if (opening == '{' && closing == '}')
return 1;
else if (opening == '[' && closing == ']')
return 1;
else
return 0;
}
int isParenthesesBalanced(char* expression) {
Stack stack;
initializeStack(&stack);
for (int i = 0; expression[i] != '\0'; i++) {
if (expression[i] == '(' || expression[i] == '{' || expression[i] == '[') {
push(&stack, expression[i]);
} else if (expression[i] == ')' || expression[i] == '}' || expression[i] == ']') {
if (isEmpty(&stack) || !isMatchingPair(pop(&stack), expression[i])) {
return 0;
}
}
}
return isEmpty(&stack);
}
int main() {
char expression[MAX_SIZE];
printf("Enter an expression: ");
fgets(expression, sizeof(expression), stdin);
if (isParenthesesBalanced(expression)) {
printf("Parentheses are balanced.\n");
} else {
printf("Parentheses are not balanced.\n");
}
return 0;
}
把 永 远 爱 你 写 进 诗 的 结 尾 ~