目录
背景
巡检工具
数据准备
1、准备一张配置信息表,该表保存需要巡检的数据信息(规则code不可重复)
2、pyspark代码编写
结果表数据展示
规则自动检测并自增
数据准备
背景
该需求是利用pyspark对部分重点产出表进行数据质量监控。主要是对
1、数据表的数据量,该指标后续可计算该表的数据量波动等
2、主键重复数量,用来保障主键的唯一性
3、每个字段的空值量,该指标后续可计算字段的空值波动率以及检测出该字段是否为空,从而提醒去上游查看数据源是否正常。
检测的后续结果可以结合BI/邮件等,对结果进行展示。
巡检工具
数据准备
准备一张配置信息表,该表保存需要巡检的数据信息(规则code不可重复)

其中
(1)规则code用来保证该条规则的唯一性,可以和t-2分区进行关联,从而计算波动率等。
(2)规则类型用来区分是表or字段 的检测规则
(3)规则名称row_cnt代表表行数检测
举例
表行数检测配置-将要检测的表的行数进行配置

字段空值检测配置-将要检测的字段进行配置

主键重复检测配置-配置主键

pyspark代码编写
1、读取上边我们在表里的规则配置信息
2、利用pyspark分别对各个规则进行检测
3、讲结果写入数据表
# encoding=utf8
import smtplib
import re
import findspark
findspark.init()
from pyspark.sql import SparkSession
import pandas as pd
import numpy as np
import warnings
import sys
warnings.filterwarnings('ignore')
spark = SparkSession.builder.appName('cdp_label_check').getOrCreate()
def get_config():
"""
获取配置
"""
df_config = pd.DataFrame()
try:
exec_sql = """select * from dm_subject.dwd_upf_monitor_label_config where rule_name<>'empty_cnt'"""
print(exec_sql)
df_config = spark.sql(exec_sql).toPandas()
except Exception as e:
print("df_config exception ", e)
return df_config
def get_empty_stat_config(bizdate):
"""
获取配置 批量统计空值数量
"""
df_config = pd.DataFrame()
try:
exec_sql = """select
concat('select ',"'",'column',"'",' ','rule_type,',"'",'empty_cnt',"'", ' ','rule_name,',"'",table_name,"'",' table_name, ','split(b.column_name,',"'",'####',"'",')[0] column_name, ',partition_name, ' partition_name, ','coalesce( row_cnt,0) row_cnt',',split(b.column_name,',"'",'####',"'",')[1] rule_code', ' from ( select ',partition_name ,', ',clause_map,' map_cnt ',' from ( select ',partition_name ,', ',clause_sum,' from ',table_name,' where ',partition_name,'={bizdate} group by ',partition_name ,')a)a lateral view explode(map_cnt) b as column_name,row_cnt')
caluse_select
from
(
select
table_name,partition_name
,concat_ws(',',collect_set(concat('sum(if (coalesce(cast(',column_name,' as string),', "'","')" ,'=', "'","'," ,'1,','0)) ',column_name)))clause_sum
,concat('map(',concat_ws(',', collect_set(concat("'",concat(column_name,'####',rule_code),"',",column_name))),')')clause_map
from dm_subject.dwd_upf_monitor_label_config a
where a.rule_type='column'
and rule_name='empty_cnt'
group by table_name,partition_name
)a """
print(exec_sql)
df_config = spark.sql(exec_sql).toPandas()
except Exception as e:
print("df_config exception ", e)
return df_config
def cal_table_row_cnt(rule_code, rule_type, rule_name, table_name, column_name, partition_name, bizdate):
"""
计算数据表数量
"""
try:
exec_sql = """insert overwrite table dm_subject.dwd_upf_monitor_label_result_di PARTITION(dt={bizdate},rule_code='{rule_code}')
select
'{rule_type}' rule_type,
'{rule_name}' rule_name,
'{table_name}' table_name,
'' column_name,
'{partition_name}' partition_name,
count(1) row_cnt
from {table_name}
where {partition_name}={bizdate}
""".format(rule_code=rule_code, rule_type=rule_type, rule_name=rule_name, table_name=table_name,
column_name=column_name, partition_name=partition_name, bizdate=bizdate)
print("sql execute begin " + exec_sql)
df = spark.sql(exec_sql)
print("sql execute end " + exec_sql)
except Exception as e:
print("table_row_cnt exception ", e)
def cal_column_duplicate_cnt(rule_code, rule_type, rule_name, table_name, column_name, partition_name, bizdate):
"""
计算列重复值数量
"""
try:
exec_sql = """insert overwrite table dm_subject.dwd_upf_monitor_label_result_di PARTITION(dt={bizdate},rule_code='{rule_code}')
select
'{rule_type}' rule_type,
'{rule_name}' rule_name,
'{table_name}' table_name,
'{column_name}' column_name,
'{partition_name}' partition_name,
count(1) row_cnt
from
(select {column_name}
from {table_name}
where {partition_name}={bizdate}
group by {column_name}
having count(1)>1
)a
""".format(rule_code=rule_code, rule_type=rule_type, rule_name=rule_name, table_name=table_name,
column_name=column_name, partition_name=partition_name, bizdate=bizdate)
print("sql execute begin " + exec_sql)
df = spark.sql(exec_sql)
print("sql execute end " + exec_sql)
except Exception as e:
print("column_duplicate_cnt exception ", e)
def cal_column_empty_cnt(rule_code, rule_type, rule_name, table_name, column_name, partition_name, bizdate):
"""
计算列空值数量
"""
try:
exec_sql = """insert overwrite table dm_subject.dwd_upf_monitor_label_result_di PARTITION(dt={bizdate},rule_code='{rule_code}')
select
'{rule_type}' rule_type,
'{rule_name}' rule_name,
'{table_name}' table_name,
'{column_name}' column_name,
'{partition_name}' partition_name,
count(1) row_cnt
from {table_name}
where {partition_name}={bizdate}
and ({column_name} is null or {column_name} ='')
""".format(rule_code=rule_code, rule_type=rule_type, rule_name=rule_name, table_name=table_name,
column_name=column_name, partition_name=partition_name, bizdate=bizdate)
print("sql execute begin " + exec_sql)
df = spark.sql(exec_sql)
print("sql execute end " + exec_sql)
except Exception as e:
print("column_empty_cnt exception ", e)
############
##############
def cal_column_empty_cnt_batch( clause_select, bizdate):
"""
计算列空值数量
"""
try:
clause_insert="""insert overwrite table dm_subject.dwd_upf_monitor_label_result_di PARTITION(dt={bizdate},rule_code) """
clause_prepare=clause_insert+clause_select
exec_sql = clause_prepare.format(clause_select=clause_select, bizdate=bizdate)
print("sql execute begin " + exec_sql)
df = spark.sql(exec_sql)
print("sql execute end " + exec_sql)
except Exception as e:
print("column_empty_cnt exception ", e)
if __name__ == "__main__":
#分区日期传入
bizdate = sys.argv[1]
print("cdp_label_check execute begin " + bizdate)
#读取配置表 获取所有的规则
df_config = get_config()
df = df_config.values.tolist()
for conf in df:
print(conf)
rule_code, rule_type, rule_name, table_name, column_name, partition_name = conf
#主键唯一性检测
if rule_name == 'duplicate_cnt':
cal_column_duplicate_cnt(rule_code, rule_type, rule_name, table_name, column_name, partition_name, bizdate)
#表行数检测
if rule_name == 'row_cnt':
cal_table_row_cnt(rule_code, rule_type, rule_name, table_name, column_name, partition_name, bizdate)
#循环检测监控列表中每个字段的空值情况
empty_stat_config = get_empty_stat_config(bizdate)
df = empty_stat_config.values.tolist()
for conf in df:
print(conf)
clause_select = conf[0]
#执行结果写入
cal_column_empty_cnt_batch(clause_select, bizdate)
print("cdp_label_check execute end " + bizdate)
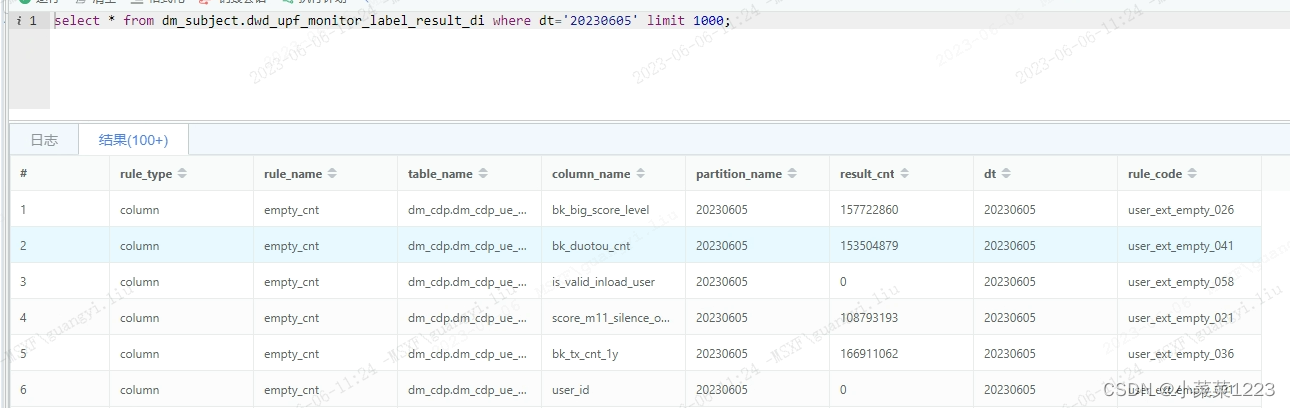
结果表数据展示
规则自动检测并自增
思考,如果我们表经常增加字段,那么每次都要往表里手动维护规则进去会很麻烦,所以我们编写自增规则的一个脚本
数据准备
1、准备一个表,里边存储已经不需要监控的字段or已经失效的字段
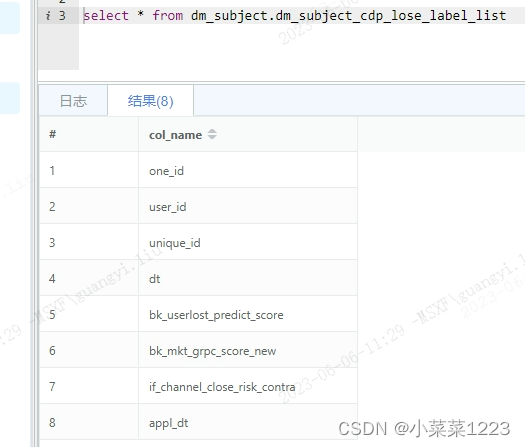
2、准备一个表,存储需要自增字段的来源表的元数据信息,可以获取到该表里的字段即可
pyspark代码编写
#coding:utf-8
import findspark
findspark.init()
from pyspark.sql import SparkSession
import pandas as pd
import numpy as np
spark = SparkSession.builder.appName('cdp_label_add_column').getOrCreate()
def get_cur_col_list():
"""
获取当前监控的字段列表
"""
try:
exec_sql = """
select * from dm_subject.tmp_dwd_upf_monitor_label_config01
"""
print ("exec_sql:", exec_sql)
cur_col_list = spark.sql(exec_sql).toPandas().values.tolist()
except Exception as e:
print ("get_cur_col_list error: ", e)
exit()
return cur_col_list
def get_lost_label_list():
"""
获取获取已下线或失效标签列表
"""
lost_label_list = []
try:
exec_sql = """
select * from dm_subject.dm_subject_cdp_lose_label_list
"""
print ("exec_sql:", exec_sql)
for i in spark.sql(exec_sql).toPandas().values.tolist(): lost_label_list.append(i[0])
except Exception as e:
print ("get_lost_label_list error: ", e)
exit()
return lost_label_list
def get_all_columns(table_name, db_name):
"""
获取该表所有字段信息
"""
all_columns_list = pd.DataFrame()
try:
exec_sql = """
SELECT t3.db_name,t1.table_name,t1.table_alias,t2.column_index,t2.column_name,t2.column_type,t2.column_comment FROM(
SELECT id,table_name,table_alias,db_id FROM ods_dsp.ds_metadata_dsmetadata_meta_table
WHERE table_name REGEXP %s AND hoodie_record_type <> 'DELETE')t1
INNER JOIN(SELECT * FROM ods_dsp.ds_metadata_dsmetadata_meta_column WHERE hoodie_record_type <> 'DELETE')t2
ON t1.id = t2.table_id
INNER JOIN(SELECT id,db_name FROM ods_dsp.ds_metadata_dsmetadata_meta_db WHERE db_name REGEXP %s AND hoodie_record_type <> 'DELETE')t3
ON t1.db_id = t3.id ORDER BY t1.table_name,t2.column_index ASC
"""%("\'%s\'"%(table_name), "\'%s\'"%(db_name))
all_columns_list = spark.sql(exec_sql).toPandas()
except Exception as e:
print ("get_all_columns error: ", e)
exit()
#print ("all_columns_list:", all_columns_list)
return all_columns_list.values.tolist()
def main(check_list, db_name):
#获取当前在监控的标签列表
col_list, table_indx = [], {}
cur_col_list = get_cur_col_list()
for i in cur_col_list:
#contract_agg_empty_001 column empty_cnt dm_cdp.dm_cdp_be_contract_agg contr_no dt
rule_code, rule_type, rule_name, table_name, column_name, partition_nam = i
#剔除不在监控范围的数据
if rule_type!='column' and rule_name!='empty_cnt':continue
#记录最大的rulecode
table_indx[table_name.split('.')[1].strip()]=rule_code if table_name not in table_indx.keys() else max(table_indx[table_name], rule_code)
col_list.append(column_name)
#print ('col_list: ', col_list, 'table_indx: ', table_indx)
#获取已下线或失效标签列表
lost_label_list = get_lost_label_list()
#获取线上所有字段
add_col = []
for table_name in check_list:
all_columns_list = get_all_columns(table_name, db_name)
#[['dm_cdp', 'dm_cdp_ue_user_agg', '用户实体的聚合属性', 0, 'one_id', 'bigint', 'one_id'],]
for i in all_columns_list:
_, _, table_comment, col_index, col_name, col_type, col_comment = i
#如果字段不在当前监控列表或者不在失效列表中
if col_name not in col_list and col_name not in lost_label_list:
add_col.append('%s,%s'%(table_name, col_name))
#print (add_col)
import datetime
#如果没有检测到新增字段
if not add_col:
print ("%s not need add column!", datetime.date.today().strftime('%Y%m%d'))
exit()
#检测到之后执行新增
res = "insert into table dm_subject.tmp_dwd_upf_monitor_label_config01 values"
for col in add_col:
tb_name, col_name = col.split(",")
max_rule_code = table_indx[tb_name]
#计算自增1的rule_code
new_rule_code = '_'.join(max_rule_code.split('_')[:-1])+'_%s'%('%03d'%(int(max_rule_code.split('_')[-1])+1))
table_indx[tb_name] = new_rule_code
res += '(\'%s\',\'column\',\'empty_cnt\',\'%s\',\'%s\',\'dt\'),'%(new_rule_code,'.'.join([db_name, tb_name]), col_name)
try:
print ('res sql: ', res.strip(','))
spark.sql(res.strip(','))
except Exception as e:
print ("exec res sql error: ", e)
if __name__ == '__main__':
check_list = [
'dm_cdp_ue_user_bas'
,'dm_cdp_ue_user_agg'
,'dm_cdp_ue_user_ext'
,'dm_cdp_be_contract_bas'
,'dm_cdp_be_contract_agg'
,'dm_cdp_be_contract_ext'
]
main(check_list, 'dm_cdp')