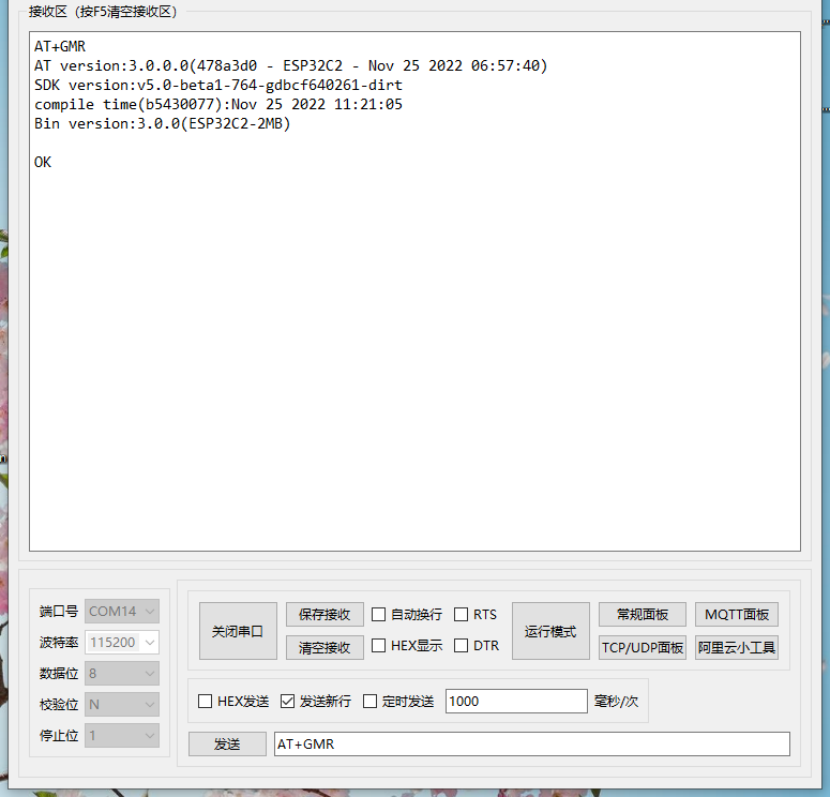
1、参考引用
- C++高级编程(第4版,C++17标准)马克·葛瑞格尔
2、建议先看《21天学通C++》 这本书入门,笔记链接如下
- 21天学通C++读书笔记(文章链接汇总)
1. 使用动态内存
1.1 如何描绘内存
- 在本书中,内存单元表示为一个带有标签的框,该标签表示这个内存对应的变量名,方框内的数据显示当前的内存值
- i 是在栈上分配的自动变量,当程序流离开作用域时会自动释放 i
int i = 7; - 使用 new 关键字时,内存分配在堆上。下面的代码在堆栈上创建一个变量 ptr,然后在堆上分配内存,ptr 指向这块内存
- 变量 ptr 仍在堆栈上,即使它指向的是堆中的内存
- 指针只是一个变量,可在堆栈或堆中,然而动态内存总是在堆上分配
int *ptr = nullptr; // 每次声明一个指针变量时,务必立即用适当的指针或 nullptr 进行初始化 ptr = new int; int *ptr = new int; // 等价于上面两行代码

- 指针既可在堆栈中,也可在堆中
- 下面的代码首先声明一个指向整数指针的指针变量 handle
- 然后,动态分配足够的内存来保存一个指向整数的指针,并将指向这个新内存的指针保存在 handle 中
- 接下来,将另一块足以保存整数的动态内存的指针保存在 * handle 的内存位置
int* *handle = nullptr; handle = new int*; *handle = new int; - 下图展示了这个两级指针,其中一个指针保存在堆栈中 (handle),另一个指针保存在堆中 (*handle)

1.2 分配和释放
- 要为变量创建空间,可使用 new 关键字。要释放这个空间给程序中的其他部分使用,可使用 delete 关键字
1.2.1 使用 new 和 delete
- 内存泄漏
- 要分配一块内存,可调用 new,并提供需要空间的变量的类型。new 返回指向那个内存的指针,但程序员应将这个指针保存在变量中。如果忽略了 new 的返回值,或这个指针变量离开了作用域,那么这块内存就被孤立了,因为无法再访问这块内存。这也称为内存泄漏(当堆中有数据块无法从堆栈中直接或间接访问时,这块内存就被孤立/泄露了)
void leaky() { new int; cout << "I just leaked an int!" << endl; } - 除非计算机能提供无限制的高速内存,否则就需要告诉编译器,对象关联的内存什么时候可以释放以作他用。为释放堆中的内存,只需要使用 delete 关键字,并提供指向那块内存的指针,如下所示
int *ptr = new int; delete ptr; ptr = nullptr; // 建议在释放指针的内存后,将指针重新设置为 mullptr。这样就不会在无意中使用一个指向已释放内存的指针
1.2.2 关于 malloc() 函数
- 在 C++ 中不应该使用 malloc() 和 fee() 函数,只使用 new 和 delete 运算符
1.2.3 当内存分配失败时
- 默认情况下,如果 new 失败了,程序会终止。在许多程序中,这种行为是可以接受的。当new 因为没有足以满足请求的内存而抛出异常失败时,程序退出。
- 也有不抛出异常的 new 版本。相反,它会返回 nullptr,这类似于 C 语言中 malloc() 的行为
int *ptr = new(nothrow) int;
1.3 数组
- 数组将多个同一类型的变量封装在一个通过索引访问的变量中
1.3.1 基本类型的数组
- 当程序为数组分配内存时,分配的是连续的内存块,每一块大到足以容纳数组的单个元素。例如,在堆栈上分配 5 个 int 型数字的局部数组的声明如下所示
- 下图展示了创建这个数组后的内存状态。在堆栈上声明数组时,数组的大小必须是编译时已知的常量值
int myArray[5];

- 在堆上声明数组没什么不同,只是需要通过一个指针引用数组的位置。下面的代码为包含 5 个 int 型数字的数组分配内存,并将指向这块内存的指针保存在变量 myArrayPtr 中
- 堆中的数组和堆栈中的数组类似,只是位置不同而已。myArrayPtr 变量指向数组的第 0 个元素。把数组放在堆中的好处在于可在运行时通过动态内存指定数组大小
int *myArrayPtr = new int[5]; delete[] myArrayPtr; // 对 new[] 的每次调用都应与 delete[] 调用配对,以清理内存 myArrayPtr = nullptr;

不要把动态分配的数组和动态数组混为一谈。数组本身不是动态的,因为一旦被分配,数组的大小就不会改变。动态内存允许在运行时指定分配的内存块的大小,但它不会自动调整其大小以容纳数据
1.3.2 对象的数组
- 对象的数组和简单类型的数组没有区别。通过 new[N] 分配 N 个对象的数组时,实际上分配了 N 个连续的内存块,每一块足以容纳单个对象
- 使用 new[] 时,每个对象的无参构造函数 (= default) 会自动调用。这样,通过 new[] 分配对象数组时,会返回一个指向数组的指针,这个数组中的所有对象都被初始化了
class Simple { public: Simple() {} ~Simple() {} }; // 如果要分配包含 4 个 Simple 对象的数组,那么 Simple 构造函数会被调用 4 次 Simple *mySimpleArray = new Simple[4];

1.3.3 多维数组
- 1. 多维堆栈数组
- 在内存中,堆栈中的二维数组如下图所示。由于内存中不存在两个数轴 (地址只是顺序排列的),计算机将维数组以一维数组的方式表示。多维数组的大小是其所有维度的乘积,再乘以这个数组中单个元素的大小
- 要访问多维数组中的值,计算机将每个下标当作多维数组中的另一个子数组。例如,表达式 board[0] 实际上指下图中突出显示的子数组。添加 board[0][2] 时,计算机通过子数组中第二个下标访问子数组,从而访问正确的元素

- 2. 多维堆数组
- 如果需要在运行时确定多维数组的维数,可以使用堆数组。正如动态分配的一维数组是通过指针访问一样,动态分配的多维数组也通过指针访问。唯一的区别在于,在二维数组中,需要使用指针的指针:在 N 维数组中,需要使用 N 级指针
// 编译器并不自动分配子数组的内存。可像分配一维堆数组那样分配第一个维度的数组 // 但是必须显式地分配每一个子数组。下面的函数正确分配了二维数组的内存 char** allocateCharacterBoard(size_t xDimension, size_t yDimension) { char** myArray = new char*[xDimension]; // Allocate first dimension for (size_t i = 0; i < xDimension; i++) { myArray[i] = new char[yDimension]; // Allocate ith subarray } return myArray; } // 要释放多维堆数组的内存,数组版本的 delete[] 语法也不能自动清理子数组 // 释放数组的代码应该类似于分配数组的代码,如以下函数所示 void releaseCharacterBoard(char** myArray, size_t xDimension) { for (size_t i = 0; i < xDimension; i++) { delete[] myArray[i]; // Delete ith subarray } delete[] myArray; // Delete first dimension }

建议尽可能不要使用旧式的 C 风格数组,因为这种数组没有提供任何内存安全性
- 这里解释它们,是因为可能在旧代码中遇到。在新代码中,应改用 C++ 标准库容器std::array 和 std::vector
- 例如,用 vector 表示一维动态数组,用 vector<vector<T>> 表示二维动态数组等
- 如果应用程序中需要 N 维动态数组,建议编写帮助类,以方便使用接口。例如,要使用行长相等的二维数据,应当考虑编写 (也可以重用) Matrix<T> 或 Table<T> 类模板,该模板在内部使用 vector<vector<T>>数据结构
1.4 使用指针
-
思考指针的方式有两种
- 指针只是一个内存地址
- 指针只是一个间接层,它告诉程序 “看那个地方”(指针箭头的意义)
- 当通过 * 运算符解除对一个指针的引用时:从地址的角度看,把解除引用想象为跳到与那个指针表示的地址对应的内存;使用图形视图时,每次解除引用都对应从箭尾到箭头的过程
- 当通过 & 运算符取一个位置的地址时:从地址的角度看,程序只不过是表示那个位置的地址的数值,这个数值可保存为指针形式;在图形视图中,& 运算符创建了一个新箭头,其头部终止于表达式表示的位置,其尾部可以保存为一个指针
-
指针的类型转换
Document *documentPtr = getDocument(); char *myCharPtr = (char*)documentPtr; // 正确 // 编译器将拒绝执行不同数据类型的指针的静态类型转换 char *myCharPtr = static_cast<char*>(documentPtr); // 错误,无法编译
2. 数组-指针的对偶性
前面提到,指针和数组之间有一些重叠
- 在堆上分配的数组通过指向该数组中第一个元素的指针来引用
- 基于堆栈的数组通过数组语法 ([]) 和普通的变量声明来引用
2.1 数组就是指针
- 下面的代码创建了一个堆栈上的数组,数组元素初始化为 0,但通过一个指针来访问这个数组
int myIntArray[10] = {}; int *myIntPtr = myIntArray; myIntPtr[4] = 5; - 下面的函数以指针形式接收一个整数数组
- 调用者需要显式地传入数组的大小,因为指针没有包含任何与大小有关的信息(任何形式的 C++ 数组,不论是不是指针,都没有内含大小信息,这是应使用现代容器的一个原因)
void doubleInts(int *theArray, size_t size) { for (size_t i = 0; i < size; ++i) { theArray[i] *= 2; } } - 这个函数的调用者可以传入基于堆栈或堆的数组
- 在传入基于堆的数组时,指针已经存在了,且按值传入函数
- 在传入基于堆栈的数组时,调用者可以传入一个数组变量,编译器会自动把这个数组变量当作指向数组的指针处理,还可以显式地传入第一个元素的地址
// 传入基于堆的数组 size_t arrSize = 4; int *heapArray = new int[arrSize]{1, 5, 3, 4}; doubleInts(heapArray, arrSize); delete[] heapArray; heapArray = nullptr; // 传入基于堆栈的数组 int stackArray[] = {5, 7, 9, 11}; arrSize = std::size(stackArray); // 从 C++17 开始 // arrSize = sizeof(stackArray); // C++17 之前的写法 doubleInts(stackArray, arrSize); // 把数组变量当作指向数组的指针处理 doubleInts(&stackArray[0], arrSize); // 显式地传入第一个元素的地址 - 数组参数传递的语义和指针参数传递的语义十分相似,因为当把数组传递给函数时,编译器将数组视为指针
- 函数如果接收数组作为参数,并修改数组中元素的值,实际上修改的是原始数组而不是副本
- 与指针一样,传递数组实际上模仿的是按引用传递的功能,因为真正传入函数的是原始数组的地址而不是副本
- 以下实现修改了原始数组,即使参数是数组而不是指针,也同样如此
void doubleInts(int theArray[], size_t size) { for (size_t i = 0; i < size; ++i) { theArray[i] *= 2; } } - 在函数原型中,theArray 后面方括号中的数字被忽略了。下面的 3 个版本是等价的
void doubleInts(int *theArray, size_t size); void doubleInts(int theArray[], size_t size); void doubleInts(int theArray[2], size_t size);
通过数组语法声明的数组可通过指针访问,当把数组传递给函数时,这个数组总是作为指针传递
2.2 并非所有的指针都是数组
- 指针本身是没有意义的,它可能指向随机内存、对象或数组。始终可使用指针的数组语法,但这样做并不总是正确的,因为指针并不总是数组。例如,考虑下面的代码
- ptr 是一个有效的指针,但不是一个数组。可通过数组语法 (ptr[0]) 访问这个指针指向的值,但是这样做的风格很可疑。事实上,对于非数组指针使用数组语法可能导致 bug。ptr[1] 处的内存可以是任意内容
int *ptr = new int;
通过指针可自动引用数组,但并非所有指针都是数组
3. 低级内存操作
3.1 指针运算
- 声明一个指向 int 的指针,然后将这个指针递增 1,则这个指针在内存中向前移动 1 个 int 的大小,而不是 1 个字节
int *myArray = new int[8]; myArray[2] = 33; *(myArray + 2) = 33; // 等价于上一行代码 - 指针运算的另一个有用应用是减法运算。将一个指针减去另一个同类型的指针,得到的是两个指针之间指针指向的类型的元素个数,而不是两个指针之间字节数的绝对值
3.2 自定义内存管理
- 大部分情况下,new 和 delete 在后台完成了所有相关工作:分配正确大小的内存块、管理可用的内存区域列表、释放内存时将内存块释放回可用内存列表
- 资源非常紧张时,或在非常特殊的情况下,例如管理共享内存时,实现自定义的内存管理是一个可行的方案
3.3 垃圾回收
- 内存清理的另一个方面是垃圾回收。在支持垃圾回收的环境中,程序员几乎不必显式地释放与对象关联的内存,运行时库会在某时刻自动清理没有任何引用的对象
- 与 C# 和 Java 不一样,在 C++ 语言中没有内建垃圾回收
- 在现代 C++ 中,使用智能指针管理内存
- 在旧代码中,则在对象层次通过 new 和 delete 管理内存
- 在 C++ 中实现真正的垃圾回收是可能的,但不容易,而将自己从释放内存的任务中解放出来可能引入新麻烦
3.4 对象池
- 垃圾回收就像买了一堆野餐用的盘子,然后把任何用过的盘子留在花园中,等着什么时候有风把这些盘于吹到邻居的花园中。当然,必须有一种更符合生态规律的内存管理方法
- 对象池是回收的代名词。购买合理数量的盘子,在使用一个盘子后,就清理它供以后重用
- 使用对象池的理想情况是:随着时间的推移,需要使用大量同类型的对象,而且创建每个对象都会有开销
4. 智能指针
内存管理是 C++ 中常见的错误和 bug 来源,许多这类 bug 都来自动态内存分配和指针的使用
- 在程序中广泛使用动态内存分配,在对象间传递多个指针时,很容易忘记每个指针只能在正确时间执行一次 delete 操作
- 出错的后果很严重:当多次释放动态分配的内存时,可能会导致内存损坏或致命的运行时错误,当忘记释放动态分配的内存时,会导致内存泄漏
- 智能指针可帮助管理动态分配的内存,这是避免内存泄漏建议采用的技术。这样,智能指针可保存动态分配的资源如内存。当堆栈变量离开作用域或被重置时,会自动释放所占用的资源。智能指针可用于管理在函数作用域内 (或作为类的数据成员) 动态分配的资源,也可通过函数实参来传递动态分配的资源的所有权
- 智能指针的主要类型
- 1、默认智能指针 unique_ptr(唯一所有权),独占对象
- 2、共享资源智能指针 shared_ptr(共享所有权),允许多个 shared_ptr 实例指向同一个对象,通过计数管理
- 3、weak_ptr 是辅助类,是一种弱引用,指向 shared_ptr 所管理的对象
- 使用智能指针时,需要添加 <memory> 头文件
4.1 unique_ptr
4.1.1 创建 unique_ptr
- 作为经验法则,总将动态分配的对象保存在堆栈的 unique_ptr 实例中
// 故意不释放对象,产生内存泄漏 void leaky() { Simple *mySimplePtr = new Simple(); mySimplePtr->go(); } // 如果 go() 方法抛出一个异常,将永远不会调用 delete,也会导致内存泄漏 void couldBeLeaky() { Simple *mySimplePtr = new Simple(); mySimplePtr->go(); delete mySimplePtr; } - 上面这两种情况下应使用 unique_ptr。对象不会显式删除,但实例 unique_ptr 离开作用域时 (在函数的末尾,或者因为抛出了异常),就会在其析构函数中自动释放 Simple 对象
// 这段代码使用 C++14 中的 make_unique() 和 auto 关键字 // 所以只需要指定指针的类型,本例中是 Simple // 如果 Simple 构造函数需要参数,就把它们放在 make_unique() 调用的圆括号中 void notLeaky() { auto mySimpleSmartPtr = make_unique<Simple>(); mySimpleSmartPtr->go(); } - 考虑下面对 foo() 函数的调用
foo(make_unique<Simple>(), make_unique<Bar>(data()))
始终使用 make_unique() 来创建 unique_ptr
4.1.2 使用 unique_ptr
-
像标准指针一样,仍可以使用 * 或 -> 对智能指针进行解引用
// 以下两种方式等价 mySimpleSmartPtr->go(); (*mySimpleSmartPtr).go(); -
get() 方法可用于直接访问底层指针,这可将指针传递给需要普通指针的函数
void processData(Simple *simple) { /* 使用普通指针 */ } auto mySimpleSmartPtr = make_unique<Simple>(); processData(mySimpleSmartPtr.get()); // 调用 -
可释放 unique_ptr 的底层指针,并使用 reset() 根据需要将其改成另一个指针
mySimpleSmartPtr.reset(); // 释放底层指针并设置为 nullptr mySimpleSmartPtr.reset(new Simple()); // 释放底层指针并设置为一个新的指针 -
可使用 release() 断开 unique_ptr 与底层指针的连接。release() 方法返回资源的底层指针,然后将智能指针设置为 nullptr。实际上,智能指针失去对资源的所有权,负责在你用完资源时释放资源
Simple *simple = mySimpleSmartPtr.release(); delete simple; simple = nullptr; -
由于 unique_ptr 代表唯一拥有权,因此无法复制它。使用 std::move() 实用工具,可使用移动语义将一个 unique_ptr 移到另一个。这用于显式移动所有权,如下所示
class Foo { public: Foo(unique_ptr<int> data) : mData(move(data)) {} private: unique_ptr<int> mData; }; auto myIntSmartPtr = make_unique<int> (42); Foo f(move(myIntSmartPtr));
4.2 shared_ptr
-
总是使用 make_shared() 创建 shared_ptr
auto mySimpleSmartPtr = make_shared<Simple>(); -
与 unique_ptr 一样,shared_ptr 也支持 get() 和 reset() 方法。唯一的区别在于,当调用 reset() 时,由于引用计数,仅在最后的 shared_ptr 销毁或重置时,才释放底层资源
-
注意:shared_ptr 不支持 release()。可使用 use_count() 来检索共享同一资源的 shared_ptr 实例数量
-
与 unique_ptr 类似,shared_ptr 默认情况下使用标准的 new 和 delete 运算来分配和释放内存
-
下面的示例使用 shared_ptr 存储文件指针。当 shared_ptr 离开作用域时 (此处为脱离作用域时),会调用 CloseFile() 函数来自动关闭文件指针。这个例子使用了旧式 C 语言的 fopen() 和 fclose() 函数,只是为了演示 shared_ptr 除了管理纯粹的内存之外还可以用于其他目的
void CloseFile(FILE *filePtr) { if (fillPtr == nullptr) { return; } fclose(filePtr); cout << "File closed." << endl;0 } int main() { FILE *f = fopen("data.txt", "w"); shared_ptr<FILE> filePtr(f, CloseFile); if (filePtr == nullptr) { cerr << "Error opening file." << endl; } else { cout << "File opened." << endl; } return 0; }
4.2.1 引用计数的必要性
- 引用计数用于跟踪正在使用的某个类的实例或特定对象的个数,引用计数的智能指针跟踪为引用一个真实指针 (或某个对象) 而建立的智能指针的数目。通过这种方式,智能指针可以避免双重删除
- 如果要创建两个标准的 shared_ptrs,并使它们都指向同一个 Simple 对象,如下面的代码所示,在销毁时,两个智能指针将尝试删除同一个对象
// 应该避免使用这种方式,改用下面的复制构造函数 void doubleDelete() { Simple *mySimple = new Simple(); shared_ptr<Simple> smartPtr1(mySimple); shared_ptr<Simple> smartPtr2(mySimple); }// 输出:代码崩溃 Simple constructor called! Simple destructor called! Simple destructor called! - 只调用一次构造函数,却调用两次析构函数,使用 unique_ptr 也会出现同样的问题。连引用计数的 shared_ptr 类也会以这种方式工作。然而,根据 C++ 标准,这是正确的行为。不应该像以上 doubleDelete() 函数那样创建两个指向同一个对象的 shared_ptr,而是应该建立副本,如下所示
void noDoubleDelete() { auto smartPtr1 = make_shared<Simple>(); shared_ptr<Simple> smartPtr2(smartPtr1); // 建立副本 }// 输出 Simple constructor called! Simple destructor called!
即使有两个指向同一个 Simple 对象的 shared_ptr,Simple 对象也只销毁一次。回顾一下,unique_ptr 不是引用计数的。事实上,unique_ptr 不允许像 noDoubleDelete() 函数中那样使用复制构造函数
4.2.2 别名
- shared_ptr 支持所谓的别名:这允许一个 shared_ptr 与另一个 shared_ptr 共享一个指针 (拥有的指针),但指向不同的对象 (存储的指针)。例如,这可用于使用一个 shared_ptr 指向一个对象的成员,同时拥有该对象本身
- “拥有的指针” 用于引用计数:当对指针解引用或调用它的 get() 时,将返回 “存储的指针”
- “存储的指针” 用于大多数操作,如比较运算符
make_shared 和 shared_ptr 的区别class Foo { public: Foo(int value) : mData(value) {} int mData; }; // 仅当两个 shared_ptrs (foo 和 aliasing) 都销毁时,才销毁 Foo 对象 /* 创建一个名为 foo 的智能指针对象,它使用 make_shared 模板函数来动态分配一个名为 Foo 的类的实例,并将值 42 传递给该实例的构造函数 这个智能指针对象可以自动管理这个实例的内存,确保在不再需要时自动释放它 */ auto foo = make_shared<Foo>(42); /* 这种构造方式称为 "别名构造函数",它允许多个智能指针共享同一个对象,同时避免智能指针在释放对象时出现问题 创建了一个名为 aliasing 的智能指针对象,使用 shared_ptr 模板函数并传递两个参数 第一个参数是上面创建的智能指针对象指向动态分配的 Foo 实例 第二个参数是 Foo 类中名为 mData 的成员的地址 */ auto aliasing = shared_ptr<int>(foo, &foo->mData);- std::shared_ptr 构造函数会执行两次内存申请(首先会申请数据的内存,然后申请内控制块)
- 而 std::make_shared 则执行一次(将数据和控制块的申请放到一起)
- make_shared 的缺点
- 因为 make_shared 只申请一次内存,因此控制块和数据块在一起,只有当控制块中不再使用时,内存才会释放,但是 weak_ptr 却使得控制块一直在使用
4.3 weak_ptr
- 在 C++ 中还有一个类与 shared_ptr 模板有关,那就是 weak_ptr。weak_ptr 可包含由 shared_ptr 管理的资源的引用。weak_ptr 不拥有这个资源,所以不能阻止 shared_ptr 释放资源
- weak_ptr 销毁时 (例如离开作用域时) 不会销毁它指向的资源:然而,它可用于判断资源是否已经被关联的 shared_ptr 释放了。weak_ptr 的构造函数要求将一个 shared_ptr 或另一个 weak_ptr 作为参数
- 为了访问 weak_ptr 中保存的指针,需要将 weak_ptr 转换为 shared_ptr 有两种方法
- 使用 weak_ptr 实例的 lock() 方法,这个方法返回一个 shared_ptr。如果同时释放了与 weak_ptr 关联的 shared_ptr,返回的 shared_ptr 是 nullptr
- 创建一个新的 shared_ptr 实例,将 weak_ptr 作为 shared_ptr 构造函数的参数。如果释放了与 weak_ptr 关联的 shared_ptr,将抛出 std:bad_weak_ptr 异常
#include <memory>
#include <iostream>
using namespace std;
class Simple {
public:
Simple() { cout << "Simple constructor called!" << endl; }
~Simple() { cout << "Simple destructor called!" << endl; }
};
void useResource(weak_ptr<Simple> &weakSimple) {
auto resource = weakSimple.lock();
if (resource) {
cout << "Resource still alive." << endl;
} else {
cout << "Resource has been freed!" << endl;
}
}
int main() {
auto sharedSimple = make_shared<Simple>();
weak_ptr<Simple> weakSimple(sharedSimple);
// Try to use the weak_ptr.
useResource(weakSimple);
// Reset the shared_ptr.
// Since there is only 1 shared_ptr to the Simple resource, this will
// free the resource, even though there is still a weak_ptr alive.
sharedSimple.reset();
// Try to use the weak_ptr a second time.
useResource(weakSimple);
return 0;
}
5. 常见的内存陷阱
5.1 分配不足的字符串
- 与 C 风格字符串相关的最常见问题是分配不足
- 大多数情况下,都是因为没有分配尾部的 ‘\0’ 终止字符
- 当假设某个固定的最大大小时,也会发生字符串分配不足的情况。基本的内置 C 风格字符串函数不会针对固定的大小操作,而是有多少写多少,如果超出字符串的末尾,就写入未分配的内存
- 以下代码演示了字符串分配不足的情况
char buffer[1024] = {0}; while (true) { // getMoreData() 函数返回一个指向动态分配内存的指针 char *nextChunk = getMoreData(); if (nextChunk == nullptr) { break; } else { // 把第二个参数的 C 风格字符串连接到第一个参数的 C 风格字符串的尾部 strcat(buffer, nextChunk); delete[] nextChunk; } } - 解决上述字符串分配不足问题的方法
- 1、使用 C++ 风格的字符串,可自动处理与连接字符串关联的内存
- 2、不要将缓冲区分配为全局变量或分配在堆栈上,而是分配在堆上
- 3、创建另一个版本的 getMoreData(),这个版本接收一个最大计数值 (包括 0 字符),返回的字符数不多于这个值,然后跟踪剩余的空间数以及缓冲区中当前的位置
5.2 访问内存越界
- 指针只不过是一个内存地址,因此指针可能指向内存中的任意位置。例如,考虑一个 C 风格的字符串,它不小心丢失了 ‘\0’ 终止字符。下面这个函数试图将字符串填满 m 字符,但实际上可能会继续在字符串后面填充 m
void fillWithM(char *inStr) { int i = 0; while (inStr[i] != '\0') { inStr[i] = 'm'; i++; } } - 如果把不正确的终止字符串传入这个函数,那么内存的重要部分被改写而导致程序崩溃只是时间问题,写入数组尾部后面的内存产生的 bug 称为缓冲区溢出错误
避免使用旧的 C 风格字符串和数组,它们没有提供任何保护,而要改用像 C++ string 和 vector 这样安全的现代结构,它们能够自动管理内存
5.3 内存泄漏
- 分配了内存,但没有释放,就会发生内存泄漏。起初,这听上去好像是粗心编程的结果,应该很容易避免。毕竟,如果在编写的每个类中,每个 new 都对应一个 deete,那么应该不会出现内存泄漏。实际上并不总是如此
- 在下面的代码中,Simple 类编写正确,释放了每一处分配的内存。当调用 doSomething() 函数时,outSimplePtr 指针修改为指向另一个 Simple 对象,但是没有释放原来的 Simple 对象。为了演示内存泄漏,doSomething() 函数故意没有删除旧的对象。一旦失去对象的指针,就几乎不可能删除它了
class Simple { public: Simple() { mIntPtr = new int(); } ~Simple() { delete mIntPtr; } void setValue(int value) { *mIntPtr = value; } private: int *mIntPtr; }; void doSomething(Simple *&outSimplePtr) { outSimplePtr = new Simple(); } int main() { Simple *simplePtr = new Simple(); doSomething(simplePtr); // 只删除第二个对象,没有删除旧的对象 delete simplePtr; return 0; }
以上只是演示内存泄漏,实际应使 mIntPtr 和 simplePtr 成为 unique_ptr,使 outSimplePtr 成为 unique_ptr 的引用