文章目录
- 任务类型
- 任务配置
- 路由策略
- 阻塞处理策略:
- 单个任务和集群任务
- 单机多任务分片
- 集群分片
任务类型
-
单个任务:一个任务实例便可完成
-
单机单任务:单机模式下任何路由模式都只有一个实例执行
-
集群单任务:由路由策略(广播模式除外)选择其中一个实例完成
-
-
分片任务:集群部署,每个实例都同时执行一部分数据。分片方式:取模分片,范围分片
-
单机多任务分片:单机模式下,创建同类型任务多个任务计划,手工分片数据作为参数
-
集群任务分片:只有广播模式会通知所有实例都会运行,每个节点取模执行任务
-
任务配置
路由策略
| 策略 | 参数值 | 详细含义 |
|---|---|---|
| 第一个 | FIRST | 固定选择第一个机器 |
| 最后一个 | LAST | 固定选择最后一个机器 |
| 轮询 | ROUND | 依次选择执行 |
| 随机 | RANDOM | 随机选择在线的机器 |
| 一致性HASH | CONSISTENT_HASH | 每个人物按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上 |
| 最不经常使用 | LEAST_FREQUENTLY_USED | 使用频率最低的机器优先被选择 |
| 最近最久未使用 | LEAST_RECENTLY_USED | 最久未使用的机器优先被选择 |
| 故障转义 | FAILOVER | 按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度 |
| 忙碌转义 | BUSYOVER | 按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定位目标执行器并发起调度 |
| 分片广播 | SHARDING_BROADCAST | 广播触发对应集群中所有机器执行一次任务,同事系统自动传递分片参数,可根据分片参数开发分片任务 |
子任务ID:
当有任务需要相互依赖时使用,比如在对账业务里,下载对账文件任务成功之后,才开始对账。那么,可以把这几个任务当成一个大任务来串行处理,即在一个任务的末尾触发另一个任务。
如果我们需要在本任务执行结束并且执行成功的时候触发另外一个任务,那么就可以把另外的任务作为本任务的子任务运行,就只需要在本任务里填入另外一个任务的jobId即可(可以在任务列表查看JobId)
阻塞处理策略:
| 策略 | 参数值 | 含义 |
|---|---|---|
| 单机串行,默认 | SERIAL_EXECUTION | 调度请求进入单机执行器后,调度请求进入FIFO |
| 丢弃后续调度 | DISCARD_LATER | 调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败 |
| 覆盖之前调度 | COVER_EARLY | 调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本次调度任务 |
单个任务和集群任务
@Component
public class SimpleJobHandler {
@XxlJob(value ="simpleJobHandler" )
public ReturnT<String> execute(String param) throws InterruptedException {
IntStream.rangeClosed(1,20).forEach(index->{
XxlJobLogger.log("simpleJobHandler>>"+index);
});
//官方文档说 如果任务超时 是采用interrupt机制打断子线程的,因此需要将InterruptedException 向上抛出
//不能catch,否则任务超时后 任务还会被正常执行完
Thread.sleep(ThreadLocalRandom.current().nextInt(10000));
//任务超时后 这句日志不会被打印出来:xxl-job任务需用XxlJobLogger输出日志
XxlJobLogger.log("执行完毕");
return ReturnT.SUCCESS;
}
}
xxl-job任务需用XxlJobLogger输出日志
单机模式:只启动一个任务执行器实例,修改路由模式即便是广播模式依然只有一个实例运行job
集群模式:启动多个任务实例,这里可以把每个实例的端口号都改为不同,可以看到同一个任务类有多个机器。除了广播模式,其他模式都只会选择机器列表中的一个执行job
单机多任务分片
对于多10条数据,我们可以创建多个任务每个任务完成不同的ID数据,只要ID不重合,那么就不会重复执行对应的事务
这里我们按id划分,[1,3,5,7,9],[2,4,6,8,10]为两组
@XxlJob(value = "singleMachineMultiTasks", init = "init", destroy = "destroy")
public ReturnT<String> singleMachineMultiTasks(String cities) throws Exception {
if (StringUtils.isEmpty(cities)) {
return new ReturnT(FAIL_CODE, "latnIds不能为空");
}
XxlJobLogger.log("任务参数={}", cities);
//str转int数组,遍历ID列表
Arrays.stream(cities.split(",")).map(String::trim).filter(StringUtils::isNotBlank).map(Integer::parseInt).forEach(latnId -> {
//获取对应ID的未处理数据集合,遍历未处理数据集合并执行对应业务
List<String> tasks = singleMachineMultiTasks.get(latnId);
Optional.ofNullable(tasks).ifPresent(todoTasks -> {
todoTasks.forEach(task -> {
XxlJobLogger.log("【{}】执行【{}】,任务内容为:{}", Thread.currentThread().getName(), latnId, task);
});
});
});
return ReturnT.SUCCESS;
}
分别启动两个任务,并在管理器上配置好对应的参数
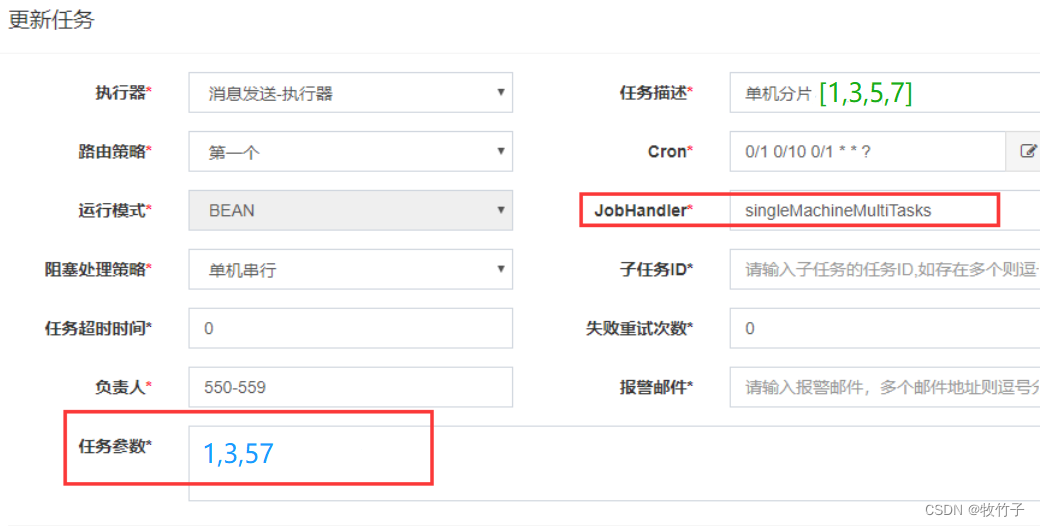
查看执行日志,两个控制台分别打印对应的执行日志如下:
任务参数=1,3,5,7,9
【1】执行【{Thread-1}】,任务内容为:{武汉}
【3】执行【{Thread-1}】,任务内容为:{北京}
【5】执行【{Thread-1}】,任务内容为:{上海}
任务参数=2,4,6,8,10
【2】执行【{Thread-20}】,任务内容为:{222}
【4】执行【{Thread-20}】,任务内容为:{444}
【6】执行【{Thread-20}】,任务内容为:{666}
集群分片
采用多机器取模的方式,来为不同的机器指定各自服务的ID列表
@XxlJob(value = "multiMachineMultiTasks", init = "init", destroy = "destroy")
public ReturnT<String> multiMachineMultiTasks(String params) throws Exception {
ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();
int n = shardingVO.getTotal(); // 动态获取所有实例数
int i = shardingVO.getIndex(); // 当前为第i个序号
IntStream.range(0, CITY_ID_LIST.size()).forEach(cityIndex -> {
//使用取余分片
if (cityIndex % n == i) {
int city = CITY_ID_LIST.get(cityIndex);
List<String> tasks = singleMachineMultiTasks.get(city);
Optional.ofNullable(tasks).ifPresent(todoTasks -> {
todoTasks.forEach(task -> {
XxlJobLogger.log("实例【{}】执行【{}】,任务内容为:{}", i, city, task);
});
});
}
});
return ReturnT.SUCCESS;
}
public void init() {
log.info("init");
}
public void destroy() {
log.info("destory");
}
如果不显示的指明生命周期函数,在方法执行完之后,会被销毁。
新增一个任务,路由策略为分片广播
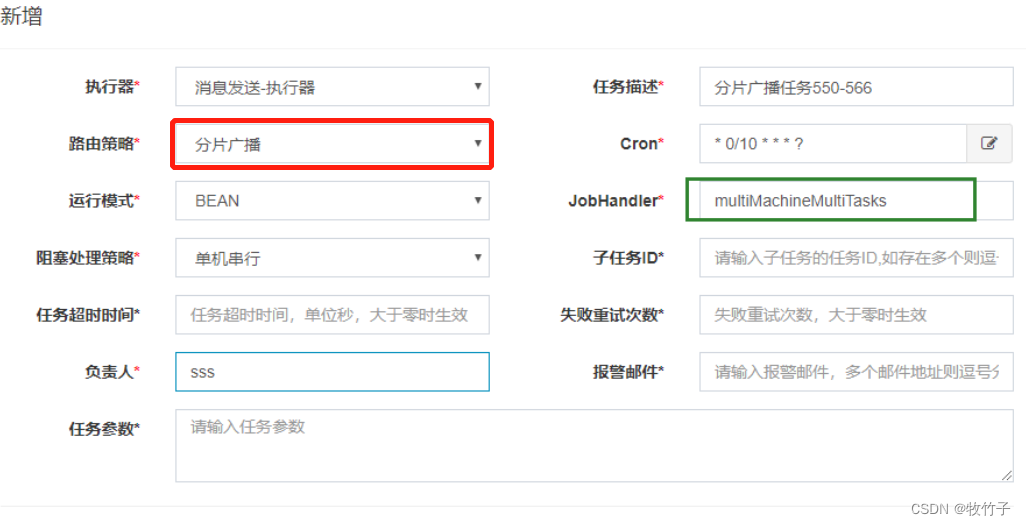
启动多个执行器实例

可以看到这个任务执执行器的机器地址有多个实例,说明它是集群模式运行。
查看控制台每个实例的日志都会根据取余分片执行不同的ID和任务内容
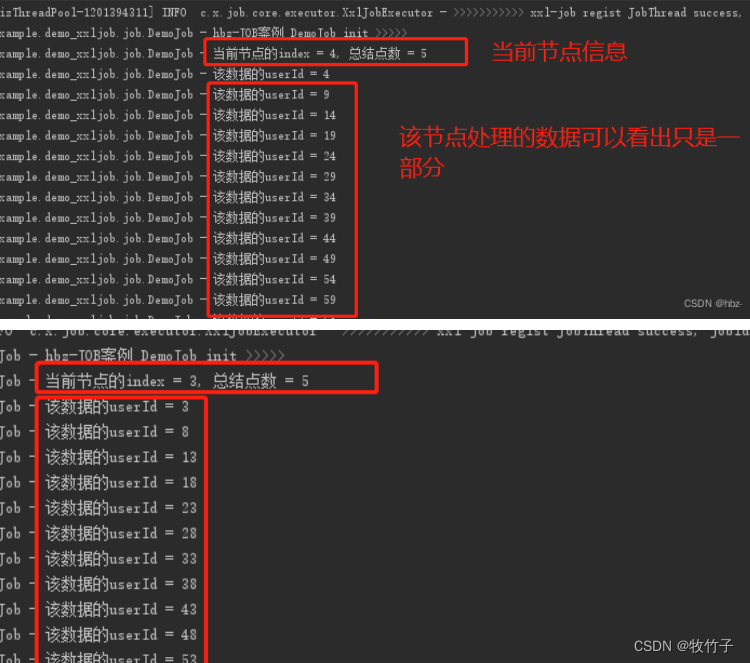
如果两个停一个,分片总数会发生变化,并且当前分片数也可能会发生变化
提出问题:取模方式对于顺序ID(自增ID)能很好的均匀分派分片数,那么对于范围分片(时间段分片)显然这里是没有提供类似分片算法的,根据实际项目情况,不一定非要用分片算法,不过不用分片算法,那么单例job又和没用有何区别呢?