OOM,out of memory,就是内存用完了耗尽了的意思。会触发kernel调用OOM killer杀进程来解除这种状况。
OOM分为虚拟内存OOM和物理内存OOM,两者是不一样的。
虚拟内存OOM发生在用户空间,用户空间分配的就是虚拟内存,不能分配物理内存,用户空间虚拟内存OOM表现为malloc、mmap等内存分配接口返回失败,错误码为ENOMEM。
程序在运行的时候触发缺页异常从而需要分配物理内存,kernel 自身在运行的时候也需要分配物理内存,如果此时物理内存不足了,就会发生物理内存OOM。
OOM是非常严重的问题,那我们如何监控、告警、甚至自愈呢?
1、采用 node_export + grafna + prometheus + alertmanager 监控
1.1、node_export 监控数据采集 --collector.vmstat
/opt/exporter/bin/node_exporter_51233 --web.listen-address=0.0.0.0:51233 --collector.cpu.info --collector.arp --collector.cpu --collector.diskstats --collector.filesystem --collector.loadavg --collector.meminfo --collector.mountstats --collector.nfs --collector.stat --collector.tcpstat --collector.vmstat
1.2、grafna 中写PromQL 制定 OOM 可视化
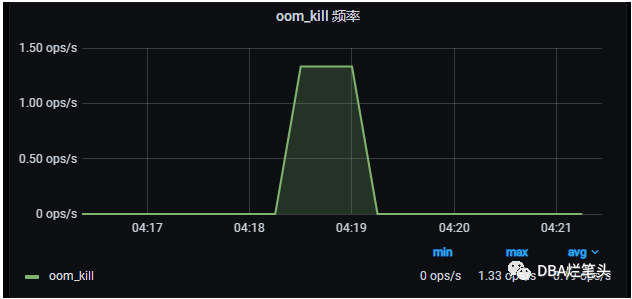
-- oom 频率increase(node_vmstat_oom_kill{host=~"$host"}[1m])
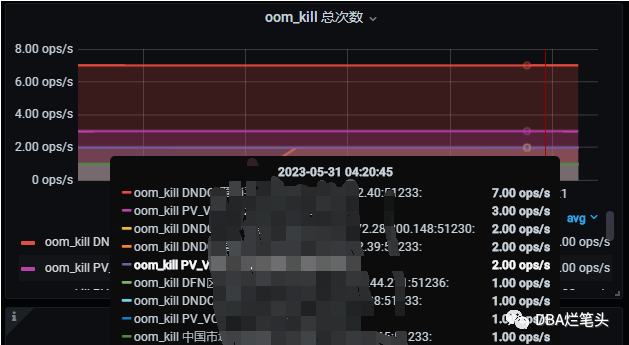
-- oom 总次数node_vmstat_oom_kill > 0
1.3、 prometheus 设定 rules oom 告警阈值
/opt/prometheus/rules/node_rules.yml 文件添加 oom 告警阈值
##alert for host oom
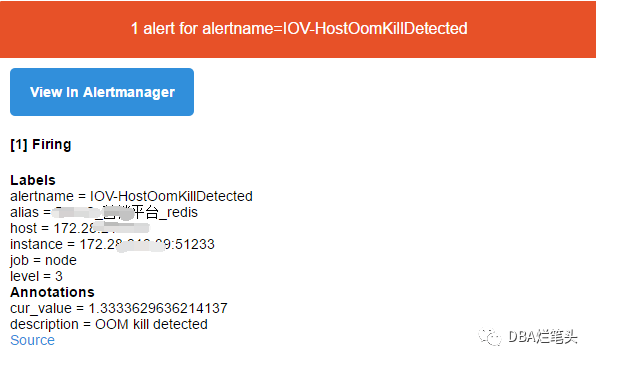
- alert: IOV-HostOomKillDetected
expr: increase(node_vmstat_oom_kill[1m]) > 0
for: 0m
labels:
level: 3
annotations:
cur_value: '{{ $value }}'
description: "OOM kill detected"
1.4、alertmanager 配置告警推送规则
alertmanager.yml 中配置,具体配置略
2、systemd服务自愈
systemd服务异常自动重启很好用,OOM就是通过kill -9来杀进程,没有
RestartPreventExitStatus 限定的情况下 服务异常中断会自愈重启。
但有的时候希望某些服务只在特定情况下进行重启,
systemd的[Service]段落里支持一个参数,叫做RestartPreventExitStatus
该参数从字面上看,意思是当符合某些退出状态时不要进行重启。
该参数的值支持exit code和信号名2种,可写多个,以空格分隔,例如
RestartPreventExitStatus=143 137 SIGTERM SIGKILL
[Unit] Description=mytest [Service] Type=simple ExecStart=/root/mytest.sh Restart=always RestartSec=5 StartLimitInterval=0 [Install] WantedBy=multi-user.target 重点参数详解 Restart=always: 只要不是通过systemctl stop来停止服务,任何情况下都必须要重启服务,默认值为no RestartSec=5: 重启间隔,比如某次异常后,等待5(s)再进行启动,默认值0.1(s) StartLimitInterval: 无限次重启,默认是10秒内如果重启超过5次则不再重启,设置为0表示不限次数重启
附上效果图:



![[Java基础]面向对象-内存解析](https://img-blog.csdnimg.cn/4513dd6d266b4ec2a7e184c51762c8bb.png)