1、引入
一个sql语句在mysql中究竟是如何运行的?又应该通过怎样的方式去查找我们要找的数据?这里就涉及到几种存储数据的算法;
可以做索引的数据结构有数组、链表、二叉搜索树和B树(B-树、B+树)。
2、各种数据结构
2.1、HASH
由于HASH查询和写入的时间复杂度是O(1),这意味着只需要一次hash计算就可以得出数据位置,但是会存在hash冲突,并且MySQL没有使用HASH表作为底层数据结构,是因为HASH不支持范围查找。
2.2、二叉搜索树
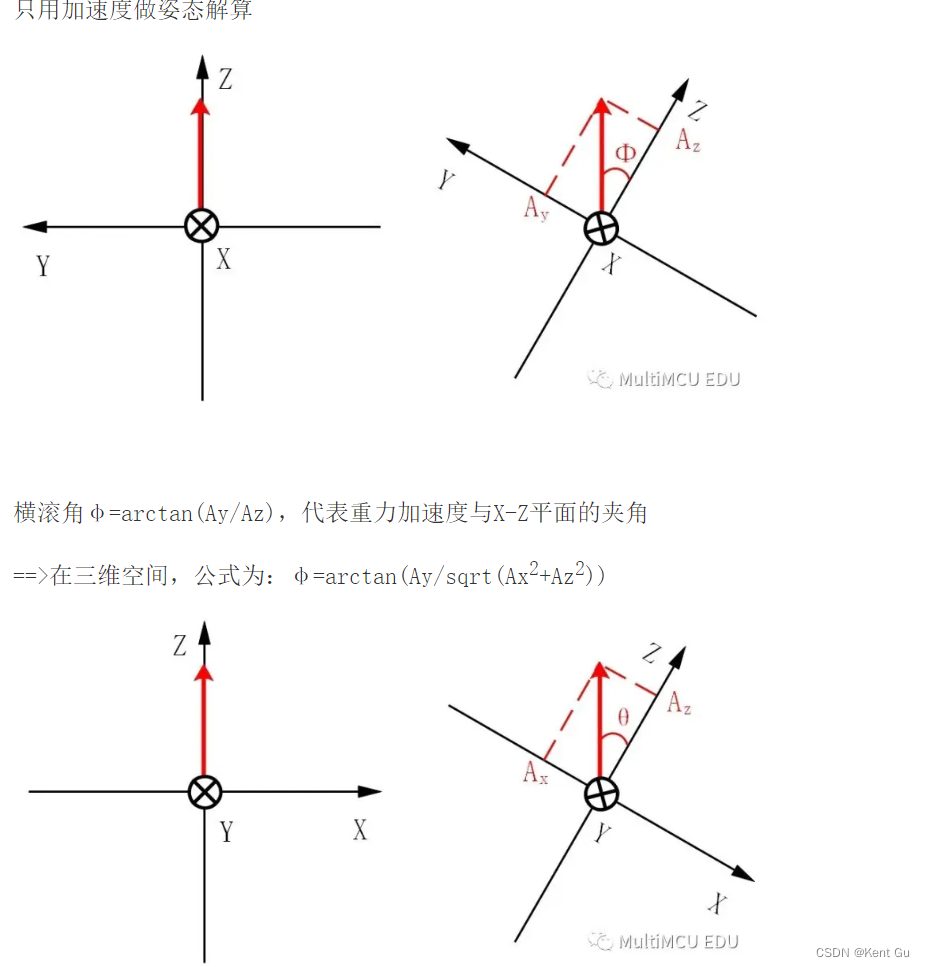
二叉搜索树的中序遍历结果是一个有序数组
1 2 3 4 5 6 7 8
二叉搜索树最好的时间复杂度是O(logN),最坏为O(N)
只写了10~11个元素,这棵树的树高就已经4层了,意味着每树高一层MySQL在查询数据的时候就多一次IO。
IO特性是系统中最重要的瓶颈,二叉搜索树在数据量非常大的时候是没有办法控制树的高度,所以也不是MySQL选用的数据结构。
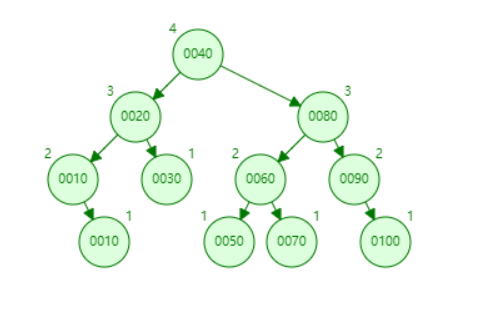
2.3、N叉搜索树
N叉搜索树是对二叉搜索树做了一个优化
*这棵树依然满足范围查找的要求
*有效的降低了树高
但MySQL依然觉得这棵树不太理想,于是在这个N叉搜索树上做了一些优化
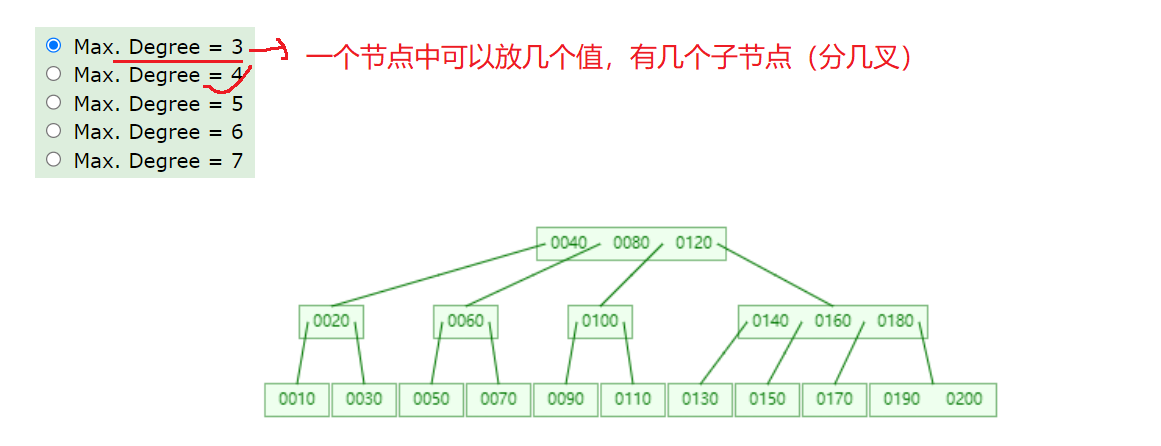
2.4、B+树
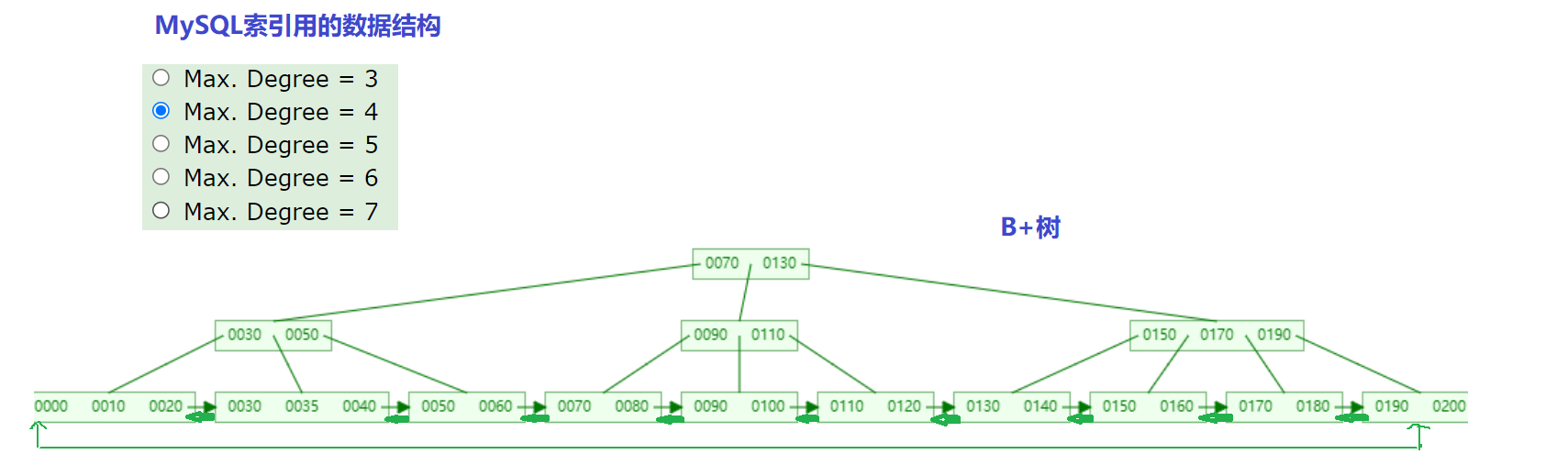
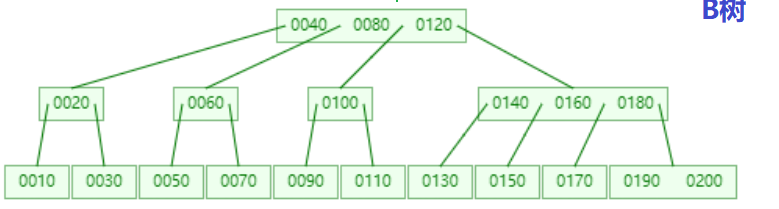
通过观察可以发现B树和B+树的一些区别,下面是对结果的总结
1、叶子页点之间都有一个相互连接的引用,可以通过一个叶子节点找到他相邻兄弟节点在MySQL中叶子节点之间是一个双向循环链表
2、非叶子节点的值,都包含在叶子节点中,在MySQL中非叶子节点保存了子节点的引用,没有存真实的数据,真实的数据全都放在了叶子节点。
3、对于B+树来说,在相同树高的情况下,查找任意元素的复杂度都是一样的,中间比较次数也都差不多,也就是说性能均衡,只要控制树高,就能达到性能可控的效果。
4、非叶子节点中的值,都是其他叶子节点中的第一个元素
3、MySQL读取数据
MySQL读取数据时,把数据放到一个叫数据页的这个单元中,每一个页大小是16kb,每一页对应的就是B+树中的一个节点。
如果我们一条数据只有1kb,那么一个叶子节点就可以放16条数据。如果我们用主键索引,非叶子节点保存的是它孩子节点的引用(6B),同时保存主键的值(8B),一个数据单元就只占用14B。
一个页(节点)的大小为16kb,一个对子节点的引用大小为14B,那么一页里就可以存1170个对字节点的引用。
最终三层树高的B+树就可以存放的数据是1170*1170*16=21,902,400条数据。
也就是说在符合上述的条件下,21,902,400条数据中可以控制在三层树高,那么MySQL就可以通过三次IO操作就把数据信息找出来。





![深度学习应用篇-计算机视觉-语义分割综述[5]:FCN、SegNet、Deeplab等分割算法、常用二维三维半立体数据集汇总、前景展望等](https://img-blog.csdnimg.cn/img_convert/fedba1bf4939202cb836f27254ff6ff5.png)