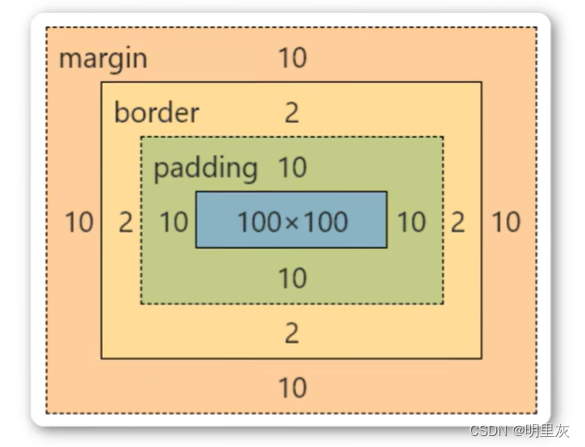
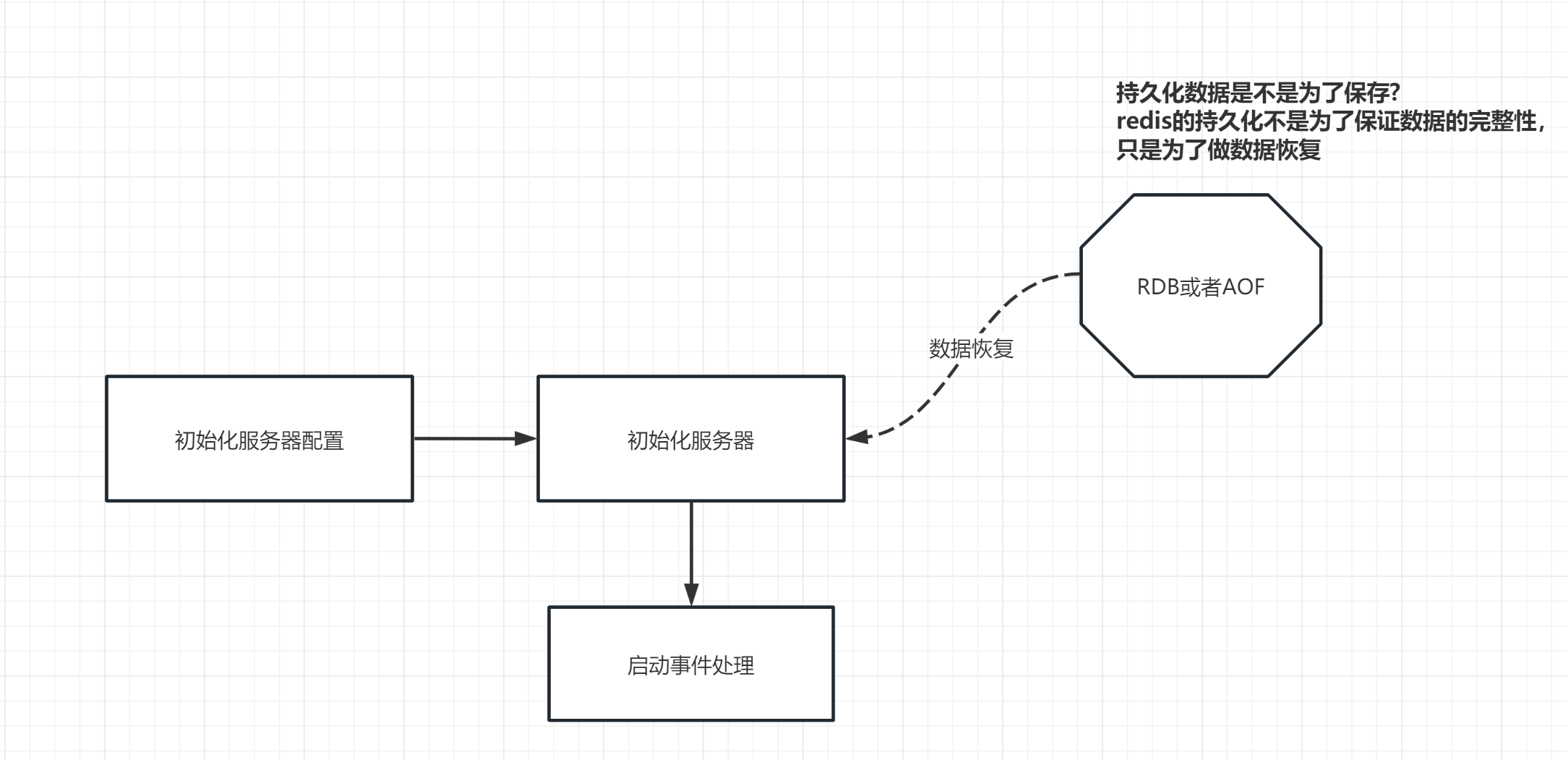
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。那么redis的底层是如何来存储数据的呢?
一、redis如何在存储大量的key时候,查询速度还能接近O(1)呢?
查询速度接近O(1)的数据结构通常让我们想到的就是HashMap结构,那下面我从源码来追踪下redis到底是不是使用的HashMap结构呢?生成的全局hashTable的大小为4
redis的数据最外层的结构是redisDb(server.h文件) ,其定义如下:
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;
从上面定义我们可以看出redisDb 的保存数据的结构是dict(dict.h),那么我们从文件中获取
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */
} dict;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
dict 包含了两个hash表(dictht ht[2]),这里使用两个hash表就是为了后续给渐进式rehash来进行服务的.属性rehashidx == -1时候代表不是处于reshaing中。
dictht 就一个hashtable,其包含dictEntry 的数组。然后我们继续看下
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
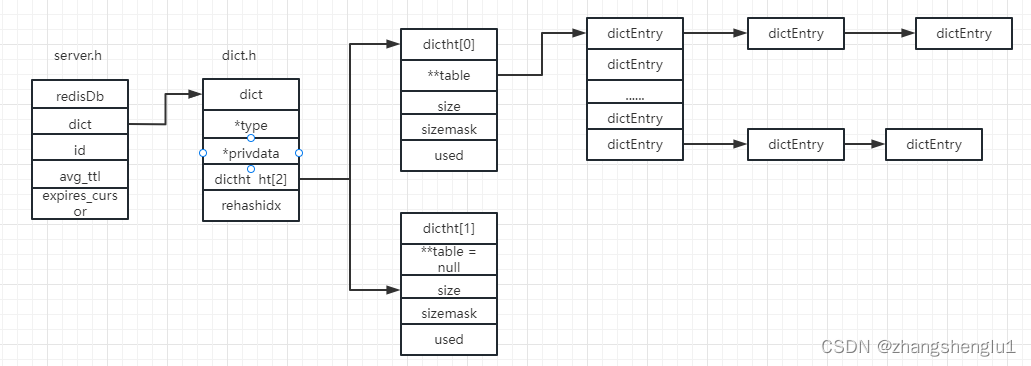
dictEntry 的就是hash表中的一个键值对,那么根据上面的代码我们可以绘出redis中内存结构图。
redis的rehash过程怎么处理呢?
随着redis中key的数据量增多,随着key的增多,那么dictEntry 连越来越长,这个时候查询出来的性能将会越来越慢。这个时候就需要对hashTable进行扩容,在数据量大的时候如果等到所有的扩容完成,那么必然会导致redis长时间等待,那么这个时候我们就采用渐进式rehash方式来进行扩容。
什么是渐进式rehash呢?
Redis 默认使用了两个全局哈希表:dictht[0]和哈希表 dictht[1],一开始,当你刚插入数据时,默认使用dictht[0],此时的dictht[1] 并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash,这个过程分为三步:
1、给dictht[1]分配更大的空间,一般是当前dictht[0]已使用大小的2倍,但是必须满足是2的整数倍!
2、把哈希表0 中的数据重新映射并拷贝到哈希表1 中(在hash表1下进行重新计算hash值);
3、释放哈希表 0 的空间
4、把dictht[0]指向刚刚创建好的dictht[1]
什么时候进行hash
- 1、在没有fork子进程进行RDS或者AOF数据备份的时候且ht[0] .used >= ht[0].size时
- 2、 在有fork子进程进行RDS或者AOF数据备份的时候且ht[0] .used > ht[0].size * 5时
扩容,肯定是在添加数据的时候才会扩容,所以我们找一个添加数据的入口,我们从源码层面进行下验证:
int dictReplace(dict *d, void *key, void *val)
{
dictEntry *entry, *existing, auxentry;
/* Try to add the element. If the key
* does not exists dictAdd will succeed. */
entry = dictAddRaw(d,key,&existing);
if (entry) {
dictSetVal(d, entry, val);
return 1;
}
/* Set the new value and free the old one. Note that it is important
* to do that in this order, as the value may just be exactly the same
* as the previous one. In this context, think to reference counting,
* you want to increment (set), and then decrement (free), and not the
* reverse. */
auxentry = *existing;
dictSetVal(d, existing, val);
dictFreeVal(d, &auxentry);
return 0;
}
然后继续查看dictAddRaw方法
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
long index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d);
/* Get the index of the new element, or -1 if
* the element already exists. */
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)
return NULL;
/* Allocate the memory and store the new entry.
* Insert the element in top, with the assumption that in a database
* system it is more likely that recently added entries are accessed
* more frequently. */
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}
然后继续往下看_dictKeyIndex方法
static long _dictKeyIndex(dict *d, const void *key, uint64_t hash, dictEntry **existing)
{
unsigned long idx, table;
dictEntry *he;
if (existing) *existing = NULL;
/* Expand the hash table if needed */
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
for (table = 0; table <= 1; table++) {
idx = hash & d->ht[table].sizemask;
/* Search if this slot does not already contain the given key */
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key)) {
if (existing) *existing = he;
return -1;
}
he = he->next;
}
if (!dictIsRehashing(d)) break;
}
return idx;
}
从上面代码注释可以看出来,_dictExpandIfNeeded就是用来进行扩容的
/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
if (!dictTypeExpandAllowed(d))
return DICT_OK;
if ((dict_can_resize == DICT_RESIZE_ENABLE &&
d->ht[0].used >= d->ht[0].size) ||
(dict_can_resize != DICT_RESIZE_FORBID &&
d->ht[0].used / d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used + 1);
}
return DICT_OK;
}
- 1、在hashtable扩容的时候,如果正在扩容的时将不会出发扩容操作
- 2、DICT_HT_INITIAL_SIZE的大小为4,即默认创建的hashtable大小为4
- 3、dict_force_resize_ratio的值为5
*这里需要关注dict_can_resize 这个字段什么时候被赋值了,