目录
前言:
引入背景:
练习:

前言:
在第十三篇我们已经详细的介绍了多表查询的类别以及每一个类别的语法:【MySQL数据库 | 第十三篇】多表查询,今天我们将通过案例来巩固我们对多表查询语法的熟悉度。
引入背景:
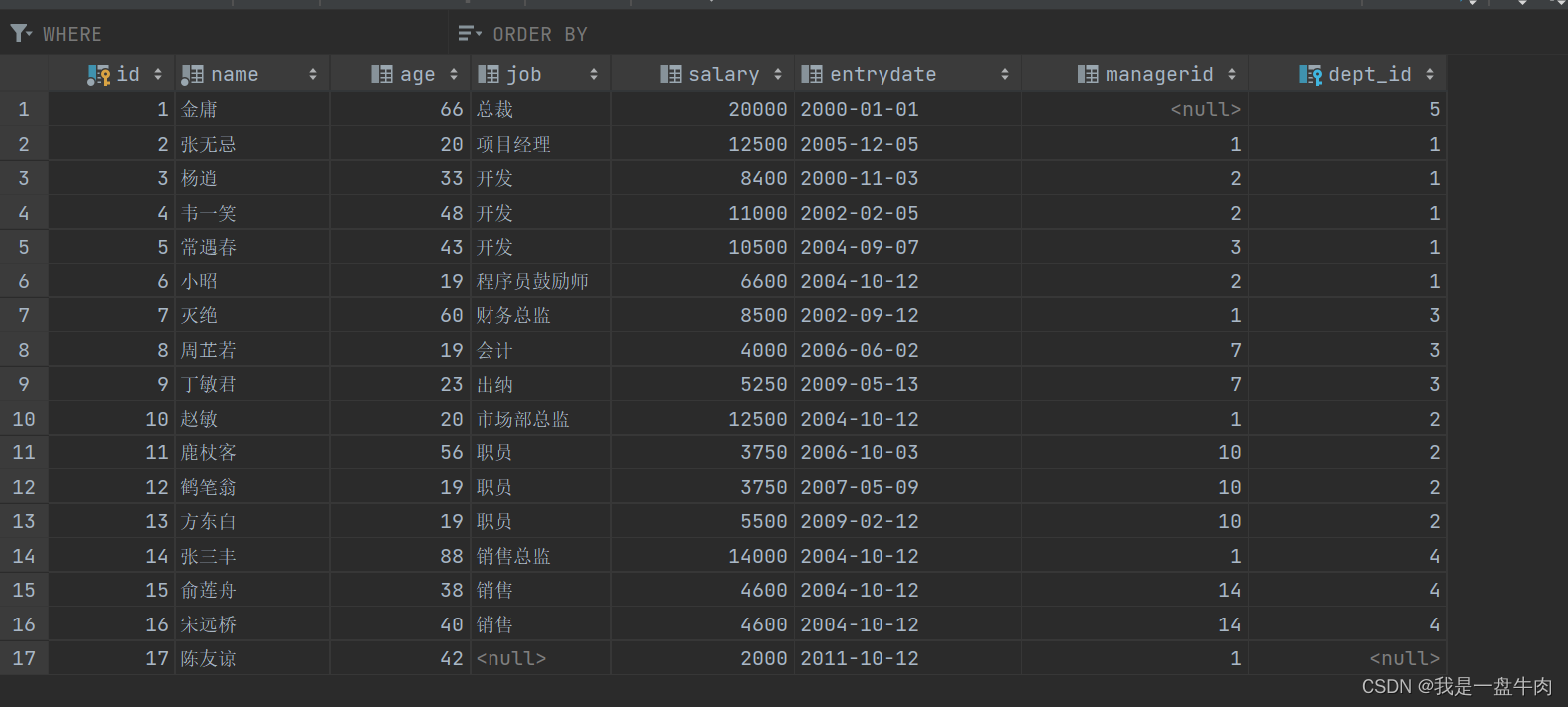
demp表:
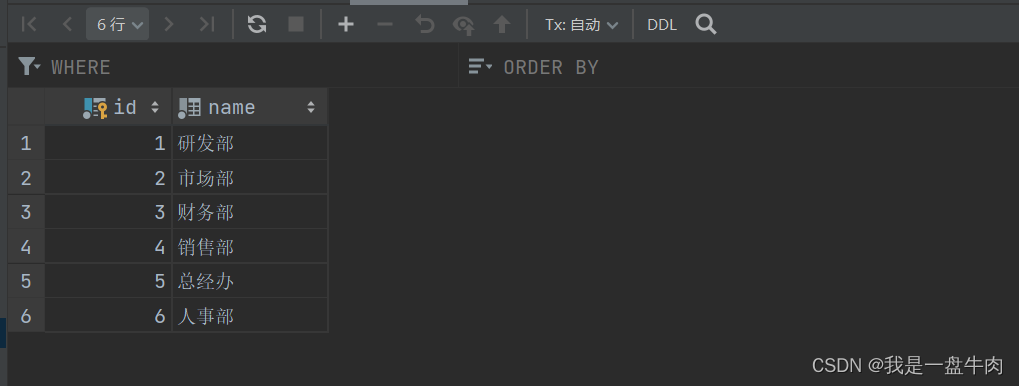
demp表:
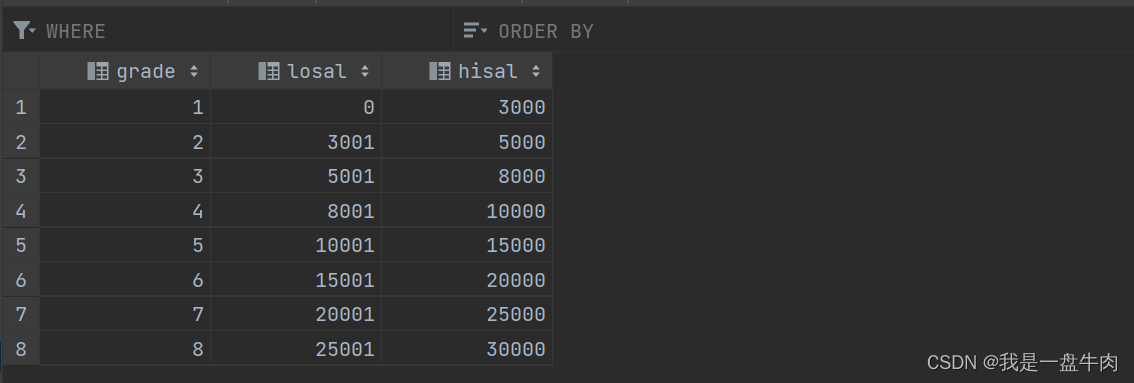
salgard表:
练习:
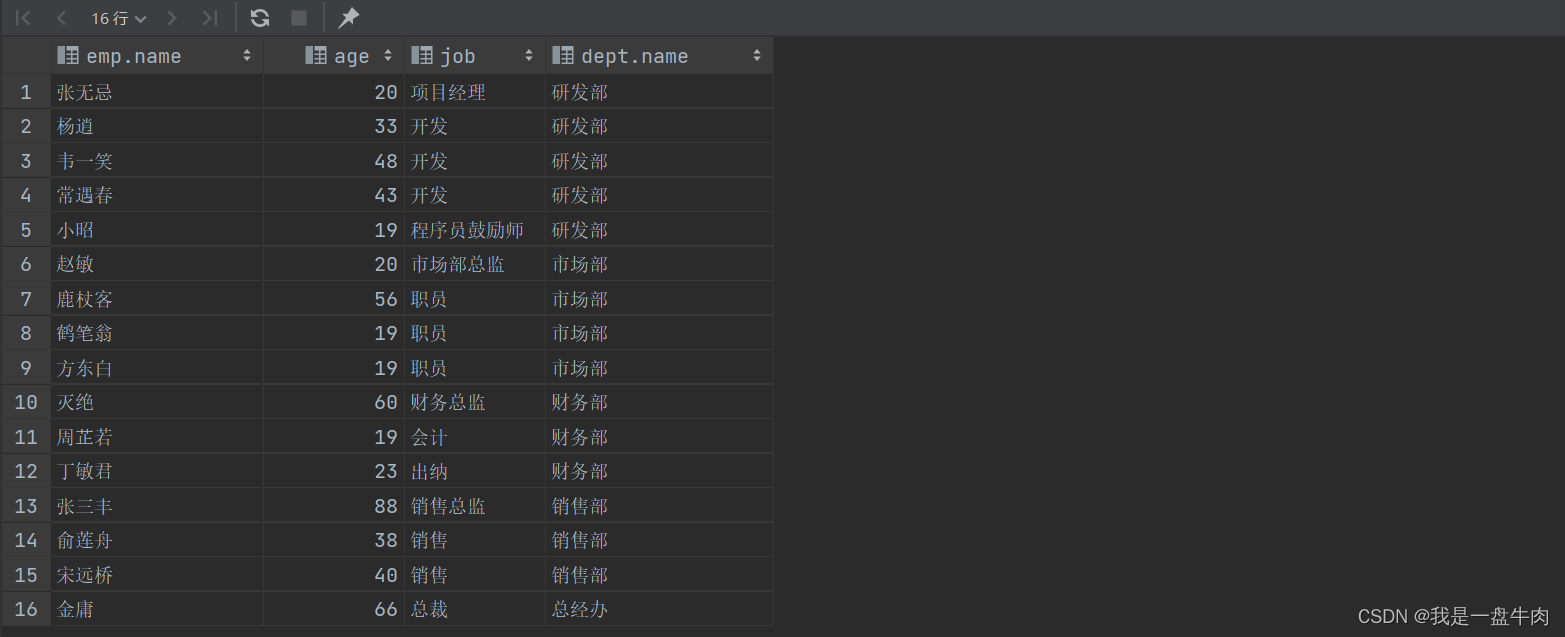
1.查询员工的姓名,年龄,职位,部门信息(隐式内连接)
select emp.name,emp.age,emp.job,dept.name from emp,dept where dept_id=dept.id;运行结果:
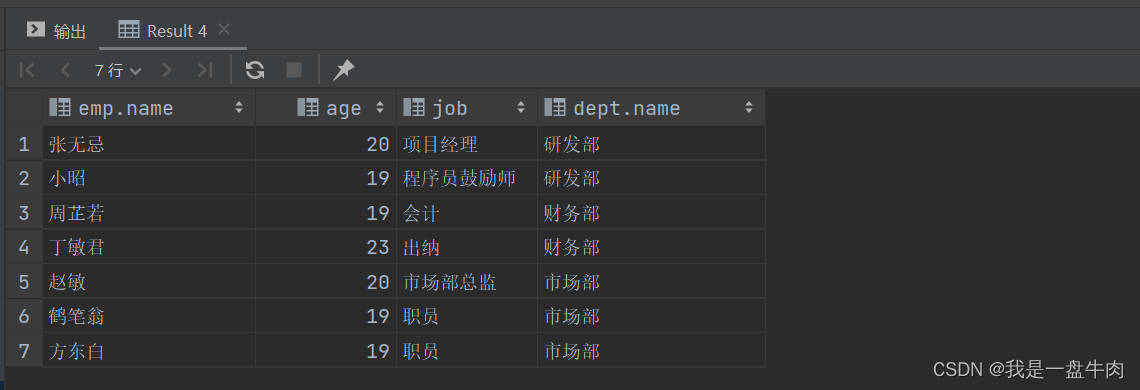
2.查询年龄小于30岁的员工姓名,年龄,职位,部门信息(显示内连接)
select emp.name,emp.age,emp.job,dept.name from emp join dept on emp.dept_id = dept.id where emp.age<30;运行结果:
3.查询所有员工的部门id,部门名称
select emp.name,emp.dept_id,d.name from emp left join dept d on emp.dept_id = d.id;运行结果:

4.查询所有年龄大于40岁的员工,以及其所属的部门的名称,如果员工没有分配部门,也要打印出
select emp.name,emp.dept_id,d.name from emp left join dept d on emp.dept_id = d.id where age>40;运行结果:

注意:
很多人在这里,会把两个条件之间的连接写成and,即:

此时的结果是:
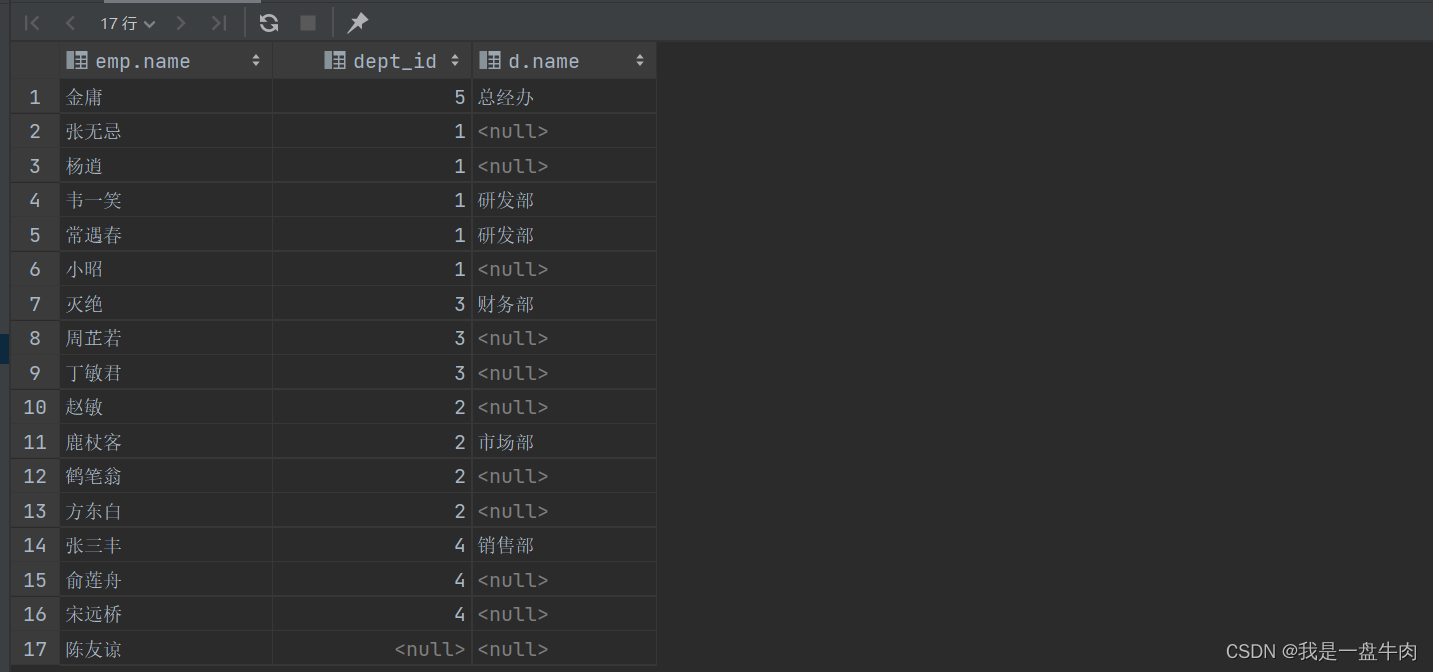
这是因为:
第一个查询中,条件 age > 40 是被放置在 WHERE 子句中的,它是针对整个查询结果集的筛选,即首先根据 emp 表中的 age 字段筛选出年龄大于40岁的记录,然后将符合条件的结果集再与 dept 表进行左连接。而第二个查询中,条件 age > 40 是在 JOIN 子句中进行指定的,它是在连接两个表时使用的筛选条件(所以我们可以看到age不满足条件的dept_id并没有和把dept重命名为d的d.name进行连接,虽然有部门id,但是不打印部门名称)。
具体来说,第一个查询会返回 emp 表中年龄大于40岁的员工记录,并将这些记录与 dept 表按照 emp 表中的 dept_id 字段进行左连接。因此,如果有一名员工的年龄大于40岁,但其所在部门在 dept 表中不存在,则该员工的部门名称为 NULL。
第二个查询会先将 emp 表与 dept 表左连接,然后筛选出符合条件 age > 40 的记录。因此,该查询的结果集中包括了 emp 表和 dept 表中所有符合连接条件的记录,但是未满足筛选条件的记录并不会包含在结果集中。
总的来说,第一个查询是先筛选再连接,而第二个查询是先连接再筛选。这会对查询结果产生影响,因此,在编写 SQL 查询时,需要根据具体的需求选择合适的查询条件和筛选方式。
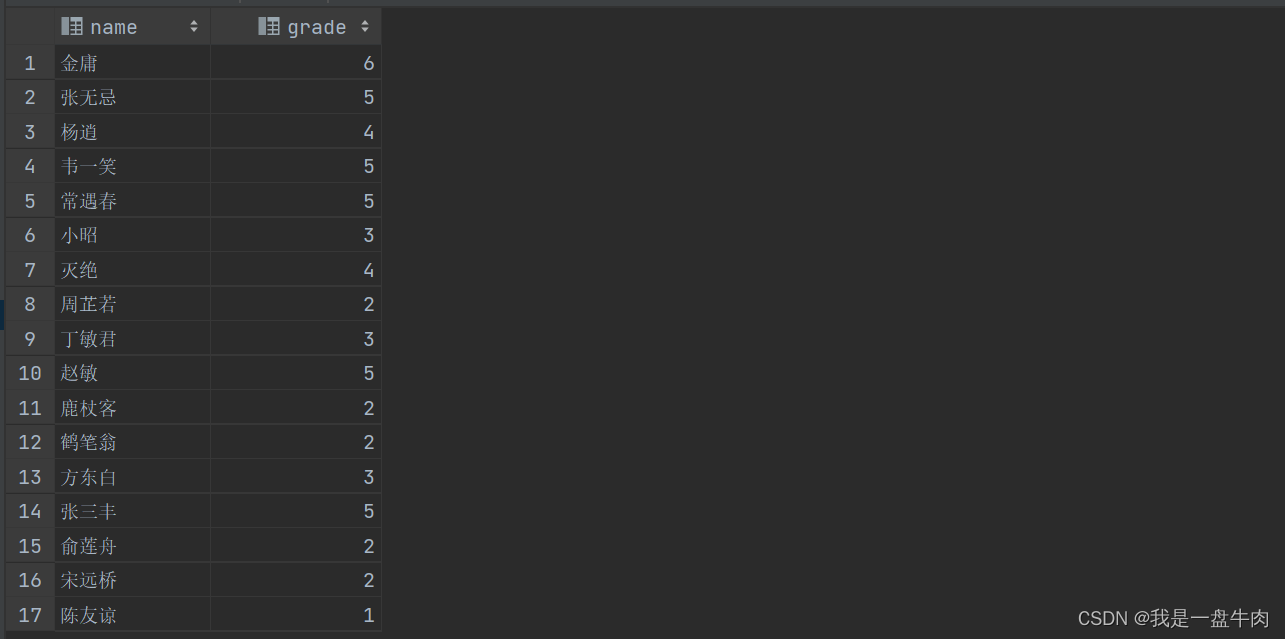
5.查询所有员工的薪资等级
select emp.name,salgrade.grade from emp,salgrade where emp.salary between salgrade.losal and salgrade.hisal;运行结果:
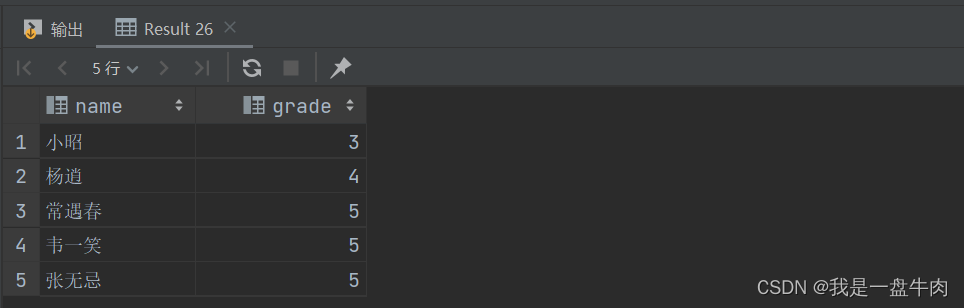
6。查询‘研发部’所有员工的信息以及工资等级
select emp.name,salgrade.grade from emp,salgrade where emp.salary between salgrade.losal and salgrade.hisal and emp.dept_id=(select dept.id from dept where dept.name='研发部');运行结果:
7.查询研发部平均工资
select avg(emp.salary) as '研发部平均工资'from emp,dept where emp.dept_id=dept.id and dept.name='研发部';运行结果:

8.查询工资比‘灭绝’高的员工
select emp.name,emp.salary from emp where salary>(select emp.salary from emp where emp.name='灭绝');运行结果: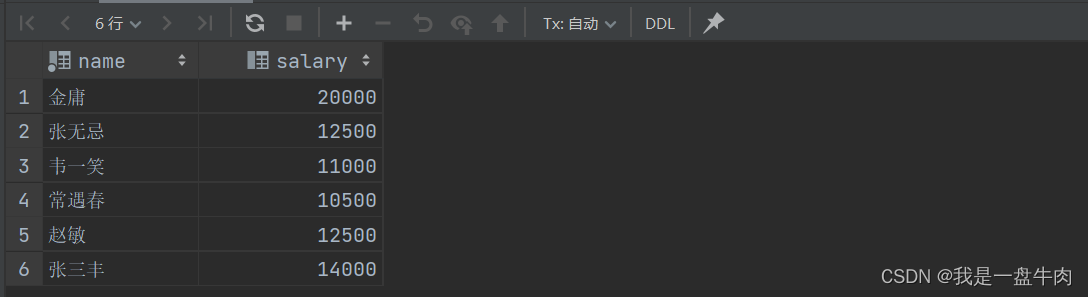
9.查询比平均薪资高的员工
select emp.name,emp.salary from emp where salary>(select avg(emp.salary) as '研发部平均工资'from emp); 运行结果: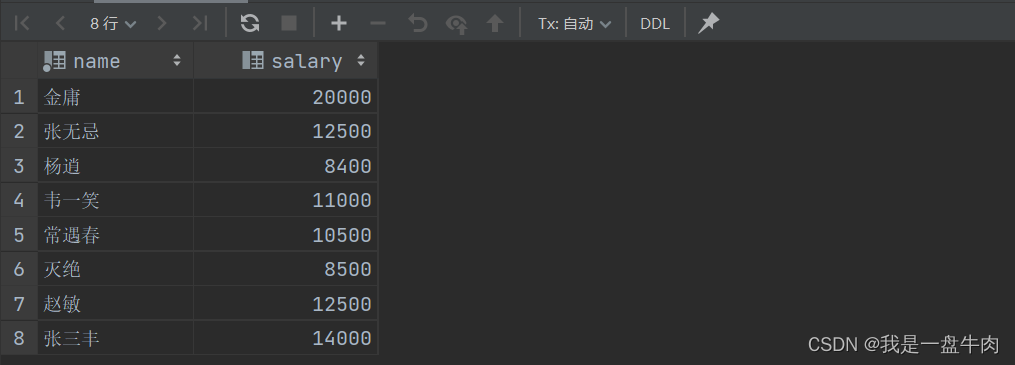
10.查询低于自己所属部门平均薪资的员工
select * from emp e2 where e2.salary<(select avg(e1.salary)from emp e1 where e1.dept_id=e2.dept_id);运行结果: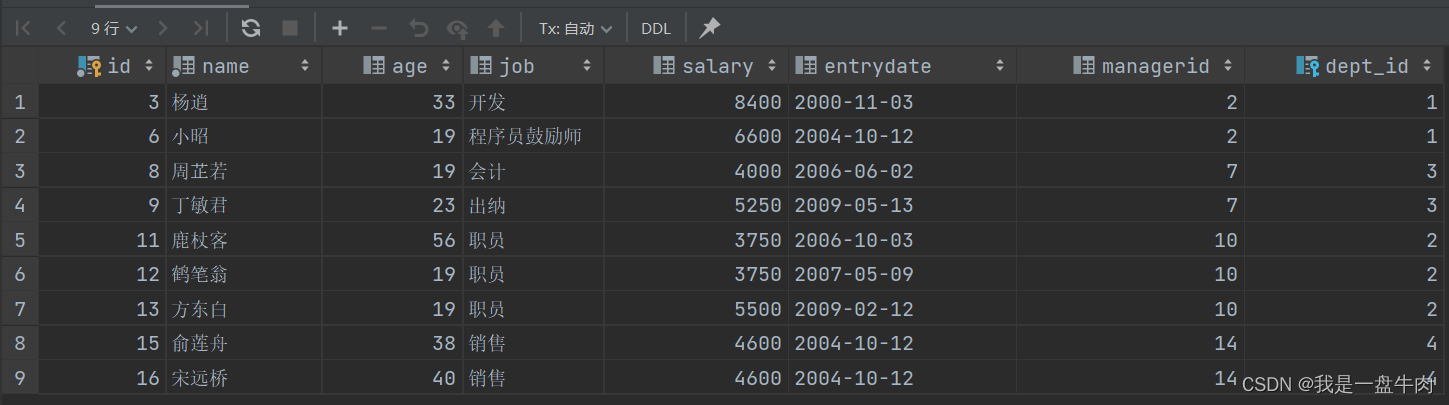
11.查询所有部门信息,统计员工人数:
select d.id ,d.name,(select count(*) from emp e where e.dept_id = d.id )'人数' from dept d;运行结果: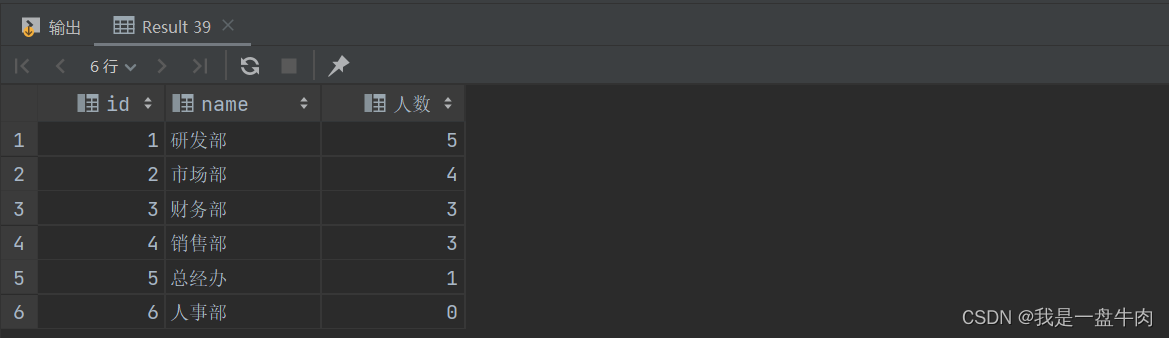
这个查询语句中使用了子查询,而且子查询被嵌套在主查询的SELECT语句中,因此可能会对性能产生影响,在部分情况下查询速度较慢。
优化建议:
1. 使用JOIN查询代替子查询
通常情况下,使用JOIN的效率要比使用子查询高。可以使用LEFT JOIN来连接emp表和dept表,然后在结果集中统计每个部门的员工数。
例如,可以使用如下的SQL查询语句来代替原有的子查询:
SELECT d.id, d.name, COUNT(e.emp_id) AS '人数'
FROM dept d
LEFT JOIN emp e ON d.id=e.dept_id
GROUP BY d.id;这样,可以在一条查询语句中完成所有计算,避免了多次查询的开销,并且通过合理的索引设计和调整,可以进一步提高查询效率。
2. 索引优化
在进行大量的统计查询时,使用合适的索引可以大大提高查询效率。对于此查询,可以在emp表的dept_id列和dept表的id列上分别建立索引,以加速查询。
3. 数据库结构优化
如果查询中使用的表和字段是经常访问的,则可以考虑对其进行垂直拆分优化,将其中的热点数据单独存放到一个表中,并配合索引等优化手段,以提高查询效率。
综上所述,优化查询的方法有很多种,需要针对具体的场景和业务需求进行选择和调整。在实践中,可以使用多种手段,综合优化查询语句的性能,以提高查询效率和减少资源消耗。
总结:
SQL语句的语法繁多,我们要多加练习才可以更高的掌握。
今天的内容到这里就结束了,感谢大家的阅读。
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力!