分类目录:《深入理解深度学习》总目录
《深入理解深度学习——注意力机制(Attention Mechanism):注意力汇聚与Nadaraya-Watson 核回归》中使用了高斯核来对查询和键之间的关系建模。式中的高斯核指数部分可以视为注意力评分函数(Attention Scoring Function), 简称评分函数(Scoring Function), 然后把这个函数的输出结果输入到Softmax函数中进行运算。 通过上述步骤,将得到与键对应的值的概率分布(即注意力权重)。 最后,注意力汇聚的输出就是基于这些注意力权重的值的加权和。
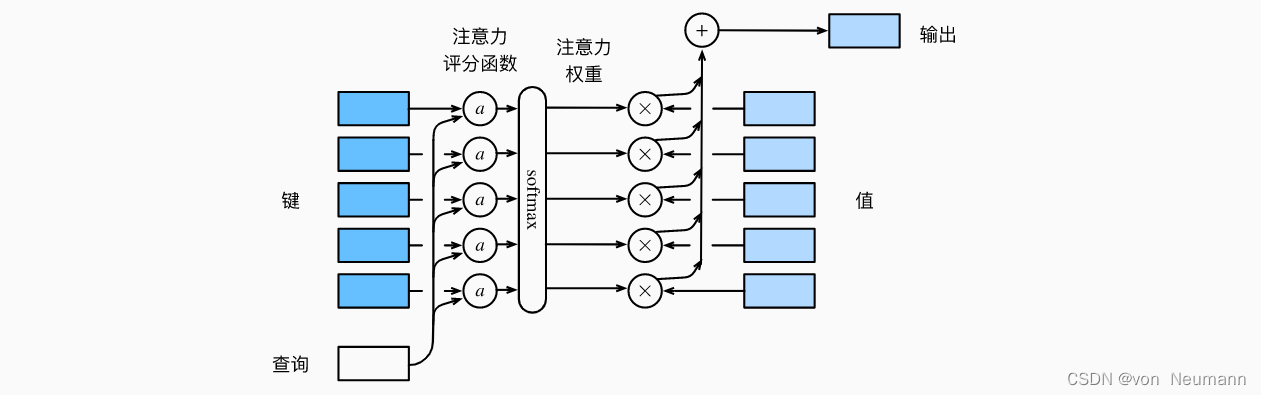
从宏观来看,上述算法可以用来实现注意力机制框架。 下图说明了如何将注意力汇聚的输出计算成为值的加权和, 其中表示注意力评分函数。 由于注意力权重是概率分布, 因此加权和其本质上是加权平均值。
用数学语言描述,假设有一个查询
q
∈
R
q
q\in R^q
q∈Rq和
m
m
m个“键—值”对
(
k
1
,
v
1
)
,
(
k
2
,
v
2
)
,
⋯
,
(
k
m
,
v
m
)
(k_1, v_1), (k_2, v_2), \cdots, (k_m, v_m)
(k1,v1),(k2,v2),⋯,(km,vm), 其中
k
i
∈
R
k
,
v
i
∈
R
v
k_i\in R^k, v_i\in R^v
ki∈Rk,vi∈Rv。 注意力汇聚函数就被表示成值的加权和:
f
(
q
,
(
k
1
,
v
1
)
,
(
k
2
,
v
2
)
,
⋯
,
(
k
m
,
v
m
)
)
=
∑
i
=
1
m
α
(
q
,
k
i
)
v
i
∈
R
v
f(q, (k_1, v_1), (k_2, v_2), \cdots, (k_m, v_m)) = \sum_{i=1}^m\alpha(q, k_i)v_i\in R^v
f(q,(k1,v1),(k2,v2),⋯,(km,vm))=i=1∑mα(q,ki)vi∈Rv
其中查询
q
q
q和键
k
i
k_i
ki的注意力权重(标量) 是通过注意力评分函数
α
\alpha
α将两个向量映射成标量, 再经过Softmax运算得到的:
α
(
q
,
k
i
)
=
Softmax
(
α
(
q
,
k
i
)
)
=
exp
(
α
(
q
,
k
i
)
)
∑
j
=
1
m
exp
(
α
(
q
,
k
i
)
)
∈
R
\alpha(q, k_i) = \text{Softmax}(\alpha(q, k_i))=\frac{\exp(\alpha(q, k_i))}{\sum_{j=1}^m\exp(\alpha(q, k_i))} \in R
α(q,ki)=Softmax(α(q,ki))=∑j=1mexp(α(q,ki))exp(α(q,ki))∈R
正如上图所示,选择不同的注意力评分函数会导致不同的注意力汇聚操作。 本节将介绍两个流行的评分函数,稍后将用他们来实现更复杂的注意力机制。
掩蔽softmax操作
正如上面提到的,Softmax操作用于输出一个概率分布作为注意力权重。 在某些情况下,并非所有的值都应该被纳入到注意力汇聚中。 例如,为了在高效处理小批量数据集, 某些文本序列被填充了没有意义的特殊词元。 为了仅将有意义的词元作为值来获取注意力汇聚, 可以指定一个有效序列长度(即词元的个数), 以便在计算Softmax时过滤掉超出指定范围的位置。 下面的masked_softmax函数实现了这样的掩蔽Softmax操作(Masked Softmax Operation), 其中任何超出有效长度的位置都被掩蔽并置为0。
def masked_softmax(X, valid_lens):
"""通过在最后一个轴上掩蔽元素来执行softmax操作"""
# X:3D张量,valid_lens:1D或2D张量
if valid_lens is None:
return tf.nn.softmax(X, axis=-1)
else:
shape = X.shape
if len(valid_lens.shape) == 1:
valid_lens = tf.repeat(valid_lens, repeats=shape[1])
else:
valid_lens = tf.reshape(valid_lens, shape=-1)
# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0
X = d2l.sequence_mask(tf.reshape(X, shape=(-1, shape[-1])),
valid_lens, value=-1e6)
return tf.nn.softmax(tf.reshape(X, shape=shape), axis=-1)
加性注意力
一般来说,当查询和键是不同长度的矢量时,可以使用加性注意力作为评分函数。 给定查询
q
∈
R
q
q\in R^q
q∈Rq和键
k
∈
R
k
k\in R^k
k∈Rk,加性注意力(Additive Attention)的评分函数为
α
(
q
,
k
)
=
w
v
T
tanh
(
W
q
q
+
W
k
k
)
∈
R
\alpha(q, k)=w^T_v\tanh(W_qq+W_kk)\in R
α(q,k)=wvTtanh(Wqq+Wkk)∈R
其中可学习的参数是 W q ∈ R h × q W_q\in R^{h\times q} Wq∈Rh×q、 W k ∈ R h × k W_k\in R^{h\times k} Wk∈Rh×k和 W v ∈ R h W_v\in R^h Wv∈Rh 。 如上式所示, 将查询和键连结起来后输入到一个多层感知机(MLP)中, 感知机包含一个隐藏层,其隐藏单元数是一个超参数。 通过使用 tanh \tanh tanh作为激活函数,并且禁用偏置项。
缩放点积注意力
使用点积可以得到计算效率更高的评分函数, 但是点积操作要求查询和键具有相同的长度。 假设查询和键的所有元素都是独立的随机变量, 并且都满足零均值和单位方差, 那么两个向量的点积的均值为0,方差为
d
d
d。 为确保无论向量长度如何, 点积的方差在不考虑向量长度的情况下仍然是1, 我们再将点积除以
d
\sqrt{d}
d, 则缩放点积注意力(Scaled Dot-product Attention)评分函数为:
α
(
q
,
k
)
=
q
T
k
d
\alpha(q, k)=\frac{q^Tk}{\sqrt{d}}
α(q,k)=dqTk
在实践中,我们通常从小批量的角度来考虑提高效率, 例如基于
n
n
n个查询和
m
m
m个“键—值”对计算注意力, 其中查询和键的长度为
d
d
d,值的长度为
v
v
v。 查询
Q
∈
R
n
×
d
Q\in R^{n\times d}
Q∈Rn×d、 键
K
∈
R
n
×
v
K\in R^{n\times v}
K∈Rn×v和值
V
∈
R
m
×
v
V\in R^{m\times v}
V∈Rm×v的缩放点积注意力是:
Softmax
(
Q
T
K
d
)
V
∈
R
n
×
v
\text{Softmax}(\frac{Q^TK}{\sqrt{d}})V\in R^{n\times v}
Softmax(dQTK)V∈Rn×v
参考文献:
[1] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015
[2] Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola. Dive Into Deep Learning[J]. arXiv preprint arXiv:2106.11342, 2021.