DBeaver数据库连接器 Download | DBeaver Community
shell命令
bin/spark-submit
–class cn.edu.ncut.sparkcore.wordcount.Test03_WordCount_cluster
–deploy-mode cluster
–master yarn
./sparkcore-1.0-SNAPSHOT.jar
10
血缘关系查看
toDebugString(): 查看血缘关系
1.从下往上看,中括号里数字越小,层级越高
2.±对应的是shuffle write 和shuffle read
3.shuffle之间之后的小括号 (2) 代表分区数量
4.血缘关系最终绘制成为了DAG有向无环图
5.DAG的一个黑点代表一个RDD转化
6.血缘关系中的 | 竖线代表沿用上面的分区数量
stage 和 Task 的切分在哪一个环节?
在Driver中
stage和Task切割流程
1 RDD object
将算子串联起来变成一个大的DAG有向无环图,还没有切分阶段和任务
2 DAG scheduler
切割stage和Task
3 Task scheduler
将上面切好的Task拿到Worker(standalone模式)或者Executor中执行
4 worker
执行Task
Application: 一个sparkContext对应一个application,一个spark程序只能有一个sparkcontext
Job:一个Action算子就会生成一个Job;sortBy和sortByKey自带一个job
Stage:Stage等于宽依赖(shuffle)的个数加1;ResultStage只有一个,最后需要执行的阶段
Task:一个Stage阶段中,最后一个RDD的分区个数就是Task的个数。
Application->Job->Stage->Task每一层都是1对n的关系。
阶段划分的源码解读
Stage:Stage等于宽依赖(shuffle)的个数加1;ResultStage只有一个,最后需要执行的阶段
在DAGScheduler类中
ResultStage
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties): Unit = {
var finalStage: ResultStage = null
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
// 划分阶段
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: BarrierJobSlotsNumberCheckFailed =>
// If jobId doesn't exist in the map, Scala coverts its value null to 0: Int automatically.
val numCheckFailures = barrierJobIdToNumTasksCheckFailures.compute(jobId,
(_: Int, value: Int) => value + 1)
logWarning(s"Barrier stage in job $jobId requires ${e.requiredConcurrentTasks} slots, " +
s"but only ${e.maxConcurrentTasks} are available. " +
s"Will retry up to ${maxFailureNumTasksCheck - numCheckFailures + 1} more times")
if (numCheckFailures <= maxFailureNumTasksCheck) {
messageScheduler.schedule(
new Runnable {
override def run(): Unit = eventProcessLoop.post(JobSubmitted(jobId, finalRDD, func,
partitions, callSite, listener, properties))
},
timeIntervalNumTasksCheck,
TimeUnit.SECONDS
)
return
} else {
// Job failed, clear internal data.
barrierJobIdToNumTasksCheckFailures.remove(jobId)
listener.jobFailed(e)
return
}
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
// Job submitted, clear internal data.
barrierJobIdToNumTasksCheckFailures.remove(jobId)
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
submitStage(finalStage)
}
createResultStage
private def createResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
checkBarrierStageWithDynamicAllocation(rdd)
checkBarrierStageWithNumSlots(rdd)
checkBarrierStageWithRDDChainPattern(rdd, partitions.toSet.size)
//
val parents = getOrCreateParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
// 创建一个resultStage
val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
getOrCreateParentStages
private def getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
getShuffleDependencies(rdd).map { shuffleDep =>
getOrCreateShuffleMapStage(shuffleDep, firstJobId)
}.toList
}
getShuffleDependencies(rdd)
private[scheduler] def getShuffleDependencies(
rdd: RDD[_]): HashSet[ShuffleDependency[_, _, _]] = {
val parents = new HashSet[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new ListBuffer[RDD[_]]
waitingForVisit += rdd
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.remove(0)
if (!visited(toVisit)) {
visited += toVisit
toVisit.dependencies.foreach {
case shuffleDep: ShuffleDependency[_, _, _] =>
parents += shuffleDep
case dependency =>
waitingForVisit.prepend(dependency.rdd)
}
}
}
parents
}
任务划分源码
1217行
private def submitMissingTasks(stage: Stage, jobId: Int): Unit = {
logDebug("submitMissingTasks(" + stage + ")")
// Before find missing partition, do the intermediate state clean work first.
// The operation here can make sure for the partially completed intermediate stage,
// `findMissingPartitions()` returns all partitions every time.
stage match {
case sms: ShuffleMapStage if stage.isIndeterminate && !sms.isAvailable =>
mapOutputTracker.unregisterAllMapOutput(sms.shuffleDep.shuffleId)
case _ =>
}
// Figure out the indexes of partition ids to compute.
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()
// Use the scheduling pool, job group, description, etc. from an ActiveJob associated
// with this Stage
val properties = jobIdToActiveJob(jobId).properties
runningStages += stage
// SparkListenerStageSubmitted should be posted before testing whether tasks are
// serializable. If tasks are not serializable, a SparkListenerStageCompleted event
// will be posted, which should always come after a corresponding SparkListenerStageSubmitted
// event.
stage match {
case s: ShuffleMapStage =>
outputCommitCoordinator.stageStart(stage = s.id, maxPartitionId = s.numPartitions - 1)
case s: ResultStage =>
outputCommitCoordinator.stageStart(
stage = s.id, maxPartitionId = s.rdd.partitions.length - 1)
}
val taskIdToLocations: Map[Int, Seq[TaskLocation]] = try {
stage match {
case s: ShuffleMapStage =>
partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap
case s: ResultStage =>
partitionsToCompute.map { id =>
val p = s.partitions(id)
(id, getPreferredLocs(stage.rdd, p))
}.toMap
}
} catch {
case NonFatal(e) =>
stage.makeNewStageAttempt(partitionsToCompute.size)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
stage.makeNewStageAttempt(partitionsToCompute.size, taskIdToLocations.values.toSeq)
// If there are tasks to execute, record the submission time of the stage. Otherwise,
// post the even without the submission time, which indicates that this stage was
// skipped.
if (partitionsToCompute.nonEmpty) {
stage.latestInfo.submissionTime = Some(clock.getTimeMillis())
}
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
// TODO: Maybe we can keep the taskBinary in Stage to avoid serializing it multiple times.
// Broadcasted binary for the task, used to dispatch tasks to executors. Note that we broadcast
// the serialized copy of the RDD and for each task we will deserialize it, which means each
// task gets a different copy of the RDD. This provides stronger isolation between tasks that
// might modify state of objects referenced in their closures. This is necessary in Hadoop
// where the JobConf/Configuration object is not thread-safe.
var taskBinary: Broadcast[Array[Byte]] = null
var partitions: Array[Partition] = null
try {
// For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep).
// For ResultTask, serialize and broadcast (rdd, func).
var taskBinaryBytes: Array[Byte] = null
// taskBinaryBytes and partitions are both effected by the checkpoint status. We need
// this synchronization in case another concurrent job is checkpointing this RDD, so we get a
// consistent view of both variables.
RDDCheckpointData.synchronized {
taskBinaryBytes = stage match {
case stage: ShuffleMapStage =>
JavaUtils.bufferToArray(
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef))
case stage: ResultStage =>
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef))
}
partitions = stage.rdd.partitions
}
if (taskBinaryBytes.length > TaskSetManager.TASK_SIZE_TO_WARN_KIB * 1024) {
logWarning(s"Broadcasting large task binary with size " +
s"${Utils.bytesToString(taskBinaryBytes.length)}")
}
taskBinary = sc.broadcast(taskBinaryBytes)
} catch {
// In the case of a failure during serialization, abort the stage.
case e: NotSerializableException =>
abortStage(stage, "Task not serializable: " + e.toString, Some(e))
runningStages -= stage
// Abort execution
return
case e: Throwable =>
abortStage(stage, s"Task serialization failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
// Abort execution
return
}
// 任务的划分
val tasks: Seq[Task[_]] = try {
val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array()
stage match {
case stage: ShuffleMapStage =>
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = partitions(id)
stage.pendingPartitions += id
new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId, stage.rdd.isBarrier())
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId,
stage.rdd.isBarrier())
}
}
} catch {
case NonFatal(e) =>
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
if (tasks.nonEmpty) {
logInfo(s"Submitting ${tasks.size} missing tasks from $stage (${stage.rdd}) (first 15 " +
s"tasks are for partitions ${tasks.take(15).map(_.partitionId)})")
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties))
} else {
// Because we posted SparkListenerStageSubmitted earlier, we should mark
// the stage as completed here in case there are no tasks to run
markStageAsFinished(stage, None)
stage match {
case stage: ShuffleMapStage =>
logDebug(s"Stage ${stage} is actually done; " +
s"(available: ${stage.isAvailable}," +
s"available outputs: ${stage.numAvailableOutputs}," +
s"partitions: ${stage.numPartitions})")
markMapStageJobsAsFinished(stage)
case stage : ResultStage =>
logDebug(s"Stage ${stage} is actually done; (partitions: ${stage.numPartitions})")
}
submitWaitingChildStages(stage)
}
}
// 阶段当中的任务数量和当前阶段中最后一个分区的数量
override def findMissingPartitions(): Seq[Int] = {
val job = activeJob.get
(0 until job.numPartitions).filter(id => !job.finished(id))
}
窄依赖(没shuffle)算子的分区数量
就是沿用上面RDD的分区数量 称之为 OneToOneDependency继承于NarrowDependency
窄依赖表示每一个父(上游)RDD 的 Partition 最多被子(下游)RDD 的一个 Partition 使用, 窄依赖我们形象的比喻为独生子女。
宽依赖(ShuffleDependency)
继承于Dependency 我们称之为宽依赖
宽依赖表示同一个父(上游)RDD 的 Partition 被多个子(下游)RDD 的 Partition 依赖,会 引起 Shuffle,总结:宽依赖我们形象的比喻为多生。
如何改变分区的数量
分区改少了 coalesce(1,false)方法窄依赖 coalesce(1,true)宽依赖
分区改多了 coalesce(4,true)宽依赖 coalesce(4,false) 窄依赖不生效
repartition(4) = coalesce(4,true)
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
RDD没有数据,数据从哪里来呢?
RDD里面有数据的分区规则,在指定RDD的数据的来源,Task切割之后,会调度到Executor中执行,在执行的时候,Task根据RDD的数据分区的规则
再指定RDD的数据来源,直接去数据源去读取数据。
RDD里面为什么没有存储数据?
懒加载
比方说行动算子调用了first(),返回一条数据,但如果TextFile给整个文件的数据,如果懒加载,先把整个流程串联,遇到行动算子,发现最终的动作是只需要一条,那就没有给其他数据也加载出来了,就只加载一条数据就可以。
如果一个RDD中需要重复使用,那么需要从头再次执行来获取数据
cache
持久化操作,可以将数据重复使用
在底层调用的就是persist()方法
cache()默认持久化的操作,只能将数据保存到内存中,如果想要保存到磁盘文件,需要改存储级别
RDD 通过 Cache 或者 Persist 方法将前面的计算结果缓存,默认情况下会把数据以缓存 在 JVM 的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 算 子时,该 RDD 将会被缓存在计算节点的内存中,并供后面重用。
在数据执行较长,或数据比较重要的场合也可以使用持久化操作
会将血缘关系中添加新的依赖。一旦出现了问题可以重头读取数据
cache存储在内存,如果丢了怎么办?
- 可以设置存储级别为磁盘,或者内存加磁盘
- 仅内存丢了也无所谓,cache不打断血缘关系,cache丢了可以顺着血缘关系重新计算。
- 不需要指定目录,随着application结束而消失
checkpoint
需要落盘,需要指定检查点的保存路径
需要开发人员自己指定一个存储目录,即使application结束也不会删除。但是checkpoint打断血缘关系,如果ck的目录丢失,没法从头计算,所以,ck可以选择放在相对来说更加安全的文件系统上HDFS
checkpoint放在HDFS上错误
Perminssion denied:user 没有写的权限
System.*setProperty*("HADOOP_USER_NAME","admin");
checkpoint cache persist区别
-
cache:
- 将数据临时存储在内存中进行数据重用
-
persist: 将数据临时存储在磁盘文件中进行数据的重用
- 涉及到磁盘IO,性能较低,但是数据安全
如果作业执行完毕,临时保存的数据完成的数据文件就会丢失
- 涉及到磁盘IO,性能较低,但是数据安全
-
checkpoint:
- 将数据长久保存在磁盘文件中进行数据重用
涉及到磁盘IO,性能较低,但是数据安全
为了保证数据安全,所以,一般情况下,会独立执行作业- 为了能够提高效率,一帮情况下会和cache联合使用
- 执行过程中,会切断血缘关系。重新建立新的血缘关系,checkpoint等同于改变我们的数据源
- 将数据长久保存在磁盘文件中进行数据重用
checkpoint源码
SparkContext类中
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
if (stopped.get()) {
throw new IllegalStateException("SparkContext has been shutdown")
}
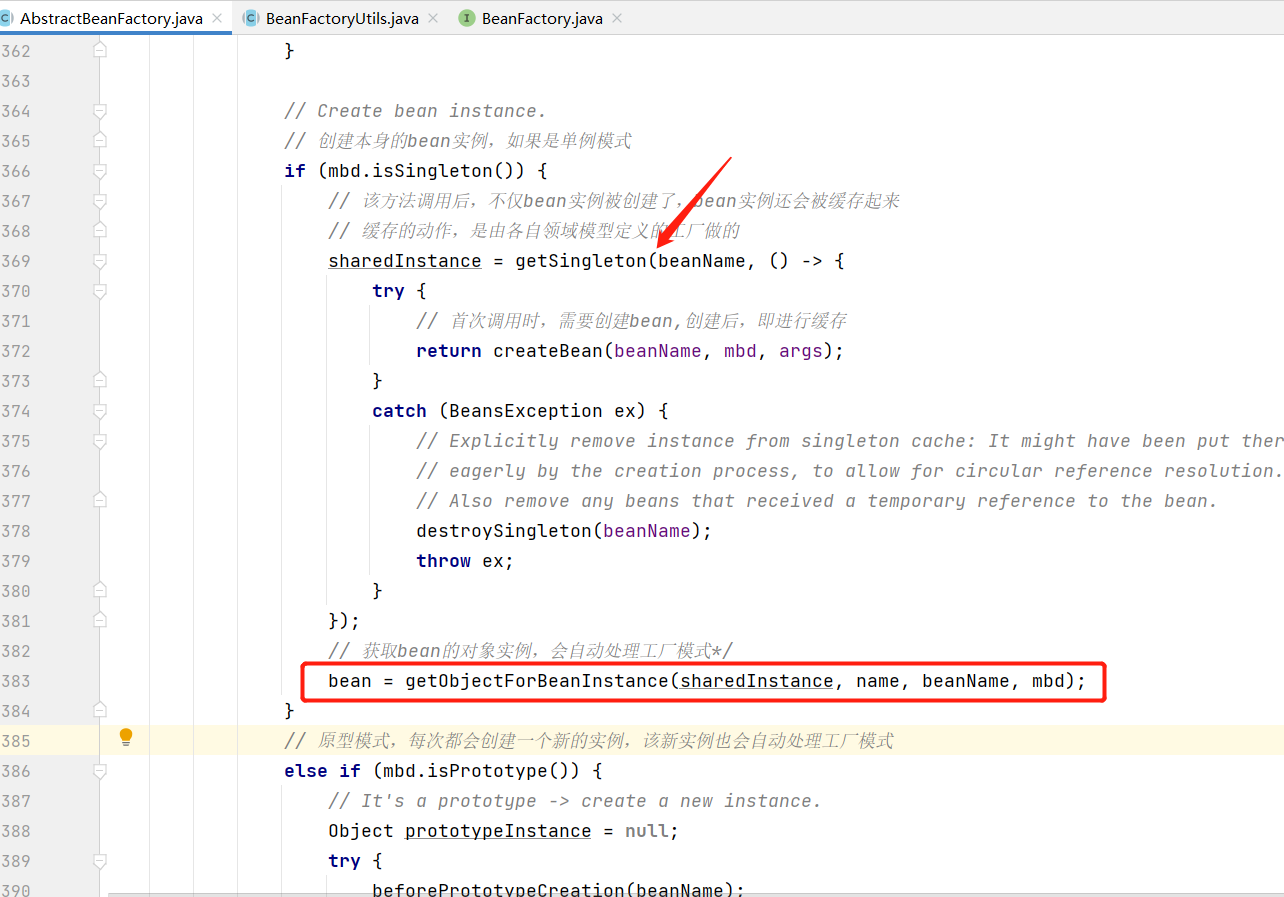
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
}
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
// 执行检查点操作
rdd.doCheckpoint()
}
在LocalRDDCheckpointData中
protected override def doCheckpoint(): CheckpointRDD[T] = {
val level = rdd.getStorageLevel
// Assume storage level uses disk; otherwise memory eviction may cause data loss
assume(level.useDisk, s"Storage level $level is not appropriate for local checkpointing")
// Not all actions compute all partitions of the RDD (e.g. take). For correctness, we
// must cache any missing partitions. TODO: avoid running another job here (SPARK-8582).
val action = (tc: TaskContext, iterator: Iterator[T]) => Utils.getIteratorSize(iterator)
val missingPartitionIndices = rdd.partitions.map(_.index).filter { i =>
!SparkEnv.get.blockManager.master.contains(RDDBlockId(rdd.id, i))
}
if (missingPartitionIndices.nonEmpty) {
rdd.sparkContext.runJob(rdd, action, missingPartitionIndices)
}
new LocalCheckpointRDD[T](rdd)
}
分区器
groupBy的分区器Optional[org.apache.spark.HashPartitioner@2]
sortBy的分区器Optional.empty
distinct的分区器Optional.empty
groupByKey的分区器Optional[org.apache.spark.HashPartitioner@2]
reduceByKey的分区器Optional[org.apache.spark.HashPartitioner@2]
sortByKey的分区器Optional[org.apache.spark.RangePartitioner@108e]
返回值是Key-Value类型,有分区器,除distinct
Spark数据倾斜怎么处理?
- 增加分区数量(simple)
- 改变分区器类型
- 自定义分区器
- SparkSQL能自动解决数据倾斜的问题
累加器使用
val sumAcc: LongAccumulator = sc.longAccumulator("sum")
累加器一般不结合转换算子使用,通常结合Action算子使用,foreach和foreachPartition
分布式共享只写变量
自定义累加器
/*
自定义数据累加器:WordCount
1. 继承AccumulatorV2类
定义我们的泛型
IN:累加器输入的数据类型
OUT: 累加器返回的数据类型
2. 重写方法()
*/
class MyAccumulator extends AccumulatorV2[String,mutable.Map[String,Long]]{
private var wcMap = mutable.Map[String,Long]()
// 判断是否为初始状态,表示初始值的意思
override def isZero: Boolean = {
wcMap.isEmpty
}
override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = {
new MyAccumulator()
}
// 重置累加器
override def reset(): Unit = {
wcMap.clear()
}
// 获取累加器需要计算的值
override def add(word: String): Unit = {
val newCount: Long = wcMap.getOrElse(word, 0L) + 1
wcMap.update(word,newCount)
}
// Driver合并多个累加器
override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = {
val map1 = this.wcMap
val map2 = other.value
map2.foreach {
case (word, count) => {
val newCount: Long = map1.getOrElse(word, 0L)+count
map1.update(word,newCount)
}
}
}
// 累加器结果
override def value: mutable.Map[String, Long] = {
wcMap
}
}
广播变量
分布式共享的只读变量。多个Task读取它
val bc: Broadcast[mutable.Map[String, Int]] = sc.broadcast(map)
热门品类 TopN
- 根据品类分组
- 根据热门规则统计每个品类的热门值
- 根据热门值进行倒叙排序,取前10
什么叫热门?
鞋 点击数 100 下单数70 支付数20
衣服 点击数100 下单数50 支付数10
带shuffle的算子有自动缓存功能
这个功能体现在多个Job当中
如果一个Application有多个Job,并且在shuflle之前共用一套代码逻辑,那么shuffle文件就会自带缓存
hive sql
-
sql解析器和语法优化器: hive
-
计算引擎: MR
-
数据来源: HDFS
spark sql (没有元数据,它需要谁的元数据就直接去谁的元数据库读)
-
sql解析器和语法优化器: spark
-
计算引擎: RDD
-
数据来源: 所有结构化数据
hive on spark
-
sql解析器和语法优化器: hive
-
计算引擎:RDD
-
数据来源:HDFS
spark on hive(spark SQL) 用Spark SQL计算Hive的数据
-
sql解析器和语法优化器: spark
-
计算引擎:RDD
-
数据来源:HDFS
生产环境用谁?
hive on spark 是基于Hadoop生态的,spark on hive 是基于spark生态的,我们的大数据平台是基于Hadoop生态搭建的,hive on spark跟hadoop 的兼容性要更好一些,可以牺牲一些性能考虑整体兼容性的问题。
spark sql在跟hadoop没有依赖关系的任务,为了运行更快可以使用spark sql
例如:将hive表当中的数据,导入到第三方(alibaba OSS)
SparkSession
一个Application可以对应多个SparkSession
普通的临时视图只有当前的session可用,全局的临时视图允许当前Application所有session使用
DSL
将SQL语法API化
CSV文件
严格意义上:以逗号分隔符的文件,Excel底层就是csv文件
广义上的CSV:以特定分割符分割的文件
parquet文件
列式存储的文件,表当中的每一列存储成一个文件
列存的好处:查询指定字段的时候性能大大提高
select name from user_info;
Spark SQL内置一个Hive
默认使用内置的hive,如何使用集群的hive ?告诉idea中的SparkSQL,集群上Hive元数据库的jdbc的位置,将hive-site.xml 放到idea当中的resources目录下
Spark提交流程
override def main(args: Array[String]): Unit = {
val submit = new SparkSubmit() {
self =>
override protected def parseArguments(args: Array[String]): SparkSubmitArguments = {
new SparkSubmitArguments(args) {
override protected def logInfo(msg: => String): Unit = self.logInfo(msg)
override protected def logWarning(msg: => String): Unit = self.logWarning(msg)
override protected def logError(msg: => String): Unit = self.logError(msg)
}
}
override protected def logInfo(msg: => String): Unit = printMessage(msg)
override protected def logWarning(msg: => String): Unit = printMessage(s"Warning: $msg")
override protected def logError(msg: => String): Unit = printMessage(s"Error: $msg")
override def doSubmit(args: Array[String]): Unit = {
try {
super.doSubmit(args)
} catch {
case e: SparkUserAppException =>
exitFn(e.exitCode)
}
}
}
submit.doSubmit(args)
}
每个Executor的线程数由谁决定
在提交的命令上可以指定Executor的线程数和Executor的数量
task的数量跟Executor的线程数不是一个概念(假设有1W个task能有1W个线程吗?)
driver是一个线程
- stage和task的划分
- task的调度
Executorbackend是一个JVM进程
它可以运行executor容器
Executor 对象级别
被new在了ExecutorBackend里,它的作用是运行task
Spark底层使用RPC通信协议
Spark现在的版本shuffle
一定会落盘,在最早期的Spark版本,Shuffle是先写入内存再写入磁盘。
1)shuffle reduce task数量小于等于spark.shuffle.sort.bypassMergeThreshold参数的值,默认为200。小于200使用bypassshuffle
storage
以Block存储,一个Block多大?一整个分区的大小,言外之意就是Spark的Cache缓存,以分区为单位存储的。
Block淘汰算法基于LRUCache算法(最近最少使用)
最小引用计数算法,这个算法会计算每个数据被使用的次数,删除的时候,删除使用频率最低的
Sparkstreaming
实时计算:毫秒级别
准实时:秒级别、分钟级别
离线计算:分钟、小时、天
流处理:来一条处理一条
批处理:来一批处理一批
流处理一定是实时计算吗?不一定
批处理一定是离线计算吗?
SparkStreaming:准实时,微批次。
Flink的批次非常小,处理的速度达到毫秒级别
SparkStreaming底层还是用的RDD来计算的。
SparkStreaming优雅关闭
如果关闭的时候有task正在运行,等当前task运行完成,再进行关闭。
如果kill掉,那就没办法优雅关闭了。
优雅关闭什么时候生效呢?项目有新功能上线,手动停掉,优雅关闭就起作用了。
RDD与IO之间的关系
val rdd: RDD = new HadoopRDD
val rrd1: RDD = new MapPartitionsRDD(rdd)
ShuffledRDD
装饰者模式

-
RDD的数据处理方式类似于IO流
-
RDD的数据只有在调用collect方法的时候,才会真正执行业务逻辑操作,之前的封装全部都是功能的扩展
-
RDD不保存的数据的但是IO可以临时保存一部分数据
RDD的概念
➢ 弹性
⚫ 存储的弹性:内存与磁盘的自动切换;
⚫ 容错的弹性:数据丢失可以自动恢复;
⚫ 计算的弹性:计算出错重试机制;
⚫ 分片的弹性:可根据需要重新分片。
➢ 分布式:数据存储在大数据集群不同节点上
➢ 数据集:RDD 封装了计算逻辑,并不保存数据
➢ 数据抽象:RDD 是一个抽象类,需要子类具体实现
➢ 不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在 新的 RDD 里面封装计算逻辑
➢ 可分区、并行计算
/ * - A list of partitions protected def getPartitions: Array[Partition]
* - A function for computing each split def compute(split: Partition, context: TaskContext): Iterator[T]
* - A list of dependencies on other RDDs protected def getDependencies: Seq[Dependency[_]] = deps
* - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) @transient val partitioner: Option[Partitioner] = None
* - Optionally, a list of preferred locations to compute each split on (e.g. block locations for
* an HDFS file) 首选的位置:判断计算发送到哪个节点效率最优
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
*/
- 移动数据,不如移动计算
将List写入文件的规则
ParallelCollectionRDD伴生对象中的方法
def slice[T: ClassTag](seq: Seq[T], numSlices: Int): Seq[Seq[T]] = {
if (numSlices < 1) {
throw new IllegalArgumentException("Positive number of partitions required")
}
// Sequences need to be sliced at the same set of index positions for operations
// like RDD.zip() to behave as expected
//length 5, numSlices 3
def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {
// 0 1 2
// 0 => start 0 end 1 (0,1)
// 1 => start 1 end 3 (1,3)
// 2 => start 3 end 5 (3,5)
(0 until numSlices).iterator.map { i =>
val start = ((i * length) / numSlices).toInt
val end = (((i + 1) * length) / numSlices).toInt
(start, end)
}
}
seq match {
case r: Range =>
positions(r.length, numSlices).zipWithIndex.map { case ((start, end), index) =>
// If the range is inclusive, use inclusive range for the last slice
if (r.isInclusive && index == numSlices - 1) {
new Range.Inclusive(r.start + start * r.step, r.end, r.step)
}
else {
new Range(r.start + start * r.step, r.start + end * r.step, r.step)
}
}.toSeq.asInstanceOf[Seq[Seq[T]]]
case nr: NumericRange[_] =>
// For ranges of Long, Double, BigInteger, etc
val slices = new ArrayBuffer[Seq[T]](numSlices)
var r = nr
for ((start, end) <- positions(nr.length, numSlices)) {
val sliceSize = end - start
slices += r.take(sliceSize).asInstanceOf[Seq[T]]
r = r.drop(sliceSize)
}
slices
case _ =>
val array = seq.toArray // To prevent O(n^2) operations for List etc
// 把长度传过去,把分区的数量传过去
positions(array.length, numSlices).map { case (start, end) =>
array.slice(start, end).toSeq
/* 0 => (0,1) => 1
1 => (1,3) => 2,3
2 => (3,5) => 4,5
*/
}.toSeq
}
}
ArrayOps类中的
override def slice(from: Int, until: Int): Array[T] = {
val reprVal = repr
val lo = math.max(from, 0)
val hi = math.min(math.max(until, 0), reprVal.length)
val size = math.max(hi - lo, 0)
val result = java.lang.reflect.Array.newInstance(elementClass, size)
if (size > 0) {
Array.copy(reprVal, lo, result, 0, size)
}
result.asInstanceOf[Array[T]]
}
val rdd: RDD[Int] = sc.makeRDD(List(4, 4, 5, 5,1), 3)
调用SparkContext类中的 maikeRDD()=> parallelize()
在parallelize()中创建了ParallelCollectionRDD对象
在ParallelCollectionRDD对象中的getPartitions()方法,调用了这个伴生对象中的slice()方法,并传入了List(4, 4, 5, 5,1)和分区的大小也就是3
在slice方法中判断传入的Seq是否属于 Range或者是NumericRange,如果不属于则使用默认的分区方法 case _ =>
val array = seq.toArray // To prevent O(n^2) operations for List etc
// 把长度传过去,把分区的数量传过去
positions(array.length, numSlices).map { case (start, end) =>
array.slice(start, end).toSeq
/* 0 => (0,1) => 1
1 => (1,3) => 2,3
2 => (3,5) => 4,5
*/
}.toSeq
在里面的positions()方法中传入当前List的长度和分区的大小,返回值是一个元素的集合
{
(0 until numSlices).iterator.map { i =>
val start = ((i * length) / numSlices).toInt
val end = (((i + 1) * length) / numSlices).toInt
(start, end)
}
i 从0到3 能取到 0 1 2 将i转换成了 元组集合为 (0,1) (1,3) (3,5)
之后在回到
positions(array.length, numSlices).map { case (start, end) =>
array.slice(start, end).toSeq
}.toSeq
进行模式匹配调用数组中的slice方法
override def slice(from: Int, until: Int): Array[T] = {
val reprVal = repr
val lo = math.max(from, 0)
val hi = math.min(math.max(until, 0), reprVal.length)
val size = math.max(hi - lo, 0)
val result = java.lang.reflect.Array.newInstance(elementClass, size)
if (size > 0) {
Array.copy(reprVal, lo, result, 0, size)
}
result.asInstanceOf[Array[T]]
}
因此数组的索引为第一个为 0
第二个为 1 2
第三个为 3 4
则形成的分区文件为 0号文件为 4
1号文件为4,5
2号文件为5,1
文件的分区规则
- 文件的分区数量的计算方式
spark 读取文件底层使用的就是Hadoop的读取方式使用TextInputFormat
long totalSize = 7; 文件的字节大小
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits); 7/2=3byte
Hadoop中的分区剩余的要大于 (1.1)
- 数据分区的分配
Spark读取文件,采用的是Hadoop的方式读取,所以一行一行读取,和字节数没有关系
数据读取时以偏移量为单位,偏移量不会被重复读取
1@@ => 012
2@@ => 345
3 => 6
数据分区的偏移量范围的计算
0 => [0,3]
1 => [3,6]
2 => [6,7]
RDD方法=>算子
算子 : Operator(操作)
RDD 的方法和Scala集合对象的方法不一样
集合对象的方法都是在同一个节点内存中完成的
RDD的方法可以将计算逻辑发送到Executor端(分布式节点)执行的
为了区分不同的处理效果,所以将RDD的方法称之为算子
RDD的方法外部的操作都是在Driver执行的,而方法内部的逻辑代码是在Executor端执行的
转换
功能的补充,将旧的RDD包装成新的RDD
-
flatMap()
-
map() 性能不够高 有一个mapPartitions()性能比较高
-
转换函数 mapPartitions() : 可以以分区为单位进行数据转换操作但是会将整个分区的数据加载到内存中进行引用 如果处理完的数据是不会被释放掉的,存在对象的引用内存较小,数据量较大的场合下,会出现内存溢出。
-
map与mapPartitions的区别
- Map 算子是分区内一个数据一个数据的执行,类似于串行操作。而 mapPartitions 算子 是以分区为单位进行批处理操作。
- Map 算子主要目的将数据源中的数据进行转换和改变。但是不会减少或增多数据。 MapPartitions 算子需要传递一个迭代器,返回一个迭代器,没有要求的元素的个数保持不变, 所以可以增加或减少数据
- Map 算子因为类似于串行操作,所以性能比较低,而是 mapPartitions 算子类似于批处 理,所以性能较高。但是 mapPartitions 算子会长时间占用内存,那么这样会导致内存可能 不够用,出现内存溢出的错误。所以在内存有限的情况下,不推荐使用mapPartitions。使用 map 操作。
-
groupBy 会将数据打乱,重新组合,这个操作我们称之为shuffle
-
filter 将数据根据指定的规则进行筛选过滤,符合规则的数据保留,不符合规则的数据丢弃。 当数据进行筛选过滤后,分区不变,但是分区内的数据可能不均衡,生产环境下,可能会出 现数据倾斜。
-
sample() 出现数据倾斜是使用它
- 第一个参数 表示抽取数据后是否将数据放回 true 放回 false 丢弃
第二个参数 如果抽取不放回的场合表示数据源中每条数据被抽取的概率基准值的概念
如果抽取放回的场合,表示数据源中的每条数据被抽取的可能次数
第三个参数 表示抽取数据时随机算法的种子(seed), 算法的第一个数
如果不传递第三个参数,那么使用当前的系统时间
- 第一个参数 表示抽取数据后是否将数据放回 true 放回 false 丢弃
-
distinct() 它的原理使用了以下的方法
-
// map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1) // (1,null) (2,null) (3,null) (4,null)(1,null) (2,null) (3,null) (4,null) // (1,null) (1,null) // (null,null) => null // (1,null)
-
-
coalesce() 根据数据量缩减分区,用于大数据集过滤后,提高小数据集的执行效率 当 spark 程序中,存在过多的小任务的时候,可以通过 coalesce 方法,收缩合并分区,减少 分区的个数,减小任务调度成本
- 默认不会让同一个分区数据打乱组合
- 可以使用shuffle来对数据进行均衡处理
- 可以扩大分区的,如果不进行shuffle操作,是没有意义的,不起作用的
-
repartition() 扩大分区,底层调用的是coalesce() 底层默认使用shuffle
-
sortBy()可以根据指定的规则对数据源中的数据进行排序,默认为升序,第二个参数可以改变排序的方式 ,sortBy默认情况下,不会改变分区,但是会在中间shuffle
-
partitionBy() key-value类型 根据指定的分区规则对数据进行重新分区 Spark 默认的分区器是 HashPartitioner
- 如果分区器和分区数量相同则什么都不做
- Spark 还有其他分区器吗? 有 RangePartitioner
- 如果想按照自己的方法进行数据分区怎么办? 自己自定义分区器
-
reduceByKey() 算子
- 相同的key的数据进行value的聚合
- reduceByKey()中如果key的数据只有一个是不会参与运算的
-
groupByKey()
- 将数据源中数据,相同key的数据分在一个组中,形成一个对偶元组 元组中的第一个元素就是可以 元组中的第二个元素就是相同的key的value的集合
- groupBy会将整体分组,
-
reduceByKey()和groupByKey()的区别
- groupByKey会导致数据打乱重组,存在shuffle操作 spark中,shuffle操作必须落盘处理,不能在内存中数据等待,会导致内存溢出。shuffle操作的性能非常低
- reduceByKey支持分区内预聚合,可以有效减少shuffle时落盘的数据量,提升shuffle的性能
- 从 shuffle 的角度:reduceByKey 和 groupByKey 都存在 shuffle 的操作,但是 reduceByKey 可以在 shuffle 前对分区内相同 key 的数据进行预聚合(combine)功能,这样会减少落盘的 数据量,而 groupByKey 只是进行分组,不存在数据量减少的问题,reduceByKey 性能比较 高。
- 从功能的角度:reduceByKey 其实包含分组和聚合的功能。GroupByKey 只能分组,不能聚 合,所以在分组聚合的场合下,推荐使用 reduceByKey,如果仅仅是分组而不需要聚合。那 么还是只能使用 groupByKey
- 分区内和分区间的计算规则是相同的
-
aggregateByKey()
- 第一个参数列表 需要传递一个参数,表示为初始值
- 第二个参数列表 需要传递两个参数 第一个参数表示分区内计算规则 第二个参数表示分区间计算规则
- 最终的返回数据结果应该和初始值的类型保持一致
-
foldByKey()
- 如果聚合计算时,分区内和分区间计算规则相同
-
combineByKey() 可以将计算过程中的第一个值进行变化
- 第一个参数 将相同key的第一个数据进行结构转换实现操作
- 第二个参数 分区内的计算第二个参数 分区内的计算
- 第三个参数 分区间的计算
-
reduceByKey flodByKey combineByKey aggtegateBykey的联系和区别
-
/* reduceByKey : combineByKeyWithClassTag[V]( (v: V) => v, // 第一个值不会参与计算 func, // 分区内计算规则 func, // 分区间的计算规则 ) aggregateByKey : combineByKeyWithClassTag[U]( (v: V) => cleanedSeqOp(createZero(), v), // 初始值和第一个key的value值进行的分区内的数据操作 cleanedSeqOp, // 分区内计算规则 combOp, // 分区间的计算规则 ) foldByKey combineByKeyWithClassTag[V]( (v: V) => cleanedFunc(createZero(), v), // 初始值和第一个key的value值进行的分区内的数据操作 cleanedFunc, // 分区内计算规则 cleanedFunc, // 分区间计算规则 ) combineByKey combineByKeyWithClassTag( createCombiner, // 相同key的第一条数据进行处理 mergeValue, // 表示分区内数据的处理函数 mergeCombiners, // 表示分区间数据的处理函数 mapSideCombine, serializer)(null) */
-
-
join
- join : 两个不同数据源的数据,相同的key的value会连接在一起,形成元组
- 如果两个数据源中没有key能匹配上,那么数据不会出现在结果中
- 如果两个数据源中key有多个相同的,会一次匹配,可能会出现笛卡尔乘积,数据量会几何增长,会导致性能降低OOM
行动
触发任务的调度和作业的执行
- collect()
- saveAsTextFile()
- aggregate() 初始值只会参与分区内计算,并且会参与分区间计算
- fold() 分区内核分区间计算相同时使用
- countByValue() 表示每个值出现的次数
- foreach()算子 其实是Executor端内存数据的打印(分布式打印)
序列化
scala中类的构造参数其实就是类的构造属性,构造参数需要进行闭包检测,其实就等同于闭包检测
kryo序列化
轻量化 和Java的序列化相比而言的话