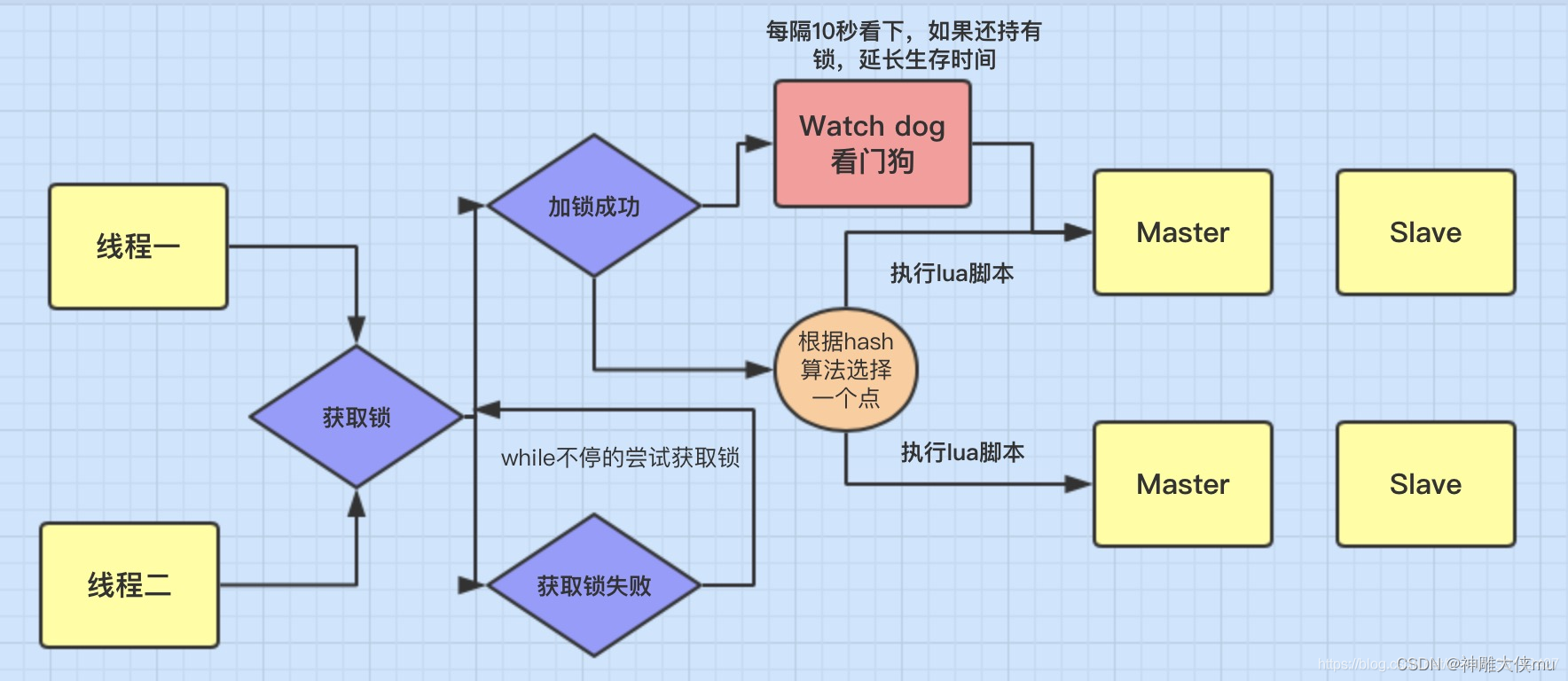
参考文章 https://blog.csdn.net/langzi6/article/details/124805024
top
第一行:运行时长,负载
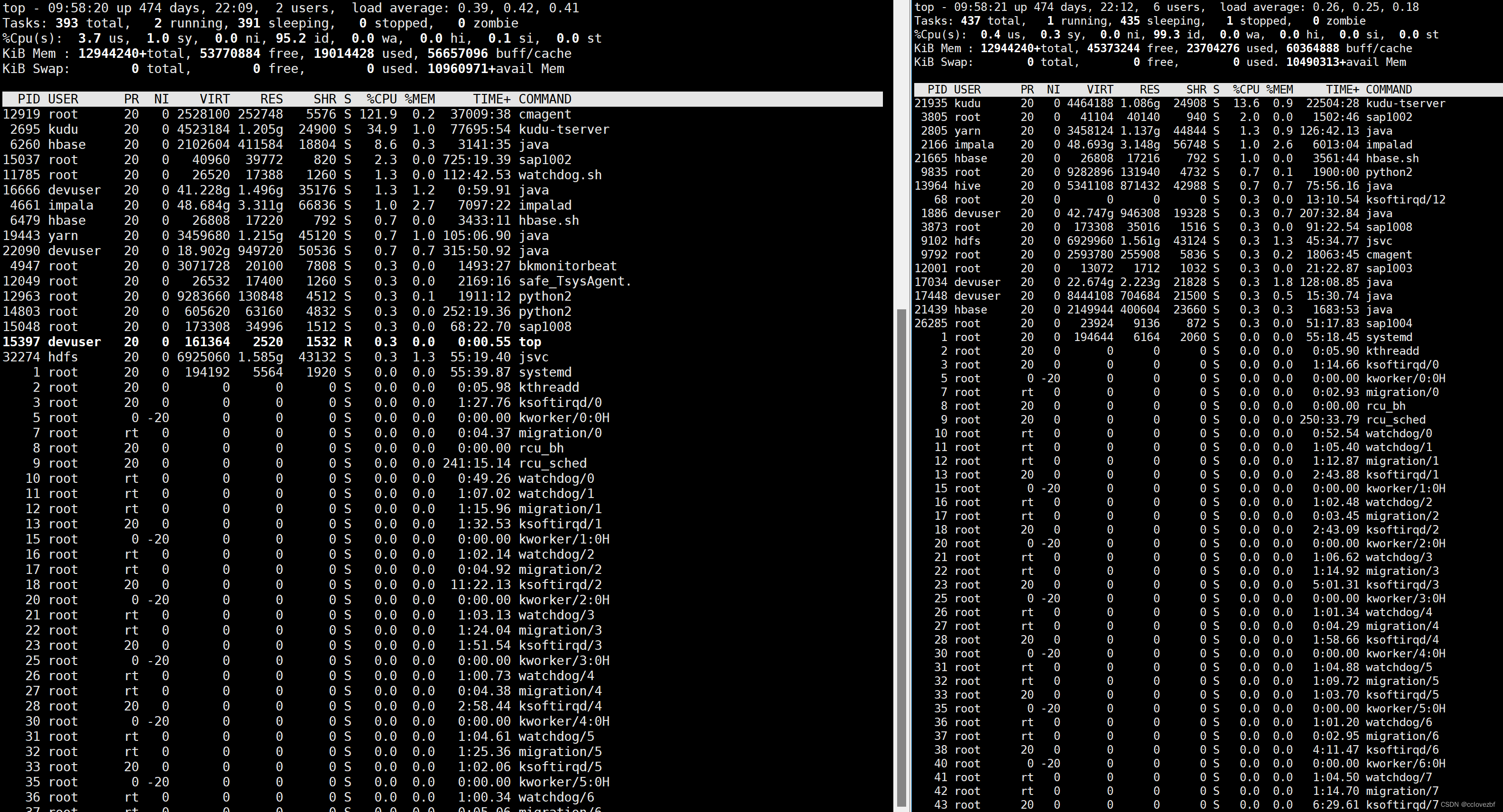
top - 10:04:54 up 474 days, 22:16, 2 users, load average: 2.07, 1.60, 0.94
top - 10:04:54:当前时间。
up 474 days, 22:16:系统已经运行的时长。
2 users:当前有2个用户登录到系统上。
load average: 2.07, 1.60, 0.94:系统在过去1分钟、5分钟和15分钟内的平均负载值。
这里具体需要关注的还是load average三个数值。先来说说定义吧:在一段时间内,CPU正在处理以及等待CPU处理的进程数之和。三个数字分别代表了1分钟,5分钟,15分钟的统计值,这个数值的确能反应服务器的负载情况。但是,这个数值高了也并不能直接代表这台机器的性能有问题,可能是因为正在进行CPU密集型的计算,也有可能是因为I/O问题导致运行队列堵了。所以,当我们看到这个数值飙升的时候,还得具体问题具体分析。大家都知道,一个CPU在一个时间片里面只能运行一个进程,CPU核数的多少直接影响到这台机器在同时间能运行的进程数。所以一般来说Load Average的数值别超过这台机器的总核数,就基本没啥问题。
我这台机器是16核32线程 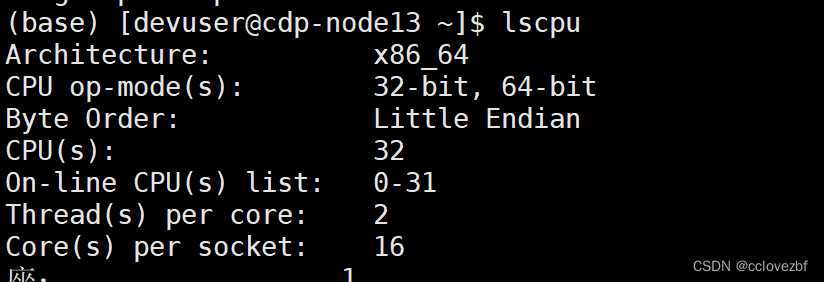
第二行:任务列表
Tasks: 394 total, 2 running, 392 sleeping, 0 stopped, 0 zombie
Tasks:总共有393个进程。
running:其中有2个进程正在运行。
sleeping:有391个进程睡眠。
stopped:没有任何进程被停止。
zombie:没有任何僵死进程(Zombie Process)。
第三行:CPU使用情况
%Cpu(s): 3.8 us, 0.6 sy, 0.0 ni, 95.5 id, 0.0 wa, 0.0 hi, 0.1 si, 0.0 st
%Cpu(s):指示各种CPU时间的使用百分比。
us:用户空间占比。(像shell程序、各种语言的编译器、各种应用、web服务器和各种桌面应用都算是运行在用户地址空间的进程,这些程序如果不是处于idle状态,那么绝大多数的CPU时间都是运行在用户态)
sy:内核空间占比。所有进程要使用的系统资源都是由Linux内核处理的,对于操作系统的设计来说,消耗在内核态的时间应该是越少越好,在实践中有一类典型的情况会使sy变大,那就是大量的IO操作,因此在调查IO相关的问题时需要着重关注它)
ni:用于调整进程优先级的用户进程空间占用率 (nice value) 。 0%
id:表示CPU空闲的时间占比。95.5%
wa:表示等待IO操作的时间占比。(和CPU的处理速度相比,磁盘IO操作是非常慢的,有很多这样的操作,比如,CPU在启动一个磁盘读写操作后,需要等待磁盘读写操作的结果。在磁盘读写操作完成前,CPU只能处于空闲状态。Linux系统在计算系统平均负载时会把CPU等待IO操作的时间也计算进去,所以在我们看到系统平均负载过高时,可以通过wa来判断系统的性能瓶颈是不是过多的IO操作造成的)
hi:表示硬中断请求的时间占比。
si:表示软中断请求的时间占比。 0.1%
st:如果为假,则没有任何虚拟机需要被置换。 如果为真,则某些虚拟机被压缩。
第四五行:内存使用情况
KiB Mem : 12944240+total, 54553152 free, 18052124 used, 56837132 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 10732576+avail Mem
和free -m对比看下
total used free shared buff/cache available
Mem: 126408 18266 52625 442 55516 107342
Swap: 0 0 0
MiB Mem:显示物理内存的使用情况。
total:总物理内存。12944240kb 126408MB=129441792kb=123G
free:空闲物理内存。54553152kb 52625MB=53888000kb
used:已使用的物理内存。 反正大差不差。
buff/cache:被高速缓存使用的内存量。
MiB Swap:显示交换分区的使用情况。
total:总交换分区大小。
free:空闲交换分区大小。
used:已使用的交换分区大小。
avail Mem:剩余可用内存。
第四第五行分别是内存信息和swap信息,所有程序的运行都是在内存中进行的,所以内存的性能对与服务器来说非常重要。不过当内存的free变少的时候,其实我们并不需要太紧张。真正需要看的是Swap中的used信息。Swap分区是由硬盘提供的交换区,当物理内存不够用的时候,操作系统才会把暂时不用的数据放到Swap中。所以当这个数值变高的时候,说明内存是真的不够用了。
这句话尤其注意,刚好今天抖音看了一个生产案例,就是说应用程序每次fullgc需要20s,之前不管他,后来发现越来越频繁一周好几次fullgc,发现每次fullgc的时候swap区的内存会减少,说明之前应用内存不够了,直接把一些数据存放到swap,在fullgc的时候需要清楚swap区的数据会浪费很多时间,后来他禁用了swap区,fullgc直接就降到100ms了。
第六行包括后续 进程列表:
PID:进程ID号。
USER:进程所有者的用户名。 --看是哪个用户启动的,看着有点用
PR:进程优先级。 --没啥用
NI:进程的nice值,用于调整进程的优先级。--没啥用
VIRT:进程占用的虚拟内存大小。 --有用
RES:进程占用的物理内存的大小。-- 有用
SHR:共享内存大小。
S:进程状态 (D=不可中断的睡眠状态, R=运行, S=睡眠, T=跟踪/停止, Z=僵尸进程)。
%CPU:该进程当前占用CPU的时间百分比。
%MEM:该进程占用物理内存的百分比。
TIME+:该进程占用CPU的总时间。
COMMAND:命令名称和参数。
以第一条
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2695 kudu 20 0 4523184 1.206g 24900 S 40.0 1.0 77725:46 kudu-tserver
pid=2695 用户是kudu 进程优先级是20 NI是0
虚拟内存VIRT=4523184kb=4.3g
物理内存RES=1.2G
共享内存=24MB
进程当前占用cpu的时间比为40%
进程占用内存的百分比为1.0%
该进程占用cpu的总时间是77725分钟46s
使用命令是kudu-tserver

上面是基础,大致了解了top命令各自代表的是啥,下面稍微深入一下如何使用top命令。
3.1. 更改显示内容
top之后我们按f可以自定义显示内容。比如这两个优先级有啥用啊,一辈子可能都用不到。
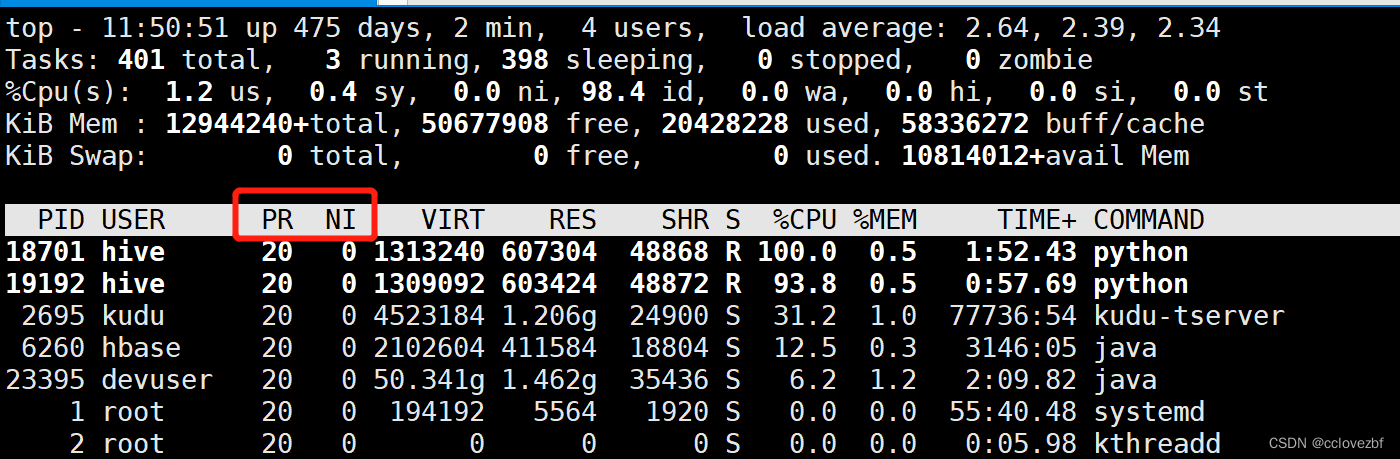
top后按F 出现以下页面 说明目前是按照cpu排序的,我不想看优先级,还想看下ppid
这里也说了使用方法,按d或空格去选择或取消指定展示列,按s去排序,按q或esc
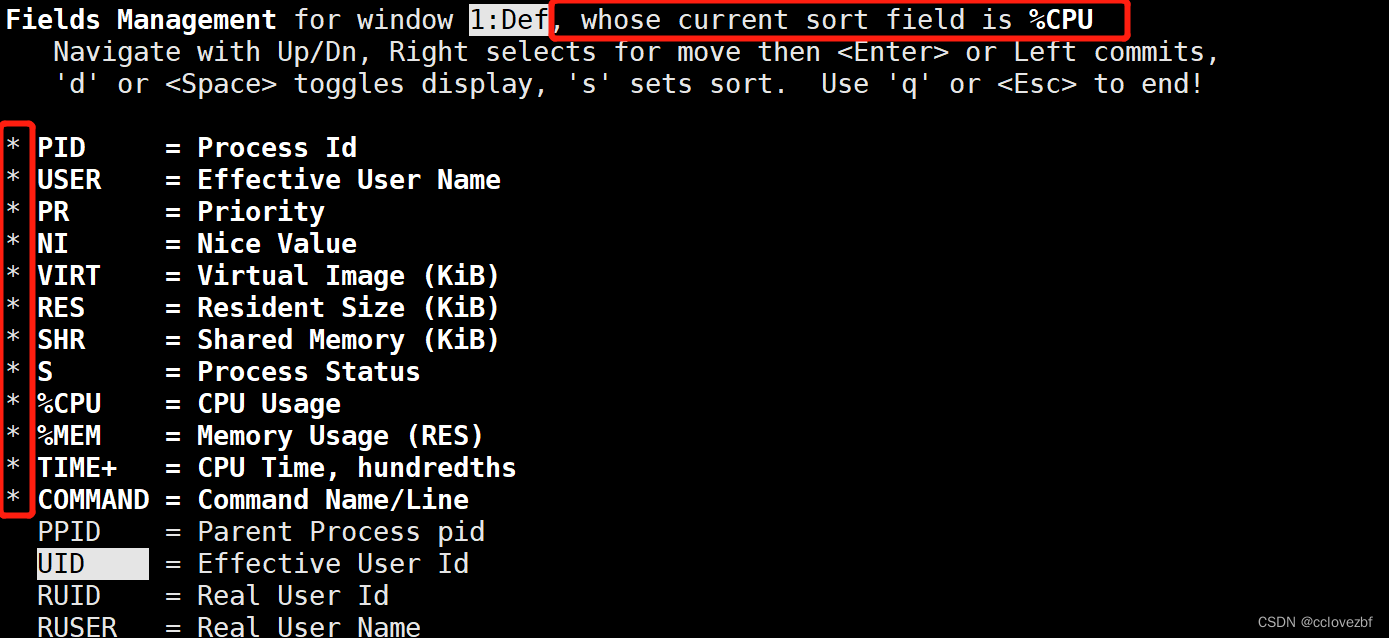
最后我们设置好了

3.2、top常用参数
要看使用方法少不了-h
(base) [devuser@cdp-node13 ~]$ top -help
procps-ng version 3.3.10
Usage:
top -hv | -bcHiOSs -d secs -n max -u|U user -p pid(s) -o field -w [cols]
说实话这个-h也很垃圾,直接看别人博客吧。
-d 指定每两次屏幕信息刷新之间的时间间隔,如希望每秒刷新一次,则使用:top -d 1
-p 通过指定PID来仅仅监控某个进程的状态 top -p pid1 -p pid2
-S 指定累计模式
-s 使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险
-i 使top不显示任何闲置或者僵死的进程
-c 显示整个命令行而不只是显示命令名 这个还挺有用的
例如:
top 每隔3秒显式所有进程的资源占用情况
top -d 1 每隔1秒显式所有进程的资源占用情况
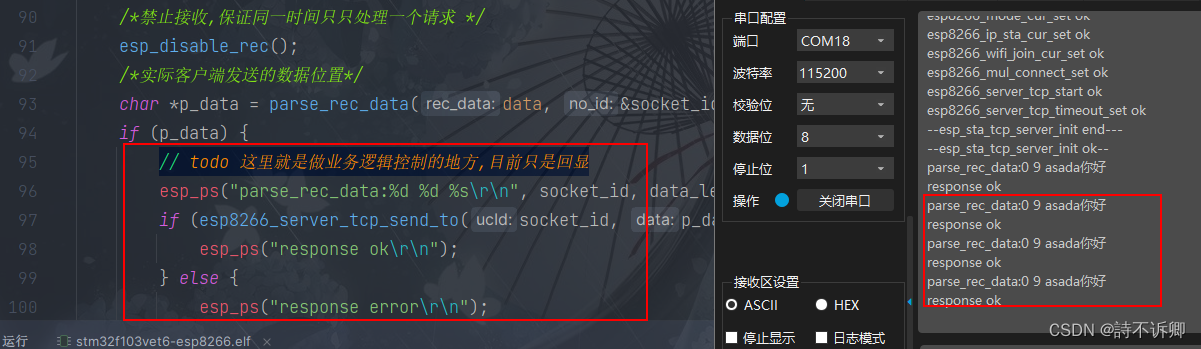
top -c 每隔3秒显式进程的资源占用情况,并显示进程的命令行参数(默认只有进程名)
top -p 28820 -p 38830 每隔3秒显示pid是28820和pid是38830的两个进程的资源占用情况
top -d 2 -c -p 69358 每隔2秒显示pid是69358的进程的资源使用情况,并显式该进程启动的命令行
3.3、top的交互命令
【1】敲top后,按键盘数字“1”可以监控每个逻辑CPU的状况: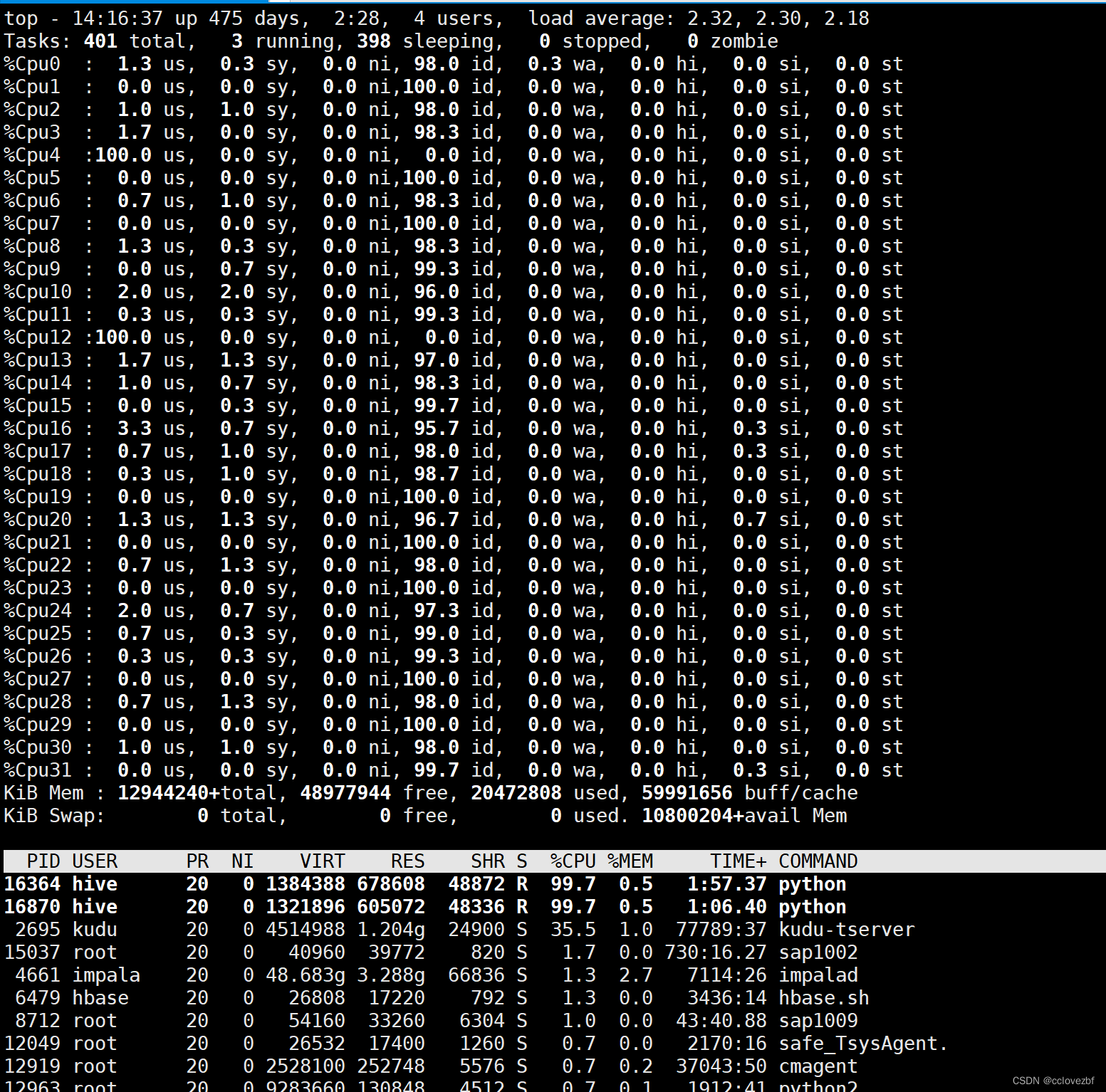
【2】敲top后,输入u,然后输入用户名,则可以查看相应的用户进程;
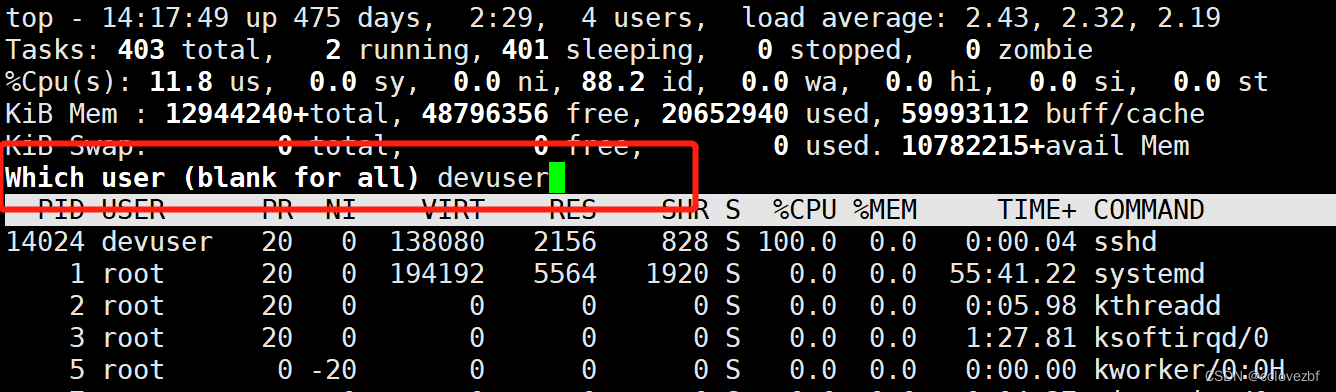
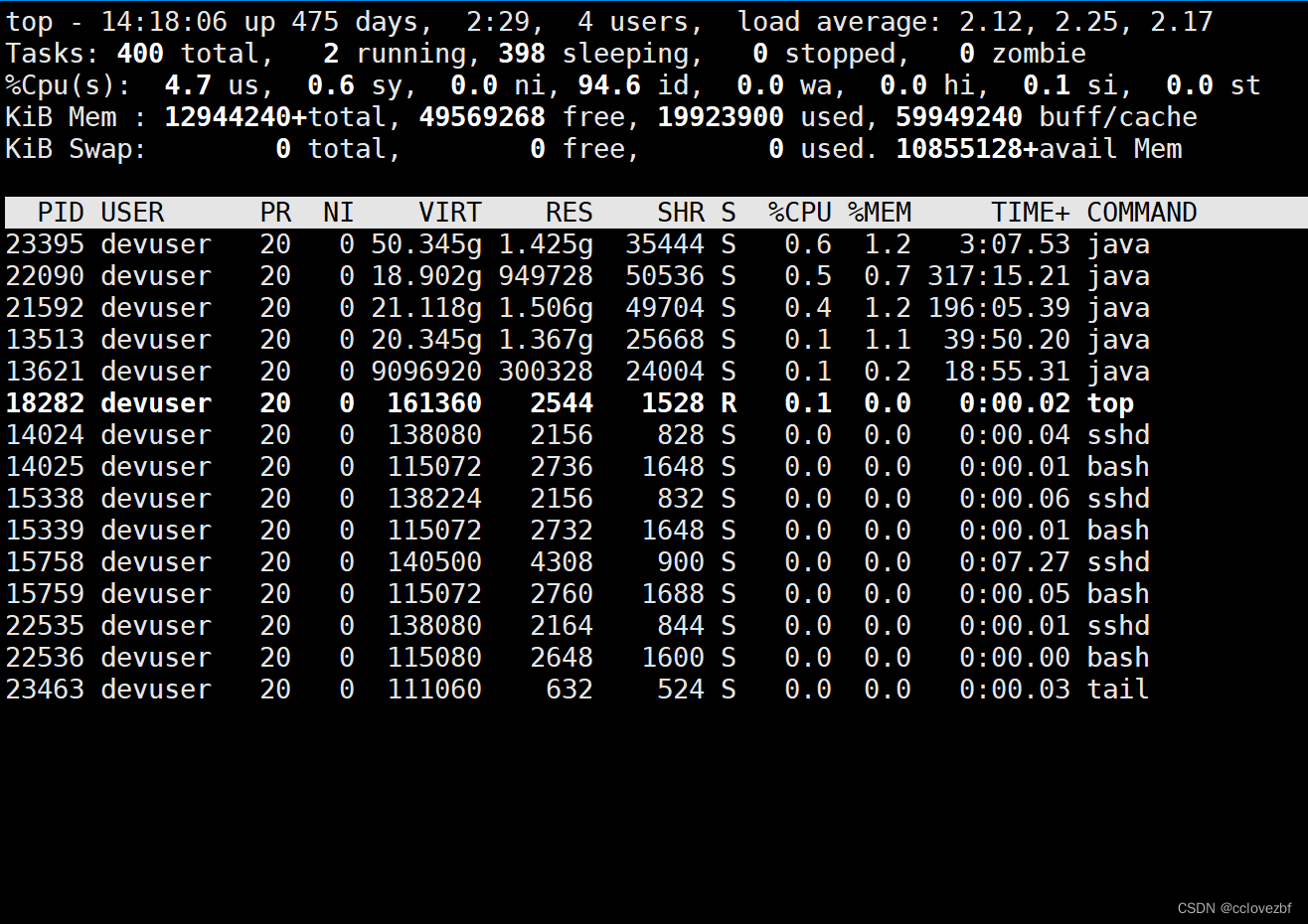
【3】敲top后,top命令默认以K为单位显示内存大小,我们可以通过大写字母E来切换内存信息区域的显示单位,如下按一下E切换到MB,再按以下切换到GB
默认kb
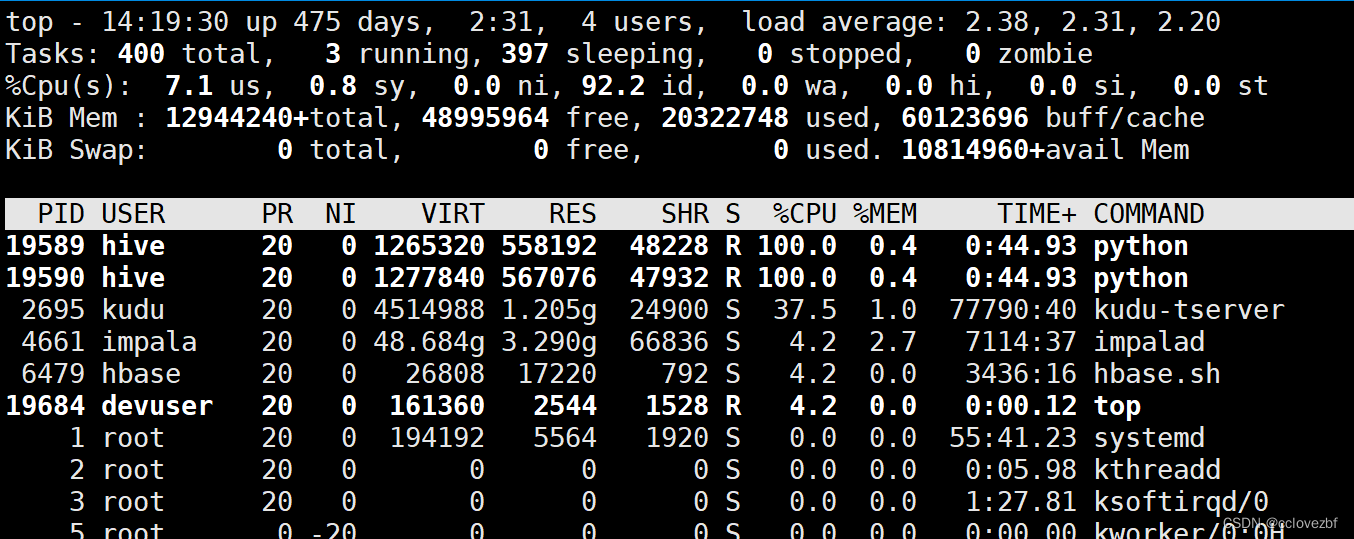
按一下E切换的MB
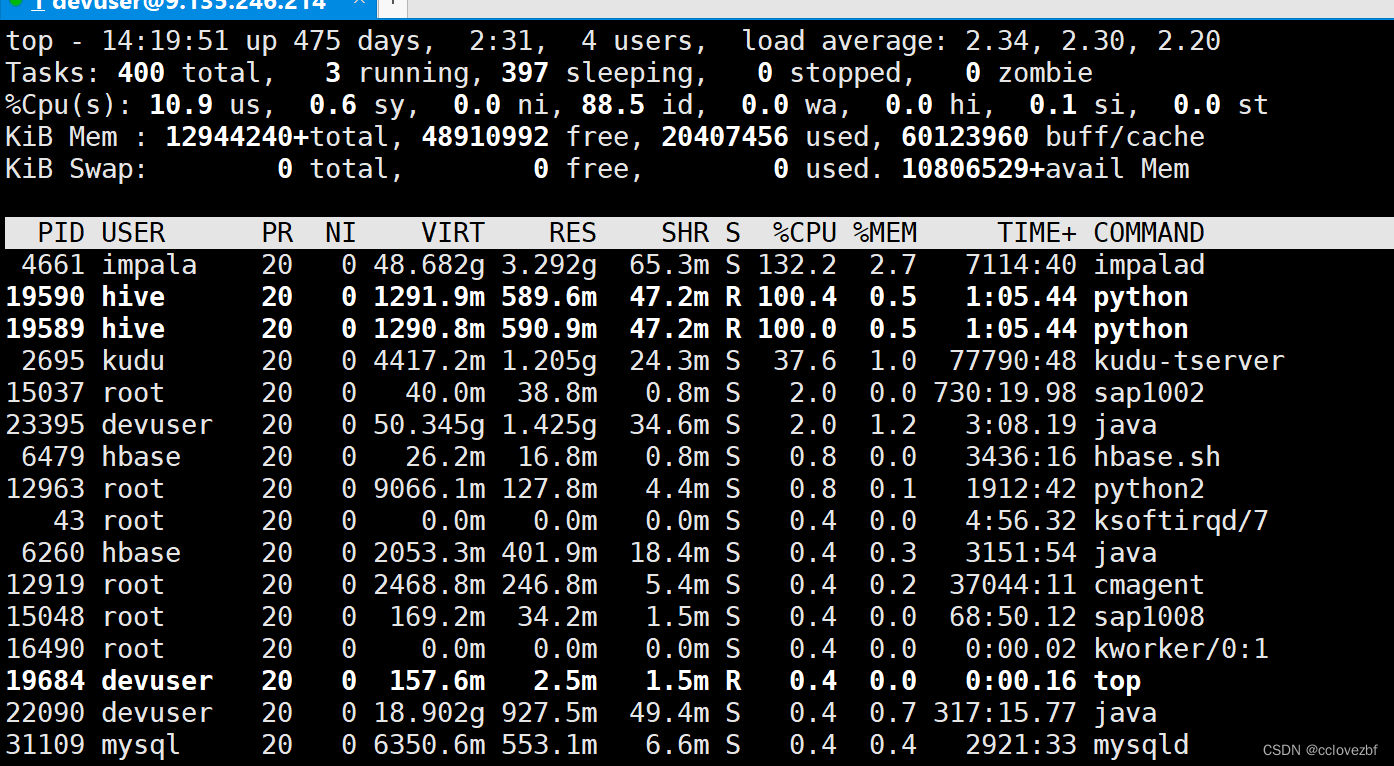
按两下E切换到GB
【4】敲top后,输入h进入top命令的帮助文档,了解更多关于top的用法。
好吧 我还以为top -h就可以了。原来是我狭隘了。