实战:kubeadm方式搭建k8s集群(containerd)-2022.12.5(成功测试-超详细)【荐】

写在开头
语雀原文阅读效果最佳,原文地址:实战:kubeadm方式搭建k8s集群(containerd)-2022.12.5(成功测试-超详细)【荐】 · 语雀 《实战:kubeadm方式搭建k8s集群(containerd)-2022.12.5(成功测试-超详细)【荐】》
实验环境
1、硬件环境
3台虚机 2c2g,20g。(nat模式,可访问外网)
| 角色 | 主机名 | ip | 内核版本 |
| master节点 | master1 | 172.29.9.61 | 3.10.0-1160.71.1.el7.x86_64 |
| node节点 | node1 | 172.29.9.62 | 3.10.0-1160.71.1.el7.x86_64 |
| node节点 | node2 | 172.29.9.63 | 3.10.0-1160.71.1.el7.x86_64 |
2、软件环境
| 软件 | 版本 |
| 操作系统 | centos7.6_x64 1810 mini(其他centos7.x版本也行) |
| containerd | v1.6.10 |
| kubernetes | v1.25.4 |
注意:默认CentOS Linux release 7.6.1810 (Core)的内核是3.10.0-957.el7.x86_64,但老师当前的内核版本有发生改变。基于之前经验,如果内核版本太低,后续的一些实验可能会有影响。这里就暂且使用默认的内核版本就好,后续遇到问题时,再升级下内核或者安装好k8s集群后升级下内核就好,或者先升级完内核再k8s集群都是可以的。
搭建时期:2022年12月5日
实验软件
链接:百度网盘 请输入提取码
提取码:9fbv
--来自百度网盘超级会员V7的分享
2022.12.5-k8s-install-containerd-softwares

1、环境准备
(all节点均要配置)。
使用 containerd 作为容器运行时搭建 Kubernetes 集群。
现在我们使用 kubeadm 从头搭建一个使用 containerd 作为容器运行时的 Kubernetes 集群,这里我们安装最新的 v1.25.4 版本。
1.创建3台虚机
在本地pc创建虚机目录:
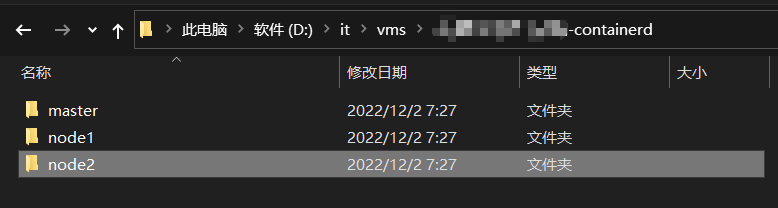
创建3台虚机:
注意:如说是用模板克隆虚机,要选择完全克隆。
开机并配置好规划的ip:


2.配置主机名
hostnamectl --static set-hostname master1 bash hostnamectl --static set-hostname node1 bash hostnamectl --static set-hostname node2 bash
注意:
节点的 hostname 必须使用标准的 DNS 命名,另外千万不用什么默认的 localhost 的 hostname,会导致各种错误出现的。
在 Kubernetes 项目里,机器的名字以及一切存储在 Etcd 中的 API 对象,都必须使用标准的 DNS 命名(RFC 1123)。
可以使用命令 hostnamectl set-hostname node1 来修改 hostname。
3.关闭防火墙,selinux
systemctl stop firewalld && systemctl disable firewalld systemctl stop NetworkManager && systemctl disable NetworkManager setenforce 0 sed -i s/SELINUX=enforcing/SELINUX=disabled/ /etc/selinux/config # 使用下面命令验证是否禁用成功 ☸ ➜ cat /etc/selinux/config SELINUX=disabled # 或者用如下命令验证: [root@master1 ~]#getenforce Disabled
注意:
如果使用的是云服务器,比如阿里云、腾讯云等,需要配置安全组,放开端口,如果只是为了测试方便可以直接全部放开,对于生产环境则只需要放开 K8s 要是使用到的一些端口,比如 6443 等等。

4.关闭swap分区
# 修改 /etc/fstab 文件,注释掉 SWAP 的自动挂载
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
# 使用 free -m 确认 swap 已经关闭
[root@master1 ~]#free -mh
total used free shared buff/cache available
Mem: 1.8G 89M 1.5G 9.5M 144M 1.5G
Swap: 0B 0B 0B
问题:k8s集群安装为什么需要关闭swap分区?
swap必须关,否则kubelet起不来,进而导致k8s集群起不来;可能kublet考虑到用swap做数据交换的话,对性能影响比较大
5.配置dns解析
cat >> /etc/hosts << EOF 172.29.9.61 master1 172.29.9.62 node1 172.29.9.63 node2 EOF
节点的 hostname 必须使用标准的 DNS 命名,另外千万别用默认 localhost 的 hostname,会导致各种错误出现的。在 Kubernetes 项目里,机器的名字以及一切存储在 Etcd 中的 API 对象,都必须使用标准的 DNS 命名(RFC 1123)。可以使用命令 hostnamectl set-hostname xxx 来修改 hostname。
问题:k8s集群安装时节点是否需要配置dns解析?
就是后面的kubectl如果需要连接运行在node上面的容器的话,它是通过kubectl get node出来的名称去连接的,所以那个的话,我们需要在宿主机上能够解析到它。如果它解析不到的话,那么他就可能连不上;🤣
6.开启内核 ipv4 转发
由于开启内核 ipv4 转发需要加载 br_netfilter 模块,所以加载下该模块:
[root@master1 ~]#lsmod |grep br_netfilter [root@master1 ~]#modprobe br_netfilter [root@master1 ~]#lsmod |grep br_netfilter br_netfilter 22256 0 bridge 151336 1 br_netfilter
最好将上面的命令设置成开机启动,因为重启后模块失效,下面是开机自动加载模块的方式,在 /etc/rc.d/rc.local 文件末尾添加如下脚本内容:
[root@master1 ~]#vim /etc/rc.d/rc.local #将以下内容追加到此文件 for file in /etc/sysconfig/modules/*.modules ; do [ -x $file ] "# $file done
然后在 /etc/sysconfig/modules/ 目录下新建如下文件:
[root@master1 ~]#mkdir -p /etc/sysconfig/modules/ [root@master1 ~]#vi /etc/sysconfig/modules/br_netfilter.modules modprobe br_netfilter
增加权限:
[root@master1 ~]#cd /etc/sysconfig/modules/ [root@master1 modules]#ls br_netfilter.modules [root@master1 modules]#chmod 755 br_netfilter.modules
然后重启后,模块就可以自动加载了:
[root@master1 ~]#reboot [root@master1 ~]#lsmod |grep br_netfilter br_netfilter 22256 0 bridge 151336 1 br_netfilter [root@master1 ~]#
然后创建 /etc/sysctl.d/k8s.conf 文件,添加如下内容:
cat > /etc/sysctl.d/k8s.conf << EOF net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 # 下面的内核参数可以解决ipvs模式下长连接空闲超时的问题 net.ipv4.tcp_keepalive_intvl = 30 net.ipv4.tcp_keepalive_probes = 10 net.ipv4.tcp_keepalive_time = 600 vm.swappiness=0 EOF # ipvs模式下长连接空闲超时的问题:一般情况,如果是线上环境,基本上不会复现这个问题。这里测试环境可以配一下这个参数。 # 注意 swappiness 参数调整 # 当然如果是生产环境使用还可以先对内核参数进行统一的调优。 # 执行如下命令使修改生效: [root@master1 ~]#sysctl -p /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 net.ipv4.tcp_keepalive_intvl = 30 net.ipv4.tcp_keepalive_probes = 10 net.ipv4.tcp_keepalive_time = 600 vm.swappiness = 0
注意:将桥接的IPv4流量传递到iptables的链
由于开启内核 ipv4 转发需要加载 br_netfilter 模块,所以加载下该模块:
modprobe br_netfilter
bridge-nf说明:
bridge-nf 使得 netfilter 可以对 Linux 网桥上的 IPv4/ARP/IPv6 包过滤。比如,设置net.bridge.bridge-nf-call-iptables=1后,二层的网桥在转发包时也会被 iptables的 FORWARD 规则所过滤。常用的选项包括:
- net.bridge.bridge-nf-call-arptables:是否在 arptables 的 FORWARD 中过滤网桥的 ARP 包
- net.bridge.bridge-nf-call-ip6tables:是否在 ip6tables 链中过滤 IPv6 包
- net.bridge.bridge-nf-call-iptables:是否在 iptables 链中过滤 IPv4 包
- net.bridge.bridge-nf-filter-vlan-tagged:是否在 iptables/arptables 中过滤打了 vlan 标签的包。
7.安装 ipvs
安装 ipvs:
cat > /etc/sysconfig/modules/ipvs.modules <<EOF #!/bin/bash modprobe -- ip_vs modprobe -- ip_vs_rr modprobe -- ip_vs_wrr modprobe -- ip_vs_sh modprobe -- nf_conntrack_ipv4 EOF chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
上面脚本创建了的/etc/sysconfig/modules/ipvs.modules文件,保证在节点重启后能自动加载所需模块。使用lsmod | grep -e ip_vs -e nf_conntrack_ipv4命令查看是否已经正确加载所需的内核模块;
接下来还需要确保各个节点上已经安装了 ipset 软件包,为了便于查看 ipvs 的代理规则,最好安装一下管理工具ipvsadm:
yum install ipset ipvsadm -y
8.同步服务器时间
然后记得一定要同步服务器时间,这里我们使用 chrony 来进行同步,其他工具也可以:
[root@master1 ~]#yum install chrony -y [root@master1 ~]#systemctl enable chronyd --now [root@master1 ~]#chronyc sources 210 Number of sources = 4 MS Name/IP address Stratum Poll Reach LastRx Last sample =============================================================================== ^? ntp6.flashdance.cx 2 6 6 5 -16ms[ +45us] +/- 187ms ^? mail.jabber-germany.de 0 7 0 - +0ns[ +0ns] +/- 0ns ^- dns2.synet.edu.cn 1 6 17 2 -858us[ -858us] +/- 20ms ^* time.neu.edu.cn 1 6 17 2 +299us[ +16ms] +/- 20ms
9.配置免密
(方便后期从master节点传文件到node节点)
#在master1节点执行如下命令,按2次回车 ssh-keygen #在master1节点执行 ssh-copy-id -i ~/.ssh/id_rsa.pub root@172.29.9.62 ssh-copy-id -i ~/.ssh/id_rsa.pub root@172.29.9.63
2、安装 Containerd
(all节点均要配置)。
1.安装containerd
接下来需要安装 Containerd 容器运行时。
如果在安装集群的过程出现了容器运行时的问题,启动不起来,可以尝试使用 yum install containerd.io 来安装 Containerd。
首先需要在节点上安装 seccomp 依赖,这一步很重要:
[root@master1 ~]#rpm -qa |grep libseccomp #自己系统当时是有这个包的,且其版本为libseccomp-2.3.1-4.el7.x86_64 libseccomp-2.3.1-4.el7.x86_64 # 如果没有安装 libseccomp 包则可以执行下面的命令安装依赖 [root@master1 ~]#wget http://mirror.centos.org/centos/7/os/x86_64/Packages/libseccomp-2.3.1-4.el7.x86_64.rpm [root@master1 ~]#yum install libseccomp-2.3.1-4.el7.x86_64.rpm -y
由于 Containerd 需要依赖底层的 runc 工具,所以我们也需要先安装 runc,不过 Containerd 提供了一个包含相关依赖的压缩包 cri-containerd-cni-${VERSION}.${OS}-${ARCH}.tar.gz,可以直接使用这个包来进行安装,强烈建议使用该安装包,不然可能因为 runc 版本问题导致不兼容。(这个安装包包含了一些包,例如runc,ctr命令等)
首先从 release 页面下载最新的 1.6.10 版本的压缩包:
[root@master1 ~]#wget https://github.com/containerd/containerd/releases/download/v1.6.10/cri-containerd-1.6.10-linux-amd64.tar.gz # 如果有限制,也可以替换成下面的 URL 加速下载(本次就用的这个加速地址) wget https://ghdl.feizhuqwq.cf/https://github.com/containerd/containerd/releases/download/v1.6.10/cri-containerd-1.6.10-linux-amd64.tar.gz
Release containerd 1.6.10 · containerd/containerd · GitHub

直接将压缩包解压到系统的各个目录中:
#可以先看下这个压缩包的文件内容: [root@master1 ~]#tar tf cri-containerd-1.6.10-linux-amd64.tar.gz etc/crictl.yaml etc/systemd/ etc/systemd/system/ etc/systemd/system/containerd.service usr/ usr/local/ usr/local/bin/ usr/local/bin/ctr usr/local/bin/critest usr/local/bin/crictl usr/local/bin/containerd usr/local/bin/containerd-shim usr/local/bin/ctd-decoder usr/local/bin/containerd-stress usr/local/bin/containerd-shim-runc-v2 usr/local/bin/containerd-shim-runc-v1 usr/local/sbin/ usr/local/sbin/runc opt/containerd/ opt/containerd/cluster/ opt/containerd/cluster/version opt/containerd/cluster/gce/ opt/containerd/cluster/gce/configure.sh opt/containerd/cluster/gce/cni.template opt/containerd/cluster/gce/cloud-init/ opt/containerd/cluster/gce/cloud-init/master.yaml opt/containerd/cluster/gce/cloud-init/node.yaml opt/containerd/cluster/gce/env [root@master1 ~]#tar -C / -xzf cri-containerd-1.6.10-linux-amd64.tar.gz
记得将 /usr/local/bin 和 /usr/local/sbin 追加到 PATH 环境变量中:(默认就在环境变量里的)
[root@master1 ~]#echo $PATH /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin [root@master1 ~]#containerd -v containerd github.com/containerd/containerd v1.6.10 770bd0108c32f3fb5c73ae1264f7e503fe7b2661 [root@master1 ~]#runc -h runc: symbol lookup error: runc: undefined symbol: seccomp_notify_respond
可以正常执行 containerd -v 命令证明 Containerd 安装成功了,但是执行 runc -h 命令的时候却出现了类似runc: undefined symbol: seccomp_notify_respond 的错误,这是因为我们当前系统默认安装的 libseccomp是 2.3.1 版本,该版本已经不能满足我们这里的 v1.6.10 版本的 Containerd 了(从 1.5.7 版本开始就不兼容了),需要 2.4 以上的版本,所以我们需要重新安装一个高版本的 libseccomp 。
注意:
老师说先要卸载老版本的libseccomp-2.3.1-4包,但是之前的chrony软件包会依赖这个libseccomp包,卸载libseccomp包的同时chrony也会被卸载掉。后面安装好高版本libseccomp-2.5.1-1要记得再次安装下chrony软件。
另外,新版本libseccomp-2.5.1-1.el8.x86_64.rpm是el8的,但是直接安装到el7上也是没问题的哦;
这里开始操作:
1、卸载老版本libseccom包 [root@master1 ~]#rpm -qa | grep libseccomp libseccomp-2.3.1-4.el7.x86_64 2、查询哪些包对这个libseccomp软件包有依赖关系 [root@master1 ~]#rpm -e --test libseccomp error: Failed dependencies: libseccomp.so.2()(64bit) is needed by (installed) chrony-3.4-1.el7.x86_64 #可以发现libseccomp软件包只背chrony软件依赖 3、卸载老版本libseccomp包 [root@master1 ~]#yum remove -y libseccomp #yum remove/erase 删除一个软件的时候也会删除对该软件具有依赖关系的包。 …… Removed: libseccomp.x86_64 0:2.3.1-4.el7 Dependency Removed: chrony.x86_64 0:3.4-1.el7 Complete! [root@master1 ~]#rpm -qa | grep libseccomp #查看老版本libseccomp已被卸载 [root@master1 ~]# 4、# 下载高于 2.4 以上的包并安装 [root@master1 ~]#wget http://rpmfind.net/linux/centos/8-stream/BaseOS/x86_64/os/Packages/libseccomp-2.5.1-1.el8.x86_64.rpm [root@master1 ~]#yum install libseccomp-2.5.1-1.el8.x86_64.rpm -y …… Installed: libseccomp.x86_64 0:2.5.1-1.el8 Complete! [root@master1 ~]#rpm -qa | grep libseccomp #再次查看,发现此时libseccomp已经是最新版本的了。 libseccomp-2.5.1-1.el8.x86_64 5、重新安装chrony软件 yum install chrony -y systemctl enable chronyd --now chronyc sources
现在 runc 命令就可以正常使用了:
[root@master1 ~]#runc -v
runc version 1.1.4
commit: v1.1.4-0-g5fd4c4d1
spec: 1.0.2-dev
go: go1.18.8
libseccomp: 2.5.1
[root@master1 ~]#runc -h
NAME:
runc - Open Container Initiative runtime
runc is a command line client for running applications packaged according to
the Open Container Initiative (OCI) format and is a compliant implementation of the
Open Container Initiative specification.
runc integrates well with existing process supervisors to provide a production
container runtime environment for applications. It can be used with your
existing process monitoring tools and the container will be spawned as a
direct child of the process supervisor.
Containers are configured using bundles. A bundle for a container is a directory
that includes a specification file named "config.json" and a root filesystem.
The root filesystem contains the contents of the container.
To start a new instance of a container:
# runc run [ -b bundle ] <container-id>
Where "<container-id>" is your name for the instance of the container that you
are starting. The name you provide for the container instance must be unique on
your host. Providing the bundle directory using "-b" is optional. The default
value for "bundle" is the current directory.
USAGE:
runc [global options] command [command options] [arguments...]
VERSION:
1.1.4
commit: v1.1.4-0-g5fd4c4d1
spec: 1.0.2-dev
go: go1.18.8
libseccomp: 2.5.1
2.配置containerd
Containerd 的默认配置文件为 /etc/containerd/config.toml,我们可以通过如下所示的命令生成一个默认的配置:
[root@master1 ~]#mkdir -p /etc/containerd [root@master1 ~]#containerd config default > /etc/containerd/config.toml
containerd都是插件化的。

1.修改containerd 的 cgroup driver类型为systemd
将 containerd 的 cgroup driver 配置为 systemd。
对于使用 systemd 作为 init system 的 Linux 的发行版,使用 systemd 作为容器的 cgroup driver 可以确保节点在资源紧张的情况更加稳定,所以推荐将 containerd 的 cgroup driver 配置为 systemd。
修改前面生成的配置文件 /etc/containerd/config.toml,在 plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options 配置块下面将 SystemdCgroup 设置为 true:
[root@master1 ~]#vim /etc/containerd/config.toml #通过搜索SystemdCgroup进行定位 [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc] …… [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options] SystemdCgroup = true ....

2.配置镜像加速器地址
然后再为镜像仓库配置一个加速器,需要在 cri 配置块下面的 registry 配置块下面进行配置 registry.mirrors:(注意缩进)
[root@master1 ~]#vim /etc/containerd/config.toml #通过搜索registry.mirrors进行定位 144 [plugins."io.containerd.grpc.v1.cri".registry] …… 152 153 [plugins."io.containerd.grpc.v1.cri".registry.mirrors] 154 [plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"] 155 endpoint = ["https://bqr1dr1n.mirror.aliyuncs.com"]

注意:这里的k8s.gcr.io仓库地址就不写了,因为现在社区已经将 K8s 默认的镜像仓库从 k8s.gcr.io 迁移到了 registry.k8s.io。(这里的标注是以前的版本)(老师当时这部分k8s.gcr.io的仓库地址是去掉的,只加了一个dock.io地址。)

[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"] endpoint = ["https://bqr1dr1n.mirror.aliyuncs.com"] #注意:这个地址是老师的私人仓库地址 [plugins."io.containerd.grpc.v1.cri".registry.mirrors."k8s.gcr.io"] endpoint = ["https://registry.aliyuncs.com/k8sxio"] #注意:这个地址是老师的私人仓库地址
3.配置pause镜像地址
注意:
现在社区已经将 K8s 默认的镜像仓库从 k8s.gcr.io 迁移到了 registry.k8s.io ,不过国内正常情况下还是不能使用。所以如果我们的节点不能正常获取 registry.k8s.io 的镜像,那么我们需要在上面重新配置sandbox_image 镜像,Containerd 模式下直接通过 kubelet (之前版本可以这么配置的)覆盖该镜像不会生效: Warning: For remotecontainer runtime, "'pod-infra-container-image is ignored in kubelet, which should beset in that remote runtime instead。因此需要在Containerd 里进行配置。
注意:在宿主机上是可以ping通这个registry.k8s.io域名的,但是可能还是无法正常拉取镜像。

当前v1.6.10版本的containerd里的sandbox_image的pause镜像地址为pause:3.6,但我们要安装的k8s v1.25.4对其pause需求要是pause:3.8才行,这里我们来修改下pause镜像地址。
配置方法:
[root@master1 ~]#vim /etc/containerd/config.toml …… sandbox_image = "registry.aliyuncs.com/k8sxio/pause:3.8" ……
修改前:

修改后:

3.启动containerd服务
由于上面我们下载的 containerd 压缩包中包含一个 etc/systemd/system/containerd.service 的文件,这样我们就可以通过 systemd 来配置 containerd 作为守护进程运行了,现在我们就可以启动 containerd 了,直接执行下面的命令即可:
[root@master1 ~]#systemctl daemon-reload [root@master1 ~]#systemctl enable containerd --now Created symlink from /etc/systemd/system/multi-user.target.wants/containerd.service to /etc/systemd/system/containerd.service.
4.验证
启动完成后就可以使用 containerd 的本地 CLI 工具 ctr 和 crictl 了,比如查看版本:
[root@master1 ~]#containerd -v containerd github.com/containerd/containerd v1.6.10 770bd0108c32f3fb5c73ae1264f7e503fe7b2661 [root@master1 ~]#ctr version #ctr--containerd类似于docker--dockerd。 Client: Version: v1.6.10 Revision: 770bd0108c32f3fb5c73ae1264f7e503fe7b2661 Go version: go1.18.8 Server: Version: v1.6.10 Revision: 770bd0108c32f3fb5c73ae1264f7e503fe7b2661 UUID: 4b5d9dc9-7e39-47ce-be54-c9f4c0fa4865 [root@master1 ~]#crictl version #crictl是操作k8s里的cri的。 Version: 0.1.0 RuntimeName: containerd RuntimeVersion: v1.6.10 RuntimeApiVersion: v1
至此,containerd安装完成。
3、初始化集群
1.添加阿里云YUM软件源
(all节点均要配置)。
上面的相关环境配置完成后,接着我们就可以来安装 Kubeadm 了,我们这里是通过指定 yum 源的方式来进行安装的:
☸ ➜ cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF

当然了,上面的 yum 源是需要科学上网的,如果不能科学上网的话,我们可以使用阿里云的源进行安装:
cat > /etc/yum.repos.d/kubernetes.repo << EOF [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF
2.安装 kubeadm、kubelet、kubectl
(all节点均要配置)。
[root@master1 ~]yum makecache fast
[root@master1 ~]yum install -y kubelet-1.25.4 kubeadm-1.25.4 kubectl-1.25.4 --disableexcludes=kubernetes
[root@master1 ~]#kubeadm version
kubeadm version: &version.Info{Major:"1", Minor:"25", GitVersion:"v1.25.4", GitCommit:"872a965c6c6526caa949f0c6ac028ef7aff3fb78", GitTreeState:"clean", BuildDate:"2022-11-09T13:35:06Z", GoVersion:"go1.19.3", Compiler:"gc", Platform:"linux/amd64"}
#可以看到我们这里安装的是 v1.25.4 版本,然后将 master 节点的 kubelet 设置成开机启动:
[root@master1 ~]#systemctl enable --now kubelet
说明:--disableexcludes 禁掉除了kubernetes之外的别的仓库
🍀 注意
到这里为止上面所有的操作都需要在所有节点执行配置 上面所有的操作都需要在所有节点执行配置,在云环境上面的话我们可以将当前环境直接做成一个镜像,然后创建新节点的时候直接使用该镜像即可,这样可以避免重复的工作。
如果是自己测试用虚拟机配置,也建议先配置1台master节点,其余节点直接克隆master节点配置过来就好。注意一点,克隆过来的机器只要配置好对应的ip,主机名和/ect/hosts内容就好,其他内容不变。

3.初始化集群
(master1节点操作)。
当我们执行 kubelet --help 命令的时候可以看到原来大部分命令行参数都被 DEPRECATED了,这是因为官方推荐我们使用 --config 来指定配置文件,在配置文件中指定原来这些参数的配置,可以通过官方文档 Set Kubelet parameters via a config file 了解更多相关信息,这样 Kubernetes 就可以支持动态 Kubelet 配置(Dynamic Kubelet Configuration)了,参考 Reconfigure a Node’s Kubelet in a Live Cluster。
然后我们可以通过下面的命令在 master 节点上输出集群初始化默认使用的配置:
[root@master1 ~]#kubeadm config print init-defaults --component-configs KubeletConfiguration > kubeadm.yaml
然后根据我们自己的需求修改配置:
比如修改 imageRepository 指定集群初始化时拉取 Kubernetes 所需镜像的地址;
kube-proxy 的模式为 ipvs;
另外需要注意的是我们这里是准备安装 flannel 网络插件的,需要将 networking.podSubnet 设置为10.244.0.0/16:
默认yaml内容如下:
[root@master1 ~]#cat kubeadm.yaml
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 1.2.3.4
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
imagePullPolicy: IfNotPresent
name: node
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.k8s.io
kind: ClusterConfiguration
kubernetesVersion: 1.25.0
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
scheduler: {}
---
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.crt
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 0s
cacheUnauthorizedTTL: 0s
cgroupDriver: systemd
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
cpuManagerReconcilePeriod: 0s
evictionPressureTransitionPeriod: 0s
fileCheckFrequency: 0s
healthzBindAddress: 127.0.0.1
healthzPort: 10248
httpCheckFrequency: 0s
imageMinimumGCAge: 0s
kind: KubeletConfiguration
logging:
flushFrequency: 0
options:
json:
infoBufferSize: "0"
verbosity: 0
memorySwap: {}
nodeStatusReportFrequency: 0s
nodeStatusUpdateFrequency: 0s
rotateCertificates: true
runtimeRequestTimeout: 0s
shutdownGracePeriod: 0s
shutdownGracePeriodCriticalPods: 0s
staticPodPath: /etc/kubernetes/manifests
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
volumeStatsAggPeriod: 0s
修改后yaml内容如下:
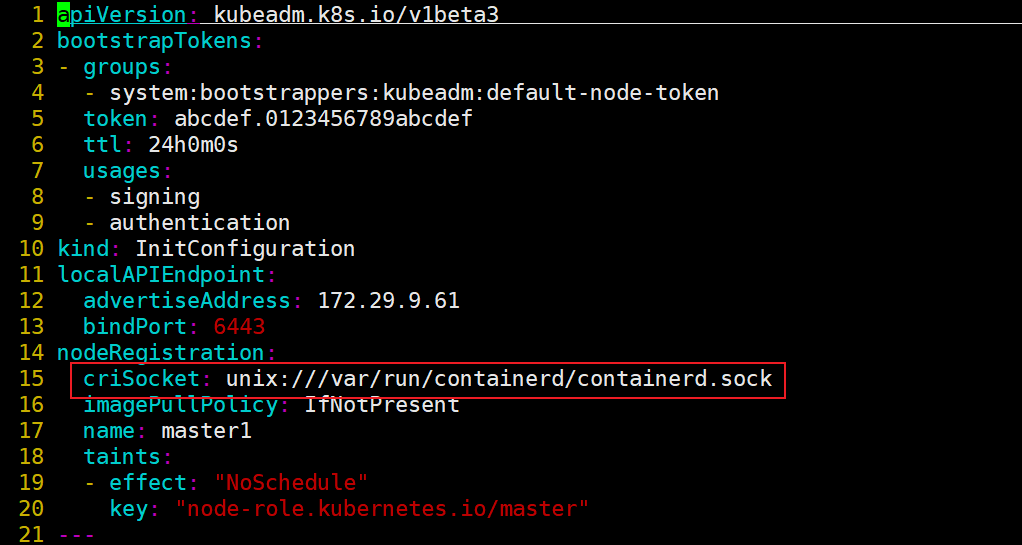
[root@master1 ~]#cat kubeadm.yaml
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
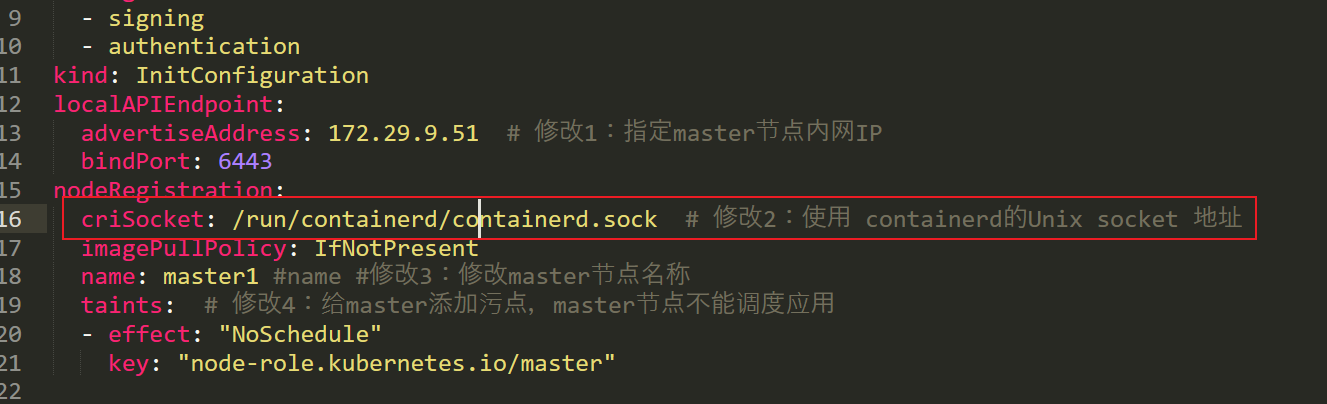
advertiseAddress: 172.29.9.61 # 修改1:指定master节点内网IP
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
imagePullPolicy: IfNotPresent
name: master1 #修改2:修改master节点名称
taints: # 修改3:给master添加污点,master节点不能调度应用
- effect: "NoSchedule"
key: "node-role.kubernetes.io/master"
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/k8sxio #修改5:image地址
kind: ClusterConfiguration
kubernetesVersion: 1.25.4 #修改6:指定k8s版本号,默认这里忽略了小版本号
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16 # 修改7:指定 pod 子网
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs # 修改4:修改kube-proxy 模式为ipvs,默认为iptables
---
apiVersion: kubelet.config.k8s.io/v1beta1
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.crt
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 0s
cacheUnauthorizedTTL: 0s
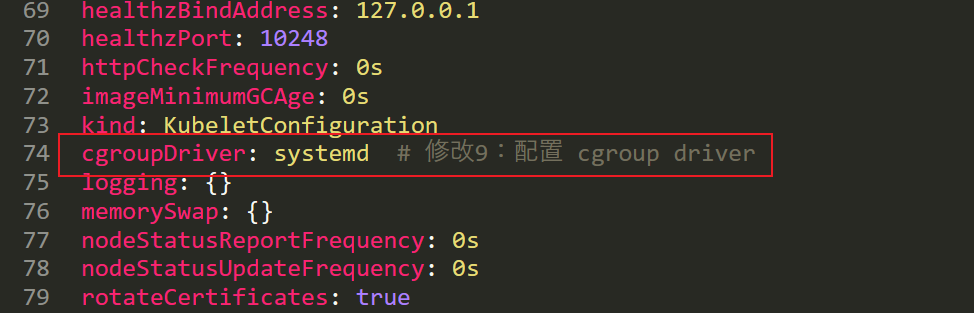
cgroupDriver: systemd
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
cpuManagerReconcilePeriod: 0s
evictionPressureTransitionPeriod: 0s
fileCheckFrequency: 0s
healthzBindAddress: 127.0.0.1
healthzPort: 10248
httpCheckFrequency: 0s
imageMinimumGCAge: 0s
kind: KubeletConfiguration
logging:
flushFrequency: 0
options:
json:
infoBufferSize: "0"
verbosity: 0
memorySwap: {}
nodeStatusReportFrequency: 0s
nodeStatusUpdateFrequency: 0s
rotateCertificates: true
runtimeRequestTimeout: 0s
shutdownGracePeriod: 0s
shutdownGracePeriodCriticalPods: 0s
staticPodPath: /etc/kubernetes/manifests
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
volumeStatsAggPeriod: 0s
总共需要修改如上7处地方。
注意:这里和之前一次部署版本之间的区别。
老版本:
新版本:(这2个配置保持不变)

配置提示
对于上面的资源清单的文档比较杂,要想完整了解上面的资源对象对应的属性,可以查看对应的 godoc 文档,地址: https://godoc.org/k8s.io/kubernetes/cmd/kubeadm/app/apis/kubeadm/v1beta3。
在开始初始化集群之前可以使用 kubeadm config images pull --config kubeadm.yaml 预先在各个服务器节点上拉取所k8s需要的容器镜像。
我们可以先list一下:
[root@master1 ~]#kubeadm config images list registry.k8s.io/kube-apiserver:v1.25.4 registry.k8s.io/kube-controller-manager:v1.25.4 registry.k8s.io/kube-scheduler:v1.25.4 registry.k8s.io/kube-proxy:v1.25.4 registry.k8s.io/pause:3.8 registry.k8s.io/etcd:3.5.5-0 registry.k8s.io/coredns/coredns:v1.9.3 [root@master1 ~]#kubeadm config images list --config kubeadm.yaml registry.aliyuncs.com/k8sxio/kube-apiserver:v1.25.4 registry.aliyuncs.com/k8sxio/kube-controller-manager:v1.25.4 registry.aliyuncs.com/k8sxio/kube-scheduler:v1.25.4 registry.aliyuncs.com/k8sxio/kube-proxy:v1.25.4 registry.aliyuncs.com/k8sxio/pause:3.8 registry.aliyuncs.com/k8sxio/etcd:3.5.5-0 registry.aliyuncs.com/k8sxio/coredns:v1.9.3
配置文件准备好过后,可以使用如下命令先将相关镜像 pull 下来:
[root@master1 ~]#kubeadm config images pull --config kubeadm.yaml

上面在拉取 coredns 镜像的时候出错了,阿里云仓库里没有找到这个镜像,我们可以手动到官方仓库 pull 该镜像,然后重新 tag 下镜像地址即可:
[root@master1 ~]#ctr -n k8s.io i pull docker.io/coredns/coredns:1.9.3 docker.io/coredns/coredns:1.9.3: resolved |++++++++++++++++++++++++++++++++++++++| index-sha256:8e352a029d304ca7431c6507b56800636c321cb52289686a581ab70aaa8a2e2a: done |++++++++++++++++++++++++++++++++++++++| manifest-sha256:bdb36ee882c13135669cfc2bb91c808a33926ad1a411fee07bd2dc344bb8f782: done |++++++++++++++++++++++++++++++++++++++| layer-sha256:f2401d57212f95ea8e82ff8728f4f99ef02d4b39459837244d1b049c5d43de43: done |++++++++++++++++++++++++++++++++++++++| config-sha256:5185b96f0becf59032b8e3646e99f84d9655dff3ac9e2605e0dc77f9c441ae4a: done |++++++++++++++++++++++++++++++++++++++| layer-sha256:d92bdee797857f997be3c92988a15c196893cbbd6d5db2aadcdffd2a98475d2d: done |++++++++++++++++++++++++++++++++++++++| elapsed: 8.2 s total: 11.1 M (1.4 MiB/s) unpacking linux/amd64 sha256:8e352a029d304ca7431c6507b56800636c321cb52289686a581ab70aaa8a2e2a... done: 691.900943ms #重新打上tag [root@master1 ~]# ctr -n k8s.io i tag docker.io/coredns/coredns:1.9.3 registry.aliyuncs.com/k8sxio/coredns:v1.9.3 registry.aliyuncs.com/k8sxio/coredns:v1.9.3 #查看镜像 [root@master1 ~]#ctr -n k8s.io i list -q|grep coredns docker.io/coredns/coredns:1.9.3 registry.aliyuncs.com/k8sxio/coredns:v1.9.3
注意:
然后在2个node节点上执行下预拉取镜像和coredns镜像拉取与重新打tag操作
kubeadm config images pull --config kubeadm.yaml ctr -n k8s.io i pull docker.io/coredns/coredns:1.9.3 ctr -n k8s.io i tag docker.io/coredns/coredns:1.9.3 registry.aliyuncs.com/k8sxio/coredns:v1.9.3 [root@master1 ~]#scp kubeadm.yaml root@172.29.9.62:~ kubeadm.yaml 100% 2076 2.1MB/s 00:00 [root@master1 ~]#scp kubeadm.yaml root@172.29.9.63:~ kubeadm.yaml 100% 2076 2.2MB/s 00:00
然后就可以使用上面的配置文件在 master 节点上进行初始化:
这里需要特别注意下:会报错。。。
#注意:可以通过加上--v 5来进一步打印更多的log信息 kubeadm init --config kubeadm.yaml --v 5
[root@master1 ~]#kubeadm init --config kubeadm.yaml [init] Using Kubernetes version: v1.25.4 [preflight] Running pre-flight checks [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' [certs] Using certificateDir folder "/etc/kubernetes/pki" [certs] Generating "ca" certificate and key [certs] Generating "apiserver" certificate and key [certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master1] and IPs [10.96.0.1 172.29.9.61] [certs] Generating "apiserver-kubelet-client" certificate and key [certs] Generating "front-proxy-ca" certificate and key [certs] Generating "front-proxy-client" certificate and key [certs] Generating "etcd/ca" certificate and key [certs] Generating "etcd/server" certificate and key [certs] etcd/server serving cert is signed for DNS names [localhost master1] and IPs [172.29.9.61 127.0.0.1 ::1] [certs] Generating "etcd/peer" certificate and key [certs] etcd/peer serving cert is signed for DNS names [localhost master1] and IPs [172.29.9.61 127.0.0.1 ::1] [certs] Generating "etcd/healthcheck-client" certificate and key [certs] Generating "apiserver-etcd-client" certificate and key [certs] Generating "sa" key and public key [kubeconfig] Using kubeconfig folder "/etc/kubernetes" [kubeconfig] Writing "admin.conf" kubeconfig file [kubeconfig] Writing "kubelet.conf" kubeconfig file [kubeconfig] Writing "controller-manager.conf" kubeconfig file [kubeconfig] Writing "scheduler.conf" kubeconfig file [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Starting the kubelet [control-plane] Using manifest folder "/etc/kubernetes/manifests" [control-plane] Creating static Pod manifest for "kube-apiserver" [control-plane] Creating static Pod manifest for "kube-controller-manager" [control-plane] Creating static Pod manifest for "kube-scheduler" [etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests" [wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s [apiclient] All control plane components are healthy after 7.004110 seconds [upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace [kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster [upload-certs] Skipping phase. Please see --upload-certs [mark-control-plane] Marking the node master1 as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers] [mark-control-plane] Marking the node master1 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule] [bootstrap-token] Using token: abcdef.0123456789abcdef [bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles [bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes [bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials [bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token [bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster [bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace [kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key [addons] Applied essential addon: CoreDNS [addons] Applied essential addon: kube-proxy Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 172.29.9.61:6443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:d4bdf1090a033f285e12087147da051a43cf786e03645fdcd48e2d51e1cacaf7 [root@master1 ~]#
master1节点初始化成功。
根据安装提示拷贝 kubeconfig 文件:
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
然后可以使用 kubectl 命令查看 master 节点已经初始化成功了:
[root@master1 ~]#kubectl get node NAME STATUS ROLES AGE VERSION master1 NotReady control-plane 3m56s v1.25.4
现在节点还处于 NotReady 状态,是因为还没有安装 CNI 插件,我们可以先添加一个 Node 节点,再部署网络插件。
4、添加节点
记住初始化集群上面的配置和操作要提前做好,将 master 节点上面的 $HOME/.kube/config 文件拷贝到 node 节点对应的文件中(如果想在 node 节点上操作 kubectl,一般不需要),安装 kubeadm、kubelet、kubectl(可选),然后执行上面初始化完成后提示的 join 命令即可:(这里同时添加其它work节点)
kubeadm join 172.29.9.61:6443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:d4bdf1090a033f285e12087147da051a43cf786e03645fdcd48e2d51e1cacaf7 [root@node1 ~]#kubeadm join 172.29.9.61:6443 --token abcdef.0123456789abcdef \ > --discovery-token-ca-cert-hash sha256:d4bdf1090a033f285e12087147da051a43cf786e03645fdcd48e2d51e1cacaf7 [preflight] Running pre-flight checks [preflight] Reading configuration from the cluster... [preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml' [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Starting the kubelet [kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap... This node has joined the cluster: * Certificate signing request was sent to apiserver and a response was received. * The Kubelet was informed of the new secure connection details. Run 'kubectl get nodes' on the control-plane to see this node join the cluster. [root@node1 ~]# [root@node2 ~]#kubeadm join 172.29.9.61:6443 --token abcdef.0123456789abcdef \ > --discovery-token-ca-cert-hash sha256:d4bdf1090a033f285e12087147da051a43cf786e03645fdcd48e2d51e1cacaf7 [preflight] Running pre-flight checks [preflight] Reading configuration from the cluster... [preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml' [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Starting the kubelet [kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap... This node has joined the cluster: * Certificate signing request was sent to apiserver and a response was received. * The Kubelet was informed of the new secure connection details. Run 'kubectl get nodes' on the control-plane to see this node join the cluster. [root@node2 ~]#
join 命令:如果忘记了上面的 join 命令可以使用命令 kubeadm token create --print-join-command 重新获取。
执行成功后运行 get nodes 命令:
[root@master1 ~]#kubectl get node NAME STATUS ROLES AGE VERSION master1 NotReady control-plane 15m v1.25.4 node1 NotReady <none> 66s v1.25.4 node2 NotReady <none> 61s v1.25.4
5、安装网络插件flannel
这个时候其实集群还不能正常使用,因为还没有安装网络插件,接下来安装网络插件,可以在文档 Creating a cluster with kubeadm | Kubernetes 中选择我们自己的网络插件,这里我们安装 flannel:
[root@master1 ~]#wget https://raw.githubusercontent.com/flannel-io/flannel/v0.20.1/Documentation/kube-flannel.yml --2022-12-05 06:48:34-- https://raw.githubusercontent.com/flannel-io/flannel/v0.20.1/Documentation/kube-flannel.yml Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.110.133, 185.199.111.133, 185.199.108.133, ... Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.110.133|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 4583 (4.5K) [text/plain] Saving to: ‘kube-flannel.yml’ 100%[========================================================================================================================================================>] 4,583 --.-K/s in 0s 2022-12-05 06:48:35 (104 MB/s) - ‘kube-flannel.yml’ saved [4583/4583]
注意:
# 如果有节点是多网卡,则需要在资源清单文件中指定内网网卡 # 搜索到名为 kube-flannel-ds 的 DaemonSet,在kube-flannel容器下面 ☸ ➜ vi kube-flannel.yml ...... containers: - name: kube-flannel #image: flannelcni/flannel:v0.20.1 for ppc64le and mips64le (dockerhub limitations may apply) image: docker.io/rancher/mirrored-flannelcni-flannel:v0.20.1 command: - /opt/bin/flanneld args: - --ip-masq - --kube-subnet-mgr - --iface=eth0 # 如果是多网卡的话,指定内网网卡的名称 #因为自己使用的是虚拟机,只有一张网卡,不用指定了。

- 这个文件不用修改什么,直接apply即可:
[root@master1 ~]#kubectl apply -f kube-flannel.yml # 安装 flannel 网络插件 namespace/kube-flannel created clusterrole.rbac.authorization.k8s.io/flannel created clusterrolebinding.rbac.authorization.k8s.io/flannel created serviceaccount/flannel created configmap/kube-flannel-cfg created daemonset.apps/kube-flannel-ds created [root@master1 ~]#
- 隔一会儿查看 Pod 运行状态:
root@master1 ~]#kubectl get po -A -owide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kube-flannel kube-flannel-ds-955fg 1/1 Running 0 3m18s 172.29.9.63 node2 <none> <none> kube-flannel kube-flannel-ds-ddfqs 1/1 Running 0 3m18s 172.29.9.62 node1 <none> <none> kube-flannel kube-flannel-ds-x2gd6 1/1 Running 0 3m18s 172.29.9.61 master1 <none> <none> kube-system coredns-7b884d5cb7-6jzn6 1/1 Running 0 30m 10.244.0.3 master1 <none> <none> kube-system coredns-7b884d5cb7-gcszd 1/1 Running 0 30m 10.244.0.2 master1 <none> <none> kube-system etcd-master1 1/1 Running 0 30m 172.29.9.61 master1 <none> <none> kube-system kube-apiserver-master1 1/1 Running 0 30m 172.29.9.61 master1 <none> <none> kube-system kube-controller-manager-master1 1/1 Running 0 30m 172.29.9.61 master1 <none> <none> kube-system kube-proxy-l6np4 1/1 Running 0 16m 172.29.9.62 node1 <none> <none> kube-system kube-proxy-vb49s 1/1 Running 0 30m 172.29.9.61 master1 <none> <none> kube-system kube-proxy-xmg7m 1/1 Running 0 15m 172.29.9.63 node2 <none> <none> kube-system kube-scheduler-master1 1/1 Running 0 30m 172.29.9.61 master1 <none> <none>
- 注意:Flannel 网络插件
当我们部署完网络插件后执行 ifconfig 命令,正常会看到新增的cni0与flannel1这两个虚拟设备,但是如果没有看到cni0这个设备也不用太担心(一般是会有的),我们可以观察/var/lib/cni目录是否存在,如果不存在并不是说部署有问题,而是该节点上暂时还没有应用运行,我们只需要在该节点上运行一个 Pod 就可以看到该目录会被创建,并且cni0设备也会被创建出来。
6、Dashboard
1.下载kube-dashboard的yaml文件
# 推荐使用下面这种方式 [root@master1 ~]#wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml --2022-12-05 07:15:13-- https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.109.133, 185.199.110.133, 185.199.111.133, ... Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.109.133|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 7621 (7.4K) [text/plain] Saving to: ‘recommended.yaml’ 100%[========================================================================================================================================================>] 7,621 --.-K/s in 0.006s 2022-12-05 07:15:23 (1.20 MB/s) - ‘recommended.yaml’ saved [7621/7621]
2.修改kube-dashboard.yaml文件
[root@master1 ~]#mv recommended.yaml kube-dashboard.yaml
[root@master1 ~]#vim kube-dashboard.yaml
# 修改Service为NodePort类型
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
ports:
- port: 443
targetPort: 8443
selector:
k8s-app: kubernetes-dashboard
type: NodePort # 加上type=NodePort变成NodePort类型的服务

注意:在 YAML 文件中可以看到新版本 Dashboard 集成了一个 metrics-scraper 的组件,可以通过 Kubernetes的 Metrics API 收集一些基础资源的监控信息,并在 web 页面上展示,所以要想在页面上展示监控信息就需要提供 Metrics API,比如安装 Metrics Server。
3.部署kube-dashboard.yaml文件
直接创建:
[root@master1 ~]#kubectl apply -f kube-dashboard.yaml namespace/kubernetes-dashboard created serviceaccount/kubernetes-dashboard created service/kubernetes-dashboard created secret/kubernetes-dashboard-certs created secret/kubernetes-dashboard-csrf created secret/kubernetes-dashboard-key-holder created configmap/kubernetes-dashboard-settings created role.rbac.authorization.k8s.io/kubernetes-dashboard created clusterrole.rbac.authorization.k8s.io/kubernetes-dashboard created rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created deployment.apps/kubernetes-dashboard created service/dashboard-metrics-scraper created deployment.apps/dashboard-metrics-scraper created
4.验证
新版本的 Dashboard 会被默认安装在 kubernetes-dashboard 这个命名空间下面:
[root@master1 ~]#kubectl get po -A -owide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kube-flannel kube-flannel-ds-955fg 1/1 Running 0 32m 172.29.9.63 node2 <none> <none> kube-flannel kube-flannel-ds-ddfqs 1/1 Running 0 32m 172.29.9.62 node1 <none> <none> kube-flannel kube-flannel-ds-x2gd6 1/1 Running 0 32m 172.29.9.61 master1 <none> <none> kube-system coredns-7b884d5cb7-6jzn6 1/1 Running 0 59m 10.244.0.3 master1 <none> <none> kube-system coredns-7b884d5cb7-gcszd 1/1 Running 0 59m 10.244.0.2 master1 <none> <none> kube-system etcd-master1 1/1 Running 0 59m 172.29.9.61 master1 <none> <none> kube-system kube-apiserver-master1 1/1 Running 0 59m 172.29.9.61 master1 <none> <none> kube-system kube-controller-manager-master1 1/1 Running 0 59m 172.29.9.61 master1 <none> <none> kube-system kube-proxy-l6np4 1/1 Running 0 44m 172.29.9.62 node1 <none> <none> kube-system kube-proxy-vb49s 1/1 Running 0 59m 172.29.9.61 master1 <none> <none> kube-system kube-proxy-xmg7m 1/1 Running 0 44m 172.29.9.63 node2 <none> <none> kube-system kube-scheduler-master1 1/1 Running 0 59m 172.29.9.61 master1 <none> <none> kubernetes-dashboard dashboard-metrics-scraper-64bcc67c9c-27pqg 1/1 Running 0 102s 10.244.1.2 node1 <none> <none> kubernetes-dashboard kubernetes-dashboard-5c8bd6b59-qlgjk 1/1 Running 0 102s 10.244.2.2 node2 <none> <none>
然后查看 Dashboard 的 NodePort 端口:
[root@master1 ~]# kubectl get svc -n kubernetes-dashboard NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE dashboard-metrics-scraper ClusterIP 10.100.184.32 <none> 8000/TCP 2m8s kubernetes-dashboard NodePort 10.101.55.122 <none> 443:30349/TCP 2m8s
然后可以通过上面的 30349端口去访问 Dashboard,要记住使用 https,Chrome 不生效可以使用Firefox 测试,如果没有 Firefox 下面打不开页面,可以点击下页面中的信任证书即可:
信任后就可以访问到 Dashboard 的登录页面了:

然后创建一个具有全局所有权限的用户来登录 Dashboard:(admin.yaml)
[root@master1 ~]#vim admin.yaml kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: admin roleRef: kind: ClusterRole name: cluster-admin apiGroup: rbac.authorization.k8s.io subjects: - kind: ServiceAccount name: admin namespace: kubernetes-dashboard --- apiVersion: v1 kind: ServiceAccount metadata: name: admin namespace: kubernetes-dashboard
直接创建:
[root@master1 ~]#kubectl apply -f admin.yaml clusterrolebinding.rbac.authorization.k8s.io/admin created serviceaccount/admin created
现在我们需要找到可以用来登录的令牌,可以使用 kubectl create token 命令来请求一个 service accounttoken:
# 请求创建一个 token 作为 kubernetes-dashboard 命名空间中的 admin这个 sa 对 kubeapiserver 进行身份验证 [root@master1 ~]#kubectl -n kubernetes-dashboard create token admin #上面的命令执行后会打印出如下所示的 token: eyJhbGciOiJSUzI1NiIsImtpZCI6ImJXaFVwN29KX0lXODl6SGtFZTN4TklxYnNiQzlmeExpb0dqQ2JYbFNBS3MifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNjcwMjAwMjY3LCJpYXQiOjE2NzAxOTY2NjcsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsInNlcnZpY2VhY2NvdW50Ijp7Im5hbWUiOiJhZG1pbiIsInVpZCI6IjYyNDkxYzRhLTc1ZDUtNGVmOC1hODM3LTdiNTIxZmZjNTMwZSJ9fSwibmJmIjoxNjcwMTk2NjY3LCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4ifQ.Qw1vzLiabrKslskQnwXnCIKK3kJWtDEvkcS5URhZTHpkkNHObqCoYMpbW9MB6RsfONV7KHQ0l1FZ13OUs31oQ--hernYB197ROl3AUp_0RMzrY_FIIRJzB5_Kr_hKqEYfm7qfYrn6rgVTgQjVsrPYjK14p5fVV0Lng7MasntsT6Dhqsj9yqo2-6Tjj2Xtc0kL4Xr_vVmziJOA9_Fj-axe6SzUd9UoWyz8jjbL31d8A7QbsuhUiyAfInSpgL2IFJ0d8-iXVhLwgFE9C_AfEmsTf_fXn0SIm7e9HS9RQTDw0wtz6aUnnqDlop3LZG-wCzDRd3WN2ajodWUftlNg5hoAQ
然后用上面的字符串作为 token 登录 Dashboard 即可:

到这里我们就完成了使用 kubeadm 搭建 v1.25.4 版本的 kubernetes 集群。😘
最后记得做下3台虚机的快照,方便后期还原。🤣


7、清理
如果你的集群安装过程中遇到了其他问题,我们可以使用下面的命令来进行重置:
➜ ~ kubeadm reset ➜ ~ ifconfig cni0 down && ip link delete cni0 ➜ ~ ifconfig flannel.1 down && ip link delete flannel.1➜ ~ rm -rf /var/lib/cni/
8、牛刀小试,快速部署一个网站
1、使用Deployment控制器部署镜像:
[root@master1 ~]#kubectl create deployment web --image=nginx deployment.apps/web created
此时用kubectl get pods命令查看pod是否是运行的:
[root@master1 ~]#kubectl get pods,deploy NAME READY STATUS RESTARTS AGE pod/web-8667899c97-4d58d 1/1 Running 0 24s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/web 1/1 1 1 24s
2、使用Service将Pod暴露出去:
[root@master1 ~]#kubectl expose deployment web --port=80 --target-port=80 --type=NodePort service/web exposed #备注 第一个--port是k8s集群内部访问端口,通过集群内部访问的ip, cluster ip; 第二个--target--port是镜像里服务跑的端口号;
用kubectl get service命令查看刚才创建的service:
[root@master1 ~]#kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 6h6m web NodePort 10.103.191.211 <none> 80:32302/TCP 21s
3、访问应用:(实验现象符合预期,完美!)
http://NodeIP:Port # 端口随机生成,通过get svc获取
#注意:此时你通过任意的nodeip:端口都可访问nginx应用;(masterip:端口是不行的)

关于我
我的博客主旨:
- 排版美观,语言精炼;
- 文档即手册,步骤明细,拒绝埋坑,提供源码;
- 本人实战文档都是亲测成功的,各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人帮您解决问题,让我们一起进步!
🍀 微信二维码
x2675263825 (舍得), qq:2675263825。

🍀 微信公众号
《云原生架构师实战》

🍀 语雀
彦 · 语雀
语雀博客 · 语雀 《语雀博客》

🍀 博客
www.onlyyou520.com

🍀 csdn
一念一生~one的博客_CSDN博客-k8s,Linux,git领域博主
🍀 知乎
一个人 - 知乎

最后
好了,关于本次就到这里了,感谢大家阅读,最后祝大家生活快乐,每天都过的有意义哦,我们下期见!





![[附源码]计算机毕业设计基于Springboot设备运维平台出入库模块APP](https://img-blog.csdnimg.cn/368e7e0a9d114d41a9cc528f097588a8.png)

![[附源码]JAVA毕业设计旅游景点展示平台的设计与实现(系统+LW)](https://img-blog.csdnimg.cn/8590f7252ccd43f8a212d47caa611678.png)