Abstract
真实失真图像的盲图像质量评估(BIQA)一直是一个具有挑战性的问题,因为在野外采集的图像包含各种各样的内容和各种类型的失真。目前绝大多数的BIQA方法都专注于如何预测合成图像的质量,但当应用于真实世界的失真图像时却失败了。为了应对这一挑战,我们提出了一种自适应超网络结构,以盲评估图像质量在野外。我们将IQA过程分为三个阶段,包括内容理解、感知规则学习和质量预测。在提取图像语义后,通过超网络自适应建立感知规则,并将其应用于质量预测网络。在我们的模型中,图像质量可以自适应的方式估计,从而很好地适用于在野外捕获的各种图像。实验结果表明,我们的方法不仅在挑战真实图像数据库上的性能优于目前最先进的方法,而且在合成图像数据库上也达到了与之竞争的性能,尽管它不是专门为合成任务设计的。
1. Introduction
图像质量评估(IQA)的目标是使计算机能够像人类一样感知图像质量。在过去的几十年里,人们付出了巨大的努力,提出了各种IQA方法。尽管他们在评估实验室合成的扭曲图像方面取得了成功,但对真实扭曲图像的IQA仍然是一个挑战。挑战主要体现在三个方面:
首先,由于无法获取参考图像,野外IQA仅限于盲IQA (BIQA)领域。参考图像的局限性已被广泛接受,使BIQA成为三种IQA中最难解决的问题,即全参考IQA (FR-IQA)、减少参考IQA (RR-IQA)和非参考IQA (NR-IQA)。其次,与普通的合成失真(如高斯模糊、JPEG压缩)添加到整个图像区域不同,真实失真更加复杂。捕获的图像不仅存在全局均匀畸变(如失焦、低照度),而且在局部区域还存在其他类型的非均匀畸变(如物体移动、过光、重影)。因此,算法面临的挑战是准确捕捉全局和局部的畸变,并将它们合并成一个适当的质量预测。第三,与合成的IQA数据库相比,图像内容变异是IQA任务中一个典型的挑战,对真实的IQA数据库来说难度更大。现有的合成IQA数据库LIVE[34]、TID2013[32]和CSIQ[21]仅包含不超过30张的参考图片,图像内容意义受限,而真正的IQA数据库LIVE Challenge[8]和KonIQ-10k[13]分别包含1169张和10073张包含不同内容的图片。这种巨大的内容变异对现有的IQA方法的泛化能力提出了很大的挑战。
由于失真的多样性和内容的多样性,真实失真图像的IQA问题一直没有得到很好的解决。如图1所示,提取的特征随着图像的变化而变化,导致质量预测与平均意见评分(mean opinion score, MOS)不一致。在之前的工作中,无论是手工制作的基于特征的方法,还是具有浅层架构的网络,都不能很好地解决综合IQA任务,都不能处理真实的失真。这表明低水平的特征不足以表现现实世界中的复杂失真。因此,人们尝试使用深度语义特征作为质量描述符:在分类任务中预先训练的深度模型被用来预测真实世界的失真。这背后的假设是,真实的扭曲实际上存在于图像生成的分类数据库(如ImageNet[7])中,而且这些预先训练的特征在某种程度上已经具有质量意识。
虽然这些尝试取得了有希望的改善,但仍缺乏进一步的努力。具体来说,简单地采用网络体系结构(最初是为学习如何识别对象而设计的)来完成IQA的任务存在两个缺点。首先,目前的深度模型只学习全局特征进行分类。然而,对于真实的IQA来说,存在着许多不同的扭曲,其中大部分存在于当地。忽略局部模式可能会导致预测的质量与人类视觉感知的不一致,因为人类视觉系统(HVS)对局部畸变很敏感,而图像的其余部分表现出相当好的质量[21]。其次,随着图像内容的变化,人类感知不同物体质量的方式也会发生变化。如[22]所示,一个清晰的蓝色天空的图像会被人类检查员认为是高质量的,而大多数IQA方法会因为图像包含的大面积平坦而误认为是一个模糊的图像。因此,在识别图像内容之前直接预测图像质量不符合人类感知世界的规律。在HVS中,自顶向下的感知模型表明,人类在注意其他相关的子任务(如质量评估)之前,会试图理解图像。然而,在目前的模型中,将IQA任务融合到语义识别网络中,迫使网络同时学习图像内容和图像质量,而让网络在识别图像内容后学习如何判断图像质量更为合适。
在本文中,我们的目标是开发一个真实的IQA方法,通过考虑上述两个挑战经常出现在现实世界的图像:失真多样性和内容变化。我们提出了一种局部失真感知模块来从多尺度中提取局部特征来处理失真多样性,并引入了一种超网络结构来动态生成权值来覆盖广泛的内容变化的质量预测网络。在我们的方法中,所提出的超网络可以根据其识别的内容自适应学习质量感知规则,目标网络遵循这种方式给出最终的质量预测。通过根据图像内容判断图像质量,该网络有望给出更符合人类感知的预测。总的来说,本文方法的主要贡献可以归纳为三个方面:
•为了提高对野外图像的评估能力,我们提出了一种基于超网络的IQA模型,该模型可以自适应调整质量预测参数。该网络以内容感知的方式预测图像质量,识别过程后的感知更符合人类认识世界的方式。
•由于局部特征有利于处理图像中的不均匀失真,我们引入了局部失真感知模块,进一步捕获图像质量。我们集合局部失真特征和全局语义特征来收集细粒度细节和整体信息,然后根据这种多尺度表示预测图像质量。
•实验结果表明,尽管我们没有专门设计提取合成特征的模型,但我们的方法不仅在真实的IQA数据库上优于其他竞争对手,而且在合成的IQA数据库上也达到了竞争对手的结果。这表明我们提出的模型是强大的和可推广的。
2. Related Work
2.1. IQA for Synthetically Distorted Images
在过去的几十年里,人们对综合IQA进行了大量的研究,主要有基于手工特征的IQA和基于学习特征的IQA两种方法。手工制作的基于特征的方法通常利用NSS模型来捕捉失真。通过对对失真外观敏感的场景统计建模,可以检测和量化图像质量的退化程度。这些质量感知的自然场景参数包括离散小波系数[30]、跨子带相关系数[1]、DCT系数[33]、局部归一化亮度系数及其两两乘积[29]、图像梯度、log-Gabor响应和颜色统计[3]。用于从合成畸变图像中获取统计信息的分布模型包括广义高斯分布(GGD)[29,30]、非对称广义高斯分布(AGGD)[3,29]、威布尔分布[3]、三阶多项式[33]和直方图计数[38]。然而,这些手工制作的功能,需要专业的设计和耗时。另外,场景统计特征从全局的角度表征图像质量,无法度量真实畸变图像中常见的局部畸变。
受机器学习在许多计算机视觉任务中的成功启发[9,10,39,40],一些基于学习的方法也被提出。在早期,引入了基于码本的学习方法[37,42,43,45]。由于其强大的学习能力,基于CNN的方法被提出,并在合成IQA中取得了显著的进展。在[14]中,使用继承自[43]的简单的pooling策略CNN进行质量预测。Ma等人[27]提出了一种更深层次的网络,可以同时学习失真类型和图像质量。在[16,23,31]中,我们学习了畸变图像的误差映射来指导质量预测,学习误差映射的方法包括残差误差[16]的训练、由FR-IQA方法计算的质量映射[31]和GAN生成的图像参考[23]。[24]和[26]注意到现有IQA数据库中训练数据的大小有限,提出通过标注训练样本的质量等级而不是质量分数来生成大量的训练样本。使用Siamese网络[5]和RankNet[4]体系结构分别学习图像的秩。
虽然这些IQA方法在合成数据库上取得了很大的性能改进,但在面对大规模数据时仍存在挑战[25,28],这表明内容变异的问题还没有得到很好的管理。研究还表明,IQA模型在合成数据库上表现良好,在真实的IQA数据库上给出了不准确的预测,这表明在野外存在的各种畸变类型的特征不能很容易地被设计用于提取合成畸变的体系结构捕获。
2.2. IQA for Authentically Distorted Images
虽然大多数的IQA模型都集中在合成失真的图像上,但针对更具挑战性的真实IQA问题的研究相对较少。在深度学习的辅助下,深度语义特征能够有效地表征图像质量。在[17]中,Kim等人表明,AlexNet[20]和ResNet[12]在ImageNet等分类数据库上预先训练的深度特征与感知质量有很强的关系,并取得了卓越的准确性。在[13]中,测试了更多的预先训练的基线网络,结果证实了语义特征在解决野外IQA问题中的力量。在[46]中,引入了两流网络结构来预测合成图像和真实图像的畸变。在他们的工作中,真实的质量预测流采用了vgg - 16[35]进行特征提取。在[22]中,Li等人提出利用多块ResNet50特征的统计量进行质量预测。最近,Zhang et al.[47]提出使用合成数据库和可信数据库中的图像对训练IQA模型,用于特征提取的骨干是ResNet-34。可以看出,目前的模型直接利用语义学习网络的输出特征进行质量预测,但主要存在两个缺陷:首先,将语义学习和质量预测混合在一个网络中,忽略了图像语义对质量感知方式的影响,而在HVS中,图像质量是在识别出图像内容后进行判断的。其次,由于深度语义特征是在全局尺度上提取的,因此忽略了图形化图像中普遍存在的局部失真问题。因此,网络无法捕捉图像的细节质量,导致预测不准确。
在这项工作中,我们提出了一种新的多尺度特征融合超网络结构来预测在野外的图像质量。以往的模型将语义理解和质量预测结合在一起,而我们将质量预测过程分为两个步骤:首先学习图像语义特征,然后根据图像所传递的内容预测质量。这个过程遵循了人类自上而下的感知流程,我们设计了一个超网络连接来模仿从图像内容到感知质量的方式的映射。此外,除了简单地使用全局语义特征来理解内容外,我们还提出融合多尺度的局部失真特征来更好地表征图像质量。通过这种方式,我们的质量预测程序变得自适应,内容感知,并能够从图像中捕捉细节和整体信息。
3. Proposed Method
在本研究中,我们的目标是开发一个根据图像内容自适应预测图像质量的质量评估网络。我们的网络体系结构如图2所示。该网络由三部分组成:提取图像语义特征的主干网络、预测图像质量的目标网络和生成目标网络自适应参数的超网络。我们将首先介绍我们的自适应IQA模型,然后在下面介绍三个子网的细节。
3.1. Self-Adaptive IQA Model
传统的基于深度学习的质量预测模型接收输入图像,直接将其映射为质量分数,其过程描述如下:

该预测模型暗示了提取同一种质量特征来预测不同的图像。然而,在实际中,由于图像内容不同,使用相同的规则来预测不同图像的质量并不能完全覆盖它们不同的展示结构。如[22]所示,人类会将清晰的蓝色天空的图像视为高质量的,而对于质量预测模型来说,这张图片最有可能被视为模糊污染的图像,因为它包含了大面积的平坦区域。这种错误预测的原因是对图像语义的忽视。对于人类来说,在理解图像内容的条件下,使用相应的规则来判断图像的质量。因此,为了模拟人类的感知过程,我们将IQA的任务建模如下:


通过引入中间变量θx和超网络,将IQA任务划分为三个步骤:语义特征提取、感知规则建立和质量预测。我们使用骨干网提取图像的语义特征S(x),使用超网络学习质量感知规则θx,使用质量预测目标网络获得最终的质量分数q。与式(1)中的质量预测模型不需要语义理解或内容识别直接估计图像质量不同,我们提出的模型遵循自上而下的感知机制,因为它试图理解图像,直到它执行质量判断的任务。这种设计使得我们的网络在面对内容变化的图像时能够更加灵活地提取影响图像质量的因素。此外,所提出的质量预测过程也更符合人类对图像质量的感知方式。
为了减少目标网络参数θx的数量,也为了更容易训练,我们将目标网络的输入简化为内容感知向量vx = Sms(x),其中Sms表示内容感知向量也被主干语义抽取网络提取,但融合了多尺度特征来捕捉图像中的局部失真。在此变更下,整个基于超网络的IQA模型可描述为:
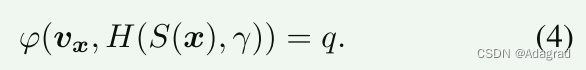
在质量预测模型的基础上,我们提出了以下三个子网络的结构。
3.2. Semantic Feature Extraction Network
如图2所示,我们的网络体系结构的前端部分是一个通用的语义特征提取网络。语义提取网络以理解图像内容为重点,输出两条特征流进行质量预测。将语义特征S(x)直接输入超网络进行权重生成,将多尺度内容特征流Sms(x)作为目标网络的输入。我们之所以提取多尺度的内容特征,是因为最后一层提取的语义特征仅仅代表了整体的图像内容。为了捕捉现实世界的局部失真,我们提出了一种通过局部失真感知模块提取多尺度特征的方法。如图3所示,我们设计的局部失真感知模块包括一系列操作,包括将多尺度特征图划分为不重叠的小块,将小块沿通道维数叠加,进行1×1卷积并将其全局平均为向量。该模块可以看作是一种基于注意力的补丁提取器,能够感知局部畸变对应的特征补丁,从而更好地捕捉其质量。
具体而言,我们使用ResNet50[12]作为语义特征提取的主干模型。使用ImageNet[7]上的预训练模型进行网络初始化。在我们的网络中,去除原始ResNet50的最后两层,即平均池化层和全连接层,输出特征流。我们从conv2 10、conv3 12、conv4 18层中提取多尺度特征作为局部失真感知模块的输入,该模块输出多尺度内容向量vx。
3.3. Hyper Network for Learning Perception Rule
受[19]的启发,我们的超网络由三个1×1卷积层和几个权值生成分支组成。由于在本文提出的网络中,全连通层作为基本的目标网络组件(见3.4节),因此需要产生两类网络参数,即全连通层权值和偏差。对于不同类型的参数,我们使用不同的权值生成方法。全连通层权值是通过对提取的特征进行卷积和重塑操作生成的,而全连通层权值是通过简单的平均池化和全连通产生的,因为偏置权值的参数量要少得多。根据目标网络中对应层的尺寸确定卷积层和全连通层的输出通道,进行尺寸匹配。将生成的权值作为感知图像质量的规则,进一步指导目标网络进行图像质量预测。
3.4. Target Network for Quality Prediction
由于语义提取网络提取的多尺度特征是内容感知的,目标网络的功能就是简单地将学习到的图像内容映射到质量分数。因此,我们使用一个小而简单的网络来进行质量预测。如图2所示,我们的目标网络由四个全连通的层组成,接收多尺度内容特征向量作为输入,通过权值确定的层进行传播,得到最终的质量分数。在目标网络中,我们选择sigmoid函数作为激活函数。
3.5. Implementation Details
我们通过PyTorch实现了我们的模型,并在NVIDIA 1080Ti gpu上进行了培训和测试。按照[17]的训练策略,我们从每个训练图像中随机抽取并水平翻转25个大小为224×224像素的patch进行增强。训练补丁继承了源图像的质量分数,最小化训练集上的L1损失:


4. Experiments
5. Conclusion
在本文中,我们提出了一个新的网络,以克服在真实的IQA任务中出现的两个具有挑战性的问题:失真多样性和内容变异。该网络将质量预测与内容理解分离开来,以模拟人类如何感知图像质量。我们采用超网络结构来完成这个感知流程,并进一步引入一个多尺度局部失真感知模块来捕获复杂的失真。实验结果表明,该方法具有较强的泛化能力,具有更广泛的应用前景。