ChatGLM的部署微调等,很多资料,不再赘述。
P-tuning V2
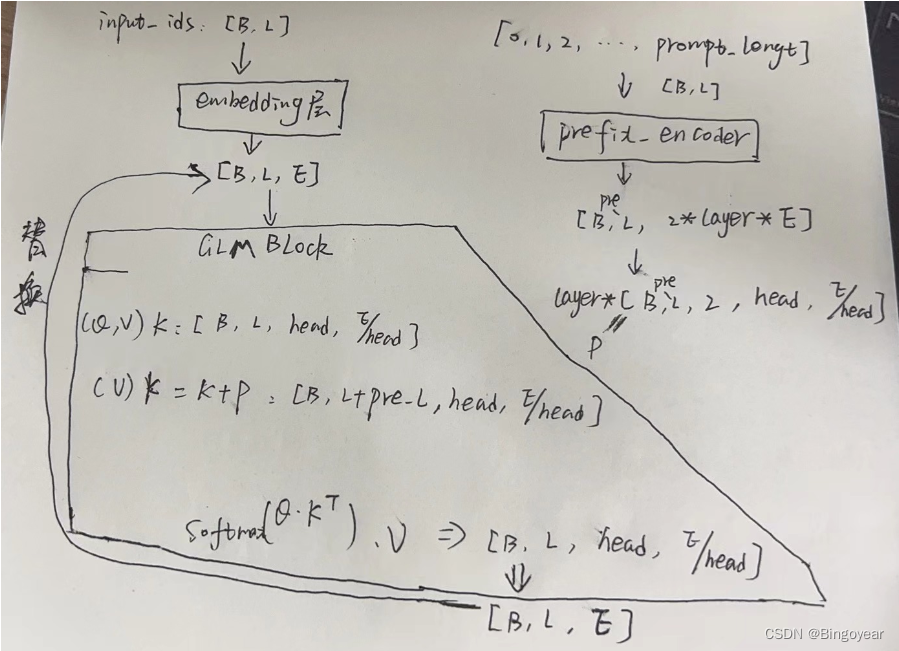
以P-Turing V2为例,介绍ChatGLM的网络结构。P-tuning V2方法训练时冻结模型的全部参数,只激活prefix_encoder的参数。
1、prefix encoder
初始化pre_len,代表prompt的最大长度
1)模型的输入为[0, 1, 2, …, pre_len-1],复制, 维度为[B, pre_L]
2) 经prefix_encoder层,输出维度 [B, pre_L, 2*layer_num*E]。layer_num和下面GLMBlock的数量一致。prefix_encoder是embedding层和MLP的组合。
3) 变换维度,令P=维度为[B, pre_L, 2*E]的张量
2、主模型
1)模型输入:[B, L]
2)经embedding层,输出embed:= [B, L, E],E为embedding的维度
3)经过多层GLMBlock层,输出维度[B, L, E]
GLMBlock是一个类Transformer的层,做改变的地方在Attention层。
在第i层,embed经若干变换,可以得到Q、K、V三个张量,维度如下 ( Q , V ) K : [ B , L , h e a d , E / h e a d ] (Q,V)K: [B, L, head, E/head] (Q,V)K:[B,L,head,E/head]
对每个K和V,添加prefix_encoder层的张量P ( V ) K = K + P : [ B , L + p r e _ L , h e a d , E / h e a d ] (V)K=K+P:[B, L+pre\_L, head, E/head] (V)K=K+P:[B,L+pre_L,head,E/head] 后面就是softmax函数那一套,输出张量hidden维度[B, L, E]
令embed=hidden,开启下一轮
4)最后一层的hidden,经layer_norm层,输出 [B, L, E],后面做损失。