首先,你已经安装好anaconda3、创建好环境、下载好TensorFlow2模块并且下载好jupyter了,那么我们就直接打开jupyter开始进行CIFAR10数据集的训练。
第一步:下载CIFAR10数据集
下载网址:http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
将数据集下载到合适的路径,方便模型训练的时候调用
第二步:导入该导的库
# tensorflow1.x
import tensorflow as tf
import numpy as np
import os
from matplotlib import pyplot as plt第三步:加载刚刚下载的数据集,如果你下载了 cifar-10-python.tar.gz那么就先解压这个压缩包,将里面的文件放入一个文件夹,我这里放在为cifar-10-batches-py目录下,所有文件如图

然后加载该数据集
import pickle
def unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
def load_data(path):
# 读取训练数据
train_images = []
train_labels = []
for i in range(1, 6):
file = path + "/data_batch_{}".format(i)
data = unpickle(file)
train_images.append(data[b"data"])
train_labels.append(data[b"labels"])
train_images = np.concatenate(train_images)
train_labels = np.concatenate(train_labels)
# 读取测试数据
file = path + "/test_batch"
data = unpickle(file)
test_images = data[b"data"]
test_labels = np.array(data[b"labels"])
# 转换数据类型
train_images = train_images.astype(np.float32)
test_images = test_images.astype(np.float32)
y_train = np.array(train_labels)
y_test = np.array(test_labels)
# 将像素值缩放到[0, 1]范围内
x_train = train_images/255.0
x_test = test_images/255.0
# 将标签数据转换为one-hot编码
# train_labels = tf.keras.utils.to_categorical(train_labels, num_classes=10)
# test_labels = tf.keras.utils.to_categorical(test_labels, num_classes=10)
return (x_train, y_train), (x_test, y_test)
# 加载数据集
(train_images, train_labels), (test_images, test_labels) = load_data("../cifar_data/cifar-10-batches-py")
train_images = train_images.reshape(50000, 32, 32, 3)
test_images = test_images.reshape(10000, 32, 32, 3)当然还有更简单的方法那就是使用TensorFlow内部模块下载数据集,如下
# 下载数据集
cifar10=tf.keras.datasets.cifar10
(x_train,y_train),(x_test,y_test)=cifar10.load_data()
x_train[0][0][0]
# 对图像images进行数字标准化
x_train=x_train.astype('float32')/255.0
x_test = x_test.astype('float32')/ 255.0第四步:数据集本来的标签是数字,我们可以将它转化成对应的类型名
label_dict={0:"airplane",1:"automobile",2:"bird",3:"cat",4:"deer",5:"dog", 6:"frog", 7:"horse", 8:"ship", 9:"truck"}第五步:开始构建神经网络模型,这里我就简单构建一个类似AlexNet的卷积神网络模型
# 建立卷积神经网络CNN模型AlexNet
#建立Sequential线性堆叠模型
'''
Conv2D(filters=,kernel_size=,strides=,padding=,activation=,input_shape=,)
filters:卷积核数量,即输出的特征图数量。
kernel_size:卷积核大小,可以是一个整数或者一个元组,例如(3, 3)。
strides:卷积步长,可以是一个整数或者一个元组,例如(1, 1)。
padding:填充方式,可以是'same'或'valid'。'same'表示在输入图像四周填充0,保证输出特征图大小与输入图像大小相同;
'valid'表示不填充,直接进行卷积运算。
activation:激活函数,可以是一个字符串、一个函数或者一个可调用对象。
input_shape:输入图像的形状
'''
'''
MaxPooling2D(pool_size=,strides=,padding=,)
pool_size:池化窗口大小,可以是一个整数或者一个元组,例如(2, 2)表示2x2的池化窗口。
'''
#this is a noe model,you just have to choose one or the other
def creatAlexNet():
model = tf.keras.models.Sequential()#第1个卷积层
model.add(tf.keras.layers.Conv2D(filters=32,
kernel_size=(3,3),
input_shape=(32,32,3),
activation='relu', padding='same'))
# 防止过拟合
model.add(tf.keras.layers.Dropout(rate=0.3))
#第1个池化层
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2,2)))
#第2个卷积层
model.add(tf.keras.layers.Conv2D(filters = 64,kernel_size=(3,3), activation='relu', padding ='same'))
# 防止过拟合
model.add(tf.keras.layers.Dropout(rate=0.3))#第2个池化层
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2,2)))# 平坦层
#第3个卷积层
model.add(tf.keras.layers.Conv2D(filters = 128,kernel_size=(3,3), activation='relu', padding ='same'))
# 防止过拟合
model.add(tf.keras.layers.Dropout(rate=0.3))#第3个池化层
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2,2)))# 平坦层
model.add(tf.keras.layers.Flatten())# 添加输出层
model.add(tf.keras.layers.Dense(10,activation='softmax'))
return model
第六步:开始加载模型
执行模型函数
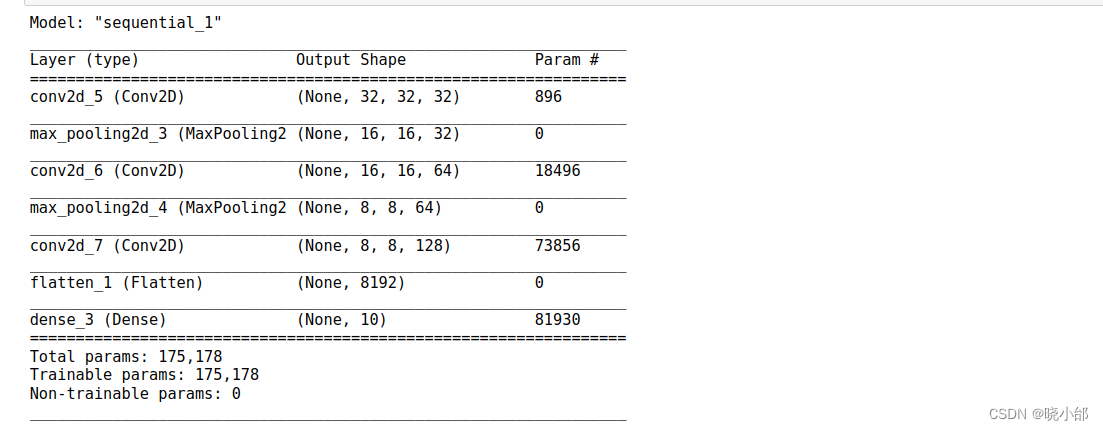
model = creatAlexNet()输出摘要
model.summary()摘要结果如下:
超参数定义及模型训练
'''
model.compile(optimizer =,loss=,metrics=)
optimizer:指定优化器,可以传入字符串标识符(如'rmsprop'、'adam'等),也可以传入Optimizer类的实例。
loss:指定损失函数,可以传入字符串标识符(如'mse'、'categorical_crossentropy'等),也可以传入自定义的损失函数。
metrics:指定评估指标,可以传入字符串标识符(如'accuracy'、'mae'等),也可以传入自定义的评估函数或函数列表
'''
'''
model.fit(x=,y=,batch_size=,epochs=,verbose=,validation_data=,validation_split=,shuffle=,callbacks=)
x:训练数据,通常为一个形状为(样本数, 特征数)的numpy数组,也可以是一个包含多个numpy数组的列表。
y:标签,也是一个numpy数组或列表,长度应与x的第一维相同。
batch_size:批量大小,表示每次迭代训练的样本数,通常选择2的幂次方,比如32、64、128等。
epochs:训练轮数,一个轮数表示使用所有训练数据进行了一次前向传播和反向传播,通常需要根据实际情况调整。
verbose:输出详细信息,0表示不输出,1表示输出进度条,2表示每个epoch输出一次。
validation_data:验证数据,通常为一个形状与x相同的numpy数组,也可以是一个包含多个numpy数组的列表。
validation_split:切分验证集,将训练数据的一部分用作验证数据,取值范围在0到1之间,表示将训练数据的一部分划分为验证数据的比例。
shuffle:是否打乱训练数据,True表示每个epoch之前打乱数据,False表示不打乱数据。
callbacks:回调函数,用于在训练过程中定期保存模型、调整学习率等操作,
常用的回调函数包括ModelCheckpoint、EarlyStopping、ReduceLROnPlateau等。
'''
# 设置训练参数
train_epochs=10#训练轮数
batch_size=100#单次训练样本数(批次大小)
# 定义训练模式
model.compile(optimizer ='adam',#优化器
loss='sparse_categorical_crossentropy',#损失函数
metrics=['accuracy'])#评估模型的方式
#训练模型
train_history = model.fit(x_train,y_train,validation_split = 0.2, epochs = train_epochs,
batch_size = batch_size)训练过程如下:

第七步:训练的损失率和成功率的可视化图
# 定义训练过程可视化函数
def visu_train_history(train_history,train_metric,validation_metric):
plt.plot(train_history.history[train_metric])
plt.plot(train_history.history[validation_metric])
plt.title('Train History')
plt.ylabel(train_metric)
plt.xlabel('epoch')
plt.legend(['train','validation'],loc='upper left')
plt.show()损失率可视化
visu_train_history(train_history,'loss','val_loss') 
成功率可视化
visu_train_history(train_history,'accuracy','val_accuracy') 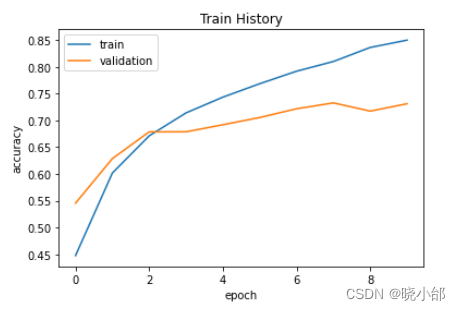
第八步:模型测试及评估
用测试集评估模型
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print('Test accuracy:', test_acc)模型测试,可视化测试
#model test
preds = model.predict(x_test)可视化函数
# 定义显示图像数据及其对应标签的函数
# 图像列表
def plot_images_labels_prediction(images,# 标签列表
labels,
preds,#预测值列表
index,#从第index个开始显示
num = 5): # 缺省一次显示5幅
fig=plt.gcf()#获取当前图表,Get Current Figure
fig.set_size_inches(12,6)#1英寸等于2.54cm
if num > 10:#最多显示10个子图
num = 10
for i in range(0, num):
ax = plt.subplot(2,5,i+1)#获取当前要处理的子图
plt.tight_layout()
ax.imshow(images[index])
title=str(i)+','+label_dict[labels[index][0]]#构建该图上要显示的title信息
if len(preds)>0:
title +='=>' + label_dict[np.argmax(preds[index])]
ax.set_title(title,fontsize=10)#显示图上的title信息
index += 1
plt.show()
执行可视化函数
plot_images_labels_prediction(x_test,y_test, preds,15,30)结果如下:

第九步:模型保存及模型使用,测试外部图片
保存模型
# 保存模型
model_filename ='models/cifarCNNModel.h5'
model.save(model_filename)加载模型,测试模型
方法一:使用TensorFlow内部模块加载图片,将dog.jpg路径换成你的图片路径
# 加载模型
loaded_model = tf.keras.models.load_model('models/cifarCNNModel.h5')
type = ("airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck")
label_dict={0:"airplane",1:"automobile",2:"bird",3:"cat",4:"deer",5:"dog", 6:"frog", 7:"horse", 8:"ship", 9:"truck"}
# 加载外来图片
img = tf.keras.preprocessing.image.load_img(
'dog.jpg', target_size=(32, 32)
)
# 转化为numpy数组
img_array = tf.keras.preprocessing.image.img_to_array(img)
# 归一化数据
img_array = img_array / 255.0
# 维度扩展
img_array = np.expand_dims(img_array, axis=0)
# 预测类别
predictions = loaded_model.predict(img_array)
pre_label = np.argmax(predictions)
plt.title("type:{}, pre_label:{}".format(label_dict[pre_label],pre_label))
plt.imshow(img, cmap=plt.get_cmap('gray'))结果如下,预测结果是正确的,我这里在浏览器下载的确实是一张狗的图片

方法二:使用PIL的库加载图片进行预测
from PIL import Image
import numpy as np
img = Image.open('./cat.jpg')
img = img.resize((32, 32))
img_arr = np.array(img) / 255.0
img_arr = img_arr.reshape(1, 32, 32, 3)
pred = model.predict(img_arr)
class_idx = np.argmax(pred)
plt.title("type:{}, pre_label:{}".format(label_dict[class_idx],class_idx))
plt.imshow(img, cmap=plt.get_cmap('gray'))结果如下,也是正确的,我这张图片确实是一张猫的图片

方法三:从网络上加载图片进行预测,将下面的网址换成你想要预测的图片网址
# 加载模型
loaded_model = tf.keras.models.load_model('models/cifarCNNModel.h5')
# 使用模型预测浏览器上的一张图片
type = ("airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck")
label_dict={0:"airplane",1:"automobile",2:"bird",3:"cat",4:"deer",5:"dog", 6:"frog", 7:"horse", 8:"ship", 9:"truck"}
url = 'https://img1.baidu.com/it/u=1284172325,1569939558&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=580'
with urllib.request.urlopen(url) as url_response:
img_array = np.asarray(bytearray(url_response.read()), dtype=np.uint8)
img = cv2.imdecode(img_array, cv2.IMREAD_COLOR)
img_array = cv2.resize(img, (32, 32))
img_array = img_array / 255.0
img_array = np.expand_dims(img_array, axis=0)
predict_label = np.argmax(loaded_model.predict(img_array), axis=-1)[0]
plt.imshow(img, cmap=plt.get_cmap('gray'))
plt.title("Predict: {},Predict_label: {}".format(type[predict_label],predict_label))
plt.xticks([])
plt.yticks([])结果如下, 这张就预测错了,明明是狗,预测成鸟(bird)去了

那么本篇文章CIFAR10数据集分类模型训练就到此结束,感谢大家的继续支持!