介绍
计算机视觉项目可能会非常令人望而生畏,涉及到各种工具和包,如OpenCV、TensorFlow和PyTorch等等。不仅需要熟悉所涉及的工具和API,还需要正确组合各个包,以使整个计算机视觉流水线正常工作。
例如,OpenCV以[H,W,C]格式处理带有BGR通道的图像,而TensorFlow以相同格式处理带有RGB通道的图像,PyTorch以[C,H,W]格式处理带有RGB通道的图像。由于这种不一致性,图像格式必须在图像在各个库之间传递时不断修改。这种问题(以及其他问题!)导致了大量样板代码,我们希望在一般情况下避免使用。
如果我们能够使用单一统一的流水线简化计算机视觉流程,该怎么办呢?这个流水线应具备以下特点:
开源且没有像GPL-3.0这样的限制,以降低成本。
模块化,适用于各种用例。
最先进的,以获得最佳性能。
最小化,以减少流水线的复杂性。
事实证明,PeekingDuck部分解决了所有这些问题 —— 这是新近由AI Singapore发布的计算机视觉包!
PeekingDuck
PeekingDuck是一个计算机视觉框架,具备以下特点:
开源(Apache 2.0) —— 没有成本或限制。
模块化 —— 可以混合匹配各种模块以解决不同的用例。
最先进的计算机视觉推理 —— 强大的深度学习模型。
最小化 —— 真正不需要Python代码!
通过使用像pip这样的软件包管理器安装PeekingDuck作为Python软件包后,可以直接从命令行/终端使用该软件包,轻松直接地与其他应用程序集成。
安装PeekingDuck
PeekingDuck作为Python软件包进行安装:
pip install peekingduck节点 —— PeekingDuck的基本构建块
使用PeekingDuck,计算机视觉流程使用称为节点的基本构建块构建。每个节点处理不同的操作集,通过混合使用各种节点,可以创建不同的流水线。截至撰写本文,PeekingDuck有6种不同类型的节点:
输入节点 —— 从实时摄像头或视频/图像文件中将图像数据输入到流水线中。
增强 - 预处理图像数据。
模型 - 执行诸如目标检测或姿态估计等计算机视觉任务。
涂抹 - 后处理模型输出。
绘制 - 可视化模型输出,如边界框。
输出 - 将模型输出保存到磁盘。
人物追踪流程
使用PeekingDuck非常简单!在本节中,我们将演示如何使用PeekingDuck创建一个人物追踪流程!
初始化PeekingDuck
第一步是在指定的目录中初始化PeekingDuck(在本例中为person_tracking/)。
mkdir person_tracking
cd person_tracking
peekingduck init这将在person_tracking/目录下创建一个名为pipeline_config.yml的配置文件,以及其他一些源代码文件。为了让PeekingDuck按照我们的意愿进行操作,我们需要修改pipeline_config.yml文件。
在我们的情况下,pipeline_config.yml应包含以下内容:
nodes:
- input.visual:
source: venice-2-train.mp4
- model.jde
- dabble.statistics:
maximum: obj_attrs["ids"]
- draw.bbox
- draw.tag:
show: ["ids"]
- draw.legend:
show: ["cum_max"]
- output.media_writer:
output_dir: output/我们在这个任务中使用了以下节点:
input.visual —— 指定要从中加载图像数据的文件。我们使用从MOT15数据集的Venice-2图像拼接而成的视频。
model.jde —— 指定要使用的模型。对于人物追踪,我们使用Joint Detection and Embedding (JDE)模型。
dabble.statistics —— 基于模型的输出进行统计计算。在这种情况下,我们计算每帧检测到的ID的最大数量。
draw.bbox —— 在每帧上绘制检测到的边界框。
draw.tag —— 为每个边界框绘制相应的标签。
draw.legend —— 绘制累积最大检测数。
output.media_writer —— 将模型的预测输出保存到磁盘上。 通过混合和匹配不同的节点,我们可以构建不同的流水线来解决不同的计算机视觉用例。PeekingDuck网站上提供了可用节点的详细列表。
https://peekingduck.readthedocs.io/en/stable/nodes/input.html
准备数据
接下来是准备数据。在我们的情况下,我们使用OpenCV将来自MOT15数据集的Venice-2图像拼接成一个名为venice-2-train.mp4的视频文件,帧率为30,分辨率为[1920, 1080]。
import cv2
import os
w = cv2.VideoWriter("venice-2-train.mp4",
cv2.VideoWriter_fourcc(*"MP4V"),
30, [1920, 1080])
files = sorted(os.listdir("MOT15/train/Venice-2/img1"))
for f in files:
im = cv2.imread(os.path.join("MOT15/train/Venice-2/img1", f))
w.write(im)
w.release()运行PeekingDuck
在初始化PeekingDuck和数据之后,只需简单地从命令行运行流水线:
peekingduck run流水线的输出将保存在output/目录下,如pipeline_config.yml中所指定的,可以将其可视化为视频或.gif图像,如下所示。
检测到的边界框已经叠加在每个被追踪的人物上,并显示了每个相应的追踪ID。累积最大追踪ID的数量也显示在每个帧的左下角。
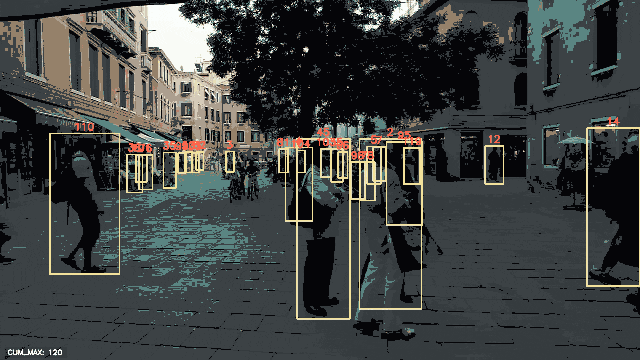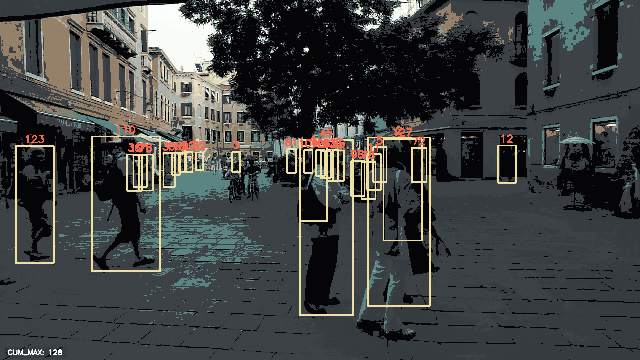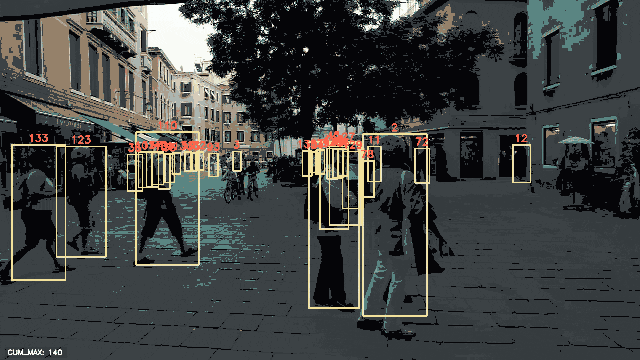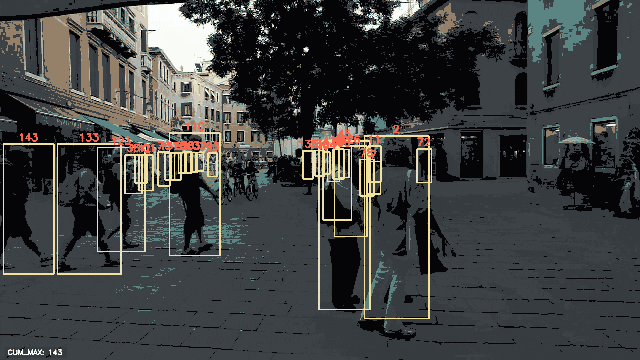
请注意,除了准备数据外,在使用PeekingDuck进行人物追踪时,我们没有编写一行Python代码!
结论
计算机视觉已经取得了长足的进步,我们现在可以访问许多出色的软件包,如PeekingDuck。
PeekingDuck提供了开源、模块化的最先进的计算机视觉模型,只需要很少量的Python代码,任何人都可以相对轻松地进行计算机视觉项目!
参考引用
https://peekingduck.readthedocs.io/en/stable/master.html
https://motchallenge.net/data/MOT15/
https://github.com/Zhongdao/Towards-Realtime-MOT
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓