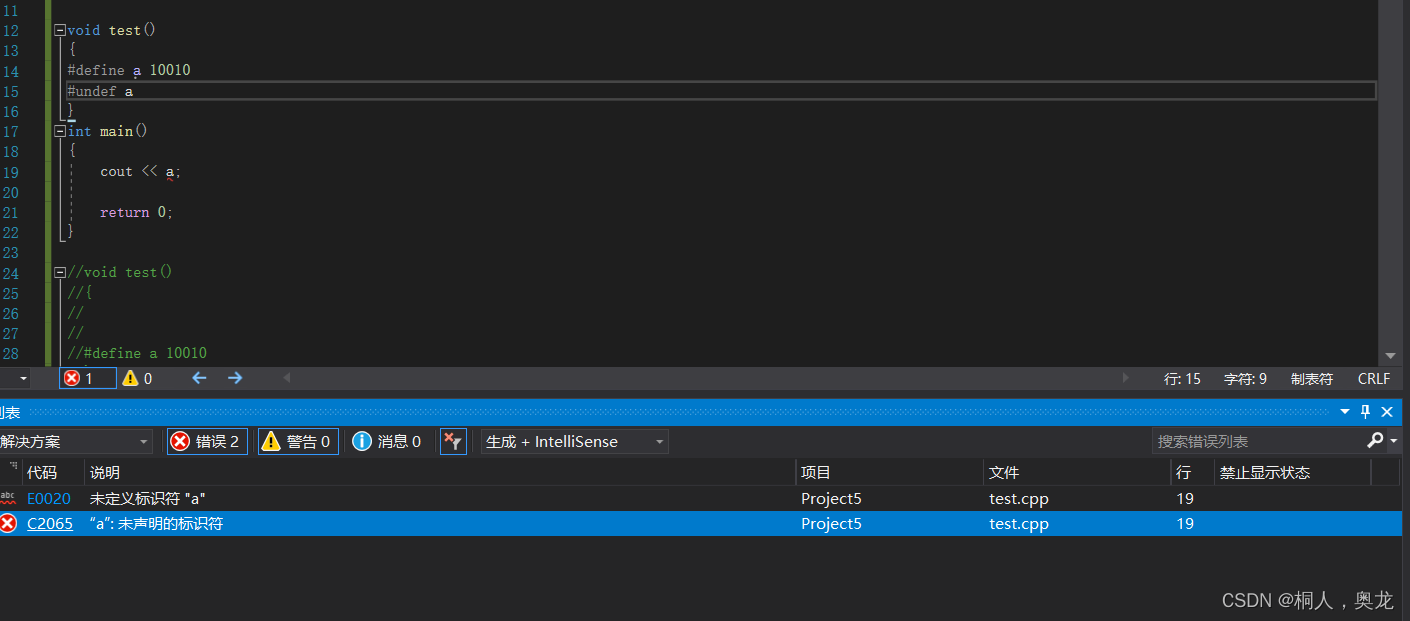
大家好!今天我们来聊一聊全球最受欢迎的视频流媒体平台Netflix的技术栈。作为一个庞大的流媒体服务提供商,Netflix需要强大的数据库支持来实现规模化的视频播放。让我们一起来看看Netflix选择了哪些数据库来支撑他们的业务。
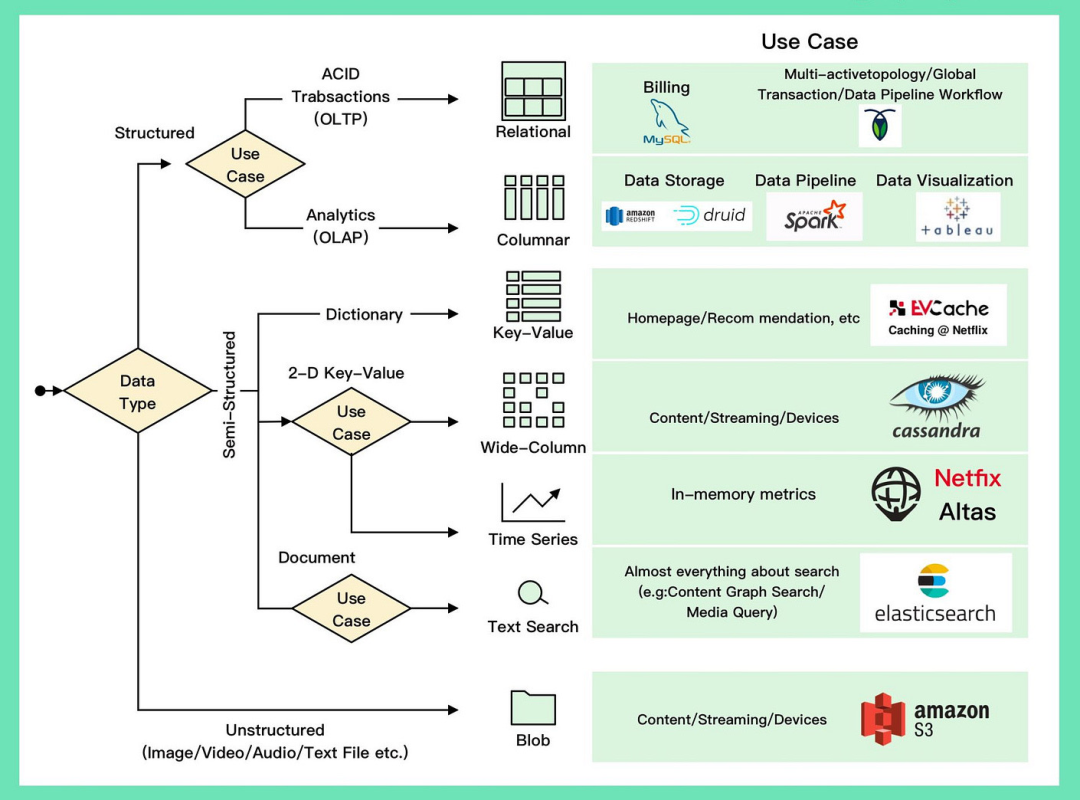
在Netflix的技术栈中,他们选择了不同类型的数据库来满足不同的需求。让我们从关系型数据库开始。
1. 关系型数据库: Netflix使用了MySql作为他们处理账单交易、订阅、税务和收入等方面的选择。MySql是一种可靠的关系型数据库,能够提供稳定的数据存储和管理。
2. 列式数据库: Netflix还使用了列式数据库。他们使用Redshift和Druid来进行结构化数据存储和分析。这些列式数据库在处理大规模数据分析和数据可视化方面非常强大,能够提供高效的查询和计算性能。
3. 键值数据库: Netflix依赖于键值数据库来处理缓存需求。他们使用了一个名为EVCache的系统,它是建立在Memcached之上的键值数据库。EVCache被广泛用于缓存Netflix主页和个性化推荐等各种数据,以提供快速的访问和响应。
4. 宽列数据库: 在宽列数据库方面,Netflix的首选是Cassandra。他们几乎将Cassandra用于所有方面,包括视频/演员信息、用户数据、设备信息和观看历史。Cassandra是一个分布式数据库,具有高度的可扩展性和容错性,非常适合处理大规模的数据存储和查询需求。
5. 时间序列数据库: Netflix还开发了一个名为Atlas的时间序列数据库,用于存储和聚合指标数据。
6. 非结构化数据: 此外,Netflix使用S3作为默认的非结构化数据存储方案,用于存储与图像/视频/指标/日志文件相关的几乎所有内容。
通过选择不同类型的数据库,Netflix构建了一个强大的技术栈,以应对他们在视频流媒体领域的挑战。不同的数据库在处理不同类型的数据和查询时发挥着关键作用,确保了Netflix能够提供高效、可靠的服务。
总的来说,Netflix的技术栈中的数据库选择是经过精心策划和权衡的,旨在为他们的业务提供最佳的性能和可靠性。这个技术栈的建设和优化是Netflix成功的关键之一,使得他们能够成为全球最大的在线视频平台之一。
希望通过今天的分享,你对Netflix的技术栈有了更深入的了解。如果你对其他公司的技术栈也感兴趣,可以随时与我交流。我们可以一起探讨各种有趣的技术话题!