前言
最近在挖客户端漏洞时,遇到了加壳的情况,之前没解决过,遇到了就解决一下。特此记录。
本文详细介绍了frida-dexdump脱壳原理相关知识并且在实战中进行了脱壳操作。
基本知识
1. Frida-dexdump
frida-dexdump通过以下步骤实现DEX文件的解析:
-
使用Frida注入到目标应用程序中,并找到DEX文件的内存地址。
-
将DEX文件的内存数据读取到Frida的JavaScript环境中,并使用Frida提供的Memory API将其转换成JavaScript的ArrayBuffer类型。
-
使用JavaScript实现的DEX文件解析器,解析ArrayBuffer中的DEX数据,并构建出DEX文件的数据结构,包括文件头、字符串池、类型池、方法池、字段池等。
-
将解析后的DEX文件数据结构转换成可读的文本格式,并输出到控制台或文件中。
需要注意的是,Frida-dexdump仅能解析已经加载到内存中的DEX文件,对于已经被加固或混淆的应用程序,DEX文件可能会被加密或修改,导致无法正确解析。
2. Frida提供的Memory API
Frida提供了一组Memory API,用于在Frida的JavaScript环境中操作目标进程的内存数据。这些API包括:
-
Memory.alloc(size):在目标进程中分配指定大小的内存,并返回其内存地址。
-
Memory.copy(dest, src, size):将目标进程中src地址开始的size字节数据复制到dest地址中。
-
Memory.protect(address, size, protection):设置目标进程中指定内存区域的保护属性,包括读、写、执行等。
-
Memory.readByteArray(address, size):从目标进程中指定地址读取指定大小的内存数据,并返回一个Uint8Array类型的数组。
-
Memory.readUtf8String(address):从目标进程中指定地址读取以NULL结尾的UTF8字符串,并返回一个JavaScript字符串。
-
Memory.writeByteArray(address, bytes):向目标进程中指定地址写入一个Uint8Array类型的数组。
-
Memory.writeUtf8String(address, str):向目标进程中指定地址写入一个以NULL结尾的UTF8字符串。
-
Memory.scan(base, size, pattern, callbacks):用于在目标进程的内存中搜索指定的内容。
3. Memory.scan
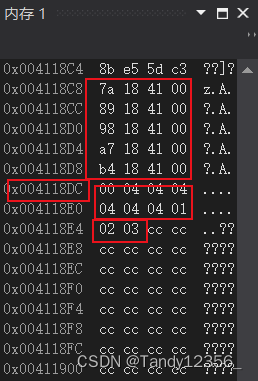
其中上面提到的Memory.scan,也是frida-dexdump的第一步的原理,通过扫描内存中数据,判断是否包含dex头部相关信息,然后通过readByteArray返回具体内容。
例如:
var dexHeader = "6465780a30333500"; // "dex\n035\0"的16进制表示
var dexAddress = null;
Memory.scan(Process.getModuleByName("<appname>.so").base, 0x1000000, dexHeader, {
onMatch: function(address, size) {
dexAddress = address;
},
onComplete: function() {}
});
if (dexAddress != null) {
console.log("DEX address: " + dexAddress);
} else {
console.log("DEX not found");
}从源码中我们也能看出来思路
https://github.com/hluwa/frida-dexdump/blob/d4b7d24a8ce0dada17fb1ce9849a8c1cffcb2cae/frida_dexdump/agent/agent.js#LL492C18-L492C18 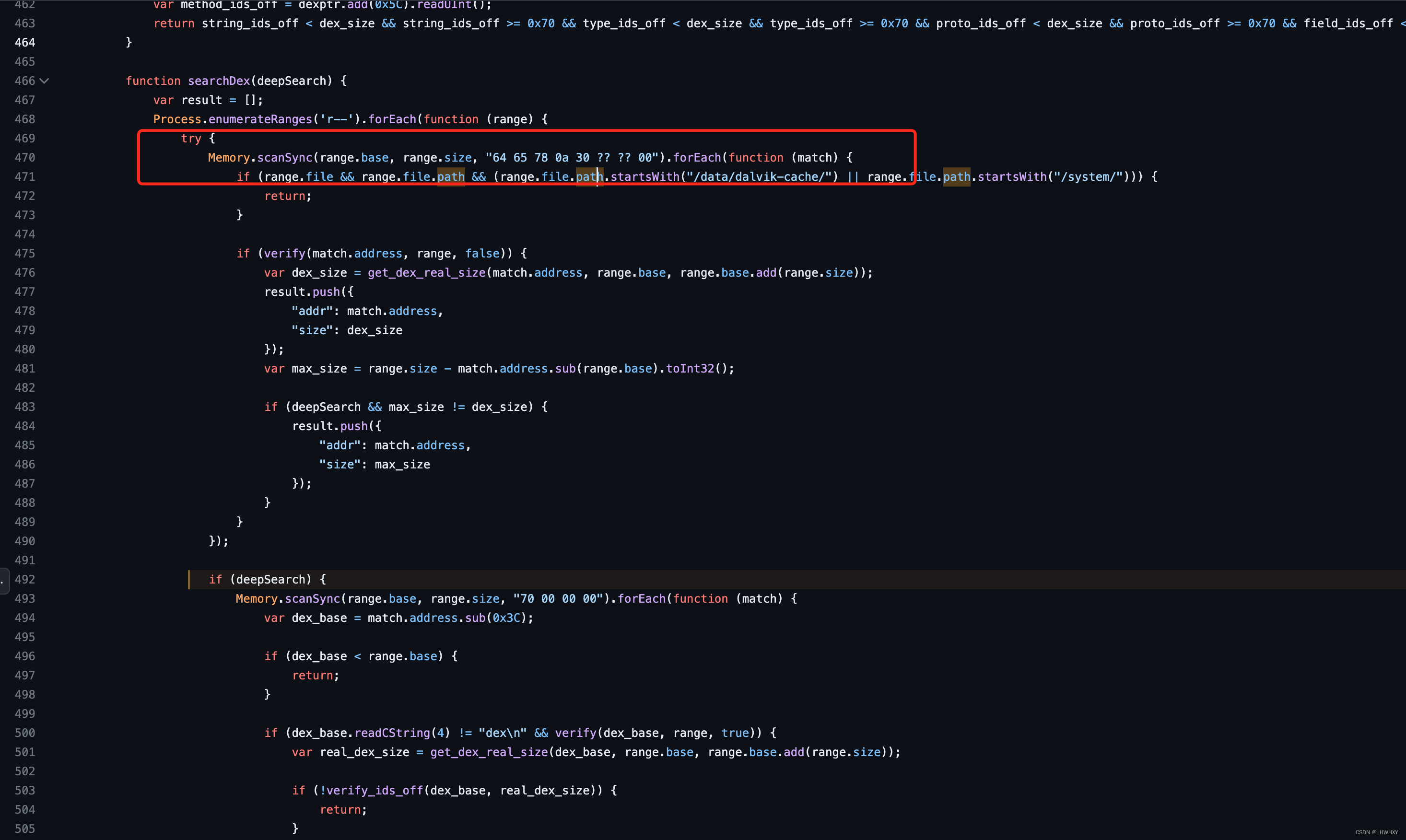
BTW:
emory.scanSync()是Frida的一个API,用于在目标进程的内存中同步搜索指定的内容。与Memory.scan()不同的是,Memory.scanSync()是同步执行的,会阻塞JavaScript线程,直到搜索完成或超时。
4. DEX文件解析器
根据DEX语法接口,将获取的二进制流转化成DEX文件。解析ArrayBuffer中的DEX数据,需要对DEX文件格式有一定的了解。不详述(不会)
要注意的是,DEX文件格式比较复杂,解析过程中需要处理很多细节和异常情况。此外,DEX文件格式可能会因为Android系统版本的不同而有所变化,因此需要根据实际情况进行调整和优化。
复现
第一步:安装frida-dexdump
python3 -m pip install frida-dexdump
Looking in indexes: http://mirrors.aliyun.com/pypi/simple/
Collecting frida-dexdump
Downloading http://mirrors.aliyun.com/pypi/packages/bf/ed/98b807674724b32de58727658985fb6ef83ba6d060557f336065f06b8298/frida_dexdump-2.0.1-py3-none-any.whl (25 kB)第二步:运行命令+运行要脱壳的APP
frida-dexdump -FU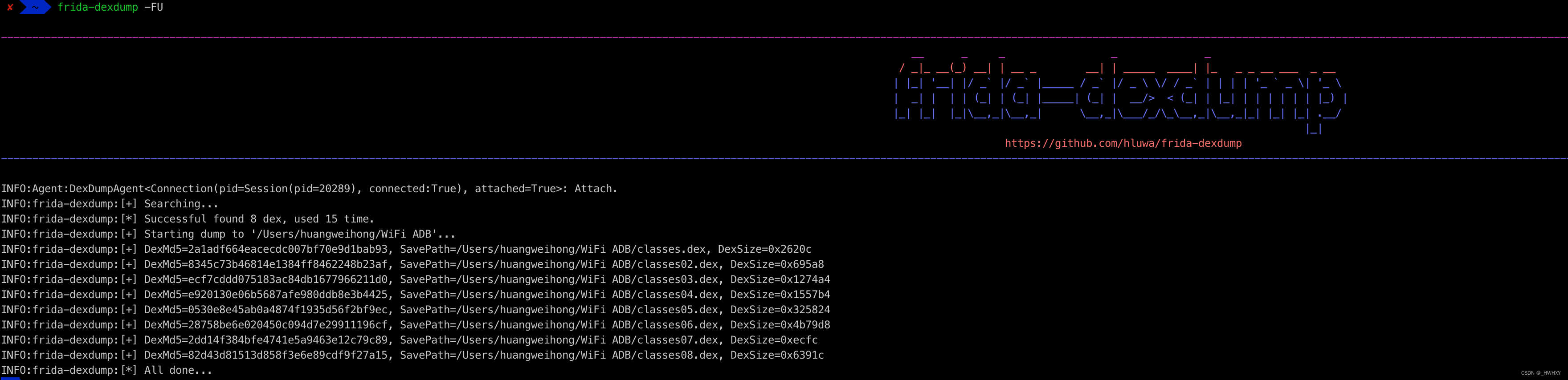
第三步:批量Jadx反编译
import os
g = os.walk("/Users/xxxx/pkg")
for path, dir_list, file_list in g:
for file_name in file_list:
if file_name.endswith(('.dex')):
_path = os.path.join(path, file_name)
commd = "/xxxxxx/jadx-1.4.7/bin/jadx -d pkg_output -j 4 " + _path
print(commd)
os.system(commd)
后话
frida-dexdump操作非常简单,从复现路径就能看出来,但是也存在局限性。
-
不支持所有DEX文件版本:
frida-dexdump只支持部分DEX文件版本,不能支持所有的DEX文件版本。如果解析的DEX文件版本不受支持,将出现解析错误或异常。 -
不支持自定义解析:
frida-dexdump提供的解析方式是固定的,不支持自定义解析。如果需要解析特定的DEX文件结构或数据,需要编写自己的解析工具或脚本。(可以自己魔改agent.js) -
无法处理加固或混淆的DEX文件:
frida-dexdump仅能解析未加固或未混淆的DEX文件,对于加固或混淆的DEX文件,将无法解析或解析出错误的结果。 -
不支持DEX文件的修改和重打包:
frida-dexdump仅能解析DEX文件的结构和数据,不能对DEX文件进行修改或重打包。如果需要修改或重打包DEX文件,需要使用其他工具或编写自己的工具。
针对如上局限性,还需要继续学习,解决问题,并得出结论。