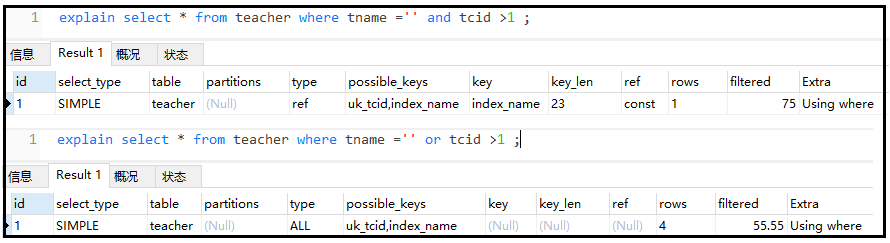
随着人工智能技术的发展,文本到音频(Text-to-Audio,简称 TTA)转换已经成为一个热门的研究领域,旨在通过深度学习模型将任意文本转换为逼真的音频,包括语音、音乐、声效等。近日,一家名为 Suno 的公司在 GitHub 上开源了一个名为 Bark 的 TTA 模型,引起了广泛关注。Bark 是一个基于转换器(Transformer)的端到端模型,可以生成高度逼真的多语言语音以及其他音频 - 包括音乐、背景噪音和简单的音效。该模型还可以产生非语言交流,如大笑、叹息和哭泣。
Bark 可以生成接近人类水平的语音,具有流畅、清晰、富有表情和情感等特点。多语言支持与自动识别:Bark 支持 13 种语言(英语、德语、西班牙语、法语、印地语、意大利语、日语、韩语、波兰语、葡萄牙语、俄语、土耳其语和简体中文),并且可以根据输入文本自动确定使用哪种语言。Bark 可以生成所有类型的音频,并且原则上看不出语音和音乐之间的区别。可以生成各种背景噪音和简单的声效,如风声、雨声、鸟叫等,增加音频的真实感和氛围感。Bark 可以生成一些非语言交流,如大笑、叹息和哭泣等,表达更多的情感和态度。Bark 具有完全克隆声音的能力 —— 包括音调、音调、情感和韵律。
项目地址:https://github.com/suno-ai/bark star/fork=21000/2100

1、安装
Bark 已经过测试并适用于 CPU 和 GPU(pytorch 2.0+、CUDA 11.7 和 CUDA