前言:
多表查询是指在一个SQL语句中使用多个表进行数据查询和操作。多表查询可以对数据表之间的关系进行查询,例如可以通过连接多个表来获取更完整的数据信息。关于单表查询我们也介绍过,已经整理成文章发布:【MySQL数据库 | 第九篇】DQL操作_我是一盘牛肉的博客-CSDN博客

目录
前言:
多表关系:
1.一对多:
2.多对多:
3.一对一:
多表查询:
多表查询的分类:
连接查询:
内连接:
外连接:
自连接:
联合查询:
子查询:
总结:
多表关系:
- 一对多
- 多对多
- 一对一
1.一对多:
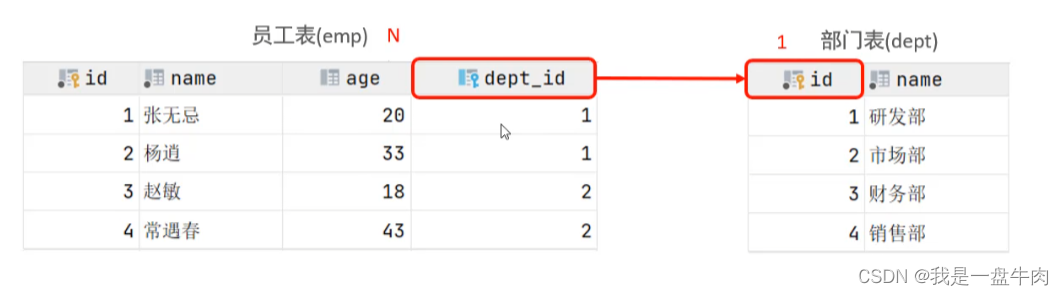
实例:部门与员工之间的关系,一个部门对应多个员工,一个员工对应一个部门。
实现:在多的一方建立外键,指向一的一方的主键。
图解:
2.多对多:
实例:学生与课程之间的关系,一个学生可以选多门课,一们课也可以让多个学生选择。
实现:建立中间第三张表,中间至少包含两个外键,分别关联两方主键
图解: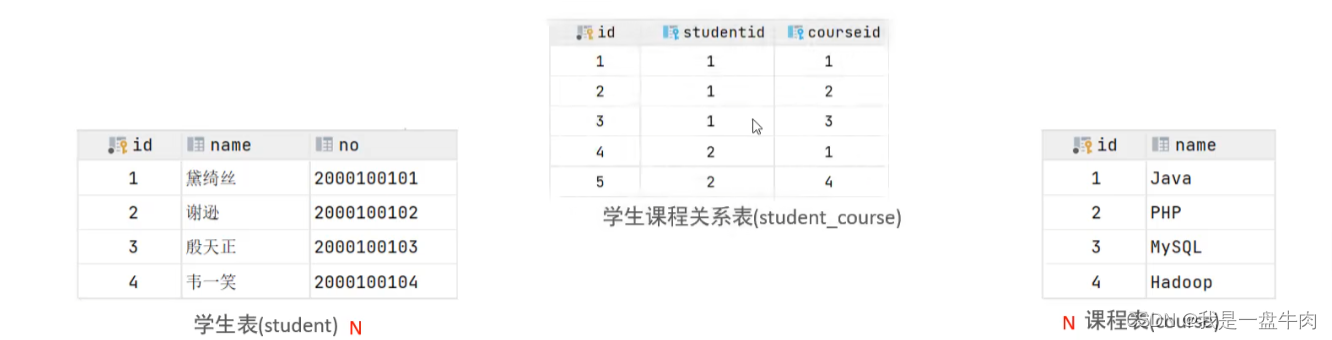 实例:
实例:
以多对多的关系实现学生与课程之间的关系
学生表: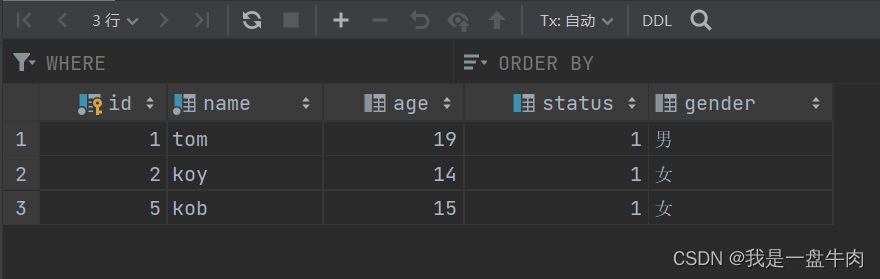
课表: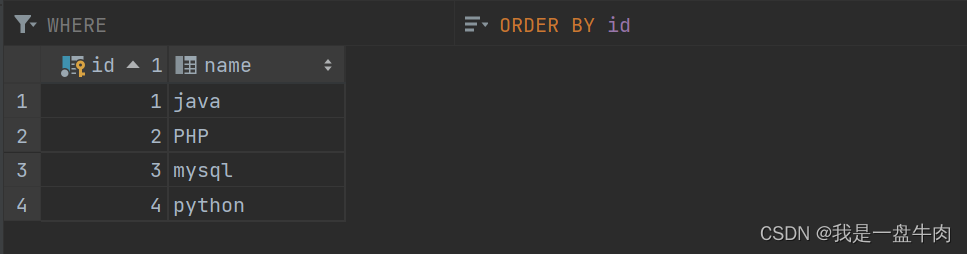
学生课程关系表: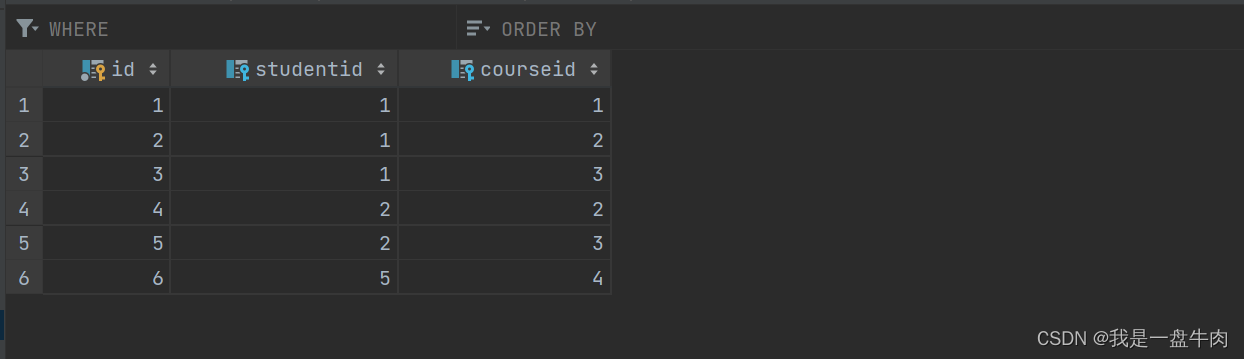
我们把studentid和courseid都设置称为两个外键,分别连接给课表和学生表。这样我们就得到了一个多对多的关系。
我们可以通过datagrip自带的视图工具来更加直观的图: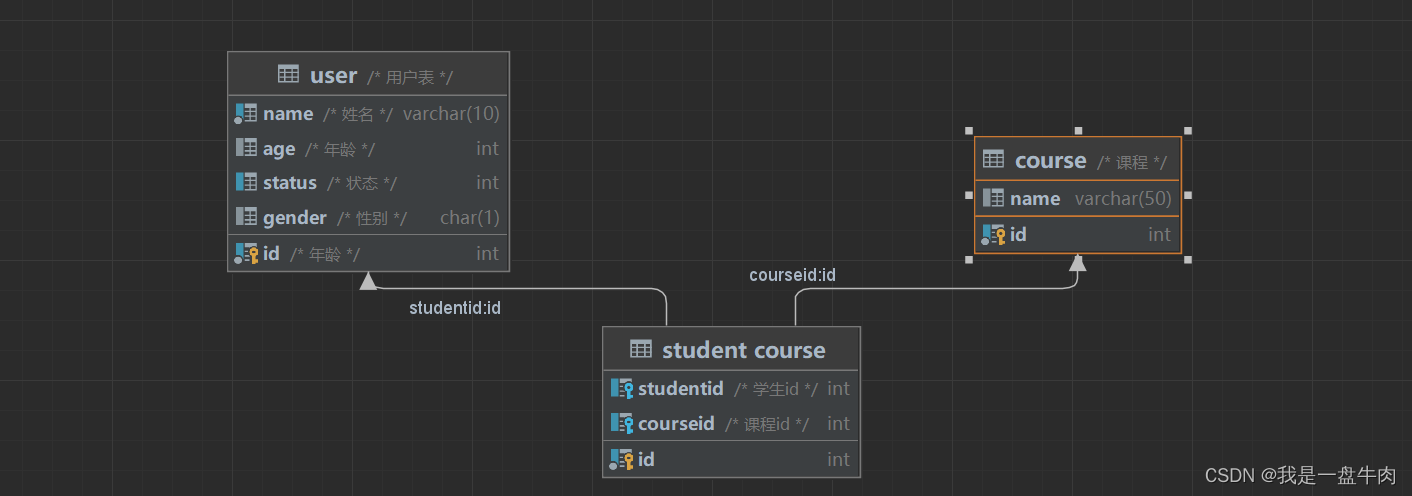
3.一对一:
实例:用户与用户详情之间的关系
关系:一对一的关系多用于单表的拆分。
实现:在任意一方加入外键,关联另一方的主键,并且设置外键是唯一的。

拆分后:

我们可以在datagrip提供的可视化工具中查看用户基本信息表和用户教育信息表的关系: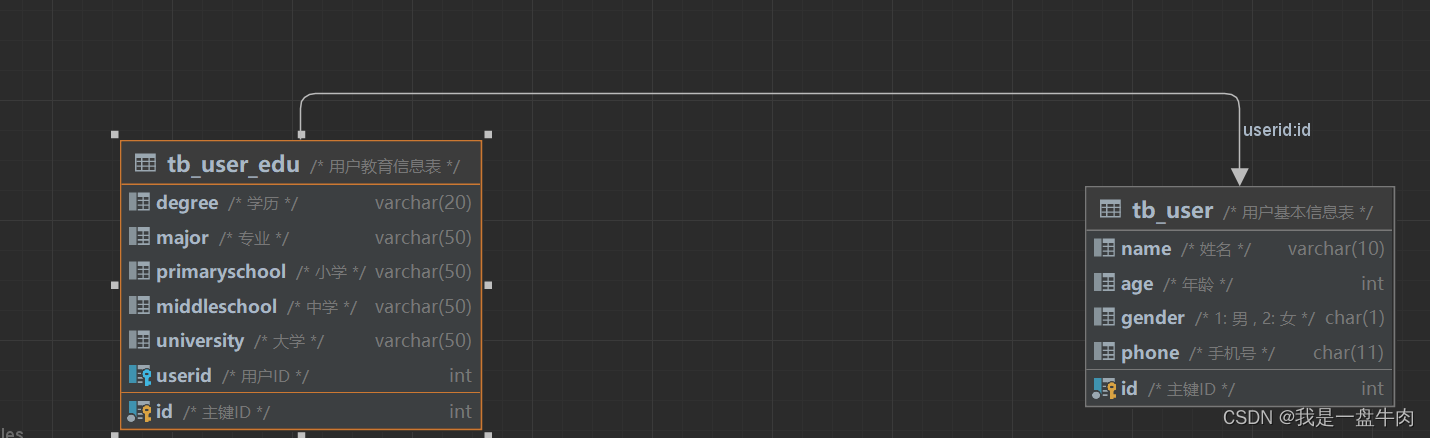
多表查询:
多表查询是指在一个SQL语句中使用多个表进行数据查询和操作。多表查询可以对数据表之间的关系进行查询,例如可以通过连接多个表来获取更完整的数据信息。
为了方便演示我们先插入两张表:dept表和emp表
dept表: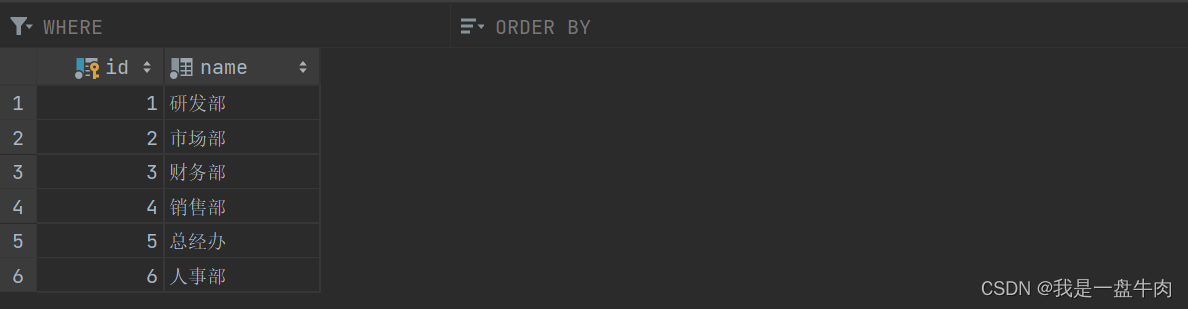
emp表: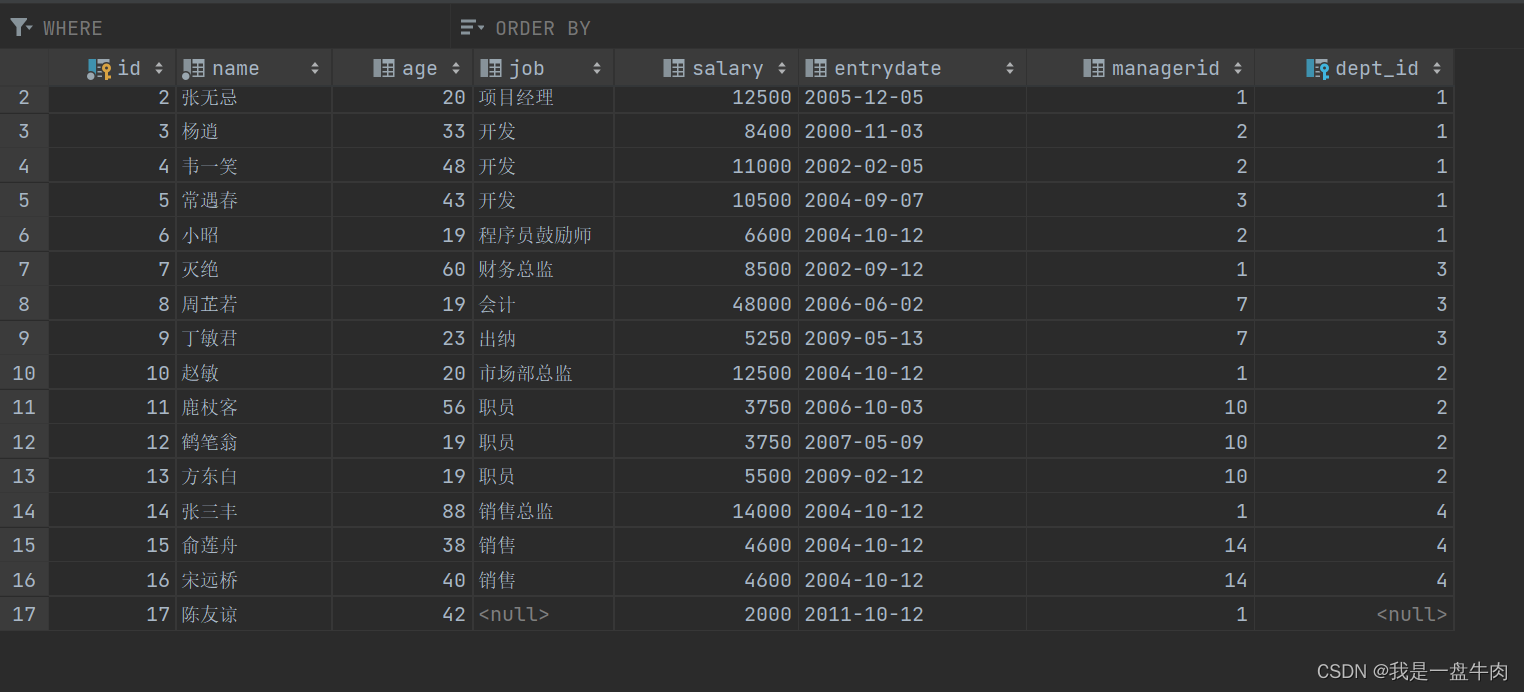
如果只是直接的两张表一起查询:
select *from emp ,dept; 查询结果: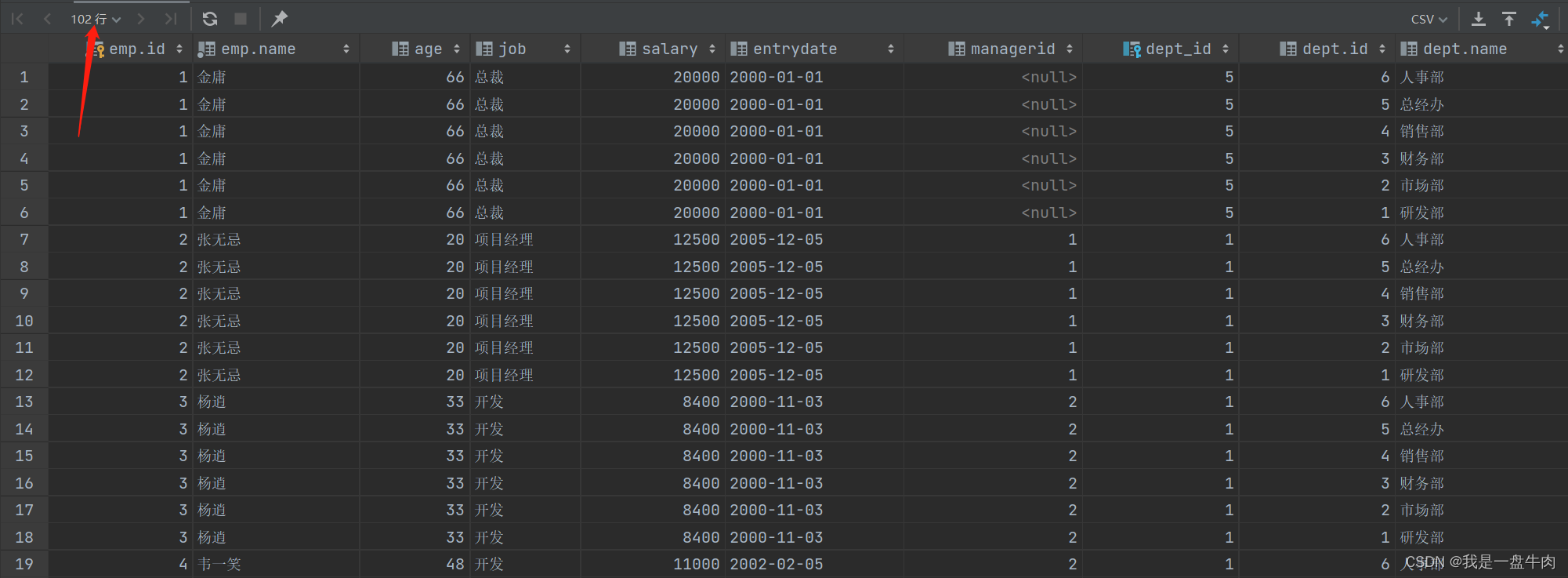
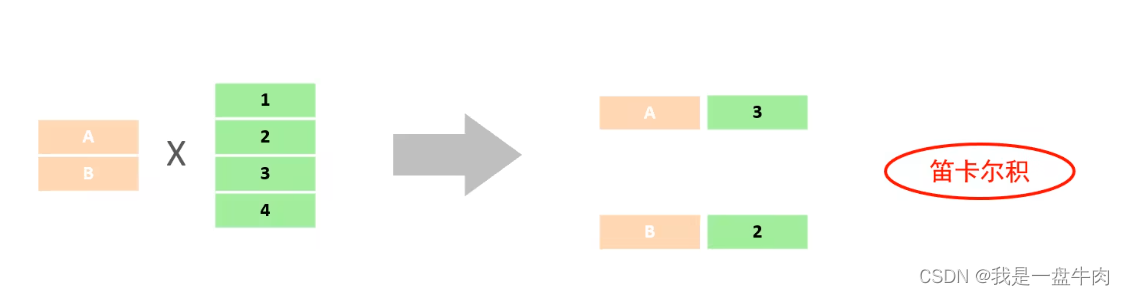
我们发现这样查询太浪费时间了,因为这是把每一个人对这个六个职位都进行一次匹配,这样确实不利于我们直接进行观察,这种(A中的每一个元素都要和B中的元素组合)现象叫做笛卡尔积现象。
而我们在实际多表查询的时候要消除这种多余的笛卡尔积现象,让数据以最直观,最清晰的方式呈现出来。
正确的思路应该是我们加上一个判断条件:只有empt表中人员职位id等于dept职位id的时候,再进行输出。
代码:
select * from emp,dept where dept_id=dept.id; 结果: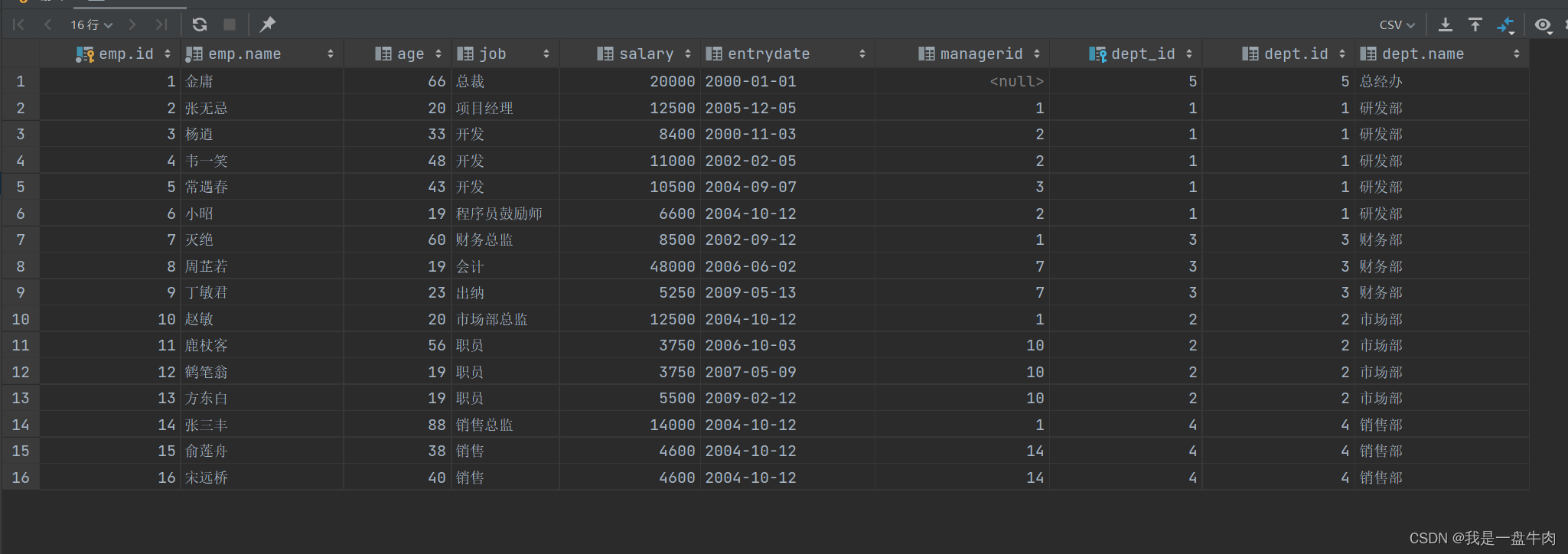
此时我们就成功的消除了多余的笛卡尔积。
多表查询的分类:
连接查询:
内连接:
相当于查询A,B交集部分数据。
外连接:
左外连接:查询左表的所有数据,以及两张表的交集数据
右外连接:查询右表的所有数据,以及两张表的交集数据
自连接:
当前表与自身的连接查询,自连接必须使用表别名
联合查询:
把多次查询的结果合并起来,形成一个新的查询结果
子查询:
一个SQL语句中嵌套另一个SQL语句,嵌套的SQL语句被称作子查询。
内连接:
1.隐式内连接:
SELECT 字段列表 FROM 表1,表2,WHERE 条件;2.显式内连接:
SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 连接条件;
案例:
1.查询每一个员工的姓名和关联部门的名称(隐式内连接)
select emp.name,dept.name from emp,dept where emp.dept_id=dept.id;结果: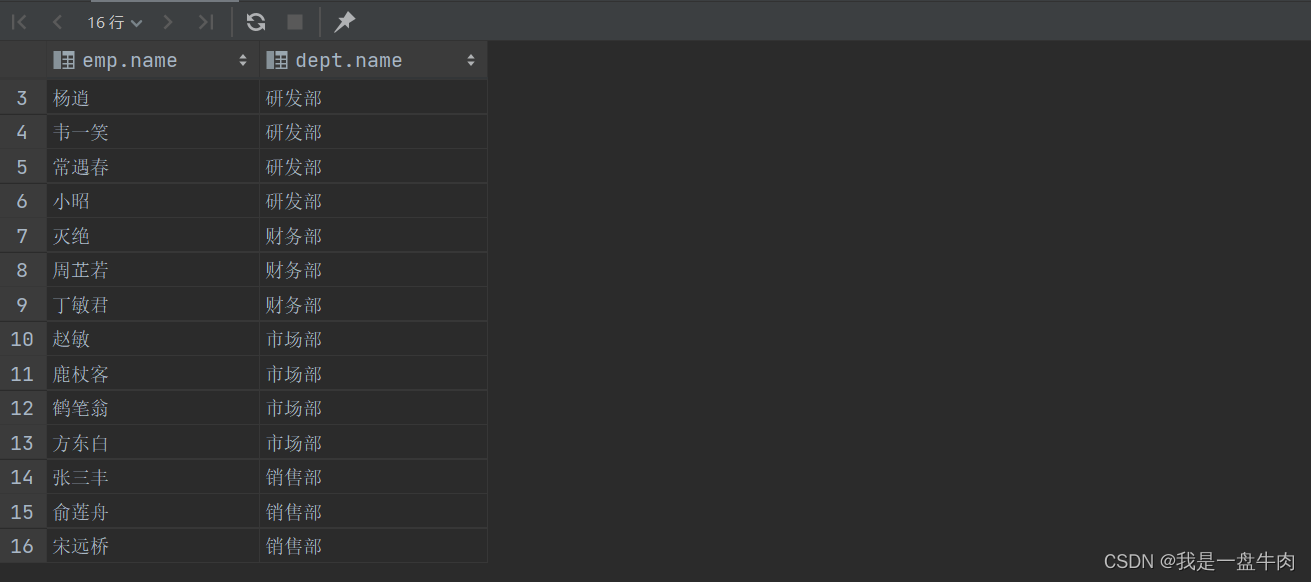
2.查询每一个员工的姓名和关联部门的名称(显式内连接)
select emp.name,dept.name from emp join dept on emp.dept_id = dept.id;结果: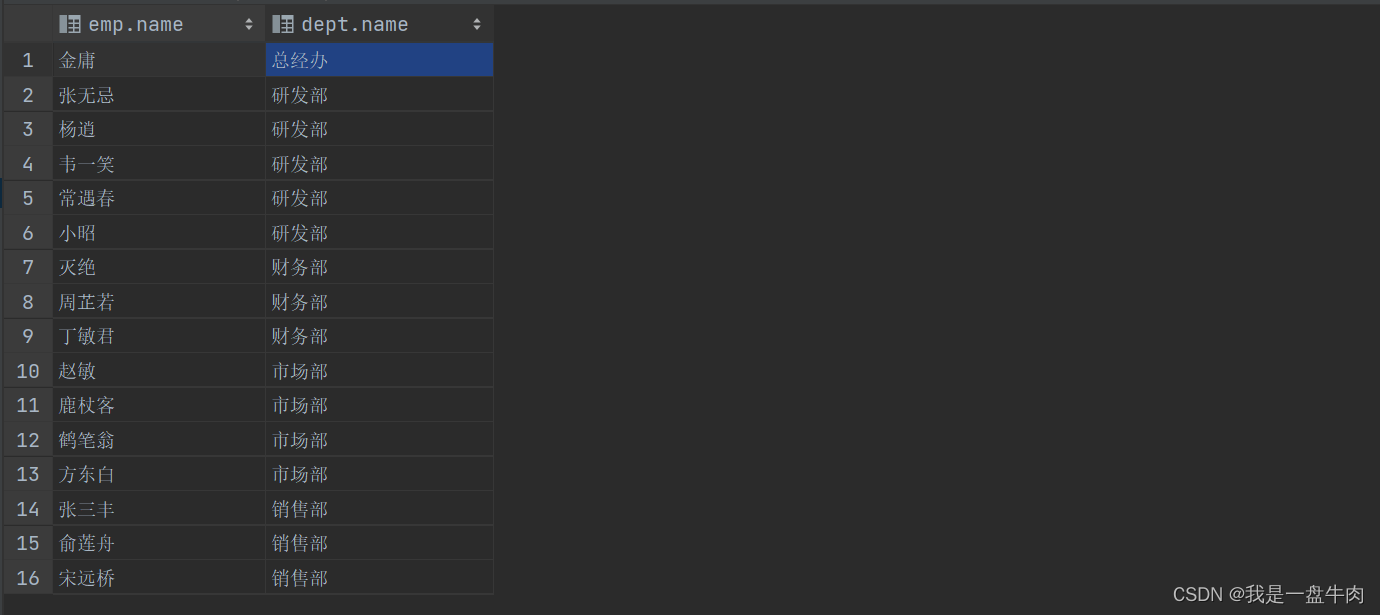
外连接:
左外连接:
select 字段名 from 表1 left [outer] join 表2 on 条件;右外连接:
select 字段名 from 表1 right [outer] join 表2 on 条件;我们认为表1是左表,表2是右表:
图解: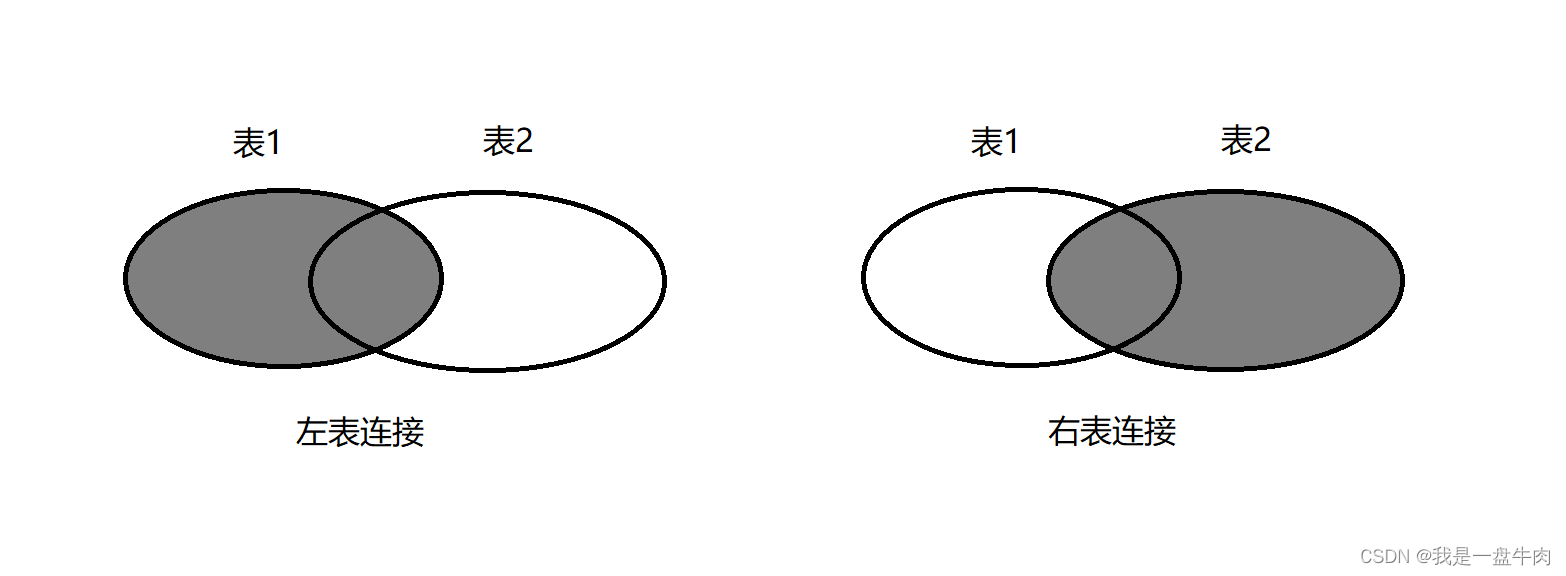
案例:
1.查询emp中的所有信息以及其人员对应的部门信息(左外连接)
select emp.* ,d.name from emp left join dept d on d.id = emp.dept_id;结果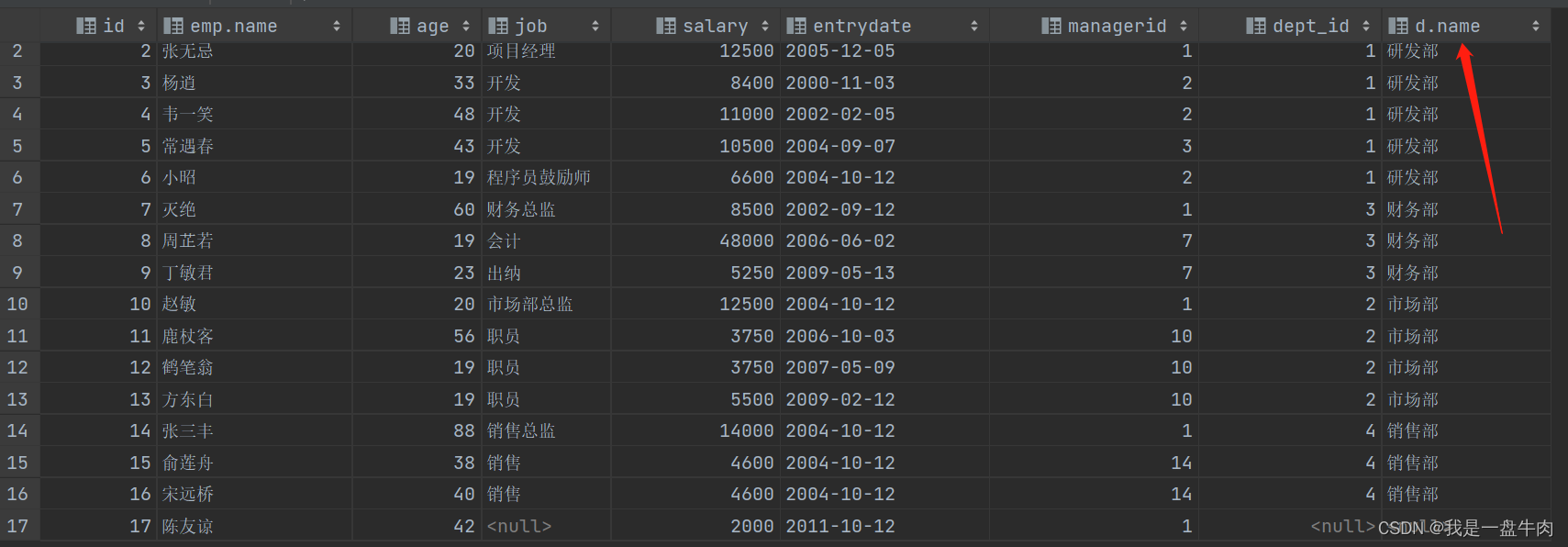
2.查询dept表的所有数据和对应的员工名称(右外连接)
select dept.*,e.name from dept right join emp e on dept.id = e.dept_id;结果: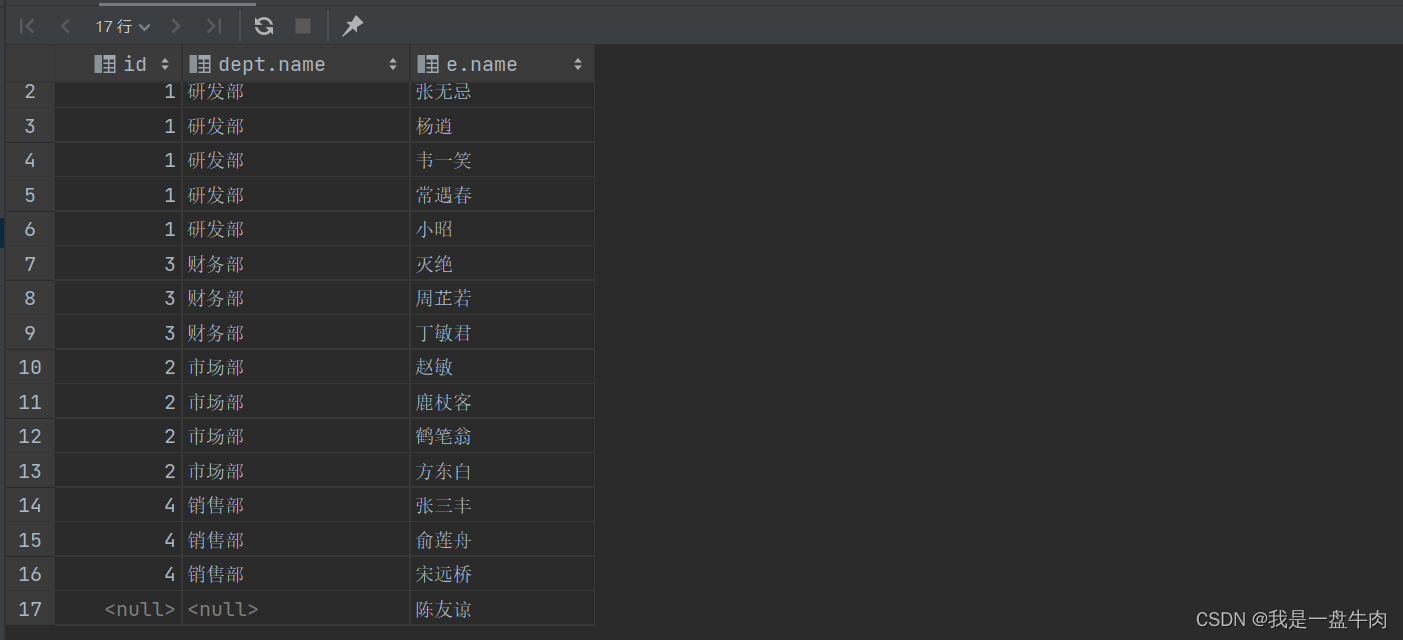
自连接:
select 字段列表 from 表A 别名A join 表A 别名B on 条件;自连接查询可以是内连接查询,也可以是外连接查询。
案例
1.查询员工以及其所属领导的名字(内连接):
select a.name ,b.name from emp a,emp b where a.managerid=b.id; 结果:(我们可以看出来此处没有老板的金庸并没有显示出来,因为他并不属于两张表的交集)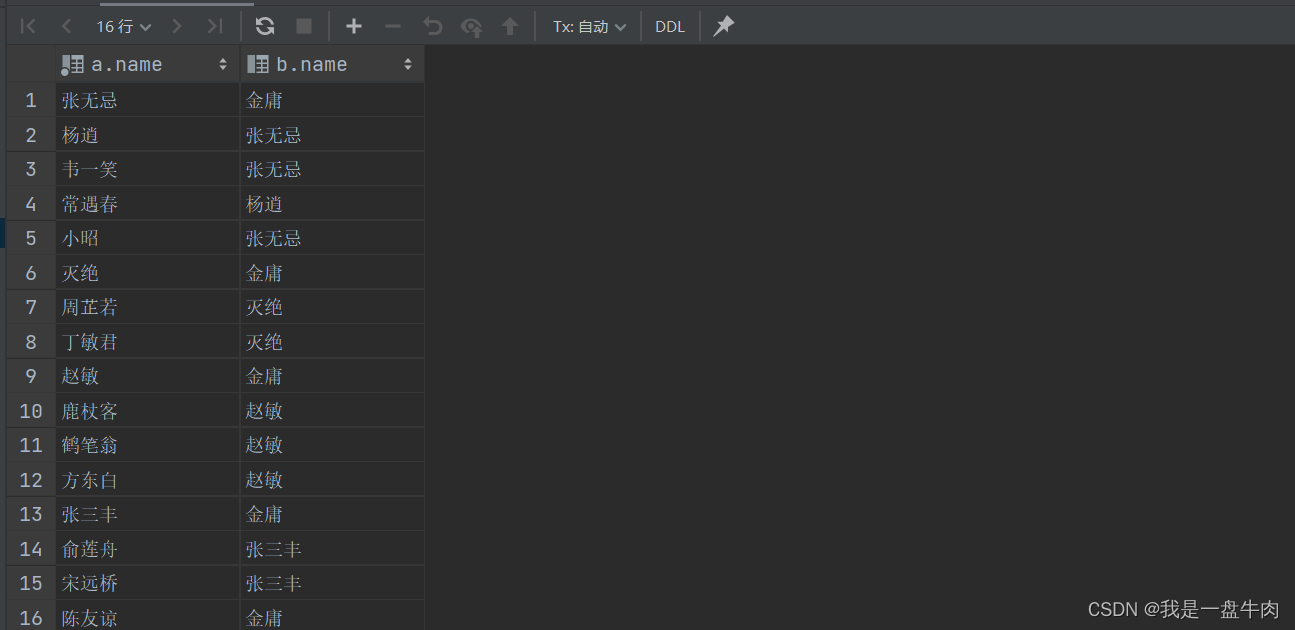
2.查询员工以及其所属领导的名字(外连接)即员工没有领导也要包含进来:
select a.name,d.name from emp a left join emp d on a.managerid=d.id;结果:(此时没有老板的金庸也被打印出来)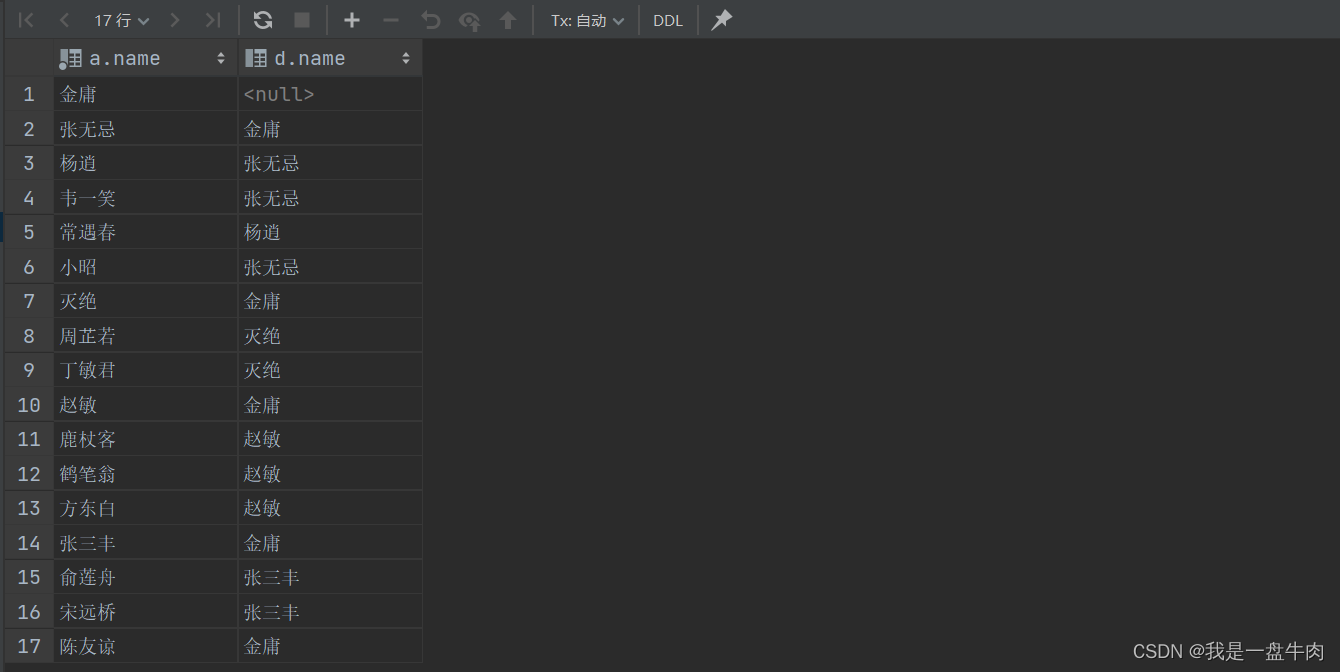
联合查询:
SELECT 字段列表 FROM 表A....
UNION [ALL]
SELECT 字段列表 FROM 表B....ALL关键字决定是否去重,如果不想去重就不写ALL。
案例:
1.将薪资大于5000的员工和年龄大于50岁的员工全部查询出来
select name from emp where emp.salary>5000
union
select name from emp where emp.age>50;结果: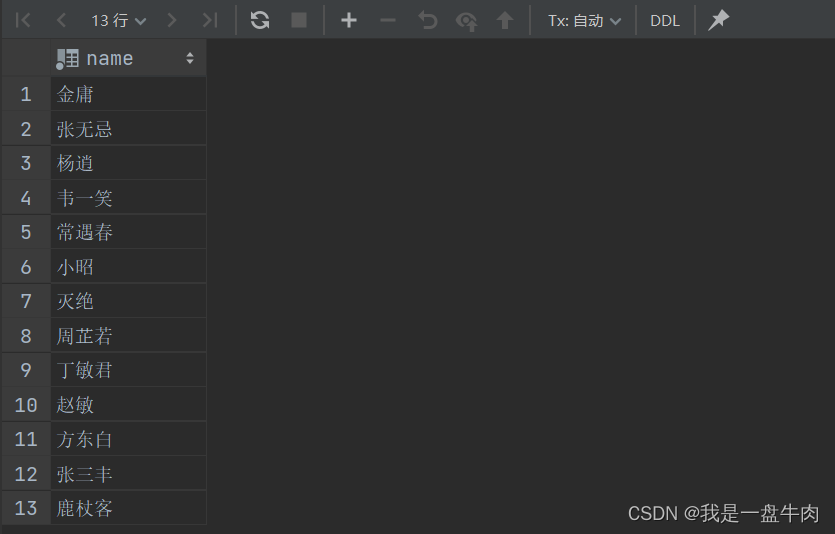
注意点:对于联合查询来讲,合并的两个查询字段必须类型一致,列数一致。
子查询:
SELECT *FROM T1 WHERE COLUMN1 =(SELECT COLUMN1 FROM T2);根据子查询的种类不同,我们分为
- 标量子查询(子查询结果为单个值)
- 列子查询(子查询结果是一列)
- 行子查询(子查询结果是一行)
- 表子查询(子查询的结果为多行多列)
红箭头所指的就是子查询

标量子查询:
子查询返回的结果是单个值(字符串,日期,数字等)
常用操作符:= <> > >= < <=
以下这些案例中子查询返回的都是一个单个值:id,entrydate,因此叫做标量子查询。
案例:
1.查询‘销售部’的所有员工信息(先查询销售部的编号,再查询谁的岗位编号符合要求)
select * from emp where dept_id=(select id from dept where name ='销售部');结果:
2.查询在'方东白'入职之后的员工信息
select * from emp where entrydate>(select entrydate from emp where name='方东白');结果:
列子查询:
子查询返回的结果是一列(可以是多行),这种子查询叫做列子查询
常用操作符:IN , NOT IN , ANY , SOME , ALL

案例:
1.查询 销售部 和 市场部 的所有员工信息
select * from emp where dept_id in (select id from dept where name ='销售部'or name ='市场部');结果:
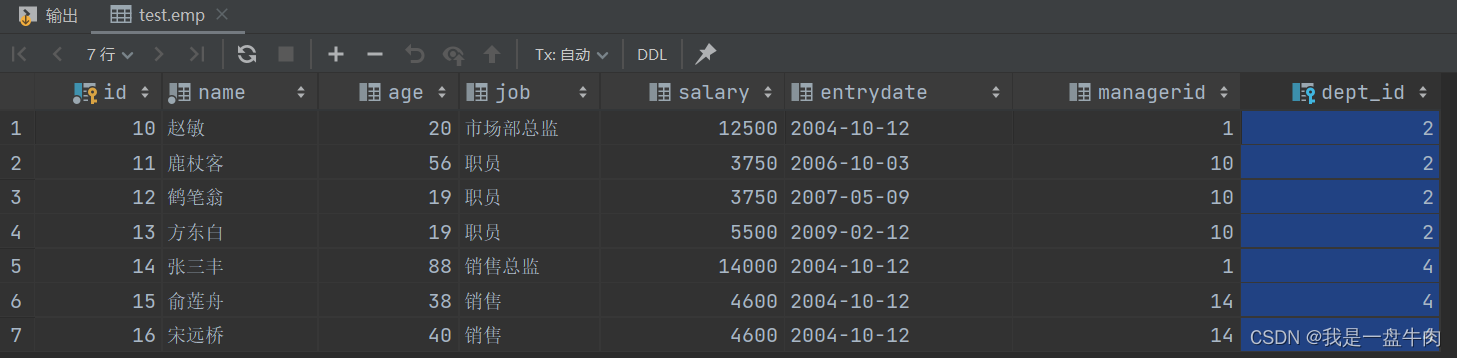
2.查询比财务部所有人工资都高的人员信息
select * from emp where salary>all (select salary from emp where dept_id = (select id from dept where name ='财务部'));结果: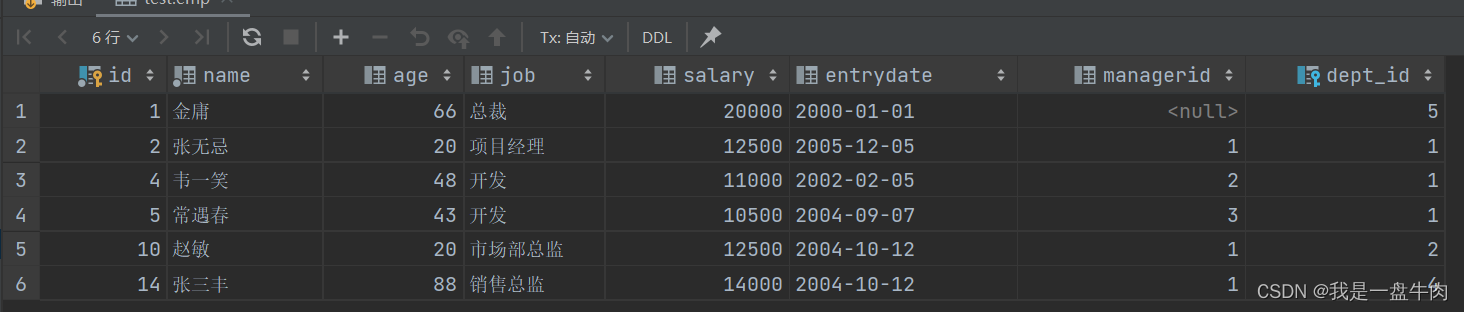
行子查询:
子查询返回的结果是一行(可以是多列),这种子查询就是行子查询
常用的操作符:= ,<> ,IN,NOT IN
案例:
1.查询与张无忌薪资和领导相同的员工信息
select * from emp where (salary,managerid)=(select salary,managerid from emp where name ='张无忌') 结果:
表子查询:
子查询的返回结果是多行多列,这种子查询结果就叫做表子查询
最常用的操作符:IN
案例:
1.查询与鹿杖客,宋远桥职位和薪资相同的员工信息:
select * from emp where (job,salary) in (select job,salary from emp where name='鹿杖客' or name ='宋远桥');结果:
总结:
多表查询是指在一个SQL语句中同时操作多个表格,并通过对不同表格之间的关联进行查询,来获得更丰富和更准确的数据。多表查询的常用方式有内连接、左连接、右连接和全连接。多表查询在实际操作中应用广泛,能够满足复杂的数据查询和处理需求,同时也能够提高数据库的查询效率和性能。
今天的内容到这里就结束了,感谢大家的阅读。
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力!



![【群智能算法改进】一种改进的算术优化算法 改进算术优化算法 改进AOA[2]【Matlab代码#38】](https://img-blog.csdnimg.cn/ea4090755e2b40f9a8e2512d59498307.png#pic_center)