Java 8 引入了 Stream API,提供了一种新的处理集合和数组的方式。Stream API 可以让我们更加便捷、灵活地处理数据,尤其是大规模数据。在这里,我将详细介绍 Java 8 中的 Stream API。
什么是 Stream
Stream 是 Java 8 中引入的一个新的概念,它代表着一种元素序列的表现形式。具体来说,它是对集合和数组等数据源的抽象,类似于 I/O 流,但它不会改变数据源本身。Stream 的出现使得我们可以更方便、更高效地对数据进行操作,它可以帮助我们轻松地实现过滤、映射、排序、统计等操作,同时还能够支持并行处理,大大提高了程序的效率。
Stream 操作类型
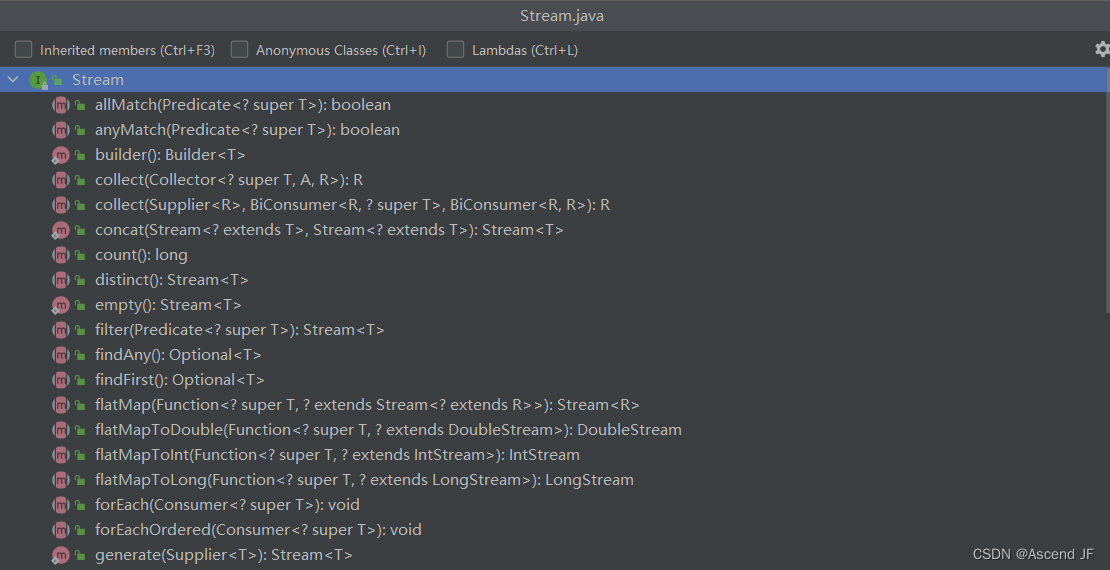
Stream API 的操作可以分为以下几类:
- 创建流的操作:创建流指的是将一个集合或其他数据源转换为 Stream 流对象的过程。通常情况下,我们可以使用 Stream 类的静态方法来创建流对象,如 Stream.of()、Collections.stream() 等。这些方法将返回一个 Stream 流对象,该对象可用于对数据进行各种操作。下面是一些常用的创建流的方法。
of(T... values):创建一个由指定元素组成的流。 empty():创建一个空的流。 generate(Supplier<T> s):创建一个无限流,每次调用 get() 方法都会生成新的数据。 iterate(T seed, UnaryOperator<T> f):创建一个无限流,在每次迭代时都会应用指定的函数。 concat(Stream<? extends T> a, Stream<? extends T> b):创建一个包含两个流的顺序流,先是流 a,再是流 b。 builder():创建一个用于构建链式操作的 Builder 对象。 ofNullable(T t):创建一个包含零个或一个元素的流,元素为指定对象(可以为 null)。 range(int startInclusive, int endExclusive):创建一个包含从 startInclusive 开始(含)到 endExclusive 结束(不含)的整数序列流。 rangeClosed(int startInclusive, int endInclusive):创建一个包含从 startInclusive 开始(含)到 endInclusive 结束(含)的整数序列流。- 中间操作(Intermediate Operations):中间操作是指转换 Stream 类型的操作,可以将一个 Stream 转换成另一个 Stream。下面是一些常用的中间操作方法。这些方法都是惰性求值的,只会创建一个新的 Stream 对象,而不是从数据源中读取数据。
filter(Predicate<T> predicate):根据指定的条件过滤流中的元素。 map(Function<T, R> mapper):将流中的元素映射为另外一种类型。 flatMap(Function<T, Stream<R>> mapper):将流中的每个元素都转换成一个新的流,然后把所有的新流合并为一个大流。 distinct():去除流中的重复元素。 sorted():按自然顺序排序流中的元素。 sorted(Comparator<T> comparator):按指定的比较器来排序流中的元素。 peek(Consumer<T> action):对每个元素执行指定的操作,并且返回一个新的流。 limit(long maxSize):从流中截取指定数量的元素。 skip(long n):跳过前面的n个元素,返回剩余的元素。- 结束操作(Terminal Operations):结束操作是指结束 Stream 该如何处理的操作,并且会触发 Stream 的执行。下面是一些常用的结束操作方法。结束操作会对数据源进行遍历,因此是及早求值的。
forEach(Consumer<T> action):对流中的每个元素执行指定的操作。 toArray():将流中的元素转换成数组。 reduce(T identity, BinaryOperator<T> accumulator):使用指定的累加器对流中的元素进行聚合。 collect(Collector<T,A,R> collector):将流中的元素收集到一个容器中。 min(Comparator<T> comparator):返回流中的最小元素。 max(Comparator<T> comparator):返回流中的最大元素。 count():返回流中元素的数量。 anyMatch(Predicate<T> predicate):判断流中是否有任意一个元素匹配指定的条件。 allMatch(Predicate<T> predicate):判断流中是否所有元素都匹配指定的条件。 noneMatch(Predicate<T> predicate):判断流中是否没有任何一个元素匹配指定的条件。 findFirst():返回流中的第一个元素。 findAny():返回流中的任意一个元素。其他方法:Java 8 Stream API 还提供了一些其他的方法,可以帮助我们更好地处理流中的数据。其中,parallel() 和 sequential() 可以用来选择并行处理或者串行处理,isParallel() 可以帮助我们判断当前流是否为并行流。而 unordered() 可以告诉流不必保证元素的顺序。onClose() 方法则可以在流关闭时执行一个指定的处理程序。最后,使用 spliterator() 方法可以创建一个 Spliterator 对象,用来遍历流中的元素。
parallel():将流转为并行流(多线程处理),可以提高处理效率。 sequential():将流转为串行流(单线程处理)。 unordered():告诉流不必保证元素的顺序。 isParallel():判断流是否是并行流。 onClose(Runnable closeHandler):在流关闭时执行指定的处理程序。 spliterator():创建一个 Spliterator 来遍历流的元素。
Stream中间操作方法详细介绍
filter(Predicate<? super T> predicate)
filter(Predicate<? super T> predicate)方法是用来过滤流中的元素,返回一个新的流,其中仅包含满足指定条件的元素。下面是一个使用示例:
import java.util.Arrays; import java.util.List; import java.util.stream.Collectors; public class StreamFilterExample { public static void main(String[] args) { List<Integer> list = Arrays.asList(1, 2, 3, 4, 5); List<Integer> filteredList = list.stream() .filter(n -> n % 2 == 0) .collect(Collectors.toList()); System.out.println(filteredList); // 输出 [2, 4] } }以上代码展示了如何使用
filter(Predicate<? super T> predicate)方法来过滤流中的元素。首先创建了一个整型列表list,然后通过stream()方法将其转换为一个流。接着,使用filter(n -> n % 2 == 0)方法得到一个新的流,其中仅包含偶数元素,并通过collect(Collectors.toList())方法将其中的元素收集到一个列表中,得到一个只包含偶数的整型列表filteredList,最终将其打印出来。需要注意的是,
filter(Predicate<? super T> predicate)方法使用了一个Predicate接口类型的参数,即一个函数式接口,用于筛选流中符合指定条件的元素。在上述代码中,使用的是一个 lambda 表达式n -> n % 2 == 0,表示筛选偶数元素。
map(Function<? super T,? extends R> mapper)
map()方法是Stream类中的一个中间操作方法,它接收一个Function类型的参数mapper,用于将流中每个元素按照指定规则映射成另一个元素并生成一个新的流。具体来说,该方法会对流中的每个元素应用mapper函数,并将函数返回值构成新流。例如,假设有一个由字符串构成的流,现在需要获取每个字符串的长度,并生成一个新的整数流,可以使用
map()方法实现:List<String> strList = Arrays.asList("Java", "Python", "C#", "JavaScript"); strList.stream() .map(str -> str.length()) .forEach(System.out::println);以上代码中,首先从字符串列表中创建一个
Stream,然后通过map()方法将每个字符串转换成其长度,并生成一个新的整数流。最后通过forEach()方法输出每个元素到控制台。需要注意的是,由于
map()方法是一个中间操作方法,因此对流的操作不会立即执行,而是在遇到终止操作方法时才会执行。同时,由于map()方法只是映射了流中的每个元素,并未改变原始流,因此不会影响流中后续元素的处理。另外,需要注意
map()方法的映射函数不能返回null,否则会抛出NullPointerException异常。如果需要在映射过程中排除某些元素,可以使用filter()方法。
flatMap(Function<? super T,? extends Stream<? extends R>> mapper)
flatMap()方法是Stream类中的一个中间操作方法,它将一个元素映射为一个Stream,然后把所有Stream合并成一个Stream。具体来说,flatMap()方法接收一个函数作为参数,该函数用于将一个元素转换为另一个Stream。flatMap()方法会遍历每个元素,并将该元素传递给该函数进行转换,最终将所有Stream合并成一个新的Stream。例如,假设有一个包含多个字符串的列表,现在需要将每个字符串转换成一个字符数组,并将所有字符数组合并成一个字符串列表,可以使用
flatMap()方法实现:List<String> strList = Arrays.asList("hello", "world"); List<String> charList = strList.stream() .flatMap(str -> Arrays.stream(str.split(""))) .collect(Collectors.toList()); System.out.println(charList); // 输出结果为 ["h", "e", "l", "l", "o", "w", "o", "r", "l", "d"]以上代码中,首先从字符串列表中创建一个
Stream,然后对每个字符串执行Arrays.stream(str.split(""))方法,将字符串转换为字符数组并返回一个Stream,最后通过flatMap()将所有Stream合并成一个新的Stream,再通过collect()方法将Stream转换为List。需要注意的是,如果函数返回的是一个数组或集合等对象,那么
flatMap()方法会直接将这个对象添加到结果Stream中,而不是将它的元素逐个添加到结果Stream中。如果需要将这个对象中的元素逐个添加到结果Stream中,可以使用flatMap()方法配合Arrays.stream()或Collection.stream()方法实现。例如,假设有一个包含多个单词的列表,现在需要将其中长度大于 3 的单词的字符转换成小写字母,可以使用
flatMap()方法实现:List<String> words = Arrays.asList("Java", "Stream", "API"); List<String> letters = words.stream() .filter(word -> word.length() > 3) .flatMap(word -> Arrays.stream(word.toLowerCase().split(""))) .collect(Collectors.toList()); System.out.println(letters); // 输出结果为 ["j", "a", "v", "a", "s", "t", "r", "e", "a", "m"]以上代码中,首先从单词列表中创建一个
Stream,然后过滤出长度大于 3 的单词并对每个单词执行Arrays.stream(word.toLowerCase().split(""))方法,将单词转换为小写字母字符数组并返回一个Stream,最后通过flatMap()将所有Stream合并成一个新的Stream,再通过collect()方法将Stream转换为List。注意,由于toLowerCase()方法返回的是一个字符串对象,因此需要先调用split()方法将字符串拆分成字符数组。
flatMapToDouble(Function<? super T,? extends DoubleStream> mapper)
flatMapToDouble()方法是Stream类中的一个中间操作方法,它将一个元素映射为一个DoubleStream,并将所有DoubleStream合并成一个新的DoubleStream。具体来说,flatMapToDouble()方法接收一个函数作为参数,该函数用于将一个元素转换为另一个DoubleStream。flatMapToDouble()方法会遍历每个元素,并将该元素传递给该函数进行转换,最终将所有DoubleStream合并成一个新的DoubleStream。例如,假设有一个包含多个字符串的列表,现在需要将每个字符串转换成一个浮点数数组,并将所有浮点数求和,可以使用
flatMapToDouble()方法实现:List<String> strList = Arrays.asList("1.0", "2.0", "3.0"); double sum = strList.stream() .flatMapToDouble(str -> DoubleStream.of(Double.parseDouble(str))) .sum(); System.out.println(sum); // 输出结果为 6.0以上代码中,首先从字符串列表中创建一个
Stream,然后对每个字符串执行DoubleStream.of(Double.parseDouble(str))方法,将字符串转换为浮点数并返回一个DoubleStream,最后通过flatMapToDouble()将所有DoubleStream合并成一个新的DoubleStream,并调用sum()方法求和。需要注意的是,如果函数返回的是一个数组或集合等对象,那么
flatMapToDouble()方法会直接将这个对象添加到结果DoubleStream中,而不是将它的元素逐个添加到结果DoubleStream中。如果需要将这个对象中的元素逐个添加到结果DoubleStream中,可以使用flatMapToDouble()方法配合Arrays.stream()或Collection.stream()方法实现。例如,假设有一个包含多个单词的列表,现在需要将其中长度大于 3 的单词的字符转换成小写字母的 ASCII 码,并将所有 ASCII 码求平均值,可以使用
flatMapToDouble()方法实现:List<String> words = Arrays.asList("Java", "Stream", "API"); double avg = words.stream() .filter(word -> word.length() > 3) .flatMapToDouble(word -> word.toLowerCase().chars().asDoubleStream()) .average() .orElse(0.0); System.out.println(avg); // 输出结果为 99.54545454545455以上代码中,首先从单词列表中创建一个
Stream,然后过滤出长度大于 3 的单词并对每个单词执行word.toLowerCase().chars().asDoubleStream()方法,将单词转换为小写字母字符数组并返回一个DoubleStream,最后通过flatMapToDouble()将所有DoubleStream合并成一个新的DoubleStream,并调用average()方法求平均值。注意,由于chars()方法返回的是一个IntStream,因此需要调用asDoubleStream()方法将其转换为DoubleStream。如果列表为空,可以通过调用orElse()方法设置一个默认值。
flatMapToInt(Function<? super T,? extends IntStream> mapper)
flatMapToInt()方法是Stream类中的一个中间操作方法,它将一个元素映射为一个IntStream,并将所有IntStream合并成一个新的IntStream。具体来说,flatMapToInt()方法接收一个函数作为参数,该函数用于将一个元素转换为另一个IntStream。flatMapToInt()方法会遍历每个元素,并将该元素传递给该函数进行转换,最终将所有IntStream合并成一个新的IntStream。例如,假设有一个包含多个字符串的列表,现在需要将每个字符串转换成一个整数数组,并将所有整数求和,可以使用
flatMapToInt()方法实现:List<String> strList = Arrays.asList("1", "2", "3"); int sum = strList.stream() .flatMapToInt(str -> IntStream.of(Integer.parseInt(str))) .sum(); System.out.println(sum); // 输出结果为 6以上代码中,首先从字符串列表中创建一个
Stream,然后对每个字符串执行IntStream.of(Integer.parseInt(str))方法,将字符串转换为整数并返回一个IntStream,最后通过flatMapToInt()将所有IntStream合并成一个新的IntStream,并调用sum()方法求和。需要注意的是,如果函数返回的是一个数组或集合等对象,那么
flatMapToInt()方法会直接将这个对象添加到结果IntStream中,而不是将它的元素逐个添加到结果IntStream中。如果需要将这个对象中的元素逐个添加到结果IntStream中,可以使用flatMapToInt()方法配合Arrays.stream()或Collection.stream()方法实现。例如,假设有一个包含多个单词的列表,现在需要将其中长度大于 3 的单词的字符转换成小写字母的 ASCII 码,并将所有 ASCII 码求平均值,可以使用
flatMapToInt()方法实现:List<String> words = Arrays.asList("Java", "Stream", "API"); double avg = words.stream() .filter(word -> word.length() > 3) .flatMapToInt(word -> word.toLowerCase().chars()) .average() .orElse(0.0); System.out.println(avg); // 输出结果为 99.54545454545455以上代码中,首先从单词列表中创建一个
Stream,然后过滤出长度大于 3 的单词并对每个单词执行word.toLowerCase().chars()方法,将单词转换为小写字母字符数组并返回一个IntStream,最后通过flatMapToInt()将所有IntStream合并成一个新的IntStream,并调用average()方法求平均值。注意,由于chars()方法返回的是一个IntStream,因此不需要调用其他方法进行转换。如果列表为空,可以通过调用orElse()方法设置一个默认值。
flatMapToLong(Function<? super T,? extends LongStream> mapper)
flatMapToLong()方法是Stream类中的一个中间操作方法,它将一个元素映射为一个LongStream,并将所有LongStream合并成一个新的LongStream。具体来说,flatMapToLong()方法接收一个函数作为参数,该函数用于将一个元素转换为另一个LongStream。flatMapToLong()方法会遍历每个元素,并将该元素传递给该函数进行转换,最终将所有LongStream合并成一个新的LongStream。例如,假设有一个包含多个字符串的列表,现在需要将每个字符串转换成一个长整数数组,并将所有长整数求和,可以使用
flatMapToLong()方法实现:List<String> strList = Arrays.asList("1", "2", "3"); long sum = strList.stream() .flatMapToLong(str -> LongStream.of(Long.parseLong(str))) .sum(); System.out.println(sum); // 输出结果为 6以上代码中,首先从字符串列表中创建一个
Stream,然后对每个字符串执行LongStream.of(Long.parseLong(str))方法,将字符串转换为长整数并返回一个LongStream,最后通过flatMapToLong()将所有LongStream合并成一个新的LongStream,并调用sum()方法求和。需要注意的是,如果函数返回的是一个数组或集合等对象,那么
flatMapToLong()方法会直接将这个对象添加到结果LongStream中,而不是将它的元素逐个添加到结果LongStream中。如果需要将这个对象中的元素逐个添加到结果LongStream中,可以使用flatMapToLong()方法配合Arrays.stream()或Collection.stream()方法实现。例如,假设有一个包含多个单词的列表,现在需要将其中长度大于 3 的单词的字符转换成小写字母的 ASCII 码,并将所有 ASCII 码求平均值,可以使用
flatMapToLong()方法实现:List<String> words = Arrays.asList("Java", "Stream", "API"); double avg = words.stream() .filter(word -> word.length() > 3) .flatMapToLong(word -> word.toLowerCase().chars().asLongStream()) .average() .orElse(0.0); System.out.println(avg); // 输出结果为 99.54545454545455以上代码中,首先从单词列表中创建一个
Stream,然后过滤出长度大于 3 的单词并对每个单词执行word.toLowerCase().chars().asLongStream()方法,将单词转换为小写字母字符数组并返回一个LongStream,最后通过flatMapToLong()将所有LongStream合并成一个新的LongStream,并调用average()方法求平均值。注意,由于chars()方法返回的是一个IntStream,因此需要调用asLongStream()方法将其转换为LongStream。如果列表为空,可以通过调用orElse()方法设置一个默认值。
distinct()
distinct()用于去除流中重复的元素,返回由不同元素组成的新流。下面是一个使用示例:
import java.util.Arrays; import java.util.List; import java.util.stream.Collectors; public class DistinctExample { public static void main(String[] args) { List<Integer> list = Arrays.asList(1, 3, 2, 4, 2, 1, 5, 6, 4, 3); List<Integer> distinctList = list.stream() .distinct() .collect(Collectors.toList()); System.out.println(distinctList); // 输出 [1, 3, 2, 4, 5, 6] } }以上代码展示了如何使用
distinct()方法去除流中重复的元素。首先创建了一个整型列表list,然后通过stream()方法将其转换为一个流。接着,使用distinct()方法得到一个由不同元素组成的新流,并通过collect(Collectors.toList())方法将其中的元素收集到一个列表中,得到一个没有重复元素的整型列表distinctList,最终将其打印出来。需要注意的是,
distinct()方法使用了对象的hashCode()和equals()方法来判断元素是否重复。因此,要确保列表中的元素已正确地实现了这两个方法。
sorted()
sorted()方法是一个中间操作,用于对Stream对象的元素进行排序并返回一个新的Stream对象。该方法会使用元素所属类的compareTo()方法进行默认排序,也可以接收一个Comparator函数来自定义排序规则。
具体用法如下:
- 创建一个包含多个元素的Stream对象。
- 调用sorted()方法,并可选地传入一个Comparator函数。
- 该方法将对Stream对象中的元素进行排序,并返回一个新的Stream对象。
例如,以下代码演示了如何使用sorted()方法对整数流进行排序:
List<Integer> list = Arrays.asList(5, 3, 8, 1, 4); Stream<Integer> sortedStream = list.stream().sorted(); sortedStream.forEach(System.out::println); // 输出 1 3 4 5 8上述代码创建一个Integer类型的列表,并将其转换成Stream对象。接下来调用sorted()方法,该方法使用默认排序规则对Stream对象中的元素进行排序,将返回一个新的Stream对象。最后使用forEach()方法遍历新的Stream对象,并将其输出到控制台上。
需要注意的是,Stream对象是惰性求值的,因此在调用sorted()方法时并不会立即执行排序操作,而是在遍历Stream对象时才进行排序。如果在排序时使用了Comparator函数,则需要确保元素类型实现了Comparable接口。
sorted(Comparator<? super T> comparator)
sorted(Comparator<? super T> comparator)方法是一个中间操作,用于对Stream对象的元素进行排序并返回一个新的Stream对象。该方法使用传入的Comparator函数来自定义排序规则。
具体用法如下:
- 创建一个包含多个元素的Stream对象。
- 调用sorted(Comparator<? super T> comparator)方法,并传入一个Comparator函数。
- 该方法将使用传入的Comparator函数对Stream对象中的元素进行排序,并返回一个新的Stream对象。
例如,以下代码演示了如何使用sorted()方法和Comparator函数对字符串流进行排序:
List<String> list = Arrays.asList("java", "python", "ruby", "c++"); Stream<String> sortedStream = list.stream().sorted((s1, s2) -> s1.length() - s2.length()); sortedStream.forEach(System.out::println); // 输出 c++ java ruby python上述代码创建一个String类型的列表,并将其转换成Stream对象。接下来调用sorted()方法,并传入一个Comparator函数,该函数按照字符串长度进行排序。该方法会返回一个新的Stream对象,其中的元素已按照指定规则排序。最后使用forEach()方法遍历新的Stream对象,并将其输出到控制台上。
需要注意的是,传入的Comparator函数可以根据任意规则进行排序,不一定要依赖元素所属类的compareTo()方法。由于Stream对象是惰性求值的,因此在调用sorted()方法时并不会立即执行排序操作,而是在遍历Stream对象时才进行排序。
peek(Consumer<? super T> action)
peek(Consumer<? super T> action)方法是一个中间操作,用于在Stream的元素流中插入一些操作,这些操作可以查看、调试或记录Stream中的元素。该方法不会改变原始Stream中的元素。
具体用法如下:
- 创建一个包含多个元素的Stream对象。
- 调用peek(Consumer<? super T> action)方法,并传入一个Consumer对象,用于接收流中的每个元素。
- 该方法将在整个流上执行指定的操作,并返回新的Stream对象。
例如,以下代码演示了如何使用peek()方法输出列表中每个元素的值:
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5); list.stream().peek(x -> System.out.println("Processing element: " + x)) .forEach(System.out::println);输出结果为:
Processing element: 1 1 Processing element: 2 2 Processing element: 3 3 Processing element: 4 4 Processing element: 5 5以上代码创建一个Integer类型的列表,并将其转换成Stream对象。接下来调用peek()方法,对每个元素执行操作并打印处理信息,最后再调用forEach()方法打印每个元素的值。由于peek()方法不会改变原始Stream中的元素,因此最终输出的结果与转换前的列表完全相同。
limit(long maxSize)
limit()方法是Stream类中的一个中间操作方法,它接收一个 long 型参数maxSize,用于将原始流截取为最多包含指定数量元素的新流。如果原始流包含的元素数量小于等于maxSize,则新流与原始流相同;如果原始流包含的元素数量大于maxSize,则新流只包含前maxSize个元素。例如,假设有一个由数字构成的流,现在需要获取其中的前五个元素,可以使用
limit()方法实现:List<Integer> numList = Arrays.asList(1, 2, 3, 4, 5, 6, 7); numList.stream() .limit(5) .forEach(System.out::println);以上代码中,首先从数字列表中创建一个
Stream,然后通过limit()方法将流截取为最多包含 5 个元素的新流,最后通过forEach()方法输出每个元素到控制台。由于调用了limit()方法,因此输出结果只包含前五个元素。需要注意的是,由于
limit()方法是一个中间操作方法,因此对流的操作不会立即执行,而是在遇到终止操作方法时才会执行。同时,由于limit()方法只截取了流的一部分元素,因此不会影响流中后续元素的处理。另外,如果提供的参数值小于等于0,则新流中不包含任何元素。如果提供的参数值大于原始流的元素数量,则新流与原始流相同。
skip(long n)
skip(long n)方法是一个中间操作,用于跳过前n个元素并返回一个新的Stream对象。如果n大于流中的元素数量,则将返回一个空的Stream对象。
具体用法如下:
- 创建一个包含多个元素的Stream对象。
- 调用skip(long n)方法,并传入要跳过的元素数目n。
- 该方法会返回一个新的Stream对象,其中包含原始流中剩余的元素。
例如,以下代码演示了如何使用skip()方法,在字符串流中跳过前两个元素:
List<String> list = Arrays.asList("apple", "banana", "orange", "pear"); Stream<String> stream = list.stream().skip(2); stream.forEach(System.out::println); // 输出 orange pear上述代码创建一个String类型的列表,并将其转换成Stream对象。接下来调用skip()方法,指定要跳过前两个元素。该方法返回一个新的Stream对象,其中包含原始流中剩余的元素。最后使用forEach()方法遍历新的Stream对象,并将其输出到控制台上。
需要注意的是,Stream对象是惰性求值的,因此在调用skip()方法时并不会立即执行跳过操作,而是在遍历Stream对象时才进行跳过。跳过的元素也不会被保留在内存中,因此可以在处理大型数据集时减少内存消耗。