every blog every motto: You can do more than you think.
https://blog.csdn.net/weixin_39190382?type=blog
0. 前言
概括
说明: 后续增补
1. 正文
1.0 通俗理解
人类视觉的注意力,简单说就第一眼会注意在一幅图像的重要位置上。

而在程序中,不管是CV还是NLP,都是对数据进行进行计算(可以理解为数组里面的数字)。在这其中,注意力是怎么呈现的呢?两个字概括:权重。通过权重把重要的数据“挑出来”,重点关注。
所以简单可以概括为:
y
=
x
∗
h
y = x*h
y=x∗h
这里的h就是注意力(权重),对x施加注意力(重点关注部分数据)。
1.1 深度学习之前
在深度学习中注意力之前就有关注意力的研究,主要在计算级视觉注意力(computational visual attention),时间大约是2000-2010年。

1.2 深度学习
1.2.1 NLP
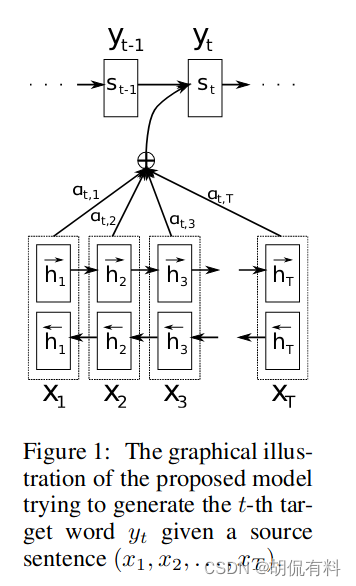
在NLP中,最早的是由Bahdanau等人于2014年提出的 Neural Machine Translation by Jointly Learning to Align and Translate(在arxiv上第一版的时间是2014.9.1)
在之前的机器翻译中,编解码网络(Encoder-Decoder)会将所有数据编码到到一个固定的长度,Cho(和Bahdanau一伙的)等发现随着句子长度的增加,网络性能会出现迅速下降。随后Bahdanau提出了RNNsearch
1.2.2 CV
在CV领域最早的是Mnih等人提出的Recurrent Models of Visual Attention(在arxiv上第一版的时间是2014.6.24)
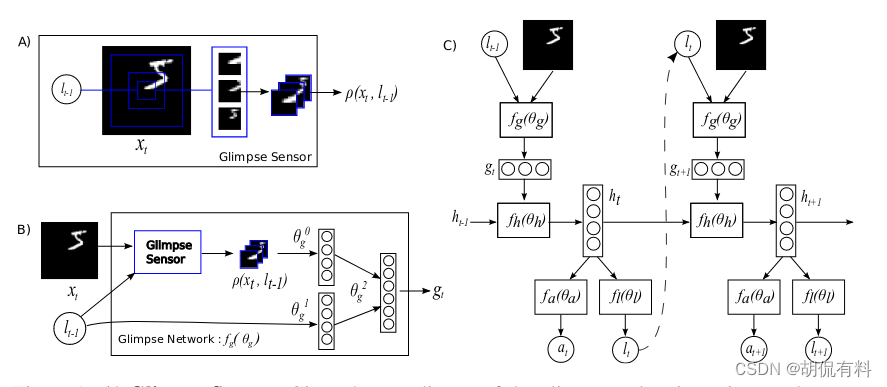
1.2.3 发展
与注意力相关的网络发展如下:
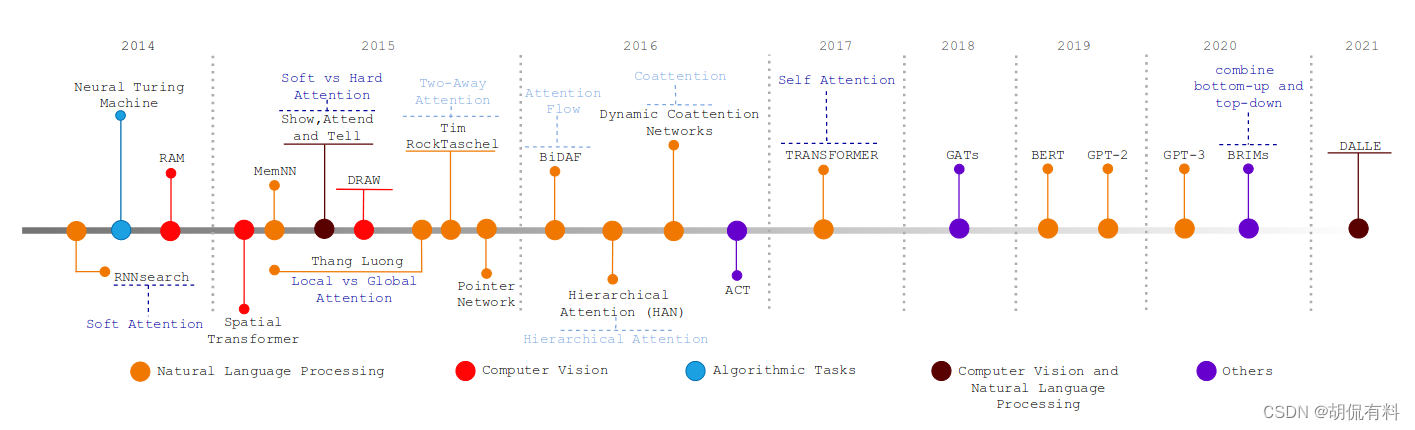
根据位置可分为如下:
- 通道注意力(channel attention)
- 空间注意力(sptail attention)
- 时间注意力(temporal attention)
- 分支注意力(branch attention)
- 通道和空间注意力(channel & spatial attention)
- 时间和空间注意力(temporal & spatial attention)
SE-Net
CVPR-2018

SK-Net
CVPR-2019
https://arxiv.org/pdf/1903.06586.pdf
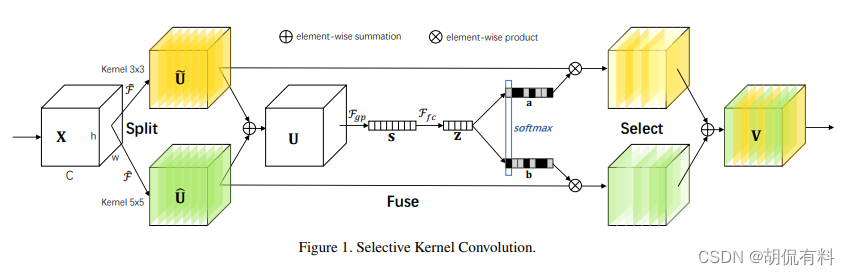
ECA-Net
CVPR-2020

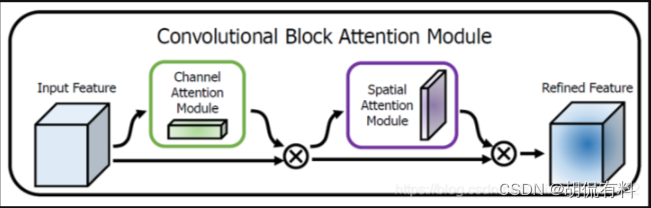
CBAM
CVPR-2018
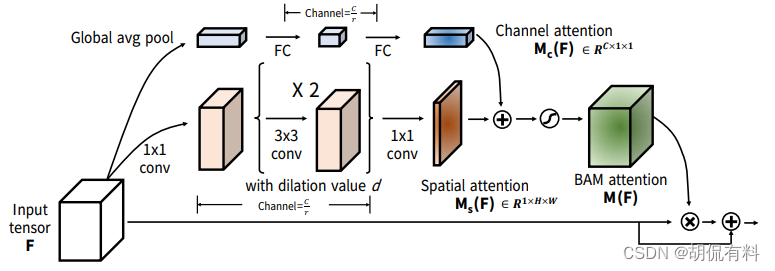
BAM
BMC-2018
https://arxiv.org/pdf/1807.06514.pdf
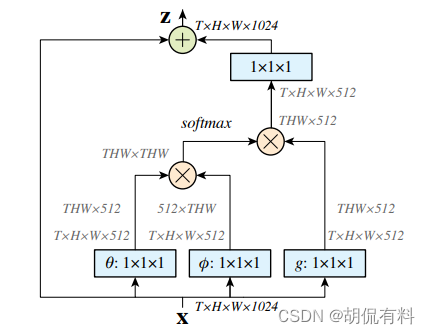
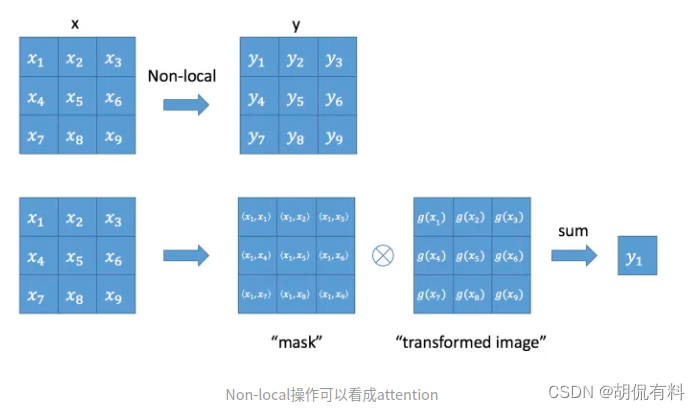
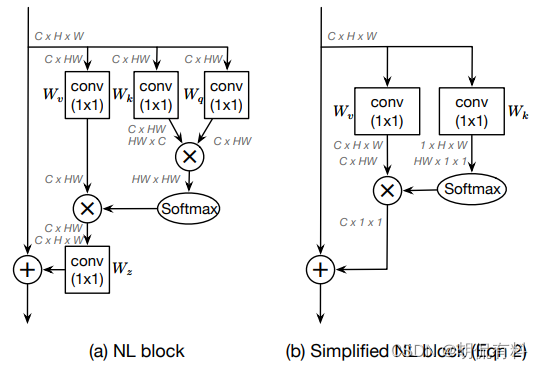
No-local
CVPR-2018
https://arxiv.org/pdf/1711.07971.pdf
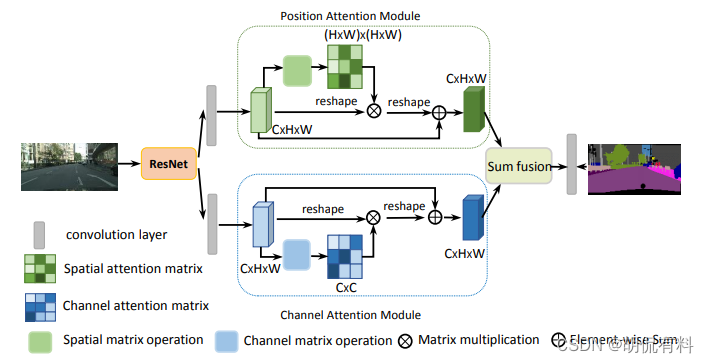
DA-Net
CVPR-2019
https://arxiv.org/pdf/1809.02983.pdf
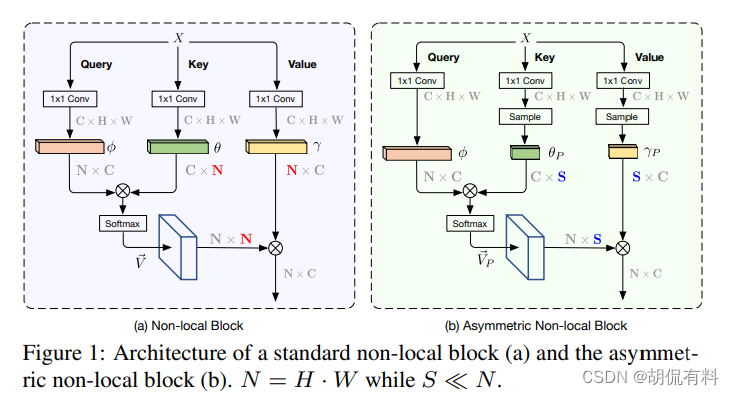
ANLNet
ICCV-2019
https://arxiv.org/pdf/1908.07678.pdf
GC-Net
ICCV-2019
https://arxiv.org/pdf/1904.11492.pdf
GSoP-Net
CVPR-2019
https://arxiv.org/pdf/1811.12006.pdf

1.2.4 统一
一般来说,注意力可用如下形式表述:
a
t
t
e
n
t
i
o
n
=
h
∗
x
attention = h * x
attention=h∗x
h即权重,即我们所说的注意力,x为原始输入。更一般的表述为:
A
t
t
e
n
t
i
o
n
=
f
(
g
(
x
)
,
x
)
Attention = f (g(x),x)
Attention=f(g(x),x)
g(x)可以表示产生注意力。f(g(x),x)表示对输入数据施加注意力。
从上图可以看到,关于注意力的生成五花八门,但最终注意力需要与输入相乘,即通过权重扩大部分数据,缩小部分数据。
关于输入数据,我们也可以通过参数变换到另一种空间
对于Transformer:
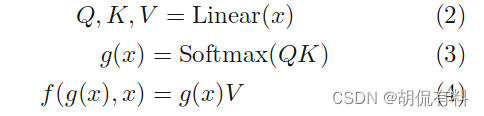
对于SE-Net
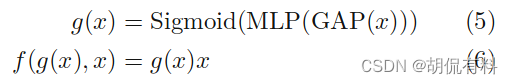
不管是卷积还是全连接,整体网络都是从一堆数据到另一堆数据,不断重复这个过程。
而注意力是从一堆数据中挑选部分数据出来进行这个过程,所以更加高效。更极致的,整个网络都使用注意力,那么在整个网络中流淌着都是有用的数据,这便是Transformer。
1.2.5 Transformer
5.1 标准情况
内部核心是self-attention,所以我们看下self-attention
我们的是输入是英文,

通过embedding转换成向量

我们需要g(x) 和x,我们通过Wq,Wk,Wv把上面两个向量映射到另一个空间,
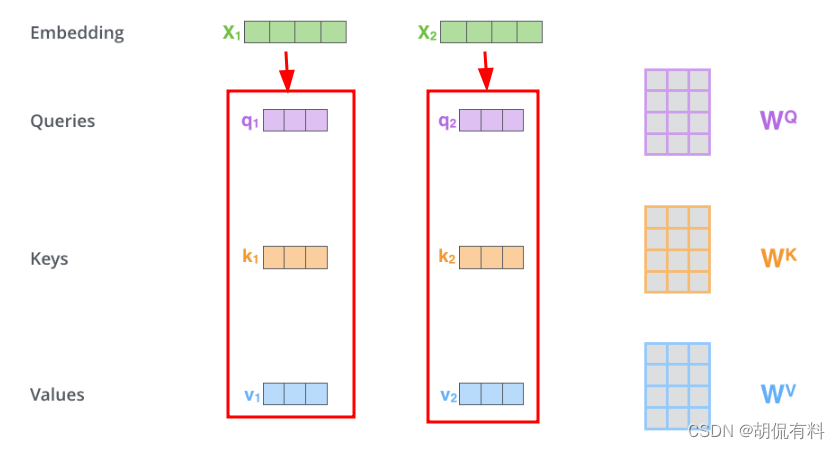
我们现在需要计算权重g(x)。对于与x1相关的权重,
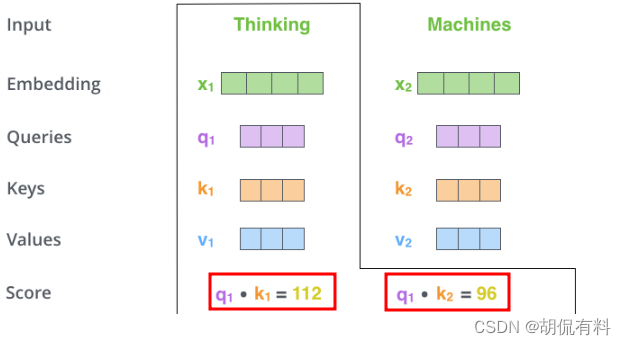
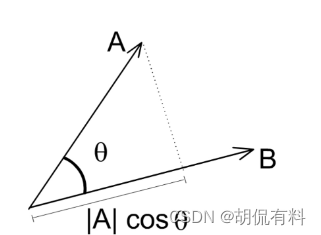
这里插一条,点积(dot prodcut)的几何意思是两个向量的相似度,值越大越相似。计算相似度也有其他方法,这里用的是点积。
调整相似度。因为值比较大,所以用一些方法将这个值缩到一个较小的范围,最终这个值也就是我们的权重。
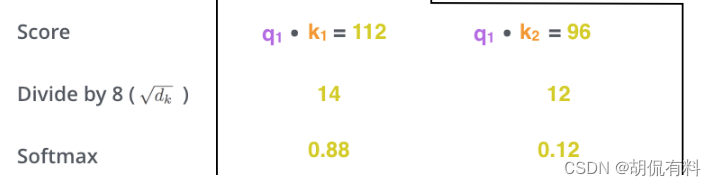
最后用我们的权重乘以对应的x(注意这个的x我们已经映射到一个新的空间v)

我们得到了第一个输入thinking与其他输入的相关性(权重),同时也施加了注意力。最后我们将第一个输入所施加的注意力求和。
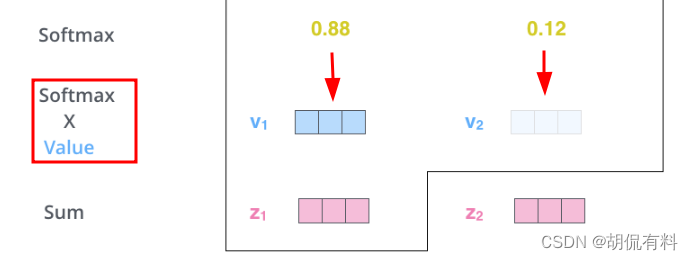
至此,我们对第一个输入与其他输入之间添加了注意力。
5.2 朴素情况
对于一个更朴素的情况。我们不对输入x进行空间变换,即不映射到3个空间,q,k,v都为x。
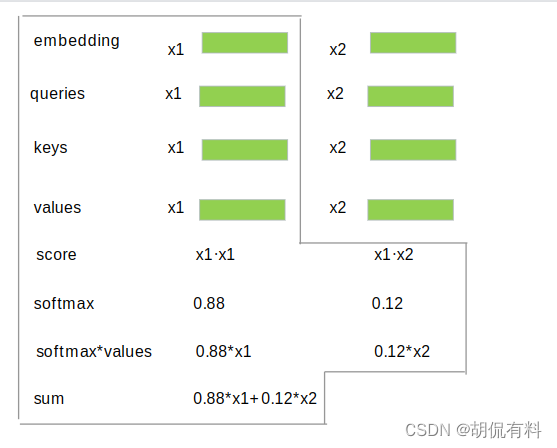
这里score,x1*x1,自己和自己和最相似,所以值自然也是最大的。(图中值没做替换,仅做一般性参考)
5.3 相似度计算
- 点积 (上面用的是这个)
- cos
- 串联 w[:q;k]
- MLP
5.4 “向量”形式
上面是逐个单词计算,实际上可以一起计算
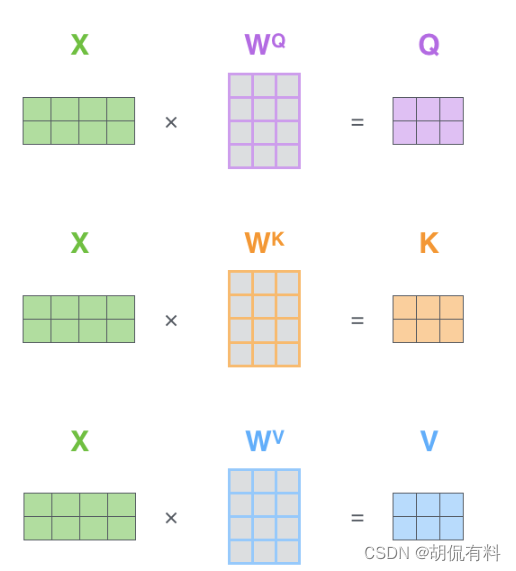
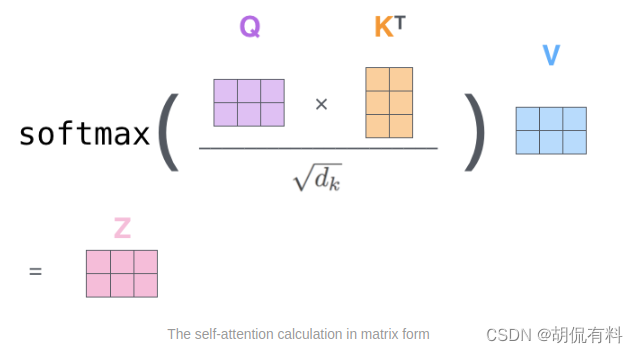
参考
[1] https://arxiv.org/pdf/1811.12006.pdf
[2] https://arxiv.org/pdf/1904.11492.pdf
[3] https://arxiv.org/pdf/1908.07678.pdf
[4] https://arxiv.org/pdf/1809.02983.pdf
[5] https://arxiv.org/pdf/1711.07971.pdf
[6] https://arxiv.org/pdf/1807.06514.pdf
[7] https://arxiv.org/pdf/1903.06586.pdf
[8] https://arxiv.org/pdf/1409.0473v6.pdf
[9] https://arxiv.org/pdf/1409.1259.pdf
[10] https://zhuanlan.zhihu.com/p/33345791
[11] https://zhuanlan.zhihu.com/p/379722366
[12] https://zhuanlan.zhihu.com/p/631398525
[13] https://easyai.tech/ai-definition/attention/
[14] https://zhuanlan.zhihu.com/p/359975221
[15] https://www.cnblogs.com/wangxuegang/p/16901089.html
[16] https://zhuanlan.zhihu.com/p/388122250
[17] https://www.cnblogs.com/wangxuegang/p/16901089.html
[18] https://blog.csdn.net/amusi1994/article/details/118347925#t19
[19] https://blog.csdn.net/Tink1995/article/details/105012972#t4
[20] https://blog.csdn.net/weixin_39190382/article/details/117711239?spm=1001.2014.3001.5502
[21] https://zhuanlan.zhihu.com/p/82312421