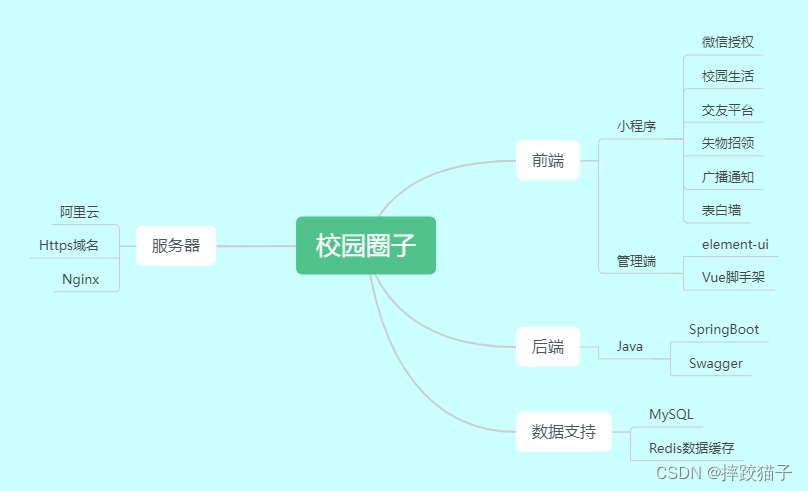
执行计划就是sql的执行查询的顺序,以及如何使用索引查询,返回的结果集的行数
EXPLAIN SELECT * from A where X=? and Y=?

1.id :是一个有顺序的编号,是查询的顺序号,有几个 select 就显示几行。id的顺序是按 select 出现的顺序增长的。id列的值越大执行优先级越高越先执行,id列的值相同则从上往下执行,id列的值为NULL最后执行。
2.selectType 表示查询中每个select子句的类型
。SIMPLE: 表示此查询不包含 UNION 查询或子询
。PRIMARY: 表示此查询是最外层的查询 (包含子查询)
。SUBOUERY: 子询中的第一个 SELECT
。UNION: 表示此查询是 UNION 的第二或随后的询
。DEPENDENT UNION: UNION 中的第二个或后面的查询语句,取决于外面的查询
。UNION RESULTUNION 的结果
。DEPENDENT SUBQUERY:子查询中的第一个 SELECT,取决于外面的查询.即子查询依赖于外层查询的结果
。DERIVED: 衍生,表示导出表的SELECT (FROM子句的子查询)
3.table: 表示该语句查询的表
4.type:优化sql的重要字段,也是我们判断sql性能和优化程度重要指标。他的取值类型范围:
。const: 通过索引一次命中,匹配一行数据
。system: 表中只有一行记录,相当于系统表;
。eq_ref: 唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配
。ref: 非唯一性索引扫描,返回匹配某个值的所有
。range: 只检索给定范围的行,使用一个索引来选择行,一般用于between、<、>
。index: 只遍历索引树:
。ALL: 表示全表扫描,这个类型的查询是性能最差的查询之一。 那么基本就是随着表的数量增多,执行效率越慢。
执行效率:
ALL <index <range< ref < eq ref < const < system,最好是避免ALL和index
5.possible_keys: 它表示Mysl在执行该sql语句的时候,可能用到的索引信息,仅仅是可能,实际不一定会用到。
6.key: 此字段是 mysql 在当前查询时所真正使用到的索引。他是possible_keys的子集
11.extra
using filesort: 表示 mysgl 对结果集进行外部排序,不能通过索引顺序达到排序效果。一般有 using filesort都建议优化去掉,因为这样的查询 cpu 资源消耗大,延时大。
using index: 覆盖索引扫描,表示查询在索树中就可查找所需数据,不用扫描表数据文件,往往说明性能0不错。
using temporary: 查询有使用临时表,一般出现于排序,分组和多表 join 的情况,查询效率不高,建议优化。
using where : sql使用了where过滤,效率较高。