1. Hadoop 入门
1. 大数据概述
1. 大数据相关说明
大数据由来: 传统数据处理应用软件不足以处理(存储和计算)它们大而复杂的数据集
大数据面临的两大问题: 针对海量数据的 存储、计算
大数据的特性:容量大、种类多、速度快、价值高
大数据部门的一般业务流程:
- 项目经理提出需求,例如统计日活、周活、月活、年度账单等
- 大数据部门的大数据平台或系统,分析一些需求指标
- 数据可视化
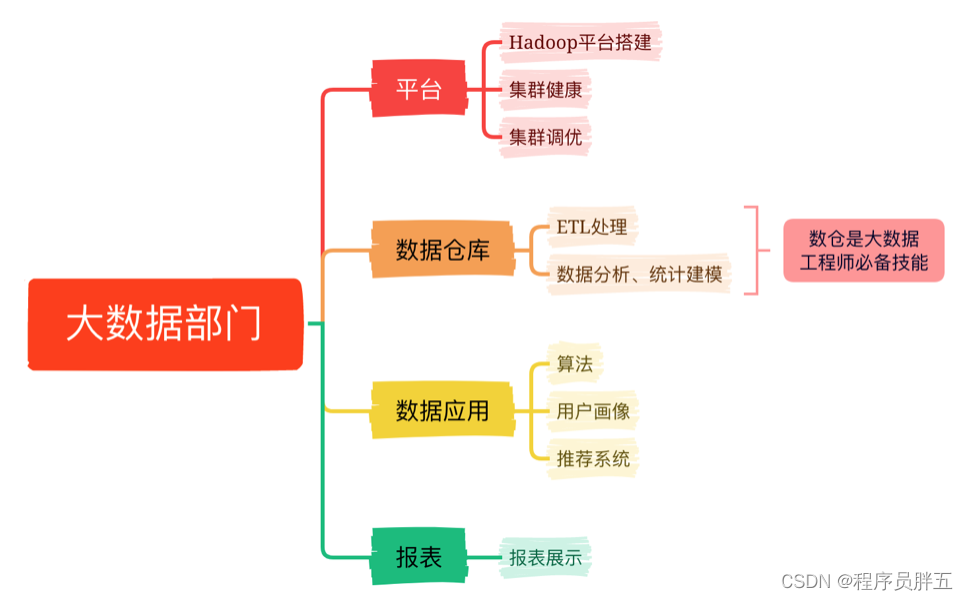
大数据部门的一般组织架构:
2. Hadoop 及大数据生态圈
Hadoop 是 Apache 旗下的一套开源软件平台,利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理。即 存储 + 计算
Hadoop 三大发行版本:Apache、Clouddera、Hortonworks
3. Hadoop 核心组件
HDFS(Hadoop Distributed File System):分布式文件系统,解决 存储 问题
YARN(Yet Another Resource Negotiator):运算资源 调度 系统
MapReduce(Map和Reduce):分布式远程 运算 框架
Common:以上三大组件的底层支撑组件(基础功能组件),主要提供基础工具包和 RPC 框架等
4. Hadoop 生态圈
Ambari: 基于 web 的工具配置
Avro:数据系列化系统
Cassandra:没有单点故障的可伸缩的多主机数据库
Chukwa:可管理大型分布式系统的数据采集系统
HBase:可扩展的分布式的数据库,支持大型表的结构化数据存储,是一种浓缩型数据库
Hive:数据仓库的基础设施,提供数据的总结和特别查询
Mahout:可扩展的机器学习和数据挖掘的库
Pig:一种高级的数据流语言
Spark:Hadoop 快速通用的计算引擎,提供了简单和丰富的编程模型,支持广泛的应用程序
Tez:一个广义的数据流的编程框架,基于 Hadoop 的 YARN,提供功能强大且灵活的引擎,来执行 DAG
Zookeeper:高性能的分布式应用程序的协调服务(只要有协调的就看 Zookeeper)
5. 集群安装模式
- 单机模式
- 伪分布式模式
- 分布式模式
- 高可用模式
- 联邦模式
6. HDFS 和 YARN 的服务种类
1. HDFS 服务(进程)
- NameNode:主节点
- DataNode:从节点
- SecondaryNameNode:主节点的辅助节点(协助 NameNode 合并元数据信息)
2. YARN 服务(进程)
- ResourceManager(主节点)
- NodeManager(从节点)
7. 知识点
- Hadoop 计算和存储在一起,因为移动计算比移动数据成本低
- Hadoop 上传文件指定用户(如 root)时不需要其密码
- Hadoop fs 在 Linux 系统中的文件位置,是在指定的 data 目录下
- 集群中发现某个表有一千多万个小文件,想办法怎么合并一下?
- 答:把小文件拉取下来,使用命令行合并,不要直接操作服务器上的那些小文件
2. Hadoop(HDFS/YARN)启动
注意:在启动 Hadoop 服务之前先启动 Zookeeper
1. 第一次启动 Hadoop 服务前先在三台机器上格式化 nodeman
hdfs namenode -format
2. 启动方式
方式一:一次性把 hdfs 和 yarn 都启动
start-all.sh # 启动服务
stop-all.sh # 停止服务
方式二:一个一个启动
start-hdfs.sh # 启动hdfs
start-yarn.sh # 启动yarn