最优化方法
牛顿法和拟牛顿法都是求解无约束最优化问题的常用方法,具有收敛速度快的优点。牛顿法是迭代算法,每一步需要求解目标函数的海森矩阵的逆矩阵,计算比较复杂,而且有时候海森矩阵不一定存在逆阵。拟牛顿法通过正定矩阵近似海森矩阵的逆矩阵或海森矩阵,简化了这一计算过程。
牛顿法
考虑无约束最优化问题
min
x
∈
R
n
f
(
x
)
(23)
\min_{x \in \Bbb R^n} f(x) \tag{23}
x∈Rnminf(x)(23)
其中
x
∗
x^*
x∗为目标函数的极小值点。
假设
f
(
x
)
f(x)
f(x)具有二阶连续偏导数,若第k次迭代值为
x
(
k
)
x^{(k)}
x(k),则可将
f
(
x
)
f(x)
f(x)在
x
(
k
)
x^{(k)}
x(k)附近进行二阶泰勒展开:
f
(
x
)
=
f
(
x
(
k
)
)
+
g
k
T
(
x
−
x
(
k
)
)
+
1
2
(
x
−
x
(
k
)
)
H
(
x
(
k
)
)
(
x
−
x
(
k
)
)
(24)
f(x) = f(x^{(k)}) + g_k^T(x - x^{(k)}) + \frac{1}{2}(x-x^{(k)})H(x^{(k)}) (x-x^{(k)}) \tag{24}
f(x)=f(x(k))+gkT(x−x(k))+21(x−x(k))H(x(k))(x−x(k))(24)
根据公式
(
20
)
(20)
(20)在
x
(
k
)
x^{(k)}
x(k)处进行二阶展开,并忽略高阶项。
这里,
g
k
=
g
(
x
(
k
)
)
=
∇
f
(
x
(
k
)
)
g_k=g(x^{(k)}) = \nabla f(x^{(k)})
gk=g(x(k))=∇f(x(k))是
f
(
x
)
f(x)
f(x)的梯度向量在点
x
(
k
)
x^{(k)}
x(k)的值,
H
(
x
(
k
)
)
H(x^{(k)})
H(x(k))是
f
(
x
)
f(x)
f(x)的海森矩阵(Hessian matrix):
H
(
x
)
=
[
∂
2
f
∂
x
i
∂
x
j
]
n
×
n
(25)
H(x) = \left[ \frac{\partial^2 f}{\partial x_i\partial x_j}\right]_{n \times n} \tag{25}
H(x)=[∂xi∂xj∂2f]n×n(25)
在点
x
(
k
)
x^{(k)}
x(k)的值。其中
∂
2
f
∂
x
i
∂
x
j
\frac{\partial^2 f}{\partial x_i \partial x_j}
∂xi∂xj∂2f =
∂
2
f
∂
x
j
∂
x
i
\frac{\partial^2 f}{\partial x_j \partial x_i}
∂xj∂xi∂2f ,所以它也是一个对称矩阵,并且二阶偏导为实数,所以它是一个实对称矩阵。
函数 f ( x ) f(x) f(x)有极值的必要条件是在极值点处一阶导数为0,即梯度向量为0.当 H ( x ( k ) ) H(x^{(k)}) H(x(k))是正定矩阵时,函数 f ( x ) f(x) f(x)的极值为极小值。
牛顿法(Newton Method)在每个迭代点处将目标函数近似为二次函数,然后通过求解梯度为 0 \pmb 0 0的方程得到迭代方向。
具体地,牛顿法寻找目标函数作二阶近似后梯度为
0
\pmb 0
0的点,逐步逼近极值点。根据费马引理,函数在点
x
x
x处取得极值的必要条件是梯度为
0
\pmb 0
0:
∇
f
(
x
)
=
0
(26)
\nabla f( x) = \pmb 0 \tag{26}
∇f(x)=0(26)
每次迭代中从点
x
(
k
)
x^{(k)}
x(k)开始,求目标函数的极小点,作为第
k
+
1
k+1
k+1次迭代值
x
(
k
+
1
)
x^{(k+1)}
x(k+1)。具体地,假设
x
(
k
+
1
)
x^{(k+1)}
x(k+1)满足:
∇
f
(
x
(
k
+
1
)
)
=
0
(27)
\nabla f(x^{(k+1)}) = \pmb 0 \tag{27}
∇f(x(k+1))=0(27)
由于式
(
24
)
(24)
(24)对
x
x
x求偏导有:
∇
f
(
x
)
=
g
k
+
H
k
(
x
−
x
(
k
)
)
(28)
\nabla f(x) = g_k + H_k(x-x^{(k)}) \tag{28}
∇f(x)=gk+Hk(x−x(k))(28)
其中
H
k
=
H
(
x
(
k
)
)
H_k=H(x^{(k)})
Hk=H(x(k))。
上式 ( 28 ) (28) (28)是如何得到的呢?
可以把该式 ( 24 ) (24) (24)展开:
f ( x ) = f ( x ( k ) ) + ( ∂ f x ( k ) ∂ x 1 ∂ f x ( k ) ∂ x 2 ⋯ ∂ f x ( k ) ∂ x n ) 1 × n ( x − x ( k ) ) n × 1 + 1 2 ( x − x ( k ) ) 1 × n T [ ∂ 2 f x ( k ) ∂ x 1 2 ∂ 2 f x ( k ) ∂ x 1 ∂ x 2 … ∂ 2 f x ( k ) ∂ x 1 ∂ x n ∂ 2 f x ( k ) ∂ x 2 ∂ x 1 ∂ 2 f x ( k ) ∂ x 2 2 … ∂ 2 f x ( k ) ∂ x 2 ∂ x n ⋮ ⋮ ⋱ ⋮ ∂ 2 f x ( k ) ∂ x n ∂ x 1 ∂ 2 f x ( k ) ∂ x n ∂ x 2 … ∂ 2 f x ( k ) ∂ x n 2 ] n × n ( x − x ( k ) ) n × 1 (29) f(x) = f(x^{(k)}) + \begin{pmatrix} \frac{\partial f x^{(k)}}{\partial x_1}& \frac{\partial f x^{(k)}}{\partial x_2} & \cdots & \frac{\partial f x^{(k)}}{\partial x_n} \end{pmatrix}_{1 \times n} (x-x^{(k)})_{n \times 1} + \frac{1}{2}(x-x^{(k)})^T_{1\times n} \begin{bmatrix} \frac{\partial^2 f x^{(k)}}{\partial x_1^2} & \frac{\partial^2 fx^{(k)}}{\partial x_1\partial x_2} & \dots & \frac{\partial^2 f x^{(k)}}{\partial x_1\partial x_n}\\ \frac{\partial^2 f x^{(k)}}{\partial x_2\partial x_1}& \frac{\partial^2 f x^{(k)}}{\partial x_2^2} & \dots & \frac{\partial^2 f x^{(k)}}{\partial x_2\partial x_n}\\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial^2 f x^{(k)}}{\partial x_n\partial x_1} & \frac{\partial^2 f x^{(k)}}{\partial x_n\partial x_2}& \dots & \frac{\partial^2 f x^{(k)}}{\partial x_n^2}\end{bmatrix}_{n\times n} (x-x^{(k)})_{n\times 1} \tag{29} f(x)=f(x(k))+(∂x1∂fx(k)∂x2∂fx(k)⋯∂xn∂fx(k))1×n(x−x(k))n×1+21(x−x(k))1×nT ∂x12∂2fx(k)∂x2∂x1∂2fx(k)⋮∂xn∂x1∂2fx(k)∂x1∂x2∂2fx(k)∂x22∂2fx(k)⋮∂xn∂x2∂2fx(k)……⋱…∂x1∂xn∂2fx(k)∂x2∂xn∂2fx(k)⋮∂xn2∂2fx(k) n×n(x−x(k))n×1(29)
上式两边同时对 x x x求梯度,可得式 ( 28 ) (28) (28)。
但式 ( 28 ) (28) (28)是怎么来的呢?
首先,等式
(
24
)
(24)
(24)右边与
x
x
x有关的项有只有
g
k
T
(
x
−
x
(
k
)
)
g_k^T(x-x^{(k)})
gkT(x−x(k))和$\frac{1}{2}(x-x{(k)})H(x{(k)}) (x-x^{(k)}) $。这里利用到了下面两个公式:
∂
a
T
x
∂
x
=
∂
x
T
a
∂
x
=
a
∂
x
T
a
x
∂
x
=
(
a
+
a
T
)
x
\begin{aligned} \frac{\partial a^T x}{\partial x} &= \frac{\partial x^T a}{\partial x} = a \\ \frac{\partial x^Tax}{\partial x} &= (a+a^T)x \end{aligned}
∂x∂aTx∂x∂xTax=∂x∂xTa=a=(a+aT)x
以及海森矩阵是对称阵,有
H
k
=
H
k
T
H_k = H^T_k
Hk=HkT。
联合式
(
27
)
(27)
(27)和式
(
28
)
(28)
(28)有
g
k
+
H
k
(
x
(
k
+
1
)
−
x
(
k
)
)
=
0
(30)
g_k + H_k(x^{(k+1)}-x^{(k)}) = 0 \tag{30}
gk+Hk(x(k+1)−x(k))=0(30)
牛顿法要求海森矩阵是可逆的,解等式
(
30
)
(30)
(30)有:
x
(
k
+
1
)
=
x
(
k
)
−
H
k
−
1
g
k
(31)
x^{(k+1)} = x^{(k)} - H_k^{-1} g_k \tag{31}
x(k+1)=x(k)−Hk−1gk(31)
或
x
(
k
+
1
)
=
x
(
k
)
+
p
k
(32)
x^{(k+1)} = x^{(k)} +p_k \tag{32}
x(k+1)=x(k)+pk(32)
其中
H
k
p
k
=
−
g
k
(33)
H_kp_k = -g_k \tag{33}
Hkpk=−gk(33)
由于在泰勒公式中忽略了高阶项将函数进行了近似,因此这个解不一定是目标函数的驻点,需要反复用式 ( 31 ) (31) (31)进行迭代,这个迭代算法就是牛顿法。
$p_k= - H_k^{-1} g_k $称为牛顿方向。
算法 牛顿法
输入: 目标函数 f ( x ) f(x) f(x),梯度 g ( x ) = ∇ f ( x ) g(x) = \nabla f(x) g(x)=∇f(x),海森矩阵 H ( x ) H(x) H(x),精度要求 ϵ \epsilon ϵ;
输出: f ( x ) f(x) f(x)的极小点 x ∗ x^* x∗。
(1) 取初始值 x ( 0 ) x^{(0)} x(0),置 k = 0 k=0 k=0。
(2) 计算 g k = g ( x ( k ) ) g_k=g(x^{(k)}) gk=g(x(k))。
(3) 若 ∣ ∣ g k ∣ ∣ < ϵ ||g_k ||< \epsilon ∣∣gk∣∣<ϵ,则停止计算,得近似解 x ∗ = x ( k ) x^*=x^{(k)} x∗=x(k)。
(4) 计算
H
k
=
H
(
x
(
k
)
)
H_k=H(x^{(k)})
Hk=H(x(k)),并求
p
k
p_k
pk
p
k
=
−
H
k
−
1
g
k
p_k =- H_k^{-1} g_k
pk=−Hk−1gk
(5) 置
x
(
k
+
1
)
=
x
(
k
)
+
p
k
x^{(k+1)} = x^{(k)} + p_k
x(k+1)=x(k)+pk。
(6) 置 k = k + 1 k=k+1 k=k+1,转(2)。
与梯度下降法相比,牛顿法有更快的收敛速度,但每次迭代的成本也更高,每次迭代需要计算梯度向量与海森矩阵,并计算海森矩阵的逆矩阵,最后计算矩阵与向量乘积。
牛顿法面临的问题是计算量大且海森矩阵不可逆的问题,拟牛顿法是对它的改进,拟牛顿法构造出一个矩阵作为海森矩阵或其逆矩阵的近似。
拟牛顿法
拟牛顿法(Quasi-Newton Methods)核心思路是不精确计算目标函数的海森矩阵然后求逆矩阵,而是通过其他手段得到海森矩阵的逆。
具体做法是构造一个近似海森矩阵或其逆矩阵的n阶正定对称矩阵 G k = G ( x ( k ) ) G_k= G(x^{(k)}) Gk=G(x(k)),用该矩阵进行牛顿法迭代。
先看牛顿法中海森矩阵
H
k
H_k
Hk满足的条件。首先,
H
k
H_k
Hk满足以下关系。在式
(
28
)
(28)
(28)中取
x
=
x
(
k
+
1
)
x=x^{(k+1)}
x=x(k+1),得
g
k
+
1
−
g
k
=
H
k
(
x
(
k
+
1
)
−
x
(
k
)
)
(34)
g_{k+1} - g_k = H_k(x^{(k+1)} - x^{(k)}) \tag{34}
gk+1−gk=Hk(x(k+1)−x(k))(34)
记
y
k
=
g
k
+
1
−
g
k
,
δ
k
=
x
(
k
+
1
)
−
x
(
k
)
y_k=g_{k+1} - g_k, \delta_k = x^{(k+1)} - x^{(k)}
yk=gk+1−gk,δk=x(k+1)−x(k),则
y
k
=
H
k
δ
k
(35)
y_k = H_k\delta_k \tag{35}
yk=Hkδk(35)
或
H
k
−
1
y
k
=
δ
k
(36)
H_k^{-1}y_k = \delta_k \tag{36}
Hk−1yk=δk(36)
式
(
35
)
(35)
(35)或
(
36
)
(36)
(36)称为拟牛顿条件,用于近似代替海森矩阵和它的逆矩阵需要满足该条件。
如果
H
k
H_k
Hk是正定的(
H
k
−
1
H_k^{-1}
Hk−1也是正定的),那么可以保证牛顿法搜索方向
p
k
p_k
pk是下降方向。因为搜索方向是
p
k
=
−
H
k
−
1
g
k
p_k = -H_k^{-1} g_k
pk=−Hk−1gk,由式
(
31
)
(31)
(31)有
x
=
x
(
k
)
+
λ
p
k
=
x
(
k
)
−
λ
H
k
−
1
g
k
(37)
x =x^{(k)} + \lambda p_k = x^{(k)} - \lambda H_k^{-1} g_k \tag{37}
x=x(k)+λpk=x(k)−λHk−1gk(37)
根据梯度下降法,所以在
x
(
k
)
x^{(k)}
x(k)的一阶泰勒展开式
(
19
)
(19)
(19)为:
f
(
x
)
=
f
(
x
(
k
)
)
+
g
k
T
(
x
−
x
(
k
)
)
f(x) = f(x^{(k)}) + g_k^T(x-x^{(k)})
f(x)=f(x(k))+gkT(x−x(k))
把
(
x
−
x
(
k
)
)
=
−
λ
H
k
−
1
g
k
(x-x^{(k)} ) = - \lambda H_k^{-1} g_k
(x−x(k))=−λHk−1gk代入上式,有:
f
(
x
)
=
f
(
x
(
k
)
)
−
λ
g
k
T
H
k
−
1
g
k
(38)
f(x) =f(x^{(k)}) -\lambda g_k^T H_k^{-1} g_k\tag{38}
f(x)=f(x(k))−λgkTHk−1gk(38)
因为
H
k
−
1
H_k^{-1}
Hk−1正定,所以有
g
k
T
H
k
−
1
g
k
>
0
g_k^T H_k^{-1} g_k > 0
gkTHk−1gk>0。当
λ
\lambda
λ为一个充分小的正数时,总有
f
(
x
)
<
f
(
x
(
k
)
)
f(x) <f(x^{(k)})
f(x)<f(x(k)),也就是说
p
k
p_k
pk是下降方向。
根据二次型的定义, g T H g g^T H g gTHg可以表示为二次型的形式,即 x T A x x^T A x xTAx的形式,其中 x x x是向量, A A A是一个对称矩阵。对于一个对称矩阵 A A A而言,如果它是正定矩阵,则对于任何非零向量 x x x,都有 x T A x > 0 x^T A x > 0 xTAx>0。
二次型是一个由平方项组成的多项式函数,其中每个变量的次数不超过2。在矩阵论中,一个关于向量 x 1 , x 2 , ⋯ , x n x_1,x_2,\cdots,x_n x1,x2,⋯,xn的二次型可以表示为:
Q ( x 1 , x 2 , ⋯ , x n ) = ∑ i = 1 n ∑ j = 1 n a i j x i x j Q(x_1,x_2,\cdots,x_n)=\sum_{i=1}^{n}\sum_{j=1}^{n}{a_{ij}x_i x_j} Q(x1,x2,⋯,xn)=i=1∑nj=1∑naijxixj
拟牛顿法将
G
k
G_k
Gk作为
H
k
−
1
H_k^{-1}
Hk−1的近似(海森矩阵的逆矩阵的近似),要求矩阵
G
k
G_k
Gk满足同样的条件。首先,每次迭代矩阵
G
k
G_k
Gk是正定的。同时,
G
k
G_k
Gk满足下面的拟牛顿条件:
G
k
+
1
y
k
=
δ
k
(39)
G_{k+1}y_k =\delta_k \tag{39}
Gk+1yk=δk(39)
按照拟牛顿条件选择
G
k
G_k
Gk作为
H
k
−
1
H_k^{-1}
Hk−1的近似或选择
B
k
B_k
Bk作为
H
k
H_k
Hk的近似的算法称为拟牛顿法。
按照拟牛顿条件,在每次迭代中可以选择更新矩阵
G
k
+
1
G_{k+1}
Gk+1:
G
k
+
1
=
G
k
+
Δ
G
k
(40)
G_{k+1} = G_k +\Delta G_k \tag{40}
Gk+1=Gk+ΔGk(40)
DFP算法
DFP(Davidon-Fletcher-Powell)算法采用了这种思路,DFP算法以其3为发明人的名字命名。DFP算法构造海森矩阵逆矩阵的近似,DFP算法选择
G
k
+
1
G_{k+1}
Gk+1的方法是,假设每一步迭代中的矩阵
G
k
+
1
G_{k+1}
Gk+1是由
G
k
G_k
Gk加上两个附加项构成的,即
G
k
+
1
=
G
k
+
α
k
μ
k
μ
k
T
+
β
k
v
k
v
k
T
(41)
G_{k+1} = G_k + \alpha_k \mu_k \mu_k^T + \beta_k v_k v_k^T \tag{41}
Gk+1=Gk+αkμkμkT+βkvkvkT(41)
其中
μ
k
\mu_k
μk和
v
k
v_k
vk为待定的
n
n
n维向量,
α
k
\alpha_k
αk和
β
k
\beta_k
βk为待定的系数。显然,按照上式构造的
G
k
G_k
Gk是一个对称矩阵。
这时,
G
k
+
1
y
k
=
G
k
y
k
+
α
k
μ
k
μ
k
T
y
k
+
β
k
v
k
v
k
T
y
k
(42)
G_{k+1} y_k = G_ky_k +\alpha_k \mu_k \mu_k^Ty_k + \beta_k v_k v_k^Ty_k \tag{42}
Gk+1yk=Gkyk+αkμkμkTyk+βkvkvkTyk(42)
为了使
G
k
+
1
G_{k+1}
Gk+1满足拟牛顿条件,即
G
k
+
1
y
k
=
δ
k
G_{k+1}y_k= \delta_k
Gk+1yk=δk:
G
k
+
1
y
k
=
G
k
y
k
+
α
k
μ
k
μ
k
T
y
k
+
β
k
v
k
v
k
T
y
k
=
δ
k
G_{k+1} y_k= G_ky_k+\alpha_k \mu_k \mu_k^Ty_k + \beta_k v_k v_k^Ty_k = \delta_k
Gk+1yk=Gkyk+αkμkμkTyk+βkvkvkTyk=δk
上式的解不唯一,可以取某些特殊值从而简化问题的求解,可使
α
k
μ
k
μ
k
T
\alpha_k \mu_k \mu_k^T
αkμkμkT和
β
k
v
k
v
k
T
\beta_k v_k v_k^T
βkvkvkT满足:
α
k
μ
k
μ
k
T
y
k
=
δ
k
(43)
\alpha_k \mu_k \mu_k^Ty_k = \delta_k \tag{43}
αkμkμkTyk=δk(43)
β k v k v k T y k = − G k y k (44) \beta_k v_k v_k^Ty_k = -G_ky_k \tag{44} βkvkvkTyk=−Gkyk(44)
不难找出这样的解,比如可以令
μ
k
=
δ
k
(45)
\mu_k = \delta_k \tag{45}
μk=δk(45)
v k = G k y k (46) v_k = G_ky_k \tag{46} vk=Gkyk(46)
将
(
45
)
(45)
(45)代入到
(
43
)
(43)
(43)可得
α
k
μ
k
μ
k
T
y
k
=
α
k
δ
k
δ
k
T
y
k
=
α
k
δ
k
(
δ
k
T
y
k
)
=
α
k
(
δ
k
T
y
k
)
δ
k
=
δ
k
(47)
\alpha_k \mu_k \mu_k^Ty_k=\alpha_k \delta_k \delta_k^Ty_k = \alpha_k \delta_k ( \delta_k^Ty_k ) = \alpha_k ( \delta_k^Ty_k )\delta_k = \delta_k \tag{47}
αkμkμkTyk=αkδkδkTyk=αkδk(δkTyk)=αk(δkTyk)δk=δk(47)
这里利用了
δ
k
T
y
k
\delta_k^T y_k
δkTyk是标量。从而得到
α
k
=
1
δ
k
T
y
k
(48)
\alpha_k = \frac{1}{\delta_k^Ty_k } \tag{48}
αk=δkTyk1(48)
同理,将
(
46
)
(46)
(46)代入
(
44
)
(44)
(44)可得
β
k
v
k
v
k
T
y
k
=
β
k
G
k
y
k
(
G
k
y
k
)
T
y
k
=
β
k
G
k
y
k
y
k
T
G
k
T
y
k
=
β
k
G
k
y
k
(
y
k
T
G
k
y
k
)
=
β
k
(
y
k
T
G
k
y
k
)
G
k
y
k
=
−
G
k
y
k
(49)
\begin{aligned} \beta_k v_k v_k^T y_k &= \beta_k G_ky_k (G_ky_k )^T y_k \\ &= \beta_k G_ky_ky_k^TG_k^Ty_k \\ &= \beta_k G_ky_k (y_k^TG_ky_k)\\ &= \beta_k(y_k^TG_ky_k) G_ky_k \\ &= -G_ky_k \end{aligned} \tag{49}
βkvkvkTyk=βkGkyk(Gkyk)Tyk=βkGkykykTGkTyk=βkGkyk(ykTGkyk)=βk(ykTGkyk)Gkyk=−Gkyk(49)
这里利用了
G
k
G_k
Gk是对称矩阵,以及
y
k
T
G
k
y
k
y_k^TG_ky_k
ykTGkyk也是标量。从而得到
β
k
=
−
1
y
k
T
G
k
y
k
(50)
\beta_k = -\frac{1}{y_k^TG_ky_k} \tag{50}
βk=−ykTGkyk1(50)
把
(
48
)
,
(
50
)
(48),(50)
(48),(50)这两个解以及
(
45
)
,
(
46
)
(45),(46)
(45),(46)代入
(
41
)
(41)
(41),得到矩阵
G
k
+
1
G_{k+1}
Gk+1的迭代公式:
G
k
+
1
=
G
k
+
δ
k
δ
k
T
δ
k
T
y
k
−
G
k
y
k
y
k
T
G
k
y
k
T
G
k
y
k
(51)
G_{k+1} = G_k + \frac{\delta_k\delta_k^T}{ \delta_k^Ty_k } -\frac{G_ky_ky_k^TG_k}{y_k^TG_ky_k}\tag{51}
Gk+1=Gk+δkTykδkδkT−ykTGkykGkykykTGk(51)
称为DFP算法。如果初始矩阵
G
0
G_0
G0是正定的,则迭代过程中每个矩阵
G
k
G_k
Gk都是正定的,通常初始矩阵可以选取单位阵。
DFP算法如下:
DFP算法
输入:目标函数 f ( x ) f(x) f(x),梯度 g ( x ) = ∇ f ( x ) g(x)=\nabla f(x) g(x)=∇f(x),精度要求 ϵ \epsilon ϵ;
输出: f ( x ) f(x) f(x)的极小点 x ∗ x^* x∗。
(1) 选定初始值 x ( 0 ) x^{(0)} x(0),取 G 0 G_0 G0为正定对称矩阵,置 k = 0 k=0 k=0。
(2) 计算 g k = g ( x ( k ) ) g_k=g(x^{(k)}) gk=g(x(k))。若 ∣ ∣ g k ∣ ∣ < ϵ ||g_k||<\epsilon ∣∣gk∣∣<ϵ,则停止计算,得近似解 x ∗ = x ( k ) x^*=x^{(k)} x∗=x(k);否则转(3)。
(3) 置 p k = − G k g k p_k=-G_kg_k pk=−Gkgk。
(4) 一维搜索: 即求得
λ
k
\lambda_k
λk使得
f
(
x
(
k
)
+
λ
k
p
k
)
=
min
λ
≥
0
f
(
x
(
k
)
+
λ
p
k
)
f(x^{(k)} + \lambda_k p_k) = \min_{\lambda \geq 0} f(x^{(k)} + \lambda p_k)
f(x(k)+λkpk)=λ≥0minf(x(k)+λpk)
(5) 置
x
(
k
+
1
)
=
x
(
k
)
+
λ
k
p
k
x^{(k+1)}=x^{(k)} + \lambda_kp_k
x(k+1)=x(k)+λkpk。
(6) 计算 g k + 1 = g ( x ( k + 1 ) ) g_{k+1} = g(x^{(k+1)}) gk+1=g(x(k+1)),若 ∣ ∣ g k + 1 ∣ ∣ < ϵ ||g_{k+1} || < \epsilon ∣∣gk+1∣∣<ϵ,则停止计算,得近似解 x ∗ = x ( k + 1 ) x^*=x^{(k+1)} x∗=x(k+1);否则,按式 ( 51 ) (51) (51)算出 G k + 1 G_{k+1} Gk+1。
(7) 置 k = k + 1 k=k+1 k=k+1,转(3)。
BFGS算法
BFGS(Broyden-Fletcher-Goldfarb-Shanno)算法以其4位发明人的名字命名,是最流行的拟牛顿算法。
该算法用
B
k
B_k
Bk近似海森矩阵,此时对应的拟牛顿条件是:
B
k
+
1
δ
k
=
y
k
(52)
B_{k+1}\delta_k = y_k \tag{52}
Bk+1δk=yk(52)
用同样的方法得到另一个迭代公式,首先令
B
k
+
1
=
B
k
+
α
k
μ
k
μ
k
T
+
β
k
v
k
v
k
T
(53)
B_{k+1} = B_k + \alpha_k \mu_k \mu_k^T + \beta_k v_k v_k^T \tag{53}
Bk+1=Bk+αkμkμkT+βkvkvkT(53)
B k + 1 δ k = B k δ k + α k μ k μ k T δ k + β k v k v k T δ k (54) B_{k+1}\delta_k = B_k\delta_k + \alpha_k \mu_k \mu_k^T\delta_k + \beta_k v_k v_k^T\delta_k \tag{54} Bk+1δk=Bkδk+αkμkμkTδk+βkvkvkTδk(54)
可使
α
k
μ
k
μ
k
T
\alpha_k \mu_k \mu_k^T
αkμkμkT和
β
k
v
k
v
k
T
\beta_k v_k v_k^T
βkvkvkT满足:
α
k
μ
k
μ
k
T
δ
k
=
y
k
(55)
\alpha_k \mu_k \mu_k^T\delta_k = y_k\tag{55}
αkμkμkTδk=yk(55)
β k v k v k T δ k = − B k δ k (56) \beta_k v_k v_k^T\delta_k = -B_k\delta_k \tag{56} βkvkvkTδk=−Bkδk(56)
不难找出这样的解,比如可以令
μ
k
=
y
k
(57)
\mu_k = y_k \tag{57}
μk=yk(57)
v k = B k δ k (58) v_k = B_k\delta_k \tag{58} vk=Bkδk(58)
分别将
(
57
)
,
(
58
)
(57),(58)
(57),(58)代入
(
55
)
,
(
56
)
(55),(56)
(55),(56),可得
α
k
y
k
y
k
T
δ
k
=
α
k
y
k
(
y
k
T
δ
k
)
=
α
k
(
y
k
T
δ
k
)
y
k
=
y
k
⇒
α
k
=
1
y
k
T
δ
k
(59)
\alpha_k y_k y_k^T \delta_k = \alpha_k y_k (y_k^T \delta_k) = \alpha_k (y_k^T \delta_k)y_k = y_k \Rightarrow \alpha_k = \frac{1}{y_k^T \delta_k} \tag{59}
αkykykTδk=αkyk(ykTδk)=αk(ykTδk)yk=yk⇒αk=ykTδk1(59)
和
β
k
v
k
v
k
T
δ
k
=
β
k
B
k
δ
k
(
B
k
δ
k
)
T
δ
k
=
β
k
B
k
δ
k
δ
k
T
B
k
δ
k
=
β
k
B
k
δ
k
(
δ
k
T
B
k
δ
k
)
=
β
k
(
δ
k
T
B
k
δ
k
)
B
k
δ
k
=
−
B
k
δ
k
⇒
β
k
=
−
1
δ
k
T
B
k
δ
k
(60)
\begin{aligned} \beta_k v_k v_k^T\delta_k &= \beta_k B_k\delta_k (B_k\delta_k)^T\delta_k\\ &= \beta_k B_k\delta_k \delta_k^TB_k\delta_k \\ &= \beta_k B_k\delta_k (\delta_k^TB_k\delta_k ) \\ &= \beta_k (\delta_k^TB_k\delta_k ) B_k\delta_k = -B_k\delta_k \end{aligned} \Rightarrow \beta_k = -\frac{1}{\delta_k^TB_k\delta_k} \tag{60}
βkvkvkTδk=βkBkδk(Bkδk)Tδk=βkBkδkδkTBkδk=βkBkδk(δkTBkδk)=βk(δkTBkδk)Bkδk=−Bkδk⇒βk=−δkTBkδk1(60)
同理,代入
(
53
)
(53)
(53)可得BFGS算法的迭代公式:
B
k
+
1
=
B
k
+
y
k
y
k
T
y
k
T
δ
k
−
B
k
δ
k
δ
k
T
B
k
δ
k
T
B
k
δ
k
(61)
B_{k+1} = B_k + \frac{y_ky_k^T}{y_k^T \delta_k} -\frac{B_k\delta_k \delta_k^TB_k}{\delta_k^TB_k\delta_k} \tag{61}
Bk+1=Bk+ykTδkykykT−δkTBkδkBkδkδkTBk(61)
可以证明,如果初始矩阵
B
0
B_0
B0是正定的,则迭代过程中的每个矩阵
B
k
B_k
Bk都是正定的。
下面写成BFGS拟牛顿法。
BFGS算法
输入:目标函数 f ( x ) f(x) f(x),梯度 g ( x ) = ∇ f ( x ) g(x)=\nabla f(x) g(x)=∇f(x),精度要求 ϵ \epsilon ϵ;
输出: f ( x ) f(x) f(x)的极小点 x ∗ x^* x∗。
(1) 选定初始值 x ( 0 ) x^{(0)} x(0),取 B 0 B_0 B0为正定对称矩阵,置 k = 0 k=0 k=0。
(2) 计算 g k = g ( x ( k ) ) g_k=g(x^{(k)}) gk=g(x(k))。若 ∣ ∣ g k ∣ ∣ < ϵ ||g_k||<\epsilon ∣∣gk∣∣<ϵ,则停止计算,得近似解 x ∗ = x ( k ) x^*=x^{(k)} x∗=x(k);否则转(3)。
(3) 由 B k p k = − g k B_kp_k=-g_k Bkpk=−gk求出 p k p_k pk。
(4) 一维搜索: 即求得
λ
k
\lambda_k
λk使得
f
(
x
(
k
)
+
λ
k
p
k
)
=
min
λ
≥
0
f
(
x
(
k
)
+
λ
p
k
)
f(x^{(k)} + \lambda_k p_k) = \min_{\lambda \geq 0} f(x^{(k)} + \lambda p_k)
f(x(k)+λkpk)=λ≥0minf(x(k)+λpk)
(5) 置
x
(
k
+
1
)
=
x
(
k
)
+
λ
k
p
k
x^{(k+1)}=x^{(k)} + \lambda_kp_k
x(k+1)=x(k)+λkpk。
(6) 计算 g k + 1 = g ( x ( k + 1 ) ) g_{k+1} = g(x^{(k+1)}) gk+1=g(x(k+1)),若 ∣ ∣ g k + 1 ∣ ∣ < ϵ ||g_{k+1} || < \epsilon ∣∣gk+1∣∣<ϵ,则停止计算,得近似解 x ∗ = x ( k + 1 ) x^*=x^{(k+1)} x∗=x(k+1);否则,按式 ( 61 ) (61) (61)算出 B k + 1 B_{k+1} Bk+1。
(7) 置 k = k + 1 k=k+1 k=k+1,转(3)。
BFGS算法在每次迭代时需要计算 n × n n \times n n×n的矩阵 B k B_k Bk,当 n n n很大时,存在该矩阵将耗费大量内容。为此, L-BFGS算法(有限存储的BFGS)算法进行了改进,其思想是不存才完整的矩阵 B k B_k Bk,只存储向量 δ k \delta_k δk和 y k y_k yk。
改进的迭代尺度法
改进的迭代尺度法(improved iterative scaling, IIS)是一种最大熵模型学习的最优化算法。
基于统计学习方法中最大熵模型内容。
假设已知最大熵模型为
P
w
(
y
∣
x
)
=
1
Z
w
(
x
)
exp
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
P_w(y|x) = \frac{1}{Z_w(x)} \exp\left( \sum_{i=1}^n w_if_i(x,y) \right)
Pw(y∣x)=Zw(x)1exp(i=1∑nwifi(x,y))
其中,
Z
w
(
x
)
=
∑
y
exp
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
Z_w(x) = \sum_y \exp \left( \sum_{i=1}^n w_if_i(x,y) \right)
Zw(x)=y∑exp(i=1∑nwifi(x,y))
对数似然函数为
L
(
w
)
=
∑
x
,
y
P
~
(
x
,
y
)
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
−
∑
x
P
~
(
x
)
log
Z
w
(
x
)
L(w) = \sum_{x,y} \tilde P(x,y) \sum_{i=1}^n w_if_i(x,y) - \sum_x \tilde P(x) \log Z_w(x)
L(w)=x,y∑P~(x,y)i=1∑nwifi(x,y)−x∑P~(x)logZw(x)
目标是通过极大似然估计学习模型参数,即求对数似然函数的极大值
w
^
\hat w
w^。
IIS的想法是: 假设最大熵模型当前的参数向量是 w = ( w 1 , w 2 , ⋯ , w n ) T w=(w_1,w_2,\cdots,w_n)^T w=(w1,w2,⋯,wn)T,希望找到一个新的向量 w + δ = ( w 1 + δ 1 , w 2 + δ 2 , ⋯ , w n + δ n ) T w+\delta=(w_1+\delta_1,w_2+\delta_2,\cdots,w_n+\delta_n)^T w+δ=(w1+δ1,w2+δ2,⋯,wn+δn)T,使得模型的对数似然函数值增大。
如果能有这样一种参数向量更新的方法 τ : w → w + δ \tau: w \rightarrow w + \delta τ:w→w+δ,那么久可以重复使用这一方法,直到找到对数似然函数的最大值。
对于给定的经验分布
P
~
(
x
,
y
)
\tilde P(x,y)
P~(x,y),模型参数从
w
w
w到
w
+
δ
w+\delta
w+δ,对数似然函数的改变量是
L
(
w
+
δ
)
−
L
(
w
)
=
∑
x
,
y
P
~
(
x
,
y
)
∑
i
=
1
n
(
w
i
+
δ
i
)
f
i
(
x
,
y
)
−
∑
x
P
~
(
x
)
log
Z
w
+
δ
(
x
)
−
∑
x
,
y
P
~
(
x
,
y
)
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
+
∑
x
P
~
(
x
)
log
Z
w
(
x
)
=
∑
x
,
y
P
~
(
x
,
y
)
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
−
∑
x
P
~
(
x
)
log
Z
w
+
δ
(
x
)
Z
w
(
x
)
\begin{aligned} L(w+\delta) - L(w) &= \sum_{x,y} \tilde P(x,y) \sum_{i=1}^n (w_i+\delta_i)f_i(x,y) - \sum_x \tilde P(x) \log Z_{w+\delta}(x) - \sum_{x,y} \tilde P(x,y) \sum_{i=1}^n w_if_i(x,y) + \sum_x \tilde P(x) \log Z_w(x) \\ &= \sum_{x,y} \tilde P(x,y) \sum_{i=1}^n \delta_if_i(x,y) - \sum_x \tilde P(x) \log \frac{Z_{w+\delta}(x)}{Z_w(x)} \end{aligned}
L(w+δ)−L(w)=x,y∑P~(x,y)i=1∑n(wi+δi)fi(x,y)−x∑P~(x)logZw+δ(x)−x,y∑P~(x,y)i=1∑nwifi(x,y)+x∑P~(x)logZw(x)=x,y∑P~(x,y)i=1∑nδifi(x,y)−x∑P~(x)logZw(x)Zw+δ(x)
利用不等式
−
log
α
≥
1
−
α
,
α
>
0
-\log \alpha \geq 1 -\alpha, \quad \alpha > 0
−logα≥1−α,α>0
建立对数似然函数改变量的下界:
L
(
w
+
δ
)
−
L
(
w
)
≥
∑
x
,
y
P
~
(
x
,
y
)
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
+
1
−
∑
x
P
~
(
x
)
Z
w
+
δ
(
x
)
Z
w
(
x
)
=
∑
x
,
y
P
~
(
x
,
y
)
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
+
1
−
∑
x
P
~
(
x
)
∑
y
exp
(
∑
i
=
1
n
(
w
i
+
δ
i
)
f
i
(
x
,
y
)
)
∑
y
exp
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
=
∑
x
,
y
P
~
(
x
,
y
)
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
+
1
−
∑
x
P
~
(
x
)
∑
y
exp
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
⋅
exp
(
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
)
∑
y
exp
(
∑
i
=
1
n
w
i
f
i
(
x
,
y
)
)
=
∑
x
,
y
P
~
(
x
,
y
)
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
+
1
−
∑
x
P
~
(
x
)
∑
y
P
w
(
y
∣
x
)
⋅
exp
(
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
)
\begin{aligned} L(w+\delta) - L(w) &\geq \sum_{x,y} \tilde P(x,y) \sum_{i=1}^n \delta_i f_i(x,y) + 1 - \sum_x \tilde P(x) \frac{Z_{w+\delta}(x)}{Z_w(x)} \\ &= \sum_{x,y} \tilde P(x,y) \sum_{i=1}^n \delta_i f_i(x,y) + 1 - \sum_x \tilde P(x) \frac{\sum_y\exp\left(\sum_{i=1}^n (w_i+\delta_i)f_i(x,y) \right)}{\sum_y\exp\left(\sum_{i=1}^n w_if_i(x,y) \right)} \\ &= \sum_{x,y} \tilde P(x,y) \sum_{i=1}^n \delta_i f_i(x,y) + 1 - \sum_x \tilde P(x) \frac{\sum_y\exp \left(\sum_{i=1}^n w_if_i(x,y) \right) \cdot \exp(\sum_{i=1}^n\delta_if_i(x,y))}{\sum_y\exp\left(\sum_{i=1}^n w_if_i(x,y) \right)} \\ &= \sum_{x,y} \tilde P(x,y) \sum_{i=1}^n \delta_i f_i(x,y) + 1 - \sum_x \tilde P(x) \sum_y P_w(y|x) \cdot \exp(\sum_{i=1}^n\delta_if_i(x,y)) \\ \end{aligned}
L(w+δ)−L(w)≥x,y∑P~(x,y)i=1∑nδifi(x,y)+1−x∑P~(x)Zw(x)Zw+δ(x)=x,y∑P~(x,y)i=1∑nδifi(x,y)+1−x∑P~(x)∑yexp(∑i=1nwifi(x,y))∑yexp(∑i=1n(wi+δi)fi(x,y))=x,y∑P~(x,y)i=1∑nδifi(x,y)+1−x∑P~(x)∑yexp(∑i=1nwifi(x,y))∑yexp(∑i=1nwifi(x,y))⋅exp(∑i=1nδifi(x,y))=x,y∑P~(x,y)i=1∑nδifi(x,y)+1−x∑P~(x)y∑Pw(y∣x)⋅exp(i=1∑nδifi(x,y))
记这个关于
δ
\delta
δ的函数为
A
(
δ
∣
w
)
A(\delta|w)
A(δ∣w):
A
(
δ
∣
w
)
=
∑
x
,
y
P
~
(
x
,
y
)
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
+
1
−
∑
x
P
~
(
x
)
∑
y
P
w
(
y
∣
x
)
⋅
exp
(
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
)
A(\delta|w) = \sum_{x,y} \tilde P(x,y) \sum_{i=1}^n \delta_i f_i(x,y) + 1 - \sum_x \tilde P(x) \sum_y P_w(y|x) \cdot \exp(\sum_{i=1}^n\delta_if_i(x,y))
A(δ∣w)=x,y∑P~(x,y)i=1∑nδifi(x,y)+1−x∑P~(x)y∑Pw(y∣x)⋅exp(i=1∑nδifi(x,y))
代表了在已知参数
w
w
w的情况下所对应的
δ
\delta
δ的函数。
于是有
L
(
w
+
δ
)
−
L
(
w
)
≥
A
(
δ
∣
w
)
L(w+\delta) -L(w) \geq A(\delta|w)
L(w+δ)−L(w)≥A(δ∣w)
即
A
(
δ
∣
w
)
A(\delta|w)
A(δ∣w)是对数似然函数该变量的一个下界。
这个不等式为什么成立,这里来证明一下。
把这个不等式写成下面的形式:
f
(
α
)
=
−
log
α
−
(
1
−
α
)
f(\alpha) = -\log \alpha - (1 -\alpha)
f(α)=−logα−(1−α)
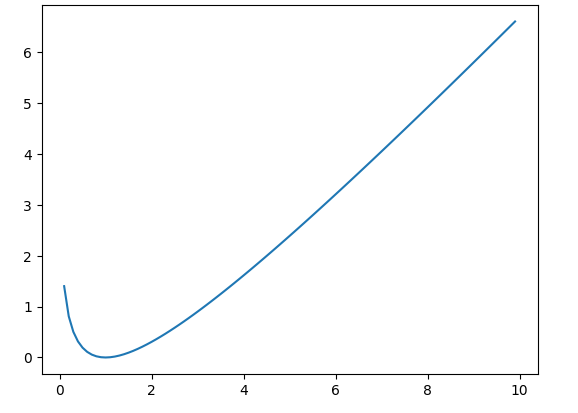
它的函数图像是上面这样子的。
我们需要证明
f
(
α
)
≥
0
f(\alpha ) \geq 0
f(α)≥0,其中
α
>
0
\alpha > 0
α>0。对上式求导数:
f
′
(
α
)
=
−
1
α
+
1
=
α
−
1
α
f^\prime(\alpha) = -\frac{1}{\alpha} + 1 = \frac{\alpha-1}{\alpha}
f′(α)=−α1+1=αα−1
显然
α
=
1
\alpha=1
α=1时导数为零。
- 当 α > 1 \alpha > 1 α>1时, f ′ ( α ) > 0 f^\prime (\alpha) > 0 f′(α)>0 ,说明在 α > 1 \alpha > 1 α>1是 f ( α ) f(\alpha) f(α)是单调递增的;
- 当 1 > α > 0 1 > \alpha > 0 1>α>0时, f ′ ( α ) < 0 f^\prime(\alpha) < 0 f′(α)<0,说明在 1 > α > 0 1 > \alpha > 0 1>α>0时, f ( α ) f(\alpha) f(α)是单调递减的;
因此,
α
=
1
\alpha=1
α=1是函数的极小值。把
α
=
1
\alpha=1
α=1代入得
f
(
1
)
=
−
log
1
−
(
1
−
1
)
=
0
f(1) = -\log 1 -(1-1) = 0
f(1)=−log1−(1−1)=0
说明
f
(
α
)
≥
0
f(\alpha ) \geq 0
f(α)≥0。
如果能找到合适的 δ \delta δ式下界 A ( δ ∣ w ) A(\delta|w) A(δ∣w)提高,那么对数似然函数也会提高。但是,函数 A ( δ ∣ w ) A(\delta|w) A(δ∣w)中的 δ \delta δ是一个向量,含有多个变量,不利于同时优化。IIS试图一次只优化其中一个变量 δ i \delta_i δi,而固定其他变量 δ j , i ≠ j \delta_j ,\, i \neq j δj,i=j。
为了达到这一目的,IIS进一步降低下界
A
(
δ
∣
w
)
A(\delta|w)
A(δ∣w)。具体地,IIS引进一个量
f
#
(
x
,
y
)
f^\#(x,y)
f#(x,y):
f
#
(
x
,
y
)
=
∑
i
f
i
(
x
,
y
)
f^\#(x,y) = \sum_i f_i(x,y)
f#(x,y)=i∑fi(x,y)
同时有:
f
i
(
x
,
y
)
f
#
(
x
,
y
)
≥
0
\frac{f_i(x,y)}{f^\#(x,y)} \geq 0
f#(x,y)fi(x,y)≥0
且
∑
i
f
i
(
x
,
y
)
f
#
(
x
,
y
)
=
1
\sum_i \frac{f_i(x,y)}{f^\#(x,y)} =1
i∑f#(x,y)fi(x,y)=1
显然这是成立的。
因为
f
i
f_i
fi是二值函数,当特征函数满足时取1,否则取0。因此
f
#
(
x
,
y
)
f^\#(x,y)
f#(x,y)表示特征在
(
x
,
y
)
(x,y)
(x,y)出现的次数,对于固定的训练集来说是一个常量。这样
A
(
δ
∣
w
)
A(\delta|w)
A(δ∣w)可以改写为:
A
(
δ
∣
w
)
=
∑
x
,
y
P
~
(
x
,
y
)
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
+
1
−
∑
x
P
~
(
x
)
∑
y
P
w
(
y
∣
x
)
exp
(
f
#
(
x
,
y
)
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
f
#
(
x
,
y
)
)
(62)
\begin{aligned} A(\delta|w) &= \sum_{x,y} \tilde P(x,y) \sum_{i=1}^n \delta_if_i(x,y) + 1 - \sum_x \tilde P(x) \sum_y P_w(y|x) \exp \left( f^\#(x,y) \sum_{i=1}^n \frac{\delta_i f_i(x,y)}{f^\#(x,y)}\right) \end{aligned} \tag{62}
A(δ∣w)=x,y∑P~(x,y)i=1∑nδifi(x,y)+1−x∑P~(x)y∑Pw(y∣x)exp(f#(x,y)i=1∑nf#(x,y)δifi(x,y))(62)
如果尝试计算
∂
A
(
δ
∣
w
)
∂
δ
i
\frac{\partial A(\delta|w)}{\partial \delta_i}
∂δi∂A(δ∣w),会发现第三项的
exp
(
∑
i
δ
i
f
i
(
x
,
y
)
)
\exp (\sum_i \delta_i f_i(x,y))
exp(∑iδifi(x,y))项不好消,还是会和所有的
δ
i
\delta_i
δi有关,因此我们尝试利用Jesen不等式,改写这个式子。
根据Jesen不等式,得到
exp
(
∑
i
=
1
n
f
i
(
x
,
y
)
f
#
(
x
,
y
)
δ
i
f
#
(
x
,
y
)
)
≤
∑
i
=
1
n
f
i
(
x
,
y
)
f
#
(
x
,
y
)
exp
(
δ
i
f
#
(
x
,
y
)
)
\exp \left( \sum_{i=1}^n \frac{ f_i(x,y)}{f^\#(x,y)} \delta_if^\#(x,y) \right) \leq \sum_{i=1}^n \frac{f_i(x,y)}{f^\#(x,y)} \exp(\delta_i f^\#(x,y))
exp(i=1∑nf#(x,y)fi(x,y)δif#(x,y))≤i=1∑nf#(x,y)fi(x,y)exp(δif#(x,y))
Jensen不等式的说明参见:EM算法
于是式
(
6.30
)
(6.30)
(6.30)可以改写为
A
(
δ
∣
w
)
≥
∑
x
,
y
P
~
(
x
,
y
)
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
+
1
−
∑
x
P
~
(
x
)
∑
y
P
w
(
y
∣
x
)
∑
i
=
1
n
(
f
i
(
x
,
y
)
f
#
(
x
,
y
)
)
exp
(
δ
i
f
#
(
x
,
y
)
)
(63)
A(\delta|w) \geq \sum_{x,y} \tilde P(x,y) \sum_{i=1}^n \delta_if_i(x,y) + 1 - \sum_x \tilde P(x) \sum_y P_w(y|x) \sum_{i=1}^n \left( \frac{f_i(x,y)}{f^\#(x,y)}\right) \exp(\delta_i f^\#(x,y)) \tag{63}
A(δ∣w)≥x,y∑P~(x,y)i=1∑nδifi(x,y)+1−x∑P~(x)y∑Pw(y∣x)i=1∑n(f#(x,y)fi(x,y))exp(δif#(x,y))(63)
记不等式右端为
B
(
δ
∣
w
)
=
∑
x
,
y
P
~
(
x
,
y
)
∑
i
=
1
n
δ
i
f
i
(
x
,
y
)
+
1
−
∑
x
P
~
(
x
)
∑
y
P
w
(
y
∣
x
)
∑
i
=
1
n
(
f
i
(
x
,
y
)
f
#
(
x
,
y
)
)
exp
(
δ
i
f
#
(
x
,
y
)
)
B(\delta|w) = \sum_{x,y} \tilde P(x,y) \sum_{i=1}^n \delta_if_i(x,y) + 1 - \sum_x \tilde P(x) \sum_y P_w(y|x) \sum_{i=1}^n \left( \frac{f_i(x,y)}{f^\#(x,y)}\right) \exp(\delta_i f^\#(x,y))
B(δ∣w)=x,y∑P~(x,y)i=1∑nδifi(x,y)+1−x∑P~(x)y∑Pw(y∣x)i=1∑n(f#(x,y)fi(x,y))exp(δif#(x,y))
进而得到
L
(
w
+
δ
)
−
L
(
w
)
≥
B
(
δ
∣
w
)
L(w+\delta) -L(w) \geq B(\delta|w)
L(w+δ)−L(w)≥B(δ∣w)
此时,
B
(
δ
∣
w
)
B(\delta|w)
B(δ∣w)是对数似然函数改变量的一个新的下界。
求
B
(
δ
∣
w
)
B(\delta|w)
B(δ∣w)对
δ
i
\delta_i
δi的偏导数:
∂
B
(
δ
∣
w
)
∂
δ
i
=
∑
x
,
y
P
~
(
x
,
y
)
f
i
(
x
,
y
)
−
∑
x
P
~
(
x
)
∑
y
P
w
(
y
∣
x
)
f
i
(
x
,
y
)
exp
(
δ
i
f
#
(
x
,
y
)
)
(64)
\frac{\partial B(\delta|w)}{\partial \delta_i} = \sum_{x,y} \tilde P(x,y) f_i(x,y) - \sum_x \tilde P(x) \sum_y P_w(y|x) f_i(x,y) \exp(\delta_i f^\#(x,y)) \tag{64}
∂δi∂B(δ∣w)=x,y∑P~(x,y)fi(x,y)−x∑P~(x)y∑Pw(y∣x)fi(x,y)exp(δif#(x,y))(64)
在上式中,除
δ
i
\delta_i
δi外不含其他任何变量。令偏导数为0得到
∑
x
,
y
P
~
(
x
)
P
w
(
y
∣
x
)
f
i
(
x
,
y
)
exp
(
δ
i
f
#
(
x
,
y
)
)
=
E
P
~
(
f
i
)
(65)
\sum_{x,y} \tilde P(x) P_w(y|x) f_i(x,y) \exp(\delta_if^\#(x,y)) = E_{\tilde P}(f_i) \tag{65}
x,y∑P~(x)Pw(y∣x)fi(x,y)exp(δif#(x,y))=EP~(fi)(65)
于是,依次对
δ
i
\delta_i
δi求解方程
(
65
)
(65)
(65)就可以求出
δ
\delta
δ。
这样就得到了一种求 w w w的最优解的迭代算法,即改进的迭代尺度算法IIS。
算法6.1 (改进的迭代尺度算法IIS)
输入: 特征函数 f 1 , f 2 , ⋯ , f n f_1,f_2,\cdots,f_n f1,f2,⋯,fn;经验分布 P ~ ( X , Y ) \tilde P(X,Y) P~(X,Y),模型 P w ( y ∣ x ) P_w(y|x) Pw(y∣x);
输出: 最优参数值 w i ∗ w^*_i wi∗;最优模型 P w ∗ P_{w^*} Pw∗。
(1) 对所有 i ∈ { 1 , 2 , ⋯ , n } i \in \{1,2,\cdots,n\} i∈{1,2,⋯,n},取初值 w i = 0 w_i=0 wi=0。
(2) 对每一 i ∈ { 1 , 2 , ⋯ , n } i \in \{1,2,\cdots, n\} i∈{1,2,⋯,n}
(a) 令
δ
i
\delta_i
δi是方程
∑
x
,
y
P
~
(
x
)
P
w
(
y
∣
x
)
f
i
(
x
,
y
)
exp
(
δ
i
f
#
(
x
,
y
)
)
=
E
P
~
(
f
i
)
\sum_{x,y} \tilde P(x) P_w(y|x) f_i(x,y) \exp(\delta_if^\#(x,y)) = E_{\tilde P}(f_i)
x,y∑P~(x)Pw(y∣x)fi(x,y)exp(δif#(x,y))=EP~(fi)
的解,这里,
f
#
(
x
,
y
)
=
∑
i
=
1
n
f
i
(
x
,
y
)
f^\#(x,y) = \sum_{i=1}^n f_i(x,y)
f#(x,y)=i=1∑nfi(x,y)
(b) 更新
w
i
w_i
wi值:
w
i
←
w
i
+
δ
i
w_i \leftarrow w_i + \delta_i
wi←wi+δi。
(3) 如果不是所有 w i w_i wi都收敛,重复步(2)。
参考
- 凸优化 Stephen Boyd
- 机器学习的数学 雷明
- 统计学习方法