索引,在MySQL中非常重要。它能提高数据库的性能,不用加内存,不用改程序,不用调sql,只要执行 正确的 create index ,查询速度就可能提高成百上千倍。
但是,查询速度的提高是以插入、更新、删除的速度为代价的,这些写操作,增加了大量的IO。所以它的价值,在于提高一个海量数据的检索速度。
什么是索引?
索引,本质上属于“书的目录”,通过目录,就可以快速的找到某个章节对应的位置,索引的效果就是加快了查找的速度。
但是索引也提高了增删查的开销,此时进行增删改,就需要调整已经创建好的索引目录;
所以还提高了空间的开销,构建索引还需要额外的硬盘空间来保存。
查看索引:
show index from 表名;
虽然我们没有手动创造一个索引,但是创建学生表的时候我们指定了id这一列是主键,表里如果有主键,主键这一列就会自动创建索引(有unique 和 foreign也会自动创建索引)

创建索引:
create index idx_student_name on student(name);在这行代码中,我们创建了一个名为idx_student_name这样的索引,根据 名字 这一列来创建的索引
创建索引最好是在表创建之初就把索引给创建好,否则,如果是针对一个表中已经有很多很多记录的表来创建索引,是一个危险操作!
这个时候会吃掉大量的磁盘IO,花费很长的时间,并且在这段时间里数据库是无法被正常使用的。

索引就是为了加快查询的速度,但是并不是所有的情况加上索引就一定快
如果姓名有重复,重名特别多的情况下,那么索引就不一定能够提高查询的速度了。
例如针对像性别这样的列,或者是大学生管理系统中年龄这样的列加索引,是无法提高查找速度的。
关于代码优化:
我们把索引创建好了之后,不需要手动使用,查询的时候就会自动的来走索引。
SQL是通过数据库的执行引擎来进行执行的,这里面会涉及到一些优化操作,执行引擎会自动评估,哪种方案是成本最低,速度最快的。
具体的某一次查询,实际上是否在走索引,以及怎么走的,其实是不好预期的。
但是可以使用explain这个关键字,显示出查询过程中,具体的使用索引的情况~
同时代码优化不只是SQL有,C,C++,Java这一些主流的语言都有代码优化的能力。
我们所使用的编译器、虚拟机就会总和评估,可能就会在保持原有代码含义不变的基础上,对你的代码进行调整。
索引的数据结构(重点)
1.哈希表
哈希表是数据结构中最重要的结构,这也是工作和面试中出现频率极高的数据结构。
当我们用哈希表查找元素,时间复杂度是O(1),这是一个非常优秀的数据结构,但是哈希表不适合做数据库的索引。
原因在于:哈希表只能比较是否相等,而对于范围的数据查询却无能为力。但是数据库却经常要进行范围查询。
2.二叉搜索树
二叉搜索树的时间复杂度是O(N),并且这是考虑的最坏情况,是在单枝树的情况下(相当于一个链表)。
并且二叉搜索树好像可以进行范围查询了。但是数据库并没有使用二叉搜索树
二叉意味着当元素多了的时候,树的高度就会比较高,树的高度就决定了查询的时候元素的比较次数慧比较多。而查询次数又会跟硬盘读写挂钩,所以二叉搜索树也不适合来作为索引的数据结构。
3.N叉搜索树
N叉搜索树就是每个节点上有多个值,同时还有多个分支,这样操作树的高度就降低了。
其中的一种典型实现,叫做B树。
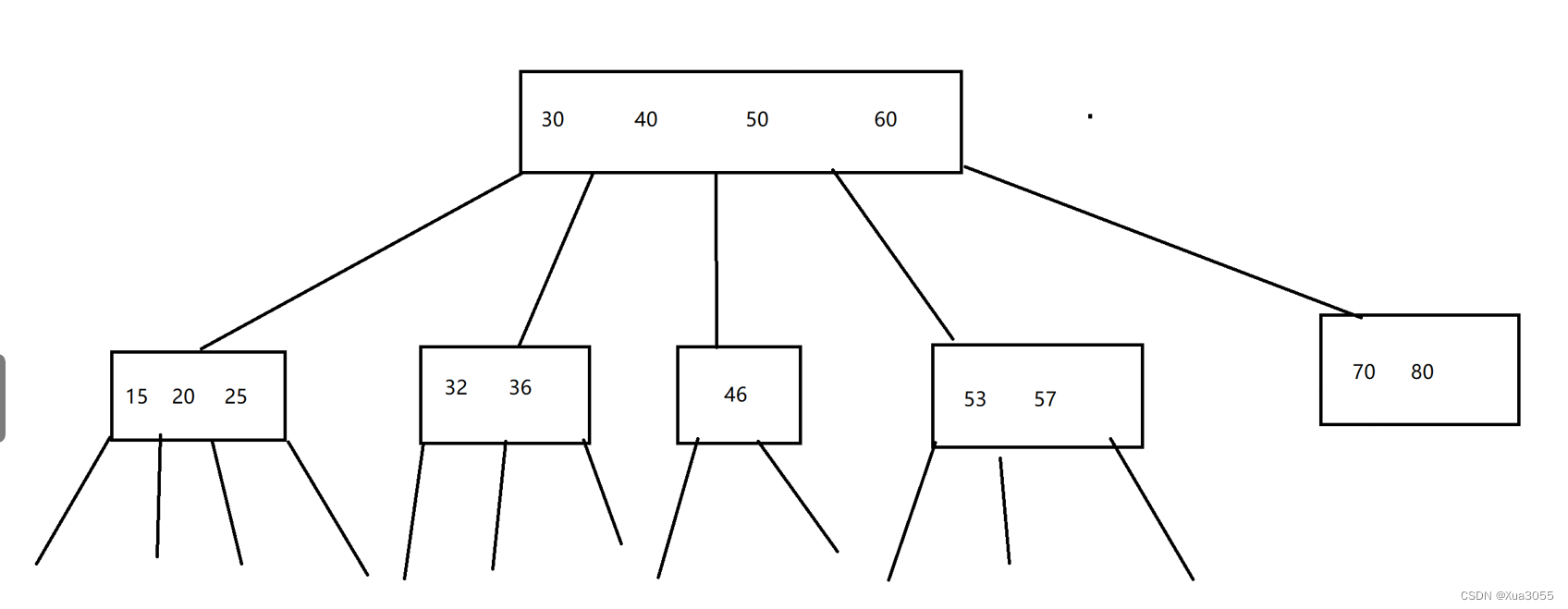
这样一看,这么多数据只用了2高度就完成了储存,这对于数据库的索引来说再适合不过了。
虽然总数据还是那么多,比较次数差不多,但是读写硬盘的次数减少了,让硬盘的占用大大降低了,因提高了速度。
4. B+树
B树已经可以比二叉搜索树更适合于做数据库的索引了,但是还不够。针对这里,又引进了B+树,这是对B树的进一步改进,可以这么说:B+树就是为了索引这个场景量身定做的数据结构。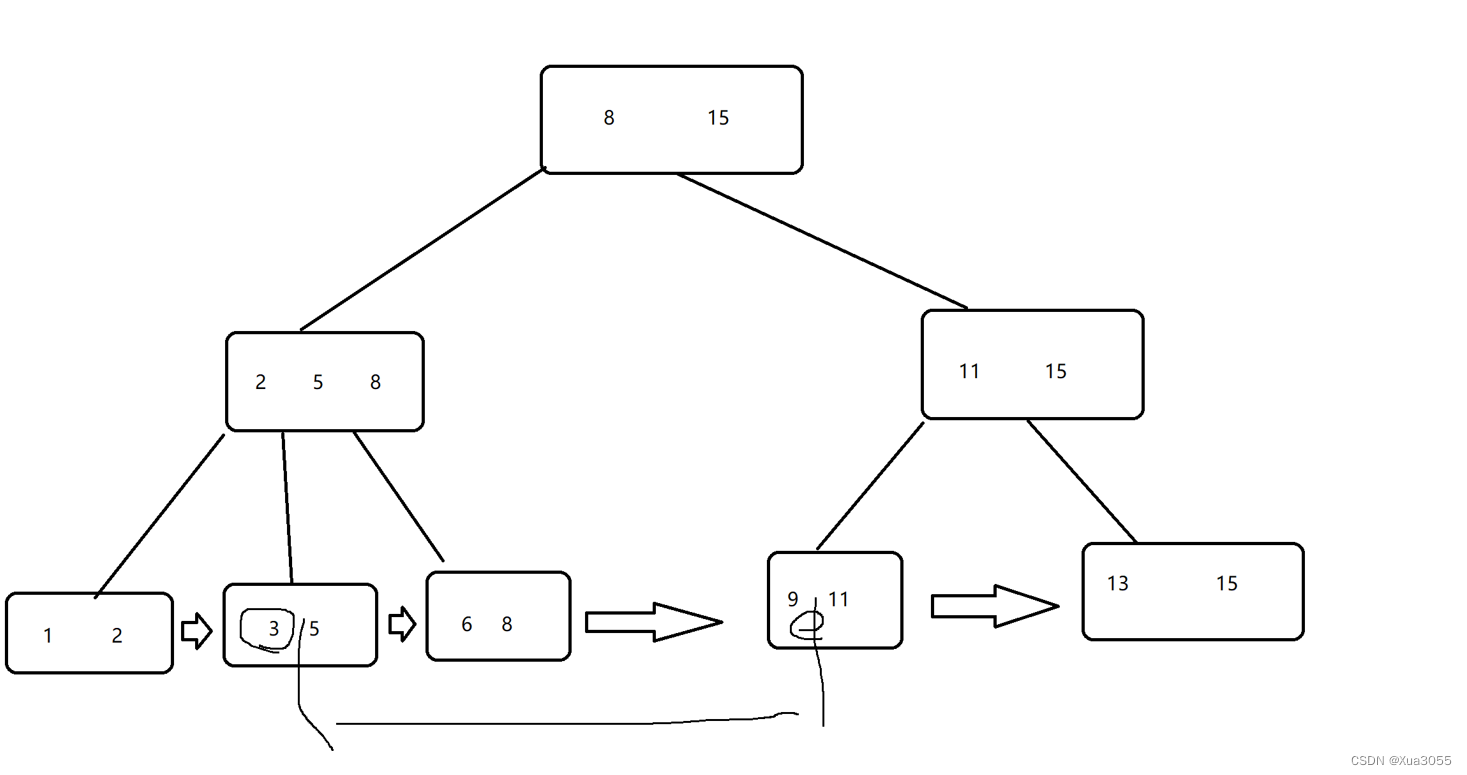
比如查找 id > 3 and id < 10 这样的元素,B+树就能很好的实现。
1.B+树也是一个N叉搜索树,每个节点上可能包含N个key,N个key划分出N个区间,最后一个区间就相当于最大值。
2.父元素的key会在子元素中重复出现,并且是以最大值的姿态出现的~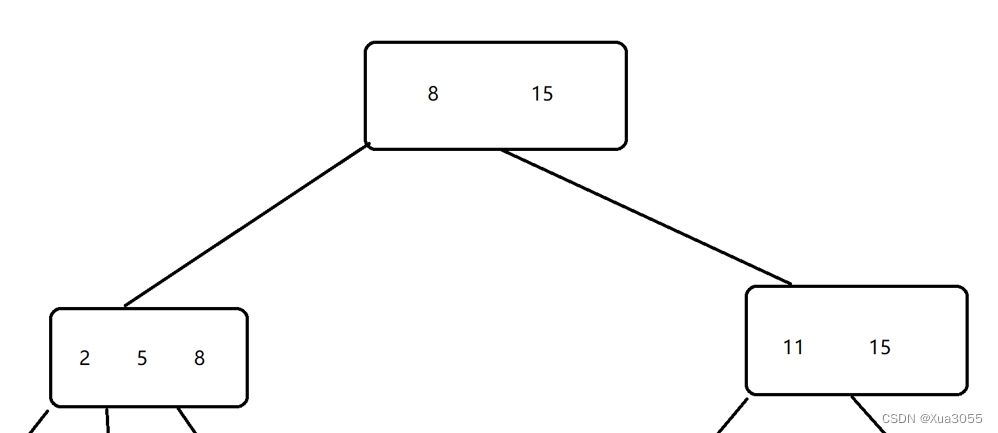
例如,在左子节点中,父元素为8和15,那么子节点里面的元素就包含:小于8的元素、8
在右节点中,包含:8到15的元素,15
这样的重复出现,导致叶子结点包含了所有数据的全集。非叶子结点中所有的值都会在叶子结点中体现出来
3.会把叶子节点,用类似于链表的方式进行首尾相连
这样的操作,好处有以下几点:
1.作为一个N叉搜索树,但是高度却很低,比较的时候硬盘的IO次数大大降低了
2.更适合进行范围查询
3.所有的查询都是落在叶子节点上的,无论查询哪个元素,中间比较的比较次数差不多,查询操作比较均衡
对于B树来说可能是可能是有的值查的快,有的值查的慢。但是在B+树,大家都是一样的速度。
4.由于所有的key都会在叶子结点中体现,因此非叶子结点不用存数据行,只要把所有的数据行给放到叶子节点上即可,非叶子结点中只需要存放索引的值(比如id)
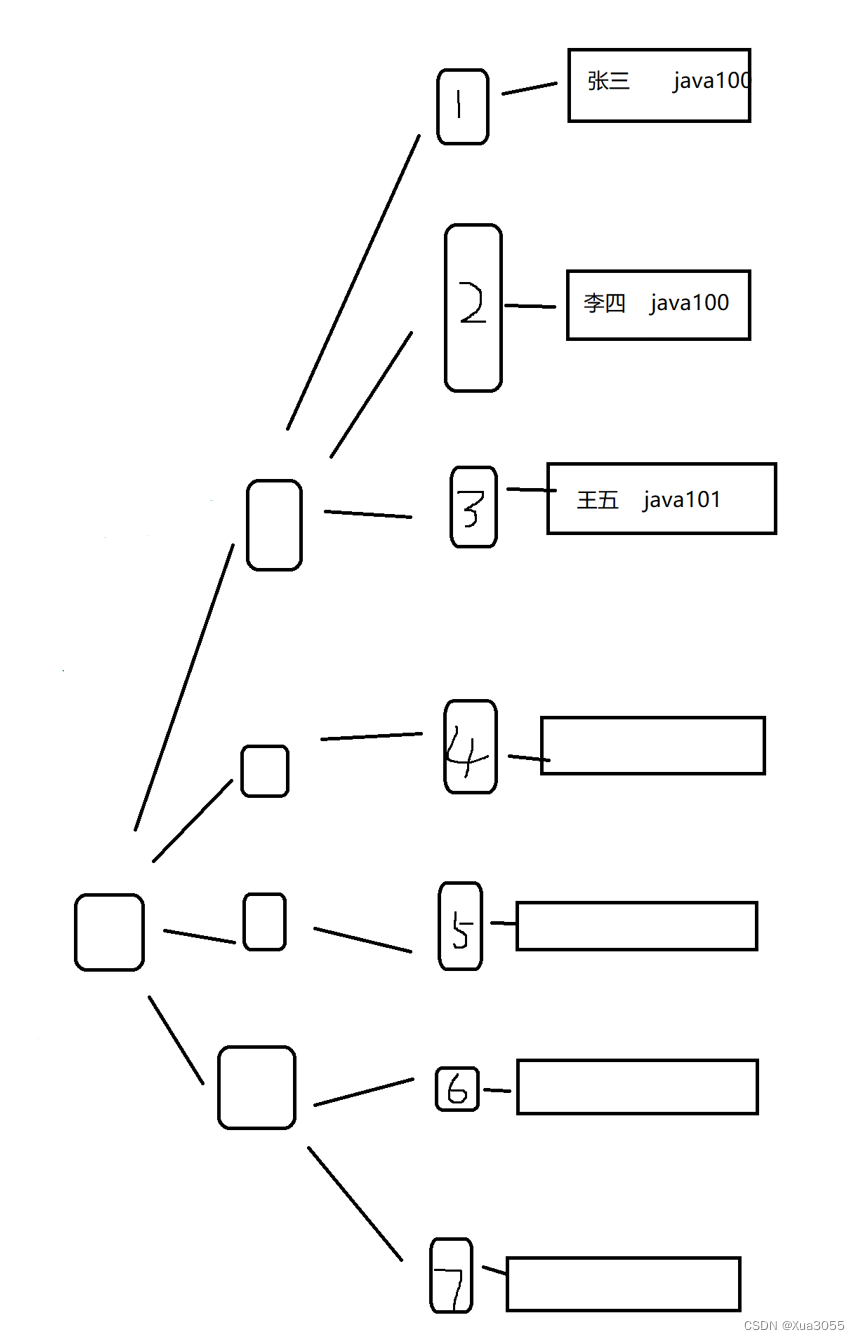
查询的时候,会根据创建的依据(例如id)就会快速在非叶子节点上检索,然后找到所需要的一条记录。并且由于非叶子结点只存了id,意味着它占用的空间是非常小的,进一步降低了硬盘IO,提高了查询速度。
除此之外,有得表并不只有主键索引,别的非主键列,也有索引~
这种情况会构造另外一个B+树,B+树非叶子节点里面存都是这一列里面的key . (比如一堆学生姓名) 到了叶子节点这一层,不是存之前的完整的数据行,而是存主键id。使用主键列来查询,只要查一次B+树就可以了。如果是使用非主键列的索引来查询,则需要先查一遍索引列的B+树,再查一遍主键列的B+树(回表)。
到这里为止,索引的基础内容就介绍的差不多了,索引有一定难度,并且不好理解,需要反复观看~